



作者 | 深蓝学院 来源 | 自动驾驶最新技术路线总结(分阶段、BEV、端到端、VLA)
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
概述
行业在解决的问题:安全且经济 corner case
技术路线之争
单车智能 vs 智能网联
传感器:视觉 vs 激光雷达
算法架构:模块化 vs 端到端
AI决策:VLM vs VLA vs WA(去LLM)
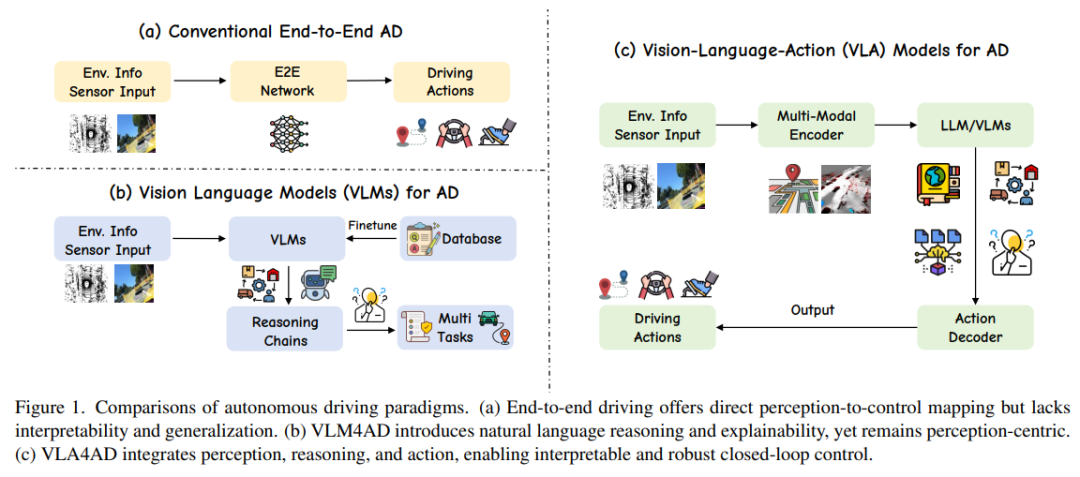
Waymo等主流企业采用 VLM,让 AI 负责环境理解与推理,最终决策权交由传统模块,确保过程可控
特斯拉、吉利、小鹏等企业探索的 VLA则试图让 AI 直接学习所有驾驶技巧,通过海量数据训练实现 “端到端” 决策
华为: ADS 4 为代表的WEWA 架构(世界引擎 + 世界动作模型)
规则系统 → 数据驱动 → 认知建模
2022年以前:感知、预测、决策(规划控制)
2022年: BEV 感知成为主流
2023年: OCC 感知兴起
2024年: 端到端(E2E)开始落地
2025年: VLA/VLM/WA成为新热点
1
—
分阶段模块化
感知(定位)、预测、规划、控制
在多模态大模型和端到端自动驾驶技术[71]出现之前,自动驾驶的感知和预测任务通常由不同模块承担,每个模块针对各自任务和数据集进行训练
感知模块:处理图像、点云等数据,完成目标检测和地图分割等任务,将感知到的世界投射到抽象几何空间。
感知数据的处理与深度学习技术的发展密切相关
定位模块:确定车辆在环境中的精确位置。
全球定位系统( GPS)
惯性测量单元(IMU)+传感器数据来估计车辆的全局位置。
基于地图的定位技术,如将车辆的传感器数据与预先制作的详细地图进行匹配 。
预测模块:通常在这些(感知输出的)几何空间内运行,预测周围环境的未来状态
如:预测其他车辆的行驶轨迹和行人的移动
决策和规划模块:根据导航信息,并在接受上游的感知和定位信息的基础上,同时结合自车的当前状态,对当前环境进行分析并做出具体决策,以在有限的时间范围内规划出满足安全、舒适等约束条件的可行驶轨迹
控制模块:负责精确控制车辆的油门、刹车和转向,以实现平滑和安全的驾驶
感知概述
最开始:二维或三维检测,其目标是识别图像中的物体(如车辆、行人、车道线),并将这些带有标签的边界框提供给下游模块。
问题:与后续的路径规划模块之间存在语义隔阂。感知的结果后面规划不好用
