







一、LoRA原理
LoRA(Low-Rank Adaptation of LLMs),即LLMs的低秩适应,是参数高效微调最常用的方法。
LoRA的本质就是用更少的训练参数来近似LLM全参数微调所得的增量参数,从而达到使用更少显存占用的高效微调。
1.1 问题定义
LoRA与训练目标是解耦的,但本文设定就是语言模型建模。
以下将给出语言建模(可自然推广到序列建模)的基本符号定义,即最大化给定提示的条件概率(本质是极大似然估计)。
The maximization of conditional probabilities given a task-specific prompt
给定一个参数为\(\mathbf{\Phi}\)预训练的自回归语言模型$ P_{\Phi}(y|x)$。
\(x\)为输入,\(y\)为输出
note: 为与原文符号一致,下文\(\mathbf{\Phi}\)、\(\mathbf{\Theta}\)、\(\mathbf{W}\)均表示模型参数
全参数微调
每次full fine-tuning训练,学一个 \(\Delta \mathbf{\Phi}\),\(|\Delta \mathbf{\Phi}|\) 参数量大hold不住

语言模型的条件概率分布建模目标
高效微调
$ \Delta \mathbf{\Phi}$ 是特定于下游任务的增量参数
LoRA将 $ \Delta \mathbf{\Phi}=\Delta \mathbf{\Phi}(\Theta)$ ,用参数量更少的$ \mathbf{\Theta}$来编码(低秩降维表示来近似), \(|\mathbf{\Phi}| << | \mathbf{\Theta}|\)

LoRA训练目标
Transformer架构参数
Transformer层的输入和输出维度大小 \(d_{model}\)
\(\mathbf{W_q}\)、\(\mathbf{W_k}\)、\(\mathbf{W_v}\),和\(\mathbf{W_o}\)分别代表自注意力的query、key、value和output投影矩阵
\(\mathbf{W}\)或\(\mathbf{W}_0\)代表预训练的权重矩阵
\(∆\mathbf{W}\)是微调后得到的增量参数矩阵(训练后,优化算法在参数上的累计更新量)
\(r\)代表LoRA模块的秩
1.2 LoRA简介
LoRA的核心思想是,在冻结预训练模型权重后,将可训练的低秩分解矩阵注入到的Transformer架构的每一层中,从而大大减少了在下游任务上的可训练参数量。
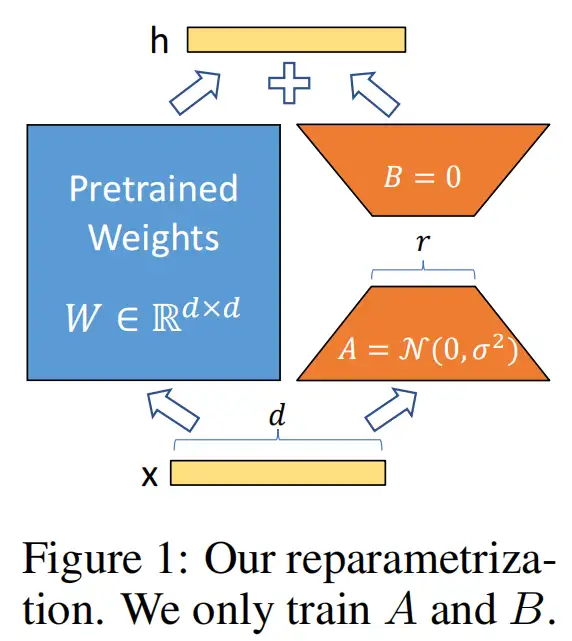
LoRA结构
We propose Low-Rank Adaptation(LoRA), which freezes the pre trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
在推理时,对于使用LoRA的模型来说,可直接将原预训练模型权重与训练好的LoRA权重合并,因此在推理时不存在额外开销。
1.3 为什么要LoRA
背景
通常,冻结预训练模型权重,再额外插入可训练的权重是常规做法,例如Adapter。可训练的权重学习的就是微调数据的知识。
但它们的问题在于,不仅额外增加了参数,而且还改变了模型结构。
这会导致模型训练、推理的计算成本和内存占用急剧增加,尤其在模型参数需在多GPU上分布式推理时(这越来越常见)。

推理性能比较
动机
深度网络由大量Dense层构成,这些参数矩阵通常是满秩的。
相关工作表明,When adapting to a specific task, 训练学到的过度参数化的模型实际上存在于一个较低的内在维度上(高维数据实际是在低维子空间中)
We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









