



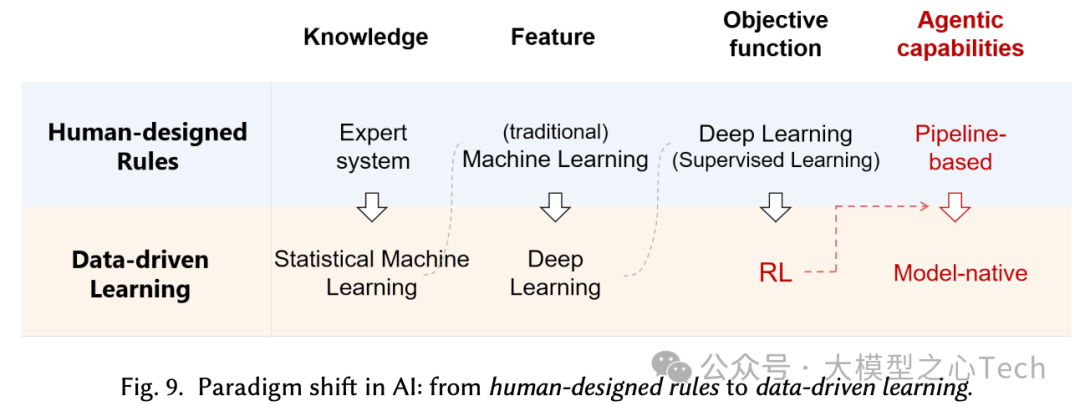
Agentic AI正从外部流水线转向模型原生,推理、记忆与行动等能力被内化到模型策略中,借助强化学习把感知与行动打通,让静态模型变成可从环境互动中学习的目标驱动体。LLM + RL + Task 正在成为现代AI的“方法论奇点”,通过预训练→后训练→推理的循环,把算力持续转化为智能。未来不仅是更高自治,更是模型与环境深度耦合/共生;这种范式迁移也意味着从“构建会用智力的系统”走向“通过经验自进化的智能”。
论文标题:Beyond Pipelines: A Survey of the Paradigm Shift toward Model-Native Agentic AI
论文链接:https://arxiv.org/abs/2510.16720v1
问题背景
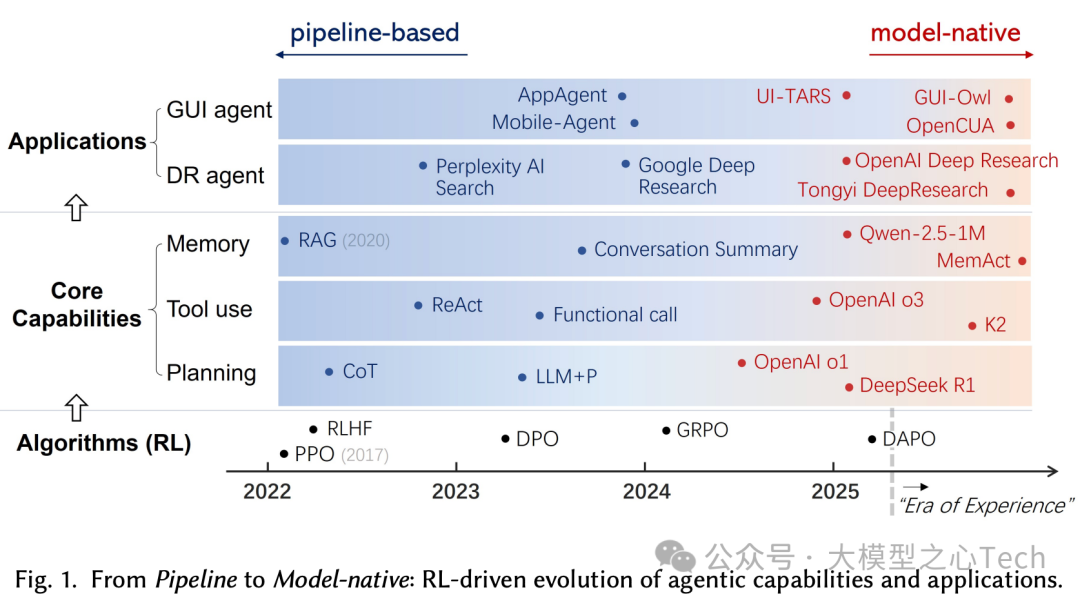