【空间关系的影响】感知视角:只要准确框出所有物体、不遗漏、不误判,就算完成任务,不关心物体与车辆的 “空间关系影响”。
规划视角:需要知道物体是否在 “可通行区域” 内,比如路边的护栏是 “不可逾越的边界”,临时停靠的车辆是 “需要绕行的障碍”,这些 “场景语义” 无法从单纯的 “框” 中解读出来。
【信息维度不匹配:从 “静态描述” 到 “动态决策”】感知输出:仅能提供 “前方 50 米有一个宽 1.8 米、高 1.5 米的矩形框,标签为‘行人’” 这类数据。
规划需要:这个行人是在过马路还是在路边站立?他的行走方向是否会与车辆路径交叉?当前车速下是否需要减速避让?这些 “动态意图” 和 “交互关系” 信息,单纯的 “框” 无法提供。
多摄像头、多传感器数据信息无法融合
BEV:将不同视角的信息融合进一个统一的、具备空间一致性的坐标系,极大地便利了路径规划与动态信息的融合。
BEV的普及实质上重塑了感知与规划之间的接口,使其更易于被端到端的学习模型所理解与利用(后面会提到端到端)
问题:BEV缺乏高度信息
OCC:占用网络不是简单地提供“这里有个车”这样的数据,而是把“某个空间点在未来若干帧里被什么占着、有多大概率被占着”等数据给厘清出,它把时间维、空间维和不确定性都纳进来,对动态交互的建模更友好。
SLAM感知
视觉SLAM、激光雷达SLAM,以激光雷达SLAM为例。在实际使用时候,一般先建图,再定位。而建图过程,即是SLAM过程(同步建图与定位);后面的定位,可以使用如NDT等算法进行定位
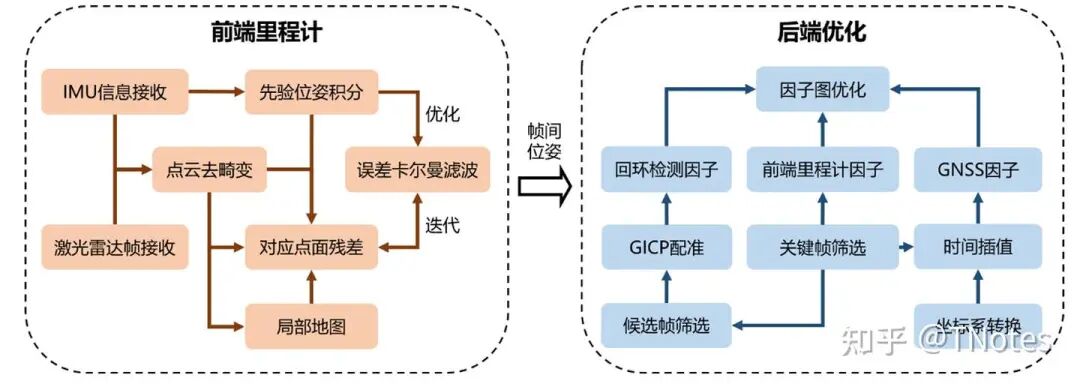
建图:前端里程计使用激光雷达和 IMU 的信息,接收到信 息后首先进行时间戳对齐以及为激光雷达点云去畸变,再通过 IMU 积分以及点面 距离残差进行误差卡尔曼滤波,迭代求解此时刻激光雷达相对于地图坐标系的里程 计位姿。后端优化接收前端里程计和 GNSS的信息,使用前端里程计构建激光雷达 里程计因子、激光雷达帧的相似性配准构建回环检测因子、GNSS 位置信息构建 GNSS 因子,共同加入因子图中进行联合优化,进一步优化前端输出的里程计位姿。 通过激光雷达点云及其对应的里程计位姿,即可构建出三维点云地图,供后续定位 等环节使用。
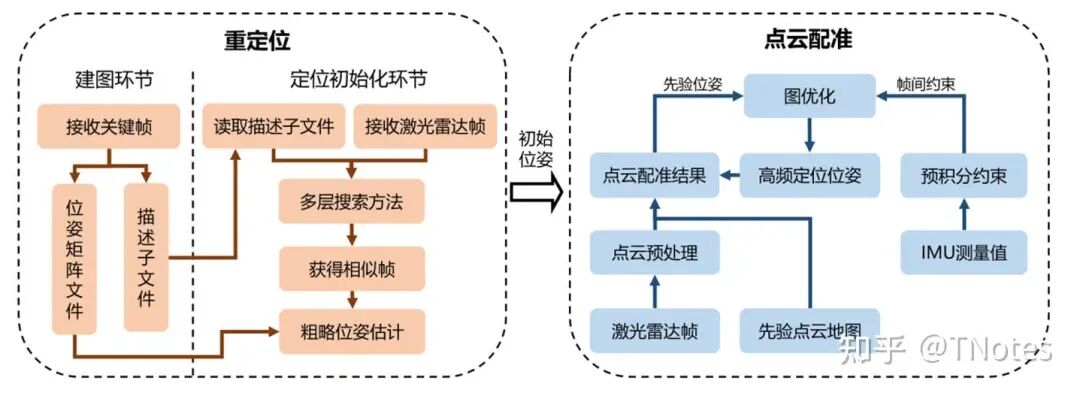
