







论文标题:VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
这是CoRL2023年重量级的工作,将LLM与low-level的动作轨迹生成结合了起来,而且无需任何训练。一作兼通讯作者是黄文龙,“AI教母”李飞飞以及“清华十大学神”之一的吴佳俊也参与了该工作。
- 项目主页:https://voxposer.github.io/
- 论文地址:https://arxiv.org/abs/2307.05973
- 代码地址:https://github.com/huangwl18/VoxPoser
一作黄文龙参加过参与了palm-e系列的工作,是Language models as zero-shot planners的一作,他在b站上有一个相关的访谈:Talk | 斯坦福博士生黄文龙:利用基础模型推动机器人在开放世界中的泛化
本文旨在通俗易懂的介绍Voxposer工作,同时对论文中的难懂的细节给出解释
核心方法

图中给出了任务类型示例
作者着重强调了Voxposer无需任何训练,能接收free-form形式的语言指令,而且能zero-shot,具有良好泛化能力。Voxposer着眼于Low-level级别的底层动作规划,而不是high-level的任务分解和规划
一句话总结:利用LLM的先验知识实现对人类指令的理解,利用视觉定位模型弥补了的LLM的空间能力缺乏,利用LLM的代码能力产生3D value map,给出了三维空间中任务的引导目标(affordance)和限制(constraint),然后交给传统的控制器去求解。
以上三个”利用“牵涉出了三个对应的问题。
一、如何接收形式不限(free-form,open-set)的指令?
以往论文中关注特定的动作种类:push,pull,pick and place,物体类别:articulated objects或deformable objects,但Voxposer可以处理任意给定的语言指令,操作任意物体。作者强调了本工作立足于open-set of instructions,open-set of objects。
这依赖大模型的先验知识能得到很好的实现,需要让大模型把输入的自然语言指令转换成通用的代码,代码调用open-vocabulary detectors(类似CLIP,不用指定目标检测的物体种类集合)产生对应的运动规划。
二、LLM的语言知识在物理世界中的定位(grounding),或者说“对齐”
LLM的预训练数据中是没有物理世界中的数据的,对空间的感知能力依然存疑,直接应用到具身智能中构成了一个gap。
这牵涉到了grounding的概念。LLM grounding 在具身智能中指的是将大型语言模型(LLM)的认知与物理世界的真实情况进行”对齐“,例如:LLM知道需要打开抽屉来完成任务,但不知道抽屉长什么样,更不知道抽屉位于物理世界的什么坐标。grounding可以利用视觉模型(VLM),例如目标检测、三维重建,让LLM给出的答案与物理世界中的物体相对应上。
充分利用LLM的代码能力,写Python 代码调用感知 API(CLIP,目标检测,open-vocabulary detectors),从而让LLM 可以获取相关对象或部分的空间几何信息。
三、如何利用LLM的知识,把语言指令转化为low-level的动作规划,实现zero-shot,减少数据收集和训练?
为了理解给定的指令,机器人需要执行任务分解,把长任务分解成一系列的动作原语,这样的好处在于,机器人只需要着眼于完成每一个相对简单的子任务。
以往利用LLM的工作都着眼于生成high-level的动作规划,然后把一系列low-level的动作交给预定义的动作原语(pre-defined motion primitives)—也就是技能(skills)—来具体执行,由于数据的缺乏,对多种skill的精通构成了一个瓶颈,尤其是模仿学习和强化学习,二者对于数据有强烈的需求。
我们如何在机器人的细粒度(low-level)动作级别利用 LLM 的丰富知识和现有成熟的控制技术,而无需对每个单独的动作原语(primitives)进行费力的数据收集或手动设计?
