




Qwen3模型+LoRA微调后推理测试输出不能停止,输出大量冗余信息
Qwen3模型基于swift框架进行LoRA微调实战训练
问题描述
用户提出一个问题后,智能体回答不会停止直至输出大量冗余信息。
如:
user:你是谁
assistant:我是xxx。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb。aaabbb…
直至达到max_new_tokens上限。
原因分析:
提示:这里填写问题的分析:
对比微调前,模型可以正常推理输出,且检查训练集质量较高,且多次调整了lora参数,以最保守的参数进行训练,甚至在训练完成后选择最初的检查点载入adapters进行推理测试,依旧出现了类似的错误。
怀疑未加载适配的model type和template,以显式的形式设置了这两个参数(不让swift自动根据模型选择),且在测试过程中观察log输出可以看到
<|im_start|>和<|im_end|>都已正常嵌入。
问题到底出在哪呢?
再次检查swift给出的示例,且保守起见选用原用例的测试集测试依旧出现了问题,到现在位置唯一的区别就在于模型了:示例选用Qwen3-8B模型,我选用的是Qwen3-8B-Base(出于可塑性考虑)。
补充下载Qwen3-8B模型,同时检查了tokenizer_config发现了问题在于两个模型分词器设置的结束符不同:
Qwen3-8B模型选用的是常规的<|im_end|>;
Qwen3-8B-Base模型选用的是<|endoftext|>。
虽然还未进行测试,但我想问题源头已经出现了。
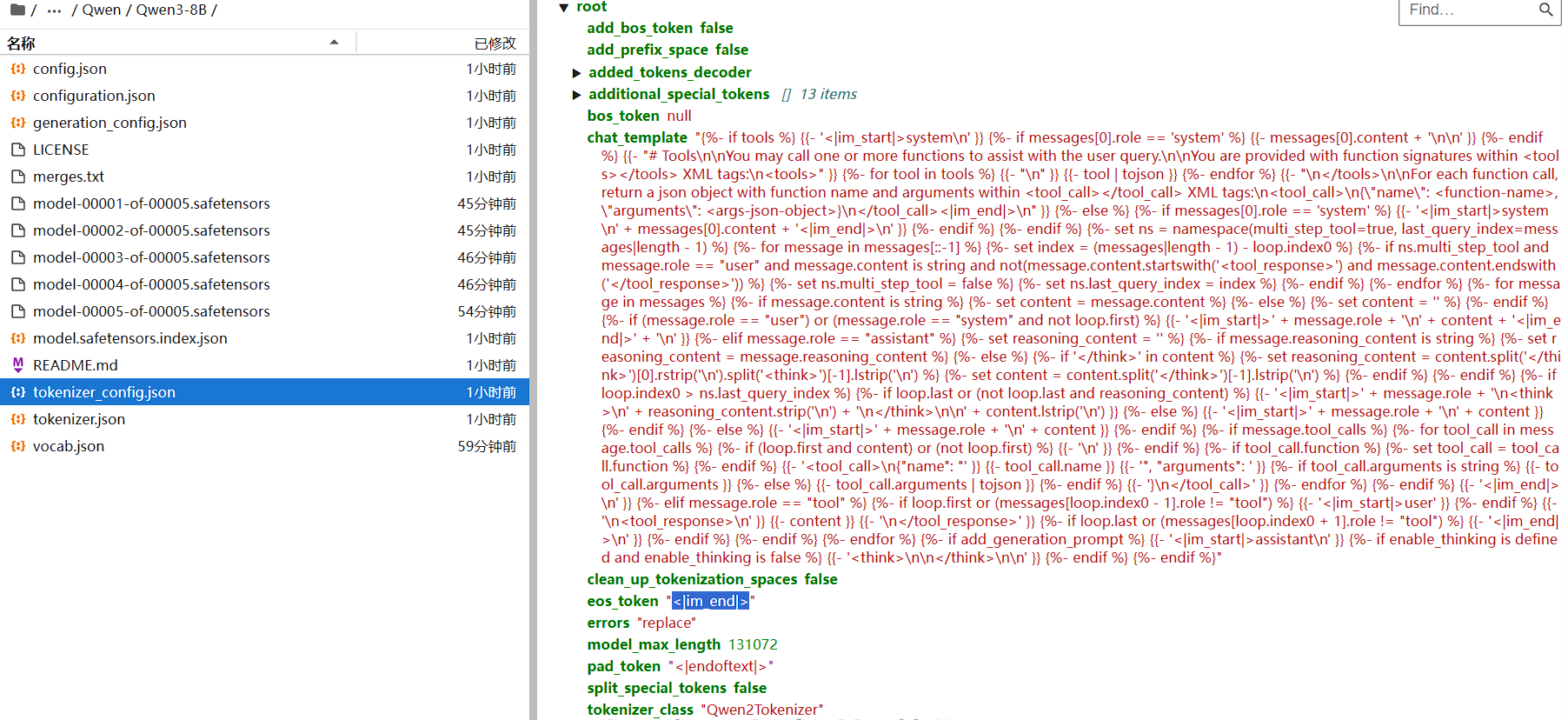
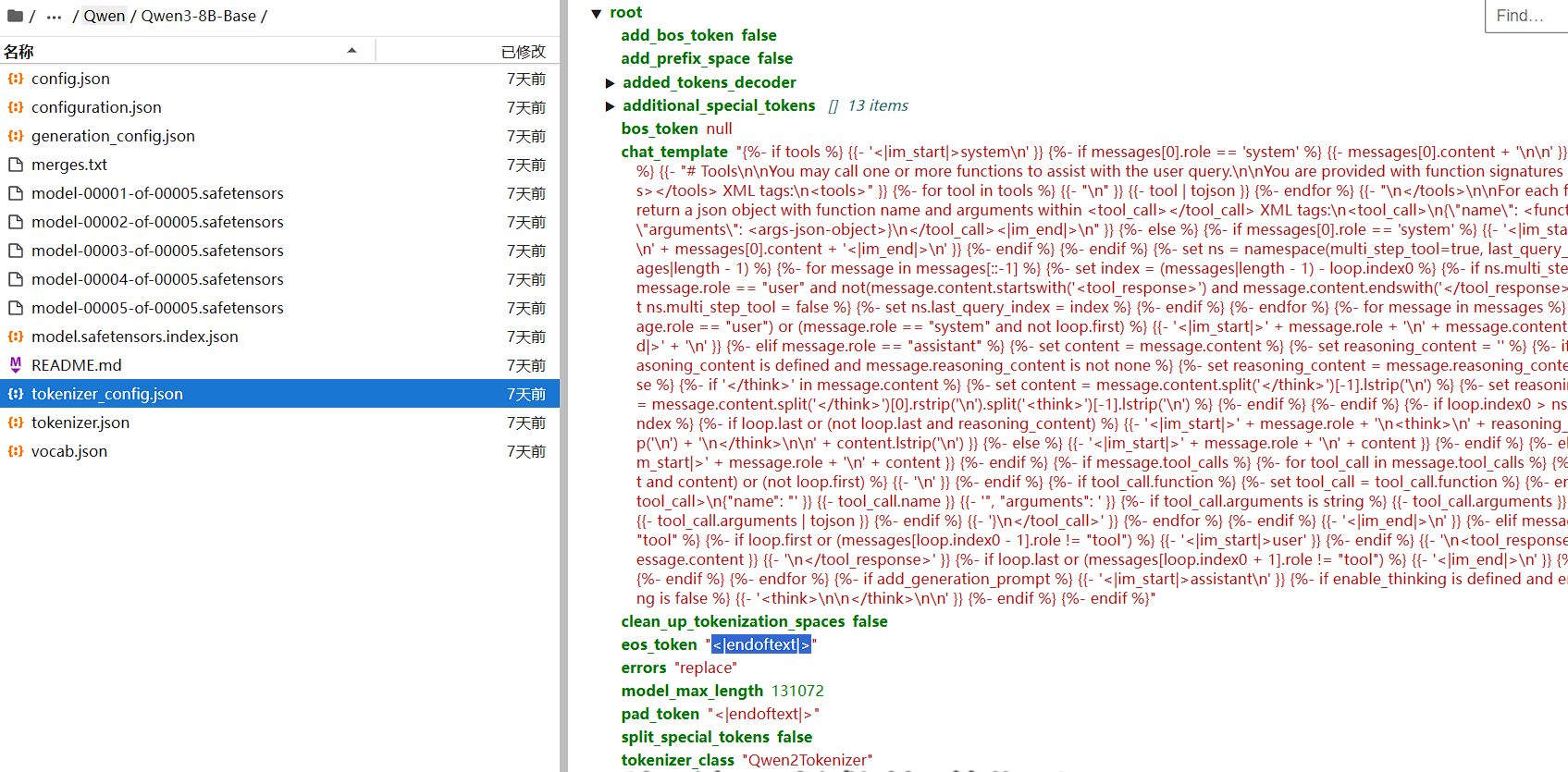
解决方案:
更换模型或者以显式形式在lora训练参数中补充设置额外的结束符<|im_end|>。


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