定位:重定位模块首先设计了一种全局描述子,这种描述子依赖激光雷达点 云的结构信息和强度信息,将点云的特征通过矩阵的方式进行表达,降低了查找相 似帧的时间。同时设计了一种多层搜索方法,可以在更短的时间内搜寻相似帧,而 且不会降低查找的准确程度。在建图环节中,会根据接收到的关键帧计算描述子并 将其对应的变换矩阵保存到文件中。当进行定位初始化时,重定位模块会加载这些 描述子和相对位姿,通过描述子的相似性判断点云帧的相似性,进而判断满足迭代 要求的位姿初值发送给点云配准模块。点云配准模块使用 IMU 预积分代替传统的 运动模型假设,和配准结果共同进行图优化,可以提供更为准确的迭代初值,降低 计算时间并增加其精度。
BEV/OCC感知
现状: 已完全成熟并大规模量产
核心:表征空间的统一。它解决了多传感器融合的根本问题——如何在统一的空间中理解三维世界
BEV和OCC感知论文汇总:
https://blog.youkuaiyun.com/CV_Autobot/article/details/138738416
BEV经典算法汇总:BEV算法(感知):常用算法和BEV论文拆解https://v11enp9ok1h.feishu.cn/wiki/CLppw4v5EiXfjDkOY8IcBDQ5nyh
优势:
天然适合动态/静态感知、OCC感知
快速替代传统单目/双目检测方案
99%常规场景可收敛
缺陷:在非结构化场景和超复杂路口(150米+)仍有瓶颈,暴露了纯几何表征的天花板。
BEV+3DGS?
GaussianLSS:迈向真实世界的BEV感知
https://zhuanlan.zhihu.com/p/1895567729823568547
https://zhuanlan.zhihu.com/p/1892984568358880566
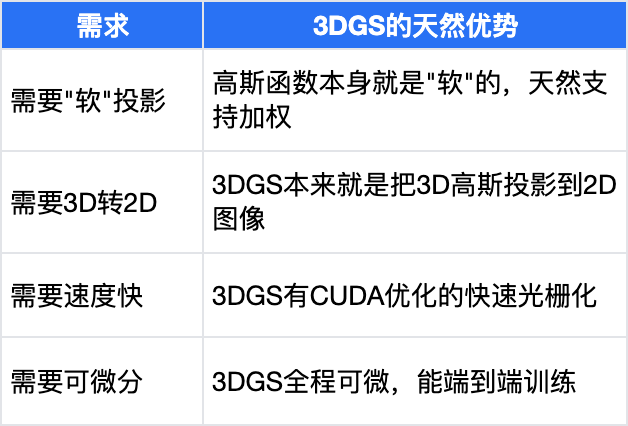
为什么现在有些BEV算法要用3DGS?
用3DGS不是为了重建场景,而是借用了3DGS的一个核心特性——”软投影”,来解决传统LSS方法的致命缺陷
3DGS在这里不是用于重建,而是被当成一个高级版的”双线性插值”或”模糊投影”工具,恰好它的”模糊”特性完美契合不确定性建模的需求。
本质是用一个成熟的渲染算法,替换掉感知 pipeline 里一个粗糙的投影模块,顺带收获了效率提升
LSS投影的缺陷:
离散=稀疏:只在少数几个深度点有特征,BEV图上出现”空洞”
不连贯:相邻像素深度差1个箱子,投影到BEV上可能相距2米,特征突然断开
没容错:深度估计错了0.5米,特征就投到隔壁车道去了
这篇文章怎么做的?