答案是:使用LLM写代码给出运动的目标和约束的充足信息,使用传统运动规划器求解。
LLM 直接以文本形式输出控制操作是不切实际的,因为实际中的控制需要每一刻都输出一个精细的控制信号,这样一来成本太高、二来LLM的预训练数据中也没有这方面的数据。
Voxposer使用LLM产生的代码绘制一个value map,包含了affordance(可行性,也就是:去哪里?)和constraint(不要去哪里)的信息,从而给出了运动规划的dense指引信息(dense是指经过平滑后,每一个空间点都有指引的信息)。
例如,给定一个指令“打开顶部抽屉并小心花瓶”, LLM 能从中推断:
1) 应抓住顶部抽屉把手,
2) 把手需要向外平移,
3) 机器人应远离花瓶。
抽屉是引导目标,花瓶是限制的区域。二者分别对应于affordances和constraints,前者指的是要接触什么地方,后者是不要接触什么地方
总结一下项目的核心流程:
(1)首先,给定环境信息(用相机采集RGB-D图像)和我们要执行的自然语言指令。
(2)接着,LLM根据自然语言指令编写代码,所生成代码能够调用VLM(视觉语言模型),指导系统生成相应的操作指示信息,即3D Value Map(主要是affordance map和constraint map)。
(3)利用value map使用传统的运动规划器对运动轨迹进行求解
(4)对于下一个子任务,重新执行这一循环
解决什么问题?
给定一个任意(free-form)的开放式的指令,首先将复杂任务分解为一连串的简单子任务序列,这可以通过LLM来完成,但不是工作的重点。
我们关注的是:给定一个简单子任务(指令),环境状态,如何生成一个动作执行轨迹序列?
这个动作轨迹序列是离散的。本工作使用末端执行器的路径点(end-effector waypoints)来表示动作轨迹序列,包含(1)执行器的6D位姿(2)执行器的速度(3)gripper的动作(张开或关闭);当然动作轨迹序列也可以包含关节的角度。
有了动作轨迹序列,交给Operational Space Controller来执行就好了,通过传统的控制技术,生成高频(5Hz)的控制信号。
