




 这篇博客探讨了ViT(Vision Transformer)如何将2D图像转换为1D序列,并指出其在中小型数据集上相对于ResNet的表现劣势。ViT缺乏卷积神经网络的局部性和平移等变性归纳偏置,这导致它在某些任务上表现不足。尽管如此,Transformer模型的独特结构为图像处理带来了新的视角和潜力。
这篇博客探讨了ViT(Vision Transformer)如何将2D图像转换为1D序列,并指出其在中小型数据集上相对于ResNet的表现劣势。ViT缺乏卷积神经网络的局部性和平移等变性归纳偏置,这导致它在某些任务上表现不足。尽管如此,Transformer模型的独特结构为图像处理带来了新的视角和潜力。
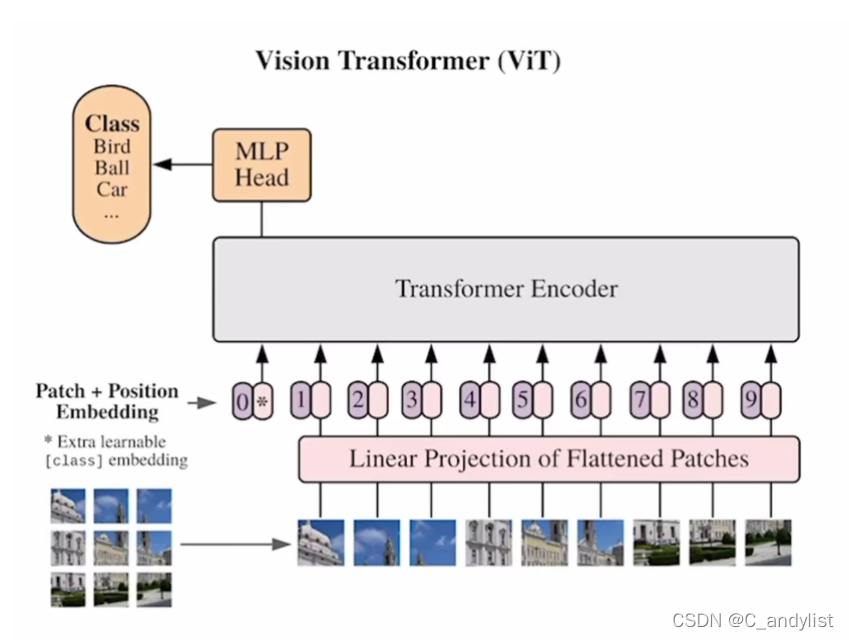
ViT解决的第一个问题就是是如何把2D的图像用1D序列形式表现出来,
其次ViT模型在中小型数据集(如ImageNet)上的效果对比ResNet是比较弱的,这是因Transformer和卷积神经网络相比,缺少了一些卷积神经网络拥有的归纳偏置的先验知识。
对于卷积神经网络来说,常说的有两个inductive bias(归纳偏置):
locality:因为卷积神经网络是以滑动窗口的形式一点一点地在图片上进行卷积的,所以假设图片上相邻的区域会有相邻的特征,靠得越近的东西相关性越强
translation equivariance(平移等变性或平移同变性):f(g(x))=g(f(x)),就是说不论是先做 g 这个函数,还是先做 f 这个函数,最后的结果是不变的。这里可以把f理解成卷积,把g理解成平移操作,意思是说无论是先做平移还是先做卷积,最后的结果都是一样的(因为在卷积神经网络中,卷积核就相当于是一个模板,不论图片中同样的物体移动到哪里,只要是同样的输入进来,然后遇到同样的卷积核,那么输出永远是一样的)

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