把每个像素变成一个3D高斯”气球”:
连续=致密:气球在BEV上自然摊开,填满空隙,没有”空洞”
平滑:相邻像素的”气球”边缘重叠,特征过渡自然
带容错:深度估计不准没关系,气球本身就有范围,真实位置仍在覆盖区内
不确定性可视化:气球大小直接反映深度估计的置信度
2
—
端到端
参考资料:端到端自动驾驶综述 https://zhuanlan.zhihu.com/p/675237671
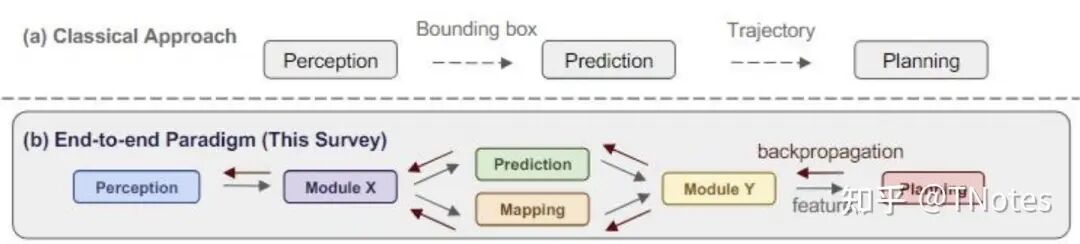
端到端定义:输入传感器的原始信息,直接输出任务关心的变量
自动驾驶系统可定义为从输入到输出完全可微的过程。模型整体学会,而不是把问题拆成一大堆由人写规则的子模块
自动驾驶端到端的本质:感知信息的无损传递
狭义的端到端
原始传感器数据为输入,规划/控制 或者 行驶轨迹(车型适配问题)动作为输出
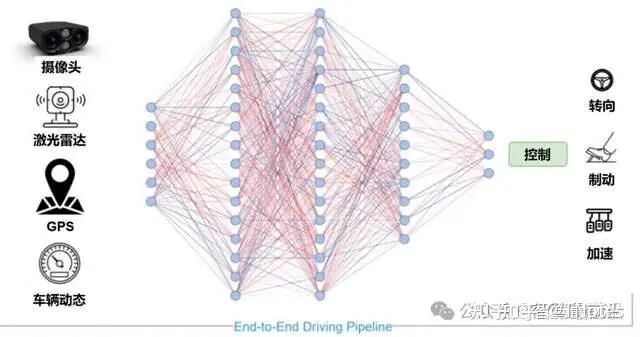
广义的端到端
感知和决策规划分别使用神经网络,模块之间仍有人工设计的数据接口。引入了一些相关的中间任务的监督
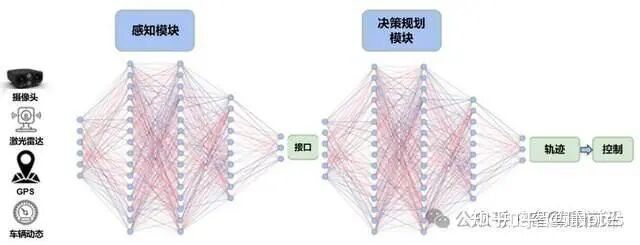
和传统分阶段的核心区别
传统:每个模块单独优化,再拼接在一起
端到端:让神经网络学会从输入到输出的整体映射,用数据告诉它“这样做就是好”的标准。试图通过梯度反传实现全局优化。
因此:传统分阶段的问题不在于分阶段本身,而在于每个阶段的信息瓶颈。
- 阶段目标与统一目标不一致
- 误差累积问题
计算负担
端到端的问题:
可解释性悖论: 端到端提升了性能但降低了可解释性,这在安全攸关的自动驾驶领域是致命的
数据问题:规模、质量(Tesla领先在数据规模上)
需要更多端到端标注的轨迹数据,成本高昂
人类的驾驶数据噪音很多,自动驾驶场景和模式繁多,学习起来困难
长尾场景覆盖度
工程复杂度: 调试和迭代比分阶段系统更困难
在广义的端到端里面,感知结果会交给决策层学习。决策层的技术路线:
模仿学习:
通过拟合人类驾驶数据来快速获得基础能力
但泛化性不足,在偏离示范数据时表现不佳
强化学习:
通过试错学得鲁棒策略
但依赖仿真环境以规避现实风险(生成场景与真实世界分布存在显著偏差)
先用模仿学习初始化模型,再通过强化学习在仿真中优化长期收益
端到端的分类
端到端的分类/阶段:
参考https://zhuanlan.zhihu.com/p/1895879471770346785
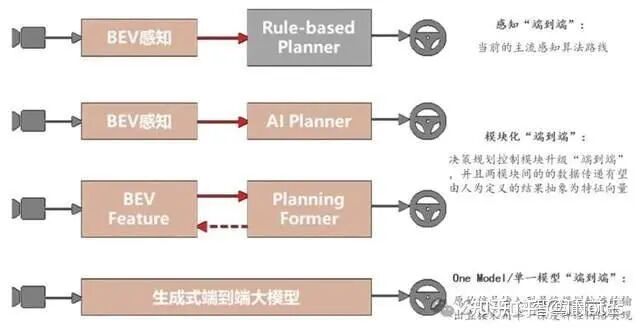
感知“端到端” 。这一阶段,整个自动驾驶架构被拆分成了感知和预测决策规划两个主要模块,其中,感知模块已经通过基于多传输器融合的BEV (Bird Eye View,鸟瞰图视角融合 ) 技术实现了模块级别的 “ 端到端 ”。通过引入 transformer 以及跨传感器的 cross attention 方案,感知输出检测结果的精度及稳定性相对之前的感知方案都有比较大的提升,不过,规划决策模块仍然以Rule-based 为主。
第二阶段:决策规划模型化。这个阶段,整个自动驾驶架构被仍然分为感知和预测决策规划两个主要模块,其中,感知端仍保持上一代的解决方案,但预测决策规划模块的变动比较大 —— 从预测到决策到规划的功能模块已经被集成到同一个神经网络当中。值得注意的是,虽然感知和预测规划决策都是通过深度学习实现,但是这两个主要模块之间的接口仍然基于人类的理解定义(如障碍物位置,道路边界等);另外,在这一阶段,各模块仍然会进行独立训练。