论文中给出了下面的公式,是上面问题的求解目标:
min τ i r { F t a s k ( T i , ℓ i ) + F c o n t r o l ( τ i r ) } subject to C ( T i ) \min_{\tau_i^r} \left\{ \mathcal{F}_{task}(\mathbf{T}_i, \ell_i) + \mathcal{F}_{control}(\tau_i^r) \right\} \quad \text{subject to} \quad \mathcal{C}(\mathbf{T}_i) minτir{Ftask(Ti,ℓi)+Fcontrol(τir)}subject toC(Ti)
这个公式看着有点累,解释一下:
- i:时刻
- T i \mathbf{T}_i Ti:当前环境状态,本工作中是输入的视觉观察信息
- ℓ i \ell_i ℓi:子任务(语言指令)
- τ i r \tau_i^r τir:生成的动作轨迹序列,共r个路径点
- F t a s k \mathcal{F}_{task} Ftask:优化目标一,指的是任务完成进度。希望每个动作都能最大化的推进任务的进度
- F c o n t r o l \mathcal{F}_{control} Fcontrol:优化目标二:指的是动作执行的成本。希望不要有多余的动作,使用最少的能量。
- subject to C ( T i ) \text{subject to} \quad \mathcal{C}(\mathbf{T}_i) subject toC(Ti):表示必须符合环境的物理约束
那么问题来了,如何定义 F t a s k \mathcal{F}_{task} Ftask和 F c o n t r o l \mathcal{F}_{control} Fcontrol?给定了二者的定义、环境、指令,如何求解动作序列轨迹?分别是接下来两部分的主题。
LLM提供什么样的信息?语言与动作的对齐
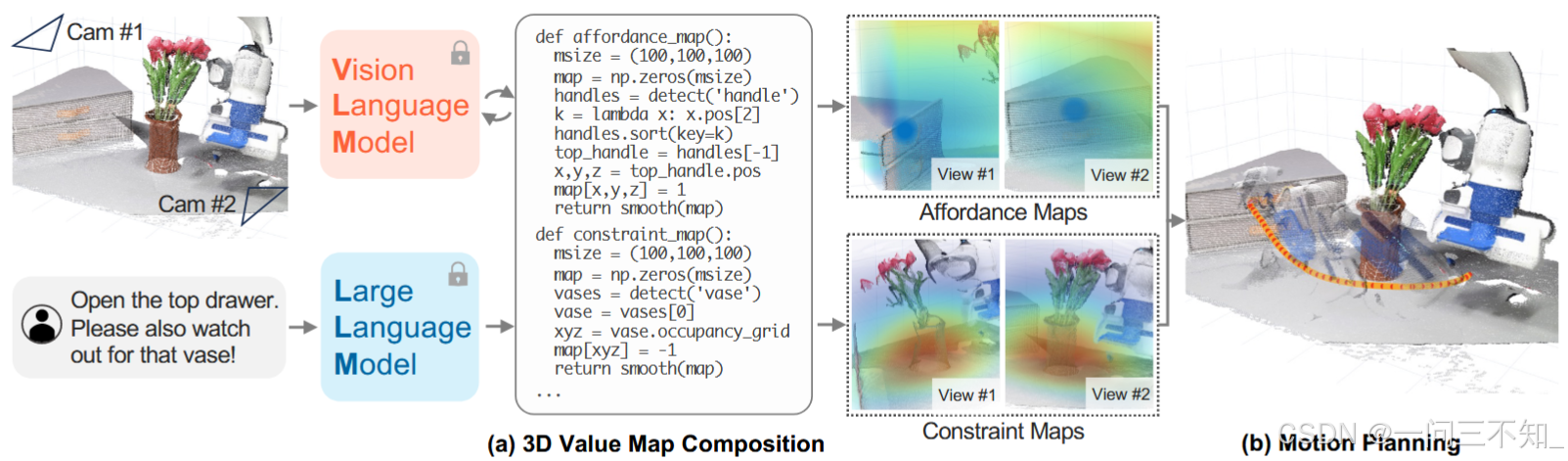
