







 该论文探讨了在情感分析中结合视觉和文本信息的网络结构,采用InceptionV3获取图像特征,并通过通道注意力和空间注意力增强视觉特征。同时,利用LSTM和语义注意力模块将单词与视觉特征关联,实现多模态融合。通过自我注意进一步提炼特征,以提高分类效果。实验表明,特征提取和多模态融合是提升性能的关键环节。
该论文探讨了在情感分析中结合视觉和文本信息的网络结构,采用InceptionV3获取图像特征,并通过通道注意力和空间注意力增强视觉特征。同时,利用LSTM和语义注意力模块将单词与视觉特征关联,实现多模态融合。通过自我注意进一步提炼特征,以提高分类效果。实验表明,特征提取和多模态融合是提升性能的关键环节。
前言
论文讲的是两个模态的情感分析, 作者提出一个网络,此网络通过在多个层次上引入注意力,从视觉和文本中产生区分性特征。 通过利用视觉数据中的通道channel注意力和空间注意力来获得双注意力的视觉特征。
总体来说
- 用 两个注意力 channel attention 和 spatial attention 注意力 提高CNN 采集图像特征能力
- 提出 语义注意力 模拟单词的图像区域与语义之间的相关性, 也就是一个JOINT ATTENDED MULTIMODAL LEARNING的过程(联合多模态学习)
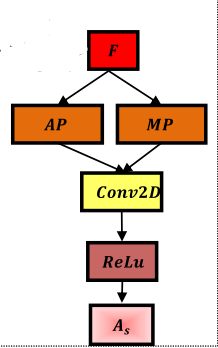
模型结构
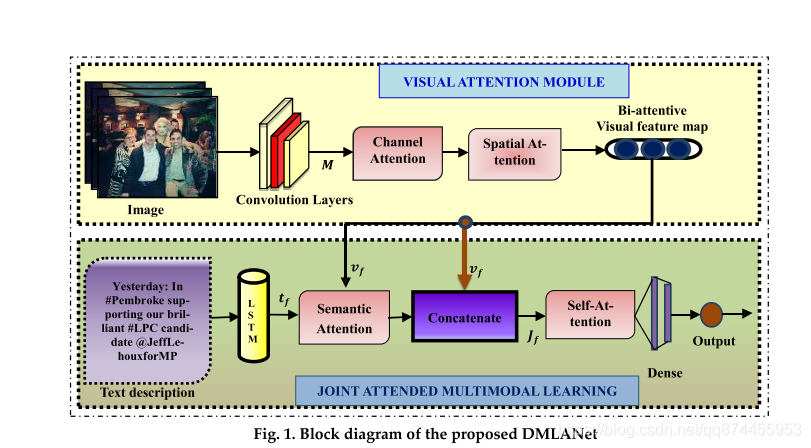
从图可以看出来 ,模型结构不算复杂
- 两模态
- 视觉部分 用 两个Attention
- 文本部分先用LSTM 提取 然后加入视觉信息, 最终来分类
下面就分两块来说, 一是视觉提取模块, 二是 多模态融合(学习)模块
视觉提取模块
视觉提取模块及结构如下图
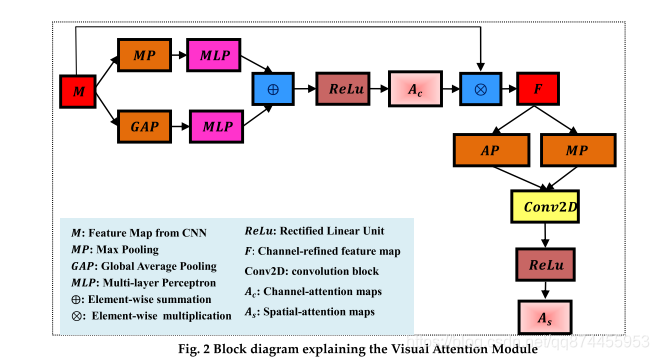
M表示 用Inception V3 得到图片的特征
AP 表示 average pooling
element-wise 表示
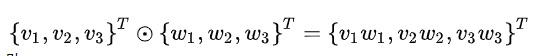
Channel Attention
这个在CV 上的 物体检测上用的比较多, 但是在情感分析方面, 大家忽略了channel 维度的Attention,作者在这里用到, 其结构如下图, 比较简单
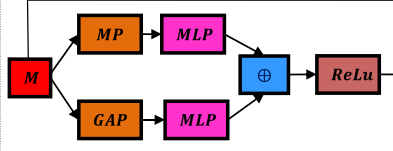
用Inception V3 得到图片的特征 , 然后过一个channel attention , 其公式是
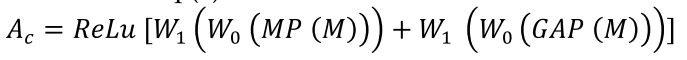
Spatial Attention
在上一步我们得到 Ac 也就是 经过Channel attention 得到的特征 F , 然后我们在经过一个Spatial Attention结构
多模态联合学习模块
首先 每个单词经过Glove 的embedding 后 过一个LSTM 得到 有上下文的 单词表示
Semantic Attention
对每个单词表示和 之前提取的视觉特征Vf进行 semantic attention,
- 先计算联合特征
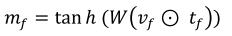
- 计算每个单词权重

- 得到单词特征加权和 加权和表示语义特征Sf
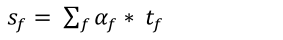
融合
然后我们将得到的语义特征和视觉特征 拼接起来, 用一个self-attention 进一步提取特征, 得到最后的特征表示进行分类
总结
这篇文章还是写的比较好的
- 效果提升 我觉得首先在初步的提取部分 视觉部分比较关键, 说明说明: 特征提的好, 效果没烦恼
- 融合方面把单词的特征 和 视觉结合在一起, 但是又不是Attention 的做法, 感觉理解还不是很透彻, 找师兄讨论一下


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