第三阶段:模块化端到端。 从结构上来讲,这一阶段的结构和上一阶段比较类似,但是在网络结构的细节及训练方案上有很大不同。首先,感知模块不再输出基于人类理解定义的结果,而更多给出的是特征向量。相应地,预测决策规划模块的综合模型基于特征向量输出运动规划的结果。除了两个模块之间的输出从 基于人类可理解的抽象输出变为特征向量,在训练方式上,这个阶段的模型必须支持跨模块的梯度传导 —— 两个模块均无法独立进行训练,训练必须通过梯度传导的方式同时进行。 【华为、小鹏、理想】
第四阶段:One Model/ 单一模型端到端。在这一阶段,就不再有感知、决策规划等功能的明确划分。从原始信号输入到最终规划轨迹的输出直接采用同一个深度学习模型。基于实现方案的不同,这一阶段的 One Model 可以是基于强化学习( Reinforcement Learning, RL)或模仿学习( Imitation Learning, IL)的端到端模型,也可以通过世界模型这类生成式模型衍生而来。【Tesla】 其中,模块化端到端以及 One Model 端到端都是基于全局优化的视角进行设计,且都满足梯度反向传播的特性,接下来,我们详细阐述下两个阶段的来龙去脉及技术特点。
3
—
VLM/VLA
参考资料:VLA综述
https://zhuanlan.zhihu.com/p/1923912633192523592
corner case的本质: 不是数据问题,而是理解问题。传统方案通过枚举case的方式永远无法穷尽,VLA通过理解语义来泛化
语言模型的突破:语言对应的概念和逻辑关系建模了出来。比如 “小狗” 或 “汽车”,在模型中是一个清晰的概念,模型能基于这些概念做理解和生成,这是过去 AI 没有的
语言的三大价值:
海量数据:语言模型吸收了海量互联网案例(尤其是 “彩色案例”,即有代表性和复杂性的场景)。这些数据对自动驾驶训练非常有帮助。
推理能力:通过链式推理(CoT, Chain of Thought),语言模型能带来一定的逻辑推理,弥补世界模型目前还未建立的细粒度推理。
人机交互:用户需要能像跟司机沟通一样,直接告诉车 “开进小区,左转,在楼下停”。这需要自然语言接口,而不仅仅是导航按钮或固定选项。
两种观点:VLA 是世界模型的核心,也有说世界模型是用来给 VLA 做仿真评测的
现在大部分 VLA、VLM 的做法,是先有一个语言模型基座,然后在一些图像数据上训练一个插件,把视觉转成语言,再输入到语言模型里。
它的 “根” 还是语言,只是头上插了个视觉转换器。
世界模型要直接在视频端建立能力,而不是先转成语言。
华为就提出了 WA(World Action, 世界行为模型),并强调不需要 L(语言)
VLA、WA 这些名字,更多是表述方式的差别。
关键还是要看它是否真正建立了时空认知能力,而不仅仅是在语言模型上做加法。
语言模型的局限:语言模型解决的是 “概念认知”,但在 “时空认知”——真实世界的四维时空(空间 + 时间)建模上仍有明显短板。比如复杂的交通场景、物理规律。自动驾驶需要的恰恰就是 “时空认知”,这个空白,正是世界模型要去补的。世界模型的目标是建立基于视频/图像的 “时空认知”,补齐语言模型的短板。
物理规律的内建:比如重力、惯性、速度变化,这些规律必须在模型内部形成;
时空操作能力:能理解和预测物体在三维空间 + 时间维度的运动,比如车辆绕行、机器人搬运。
缺陷
空间理解能力: 现有通用大模型缺乏精确的3D空间理解
实时性约束: 车端算力限制vs模型能力的平衡
专用基座模型: 需要专门为自动驾驶训练的基础模型
VLM
VLM能够解释复杂的交通场景、回答相关问题,显著提升了系统的可解释性和对罕见事件的泛化能力。然而,这些模型主要停留在“感知和理解”,语言输出与车辆的实际控制脱节,存在“行动鸿沟”