生成式AI进步迅猛,但多为“反应式输出”,缺乏面向目标的长期推理与环境交互;为迈向自主行动,研究焦点转到“智能体AI(agentic AI)”,其三大核心能力是规划、工具使用、记忆。
早期系统是流水线范式(Pipeline-based),这三大能力被放在外部编排里:规划依赖符号规划或CoT/ToT提示,工具使用依赖函数调用与ReAct式思维-行动回路,记忆依赖会话摘要与RAG;因此模型是被动组件,系统脆弱且难以应对非预期情境。
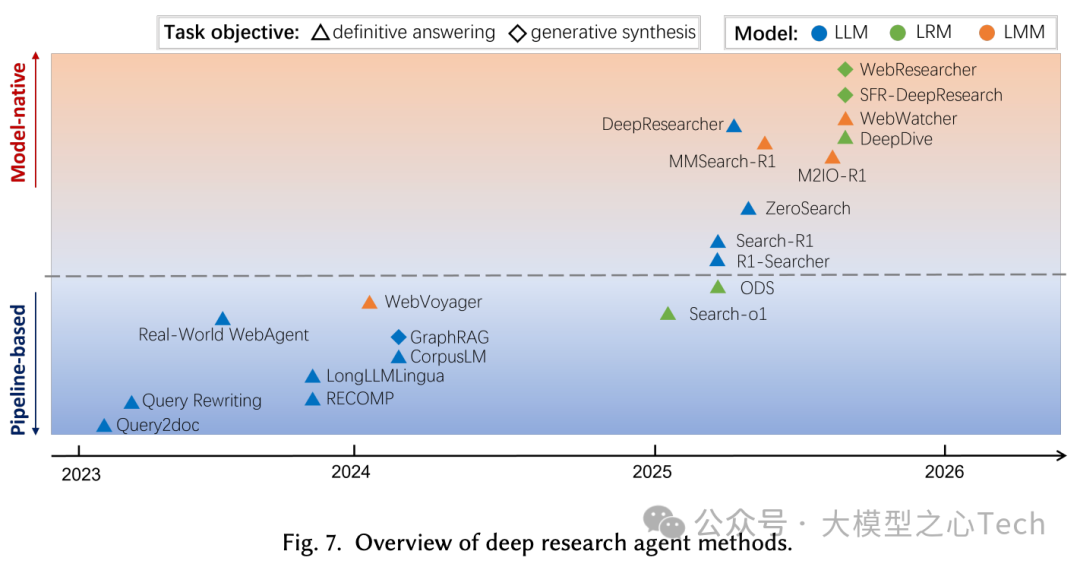
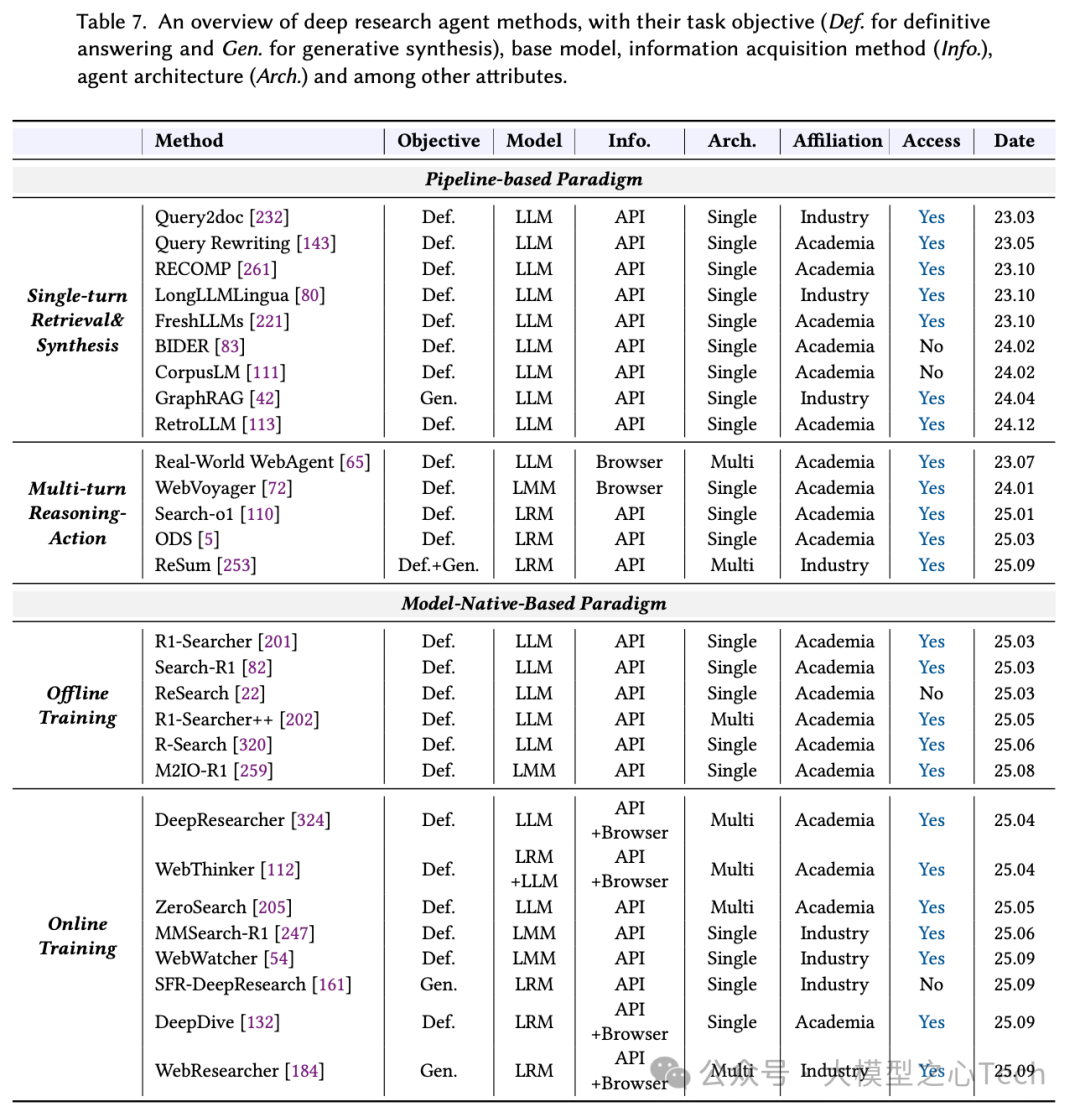
新范式模型原生则强调通过端到端训练把规划、工具使用与记忆内化进模型参数,让LLM成为主动决策者。这种范式转变的核心驱动力正是大规模强化学习(RL)用于LLM训练,使得从“SFT/偏好优化”转向结果驱动的RL(如GRPO、DAPO等),从而形成了统一训练图景“LLM + RL + Task”。