图中的affordance map和constraint map实际上是三维的。图中的蓝色位置表示value高,要接近,红色表示value低,要避开。
如何来定义 F t a s k \mathcal{F}_{task} Ftask?
产生一个voxel value map,也就是一个三维的体素价值图,每一个体素都会被分配到一个value。
对于“打开顶部抽屉并小心花瓶”任务来说,抽屉的value是高的,需要尽量接近;而花瓶的value则是相当低的,需要绕着走。
然后定义一个entity of interest,例如机器人末端执行器、物体或物体的一部分。
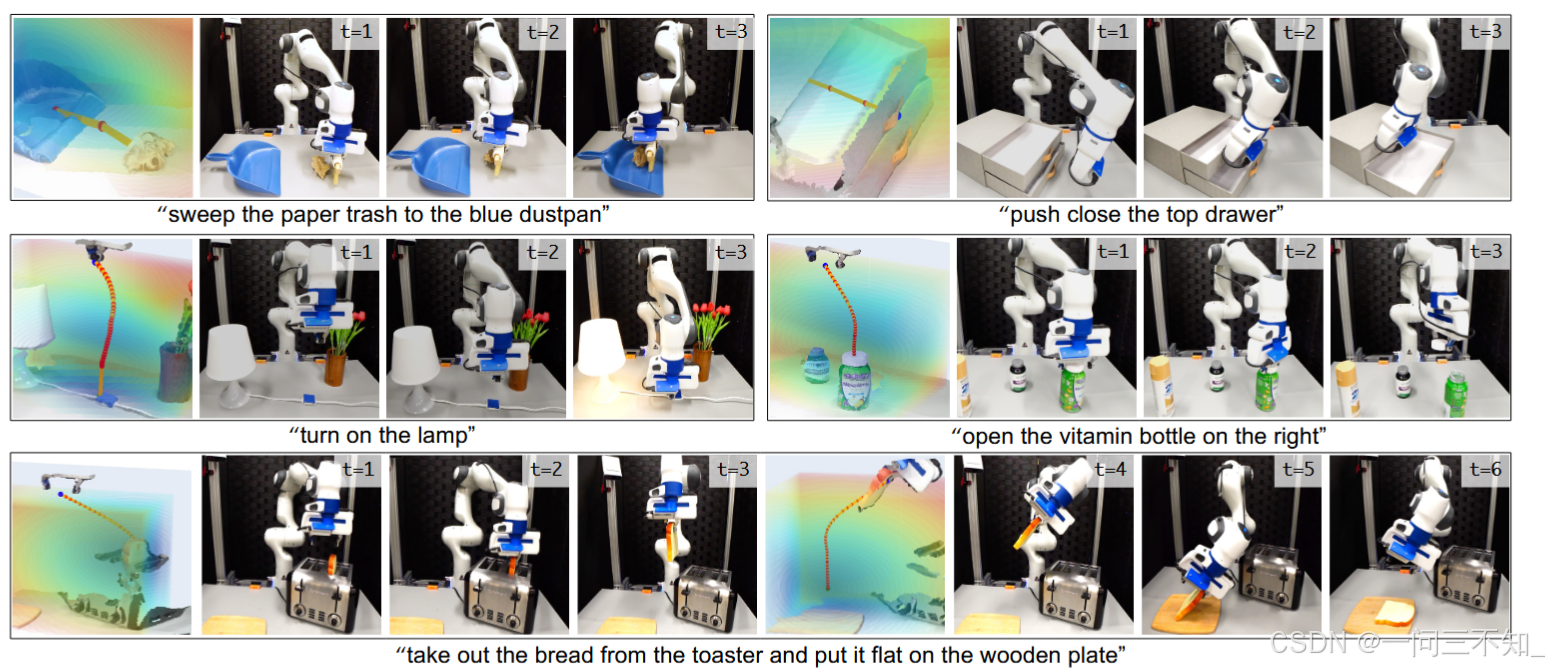
这里的entity of interest听起来不太直观
第一行的entity of interest是物体:因为需要移动垃圾到簸箕中,垃圾是移动的
第二、三行的entity of interest是机器人末端执行器:因为需要移动机器人的end-effector,目标对象如:”灯“”瓶子“”面包“都是固定的。可以看到图中产生了一连串红线,用来引导轨迹规划
我们如此定义 F t a s k \mathcal{F}_{task} Ftask:
F t a s k = − ∑ j = 1 ∣ τ i e ∣ V ( p j e ) \mathcal{F}_{task} = - \sum_{j=1}^{\left| \tau_i^e \right|} \mathbf{V}(p_j^e) Ftask=−∑j=1∣τie∣V(pje)
- e:entity of interest
- V:voxel value map,体素价值图,每个体素都有一个value分数
- p:表示entity of interest的三维坐标
这个公式表示对每个时刻(轨迹点)的entity of interest的所在点进行value分数求和。
希望最小化 F t a s k \mathcal{F}_{task} Ftask,也就是尽量让e接近高分数的区域。
那么问题来了:如何产生一个voxel value map?