VLM:环境信息输入 → VLM → 推理链/多任务(感知和理解,用于增强可解释性) → 输出(非直接控制)
输入数据
视觉输入:前视相机图像(多摄像头拼接)、导航地图信息(如高德/百度地图截图)、BEV特征图
语言输入:
Prompt指令:系统预设的引导文本(如”请分析当前场景并给出驾驶建议”)
导航指令:来自导航系统的文本(如”前方500米右转”)
用户指令:驾驶员语音转文本(如”避开拥堵路段”)
数据格式:图像经过ViT/CNN编码为256-512维特征向量;文本经Tokenizer编码为Token序列
核心处理流程
采用三阶段推理链:
场景描述(天气、时间、道路类型等基础信息)
场景分析(关键物体识别、风险判断、意图预测(如”路边停车可能开车门”))
高层决策建议
技术实现:
视觉编码器:ViT或CNN提取图像特征
语言编码器:Transformer-based LLM(如Qwen-7B压缩版)
跨模态对齐:通过Cross-Attention机制,让每个文本Token关注图像相关区域
运行频率:低频率(2-5 Hz),作为”慢系统”
输出数据
场景描述:文本格式,如”雨天夜间,城市主干道,前方红灯”
场景分析:文本格式,如”右侧公交车遮挡视线,存在行人横穿风险”
Meta-Actions:结构化决策建议, VLA
VLA
VLA:感知推理行动闭环。VLA旨在打造能够理解高级指令、推理复杂场景并自主决策的智能车辆。
环境信息输入 → 多模态编码器 → LLM/VLM → 动作解码器 → 驾驶动作
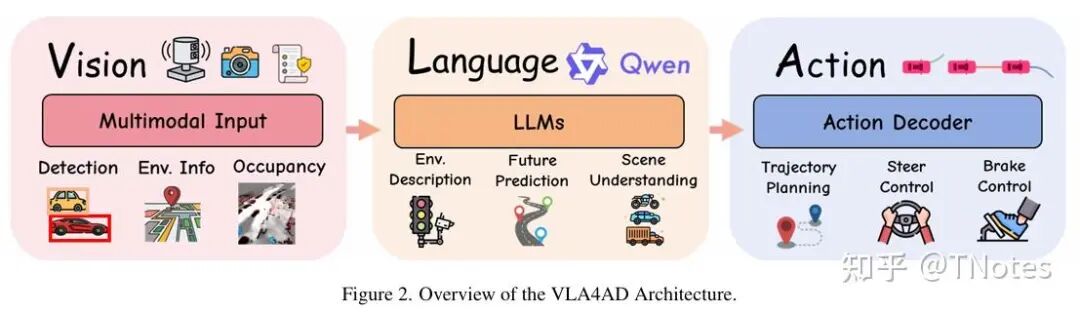
输入数据
视觉数据 (Visual Data): 视觉是自动驾驶系统的核心输入。技术已从早期的单前视摄像头发展到如今的多摄像头环视系统。原始图像可以被直接处理,或转换为鸟瞰图(BEV)等结构化表示,以辅助空间推理。
其他传感器数据 (Other Sensor Data): 为增强空间感知能力,系统还融合了多种传感器。包括用于精确3D结构的激光雷达(LiDAR)、用于速度估计的雷达(RADAR)、用于运动追踪的惯性测量单元(IMU)以及用于全局定位的GPS。方向盘转角、油门等本体感知数据也愈发重要。
语言输入 (Language Inputs): 语言输入的形式日趋丰富,其演进路径如下:
直接导航指令:例如“在下一个路口左转”。
环境查询:例如“现在变道安全吗?”。
任务级指令:例如,用自然语言解析交通规则或高阶目标。
对话式推理:最新的研究已支持多轮对话和基于思维链(CoT)的复杂推理,甚至包括语音指令输入。
采用端到端一体化架构
多模态编码:视觉特征+语言特征
融合与推理
动作生成(关键区别)
技术实现:三大核心模块
视觉编码器 (Vision Encoder): 该模块负责将原始图像和传感器数据转换为潜在表征。通常使用如DINOv2或CLIP等大型自监督模型作为骨干网络。许多系统采用BEV投影技术,或通过点云编码器(如PointVLA)来融合3D信息。
语言处理器 (Language Processor): 该模块使用预训练的语言模型(如LLaMA2或GPT系列)来处理自然语言指令。通过指令微调或LoRA等轻量化微调策略,可以高效地让模型适应自动驾驶领域的特定知识。
动作解码器 (Action Decoder): 该模块负责生成最终的控制输出。其实现方式主要有三种:
自回归令牌器:将连续的轨迹点或离散的动作(如“加速”、“左转”)作为Token,并依次生成。
扩散模型头 (Diffusion heads):基于融合后的特征,通过采样生成连续的控制信号。
分层控制器:由一个高阶的语言规划器生成子目标(如“超车”),再由一个低阶的PID或MPC控制器来执行具体轨迹。