目前,智能体应用沿着两条主要路线发展:(1)Deep Research智能体,它充当“大脑”,擅长复杂的推理和分析;(2)GUI智能体,它充当“眼睛和手”,模拟人类与图形环境的交互。
面向LLM 的 RL
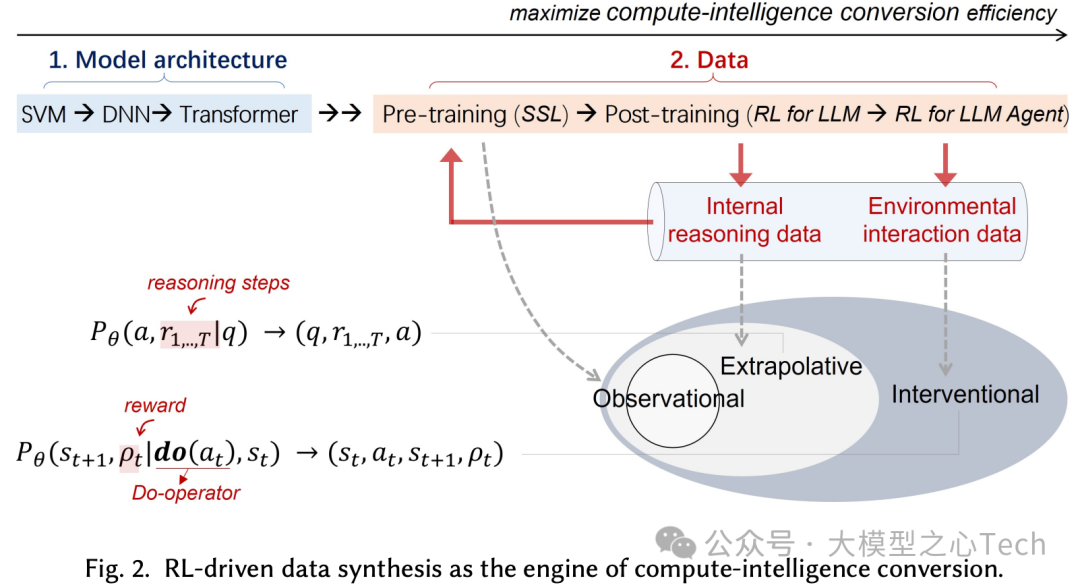
因程序化数据稀缺与 Out-of-Distribution (OOD) 脆弱,必须用结果驱动的 RL把规划等能力从提示诱导转为参数内化;借助 LLM 先验与语言统一接口,RL 成为训练模型原生代理的可行且通用的“LLM + RL + Task”范式。
1. 为什么必须用 RL
CoT 等流水线只是把“步骤”塞进提示里,诱导模型模仿程序化模式,但并未让参数学会过程本身,易在分布外场景失效。
要把“规划”等能力内化进模型,需要直接优化参数:将答案视作对所有潜在推理轨迹的边缘化,目标变为同时学到 奖励和动作;SFT 受制于( q,R,a )轨迹数据稀缺与昂贵,RL 则用结果驱动的奖励直接优化整条推理轨迹 。