可以prompt LLM 进行如下顺序的操作,参考本节第一张图的代码。
1) 调用感知 API(调用视觉语言模型 (VLM),例如开放词汇检测器获取相关对象的空间几何信息)。函数示例为:vases=detect(vase)
2) 生成 NumPy 操作来操作 3D 数组
3) 在相关位置指定精确值。例如:map[xyz]=1
这个方法被称为Voxposer
由于一般代码中都是在某个点指定精确值, voxel value map通常是稀疏的,因此我们通过平滑操作来增密体素贴图。这鼓励运动规划器优化更平滑的轨迹。
动作轨迹的规划与执行
现在我们有了value map,也就是给出了任务执行的目标和限制,但是还没有动作执行的路径点,接下来使用传统的控制技术求解。
作者使用简单的零阶优化,通过随机采样轨迹并使用上面提出的优化目标对其进行评分。迭代式的求解运动规划。
作者发现,Voxposer具有良好的抵抗外部干扰能力,这是因为在轨迹合成过程中,代码可以保存下来。如果物体的位置被人为的改变,voxel value map的数据变的不符合现实;重新执行目标定位、生成voxel value map之后,voxel value map的数据又重新符合现实。这构成了闭环反馈控制。
online learning
之前我们实现了zero-shot,现在考虑稍加训练增强模型的表现。
MPC(模型预测控制)是一种基于模型的控制策略,它通过预测系统未来行为并优化控制动作来实现精确的过程控制。
可以使用MPC来进行对环境的建模和预测,流程如下:
- 收集 ( o t , a t , o t + 1 ) (o_t, a_t, o_{t+1}) (ot,at,ot+1)数据对, a t = M P C ( o t ) a_t=MPC(o_t) at=MPC(ot),MPC根据观察产生了策略
- 训练一个动态的模型来预测下一个状态的信息,损失函数是预测的误差。从而更好的对环境建模
MPC中的采样分布 P ( a t ∣ o t ) P (a_t|o_t) P(at∣ot)对于训练效率至关重要。实践中,对于“open the door”这样的任务,门上的大部分位置都是对任务完成没有帮助的,因此只需要关注门把手;对于门把手,大部分方向的动作也都没有用,只有”向下按压“的动作才是有效的。
利用LLM提供的先验知识,能大大提高采样有效样本的过程,促进学习的效率。具体实施的流程是:先使用预设的路径点作为探索的先验知识,向每个路径点添加少量噪声以促进局部探索。
实验
具体实现:
- LLMs and Prompting:使用GPT-4生成代码,prompt中包含5-20个例子
- VLMs and Perception:输入观察的图片,使用LLM给定的物体类别,使用OWL-ViT获取bounding box,然后使用SAM提取mask,最后使用video tracker XMEM追踪物体的mask部分,得到一系列的mask图像。然后使用RGB-D的信息,将二维的mask图像部分转换为三维的点云信息。
- Value Map的组成:
- affordance
- avoidance
- end-effector velocity
- end-effector rotation
- gripper action
运动规划器:只考虑affordance map和avoidance map,使用贪心策略,得到一系列运动轨迹。然后把end-effector velocity, end-effector rotation, gripper action等信息映射到每一个轨迹点上。
配置
Operational Space Controller作为控制器
SAPIEN仿真环境
Franka Emika Panda robot
RGB-D cameras (Azure Kinect)
加入干扰来验证闭环控制的能力
总结
相当于LLM把自然语言指令变成了运动学的约束(constraint)和目标(affordance),然后交给motion planner求解。
作者着重强调了Voxposer无需任何训练,能接收free-form形式的指令,而且能zero-shot。
巧妙的地方在于把视觉模型工具和语言模型生成代码的能力结合了起来,弥补了LLM缺乏空间感的不足。利用value map避免了对运动轨迹的直接生成,兼具了传统控制的优势。同时能够多次执行代码,重新对物体定位,闭环式执行任务。
limitation
- 它依赖于外部感知模块的精度,对细粒度的操作效果不好。如果value map给的不精准(三维空间定位出了偏差很正常),导致motion planner难以完成任务
- 虽然适用于高效的动力学学习,但仍然需要一个通用的动力学模型来实现具有相同泛化水平的contact-rich的任务。换句话说就是依赖motion planner
- 仅考虑末端执行器轨迹,但考虑全身的关节似乎是更好的选择
- 可以开发更先进的轨迹优化方法,以最佳方式与 VoxPoser 合成的value-map接口
- 手工prompting复杂
- 调用GPT-4本来就慢,更何况每一个sub-task都要进行好几次API调用
参考
https://zhuanlan.zhihu.com/p/651670658
https://blog.youkuaiyun.com/weixin_41896770/article/details/132003290

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