输出数据
【直接控制信号】低阶动作 (Low-Level Actions): 一部分VLA4AD系统直接预测原始控制信号,如方向盘转角、油门和刹车。这种方式优点是可以输出更精细的控制,但对感知误差敏感,且缺乏长远规划能力,并且不同车型的可拓展性较差。
【轨迹点序列(部分方案):未来5秒、每秒10个点的(x,y)坐标及速度】轨迹规划 (Trajectory Planning): 另一些VLA自动驾驶研究输出预测轨迹或路径点。这种方式具有更好的可解释性和拓展能力s,可以由下游的MPC等规划器灵活执行。它使得VLA模型能够进行更长时程的推理,并更有效地整合多模态信息。
思维链(CoT):可选输出推理过程,如"检测到锥桶→分析施工区域→规划绕行轨迹"
共存协作——VLM提供高层决策指导,VLA负责底层精细执行。
商业应用:小鹏第二代VLA
语言作用的演变:VLA发展的四个阶段
阶段一:语言模型作为解释器 (Pre-VLA)
以场景描述增强可解释性。
采用冻结视觉模型(如CLIP)+ LLM的架构,代表作为DriveGPT-4,仅生成高阶操纵标签或场景描述,但不参与控制。
核心问题是延迟高、效率低,且存在语义鸿沟(描述≠驾驶指令)。
阶段二:模块化VLA模型
语言成为主动规划组件,嵌入可解释的决策中间环节。语言不再仅仅是“评论员”,而是成为了规划过程中的一个可解释的中间环节,将高级指令转化为车辆可执行的计划。
典型工作包括OpenDriveVLA(融合多模态输入生成路径点)、CoVLA-Agent(动作Token映射轨迹)、DriveMoE(用语言线索动态选择专家)和RAG-Driver(检索增强规划)。
虽缩小了语义差距,但依赖多阶段流水线,存在延迟与级联误差风险。
阶段三:统一的端到端VLA模型
构建单一可微分网络,将传感器输入(+可选文本指令)直接映射到轨迹或控制信号。
代表作为EMMA、LMDrive、CarLLaVA(基于LLaVA,采用“行动构想”技术)、ADriver-I(生成式视频模型预测未来画面)和DiffVLA(扩散生成轨迹)。模型反应灵敏,但在长时程规划与细粒度解释上仍存瓶颈。
阶段四:推理增强的VLA模型
将VLM/LLM置于控制环路核心,实现长时程推理、记忆与交互。
核心是让模型在行动前进行解释与预测。
代表作为ORION(结合记忆模块与LLM生成轨迹+自然语言解释)、Impromptu VLA(思维链CoT对齐行动,零样本SOTA)和AutoVLA(融合CoT与轨迹规划,离散化路径点)。
未来挑战在于城市规模记忆索引、LLM推理实时性(30Hz)及策略形式化验证。
4
—
VLA和世界模型
两种观点:VLA 是世界模型的核心,也有说世界模型是用来给 VLA 做仿真评测的
现在大部分 VLA、VLM 的做法,是先有一个语言模型基座,然后在一些图像数据上训练一个插件,把视觉转成语言,再输入到语言模型里。
它的 “根” 还是语言,只是头上插了个视觉转换器。
世界模型要直接在视频端建立能力,而不是先转成语言。
华为就提出了 WA(World Action, 世界行为模型),并强调不需要 L(语言)
VLA、WA 这些名字,更多是表述方式的差别。
关键还是要看它是否真正建立了时空认知能力,而不仅仅是在语言模型上做加法。
统一vla和世界模型:阿里最新工作https://mp.weixin.qq.com/s/_o4P-wzVKx5wQEWDUt_qsQ
- 世界模型 通过结合对动作与图像的理解来预测未来图像,旨在学习环境的潜在物理规律,以提升动作生成的准确性;
- 动作模型 则基于图像观测生成后续动作,不仅有助于视觉理解,还反向促进世界模型的视觉生成能力。
思考:自动驾驶是否一定需要语言模型?