相比 SFT,RL 的两大优势:动态探索式采样与相对价值学习,把模型从“被动模仿者”变成“主动探索者”。
2. 为什么可行
预训练 LLM 自带世界知识与结构先验,可进行先验引导的探索,显著提高样本效率;形式化为在知识条件 下优化期望回报。
语言介面把状态、动作、奖励统一到文本/符号空间:动作可为文本、工具调用或 GUI 操作,奖励可为事实正确性、偏好或可编程验证,从而让 RL 跨任务泛化,成为内化代理能力的通用机制。
3. 统一范式与算法演进
一方面,早期 RLHF擅长单轮对齐,但不适合长程、多轮与稀疏奖励;后续出现 GRPO、DAPO 等结果驱动 RL以提升长程训练稳定性与效率;另一方面,以基础模型提供先验,学习算法(RL/偏好优化)在任务环境中通过交互与奖励精炼能力。
核心能力:规划
流水线范式两类路线:
符号规划系(LLM+P/LLM+PDDL):LLM 生成PDDL等形式化描述,交由外部规划器求解;闭域强、跨域与鲁棒性受限。 Beyond Pipelines A Survey of th…
提示工程系(CoT/ToT 等):将规划当作序列生成;分线性(逐步CoT)与非线性(ToT、LLM+MCTS、RAP等)两类,后者引入搜索与评估但计算开销大、依赖外部评估质量
把规划视为从初始状态到目标状态的自动化推理与行动序列搜索;传统符号规划可解释但重建模、跨域差。提示/管线对设计高度敏感、在复杂任务下不稳定、Token/算力成本高,难以充分发挥模型潜能。
模型原生范式通过监督学习与强化学习把规划能力直接内化到参数中,摆脱外部搜索器/评估器,提升开放环境下的灵活性与稳健性。
监督学习:依赖高质量过程数据;因程序化数据稀缺,主攻两条路——数据合成(多路径采样、MCTS/过程奖励等)与数据蒸馏(强推理教师→学生),以低人工成本扩充高质长链路推理数据。
强化学习:通过结果驱动的轨迹奖励直接优化规划策略,弥补离线监督不足。