参考资料:https://mp.weixin.qq.com/s/Iubiu1CC8YG_ppAzDk3Luw
2025技术路线之争
以华为乾崑智驾 ADS 4为代表的WEWA 架构(世界引擎 + 世界动作模型)
以理想、小鹏等企业竞逐的VLA 架构(视觉 - 语言 - 动作模型)
两种技术路线对比
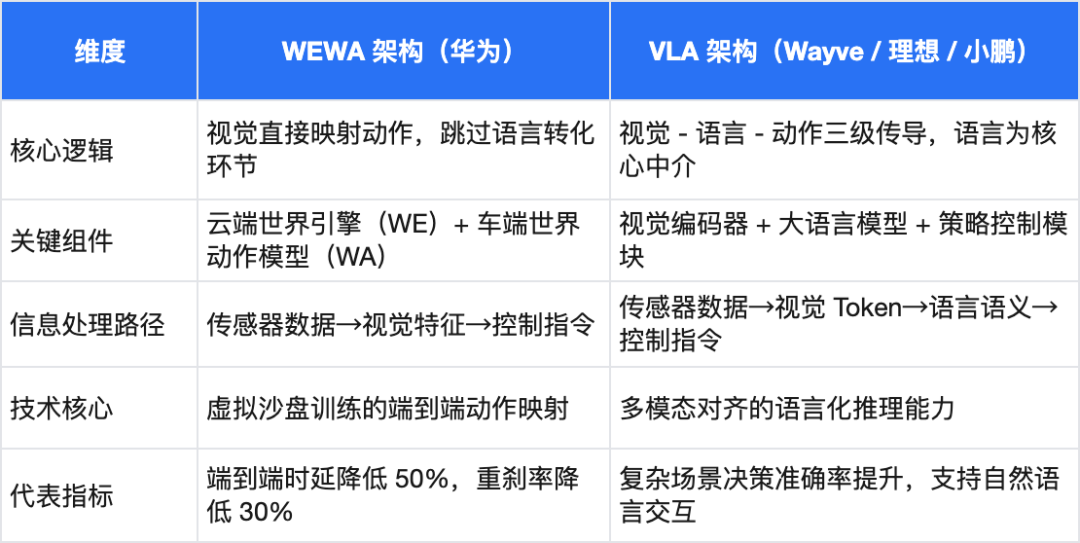
VLA 架构的兴起仍源于语言模型带来的场景抽象能力与认知智能跃升,这正是 WEWA 等 “去语言化” 架构不具备的。
语言的高度抽象能力可以把成千上万的类似场景压缩成一句话。所谓抽象,本质是归类,用对一类场景的描述来涵盖这一类中数不清的个例。
语言模型在自动驾驶中的作用
跨场景的知识迁移能力:大语言模型(LLM)通过互联网级预训练积累的常识知识,赋予自动驾驶系统"类人推理"能力,这被认为是解决长尾场景的关键突破。【华中理工与地平线团队开发的Senna系统,在大型数据集DriveX上预训练后,相比未预训练模型平均规划误差降低27.12%,碰撞率降低33.33%,印证了跨场景迁移的量化价值。】
多模态信息的统一表征:语言作为通用语义载体,实现了视觉、语音、导航等异构信息的端到端对齐,解决了传统架构的接口瓶颈问题。【商汤DriveMLM通过一致的决策指令设置,可直接与Apollo等模块化系统对接,无需重大更改即可实现闭环驾驶,证明了语言接口的兼容性价值。】
决策的可解释性与安全性:语言模型将"黑箱"决策转化为自然语言推理链,这是L3+自动驾驶商业化的信任基石。
来源:https://zhuanlan.zhihu.com/p/82012206659
作者:TNotes
参考资料:
传统的视觉/激光雷达–>世界模型
https://mp.weixin.qq.com/s/Iubiu1CC8YG_ppAzDk3Luw
自动驾驶技术路线总结:https://zhuanlan.zhihu.com/p/19
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 3527
3527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