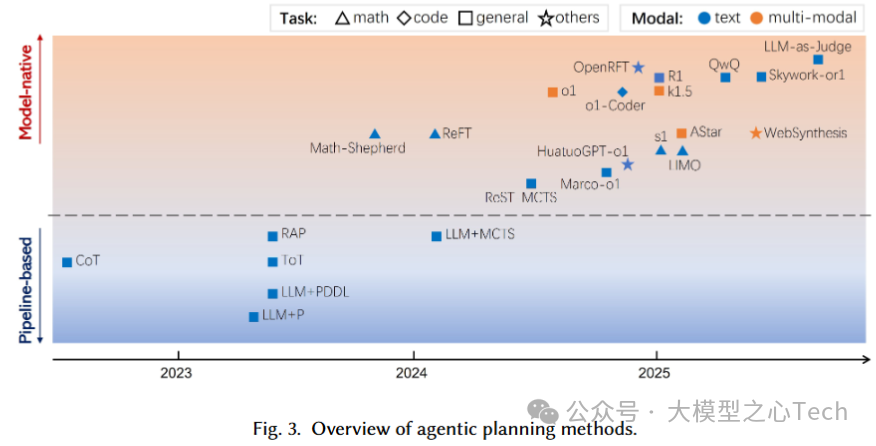
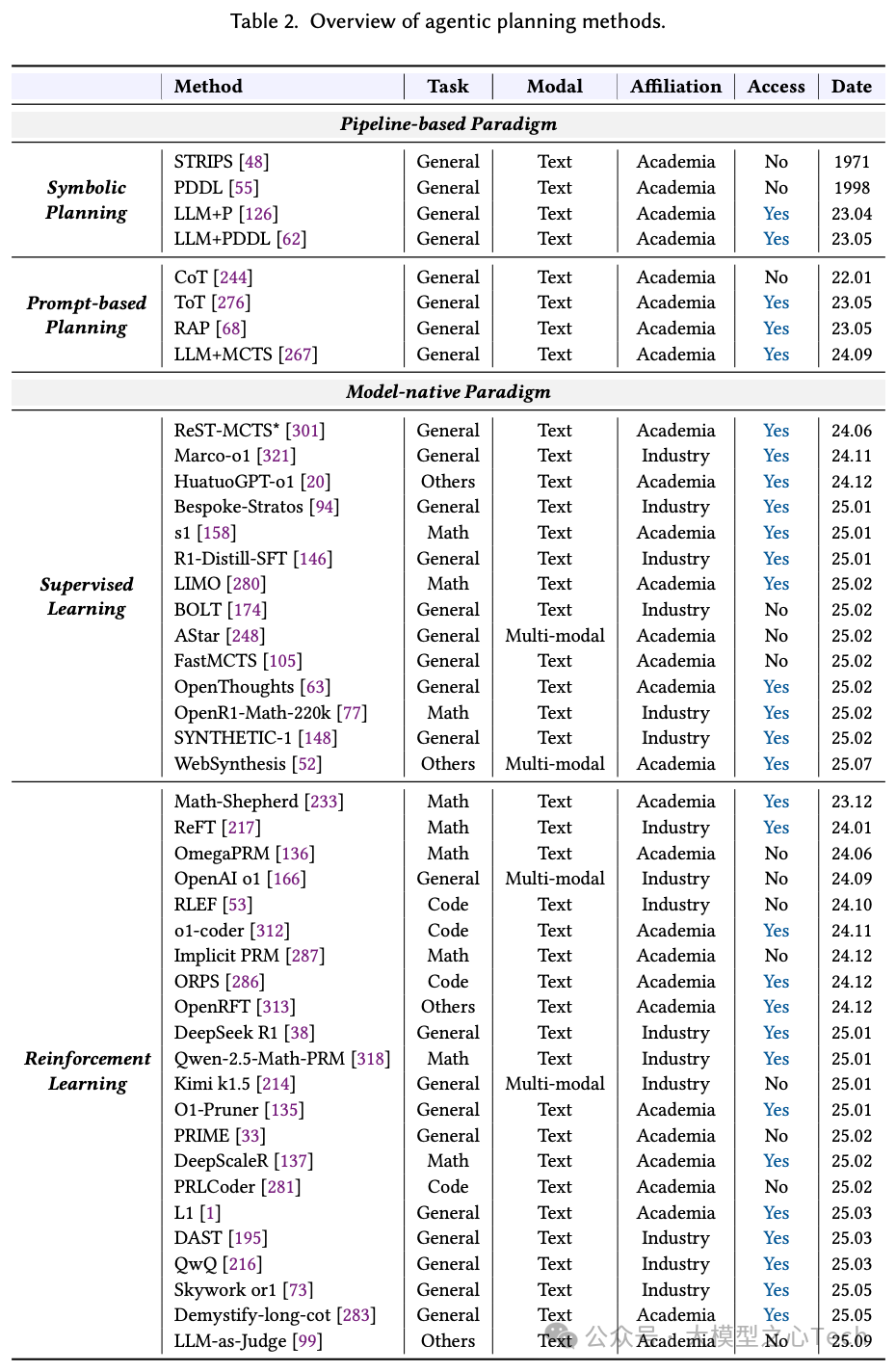
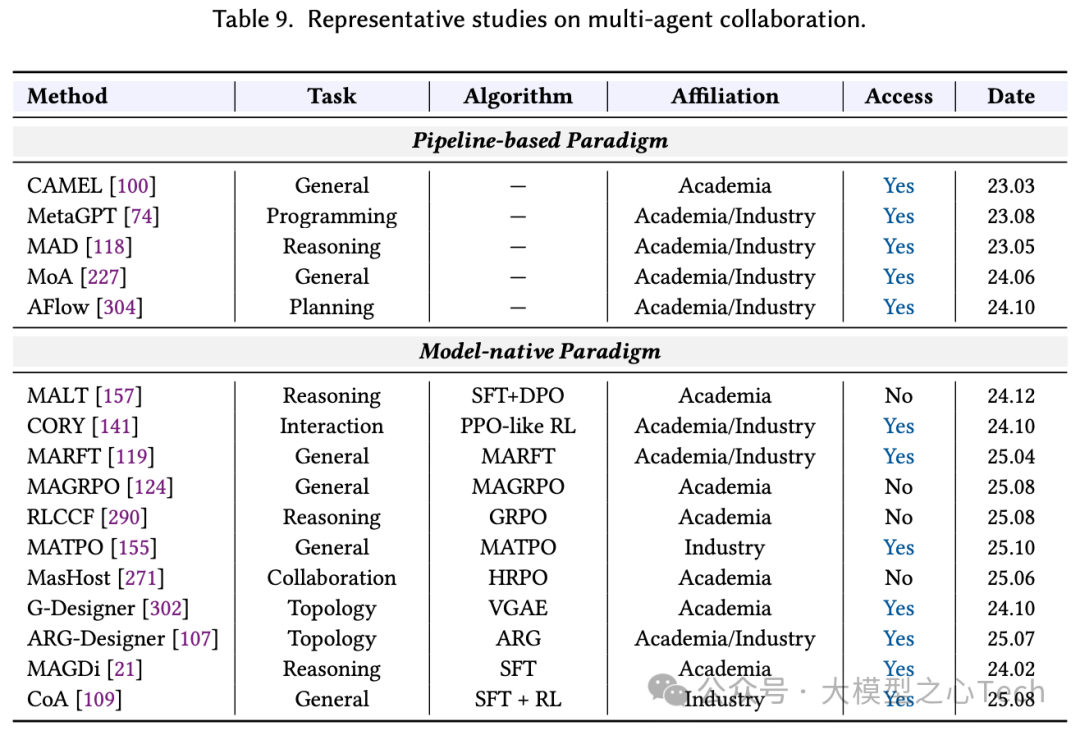
总得来说,模型原生规划实现了两次关键迁移,一种是训练方式从SFT转向RL,以缓解高质量过程数据稀缺与成本高的问题;另一种是,在RL内部从“过程奖励”转向“结果奖励”,并常结合格式等规则型奖励以稳定优化。这一演进不只发生在语言规划上,多模态也从外接视觉工具/提示链过渡到端到端训练,实现“所见即所思”的原生感知-推理。下图表展示了两种范式的代表性研究:
核心能力:工具使用
工具使用包括两层:1. 行动层面的计划:何时、按什么顺序调用哪些工具,并随反馈调整);2. 执行:生成语法正确的调用命令并与环境交互。
早期系统工作流把模型嵌在固定节点,虽然可预测但缺乏灵活性,而提示法把决策逻辑写进提示里,分为先计划后执行与计划-执行交替,后者虽然更适应动态反馈,但计算开销与依赖评估质量更高。
模型原生迁移把工具使用的决策内化到参数中,沿“计划/执行”两层形成两类训练路线:1.模块化训练:只优化小型可训练规划器,执行由模板/冻结模型承担,以减轻信用分配噪声、提升样本效率与稳定性;2. 端到端训练:统一目标下同时学计划与执行),其核心难点在跨步信用分配(轨迹级 vs. 步级)与环境噪声(静态/模拟 vs. 动态/真实)。
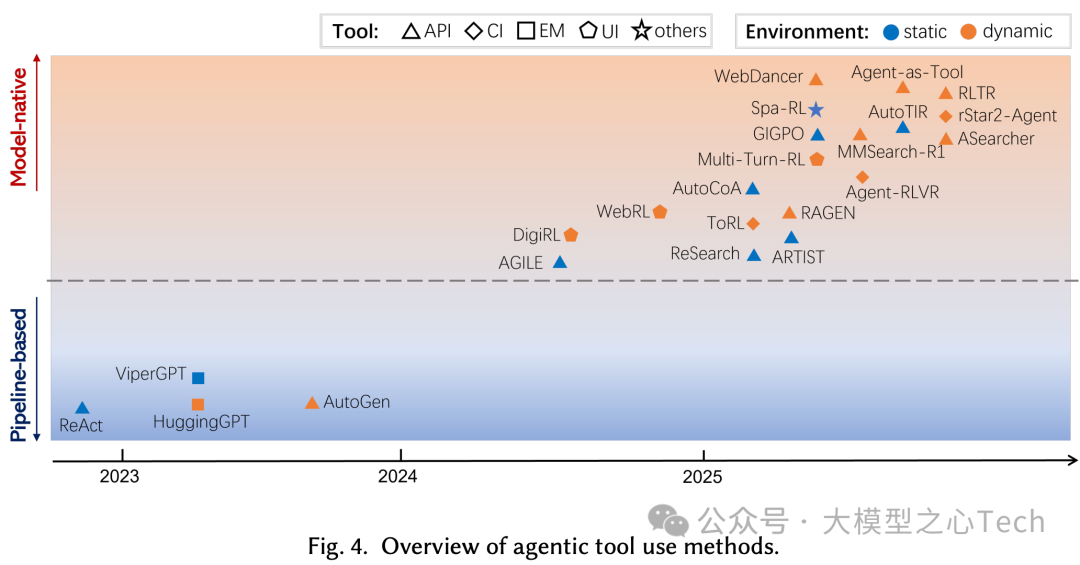
工具使用从外部编排的流水线走向模型原生,不再依赖预设流程,而是把“何时/如何用哪个工具”的计划层与“正确调用并读懂反馈”的执行层一起内化为模型的多目标决策问题。然而,目前还存在两大挑战待解决,1. 信用分配:如何把最终结果可靠归因到长动作序列中的具体决策步;2. 环境噪声:工具超时、返回不一致、内容动态等使训练不稳定。
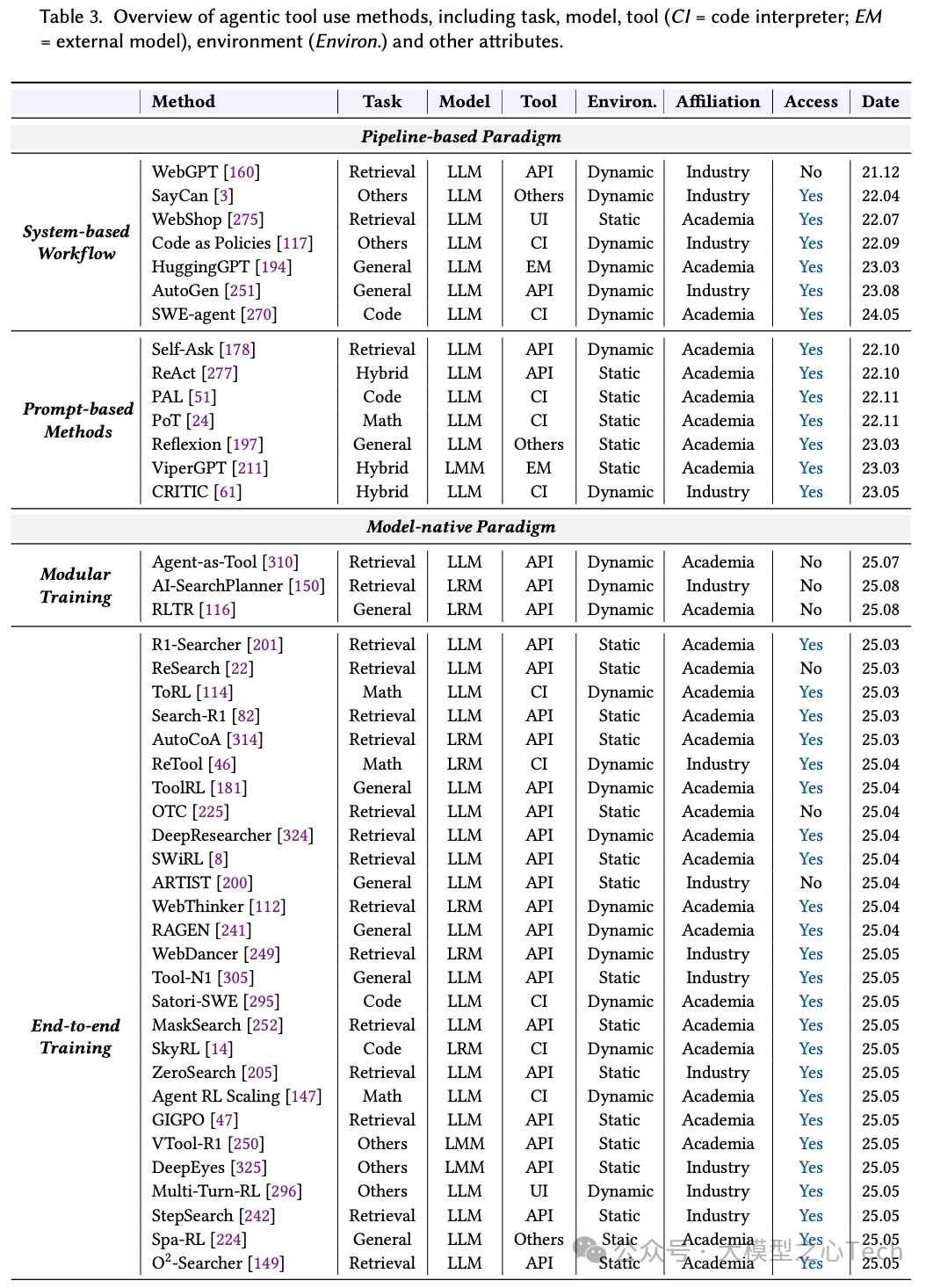
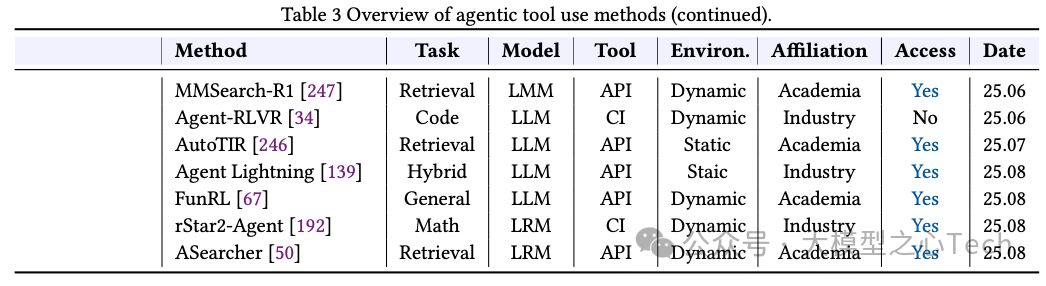
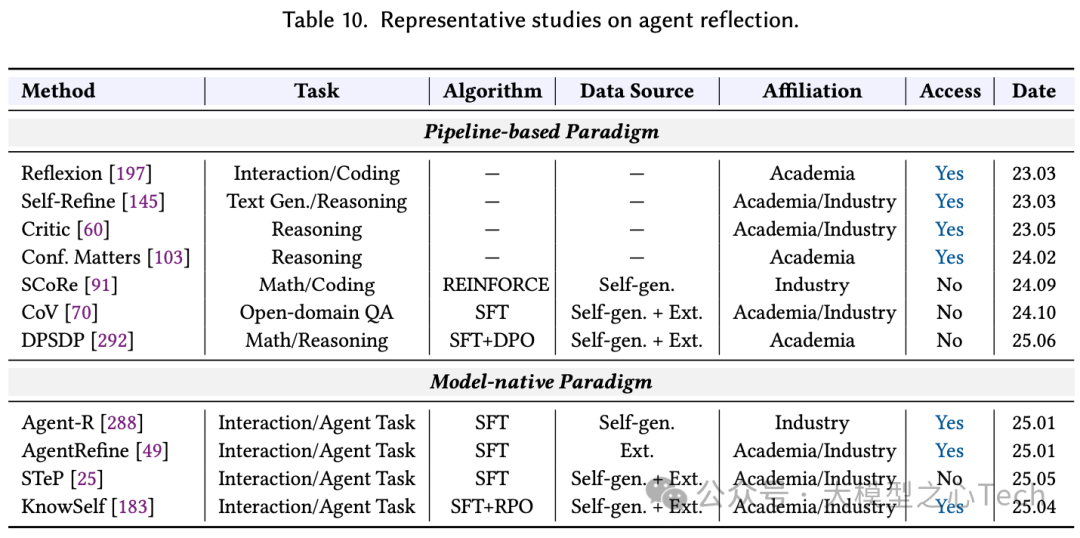
通过回归“模块化训练”,将规划器与执行器解耦,只优化规划器,以隔离执行噪声、提升样本效率与稳定性。一方面,端到端细化奖励,将轨迹级转向步/轮级信用分配,使学习信号更对齐有效动作、稳定训练。另一方面,训练环境由静态/模拟环境走向动态真实环境,可以缩小“仿真到现实”差距。下表展示了工具使用的代表型代理研究:
核心能力:记忆
记忆从单一外部模块提升为贯穿任务全周期的能力,文中提出记忆是“面向行动的证据治理”,将流程拆为写入/存储、管理/压缩、检索、利用四职能。
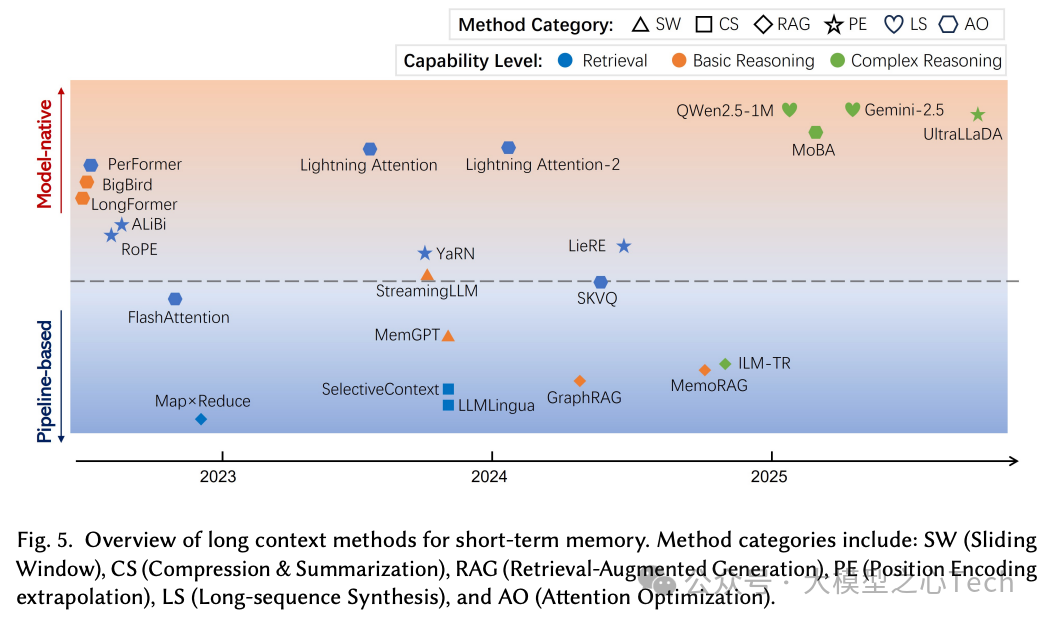
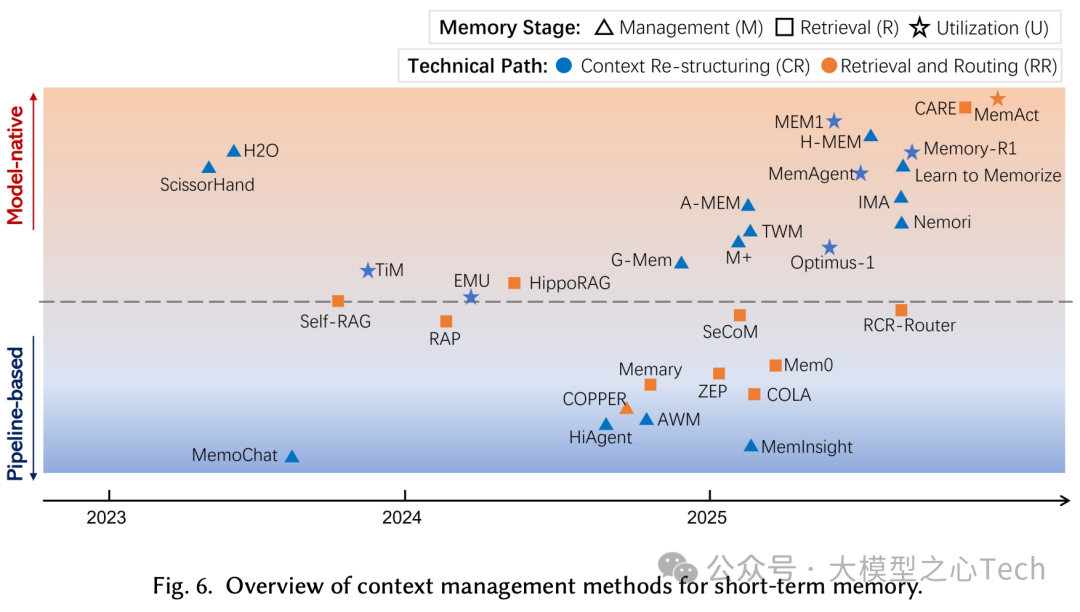
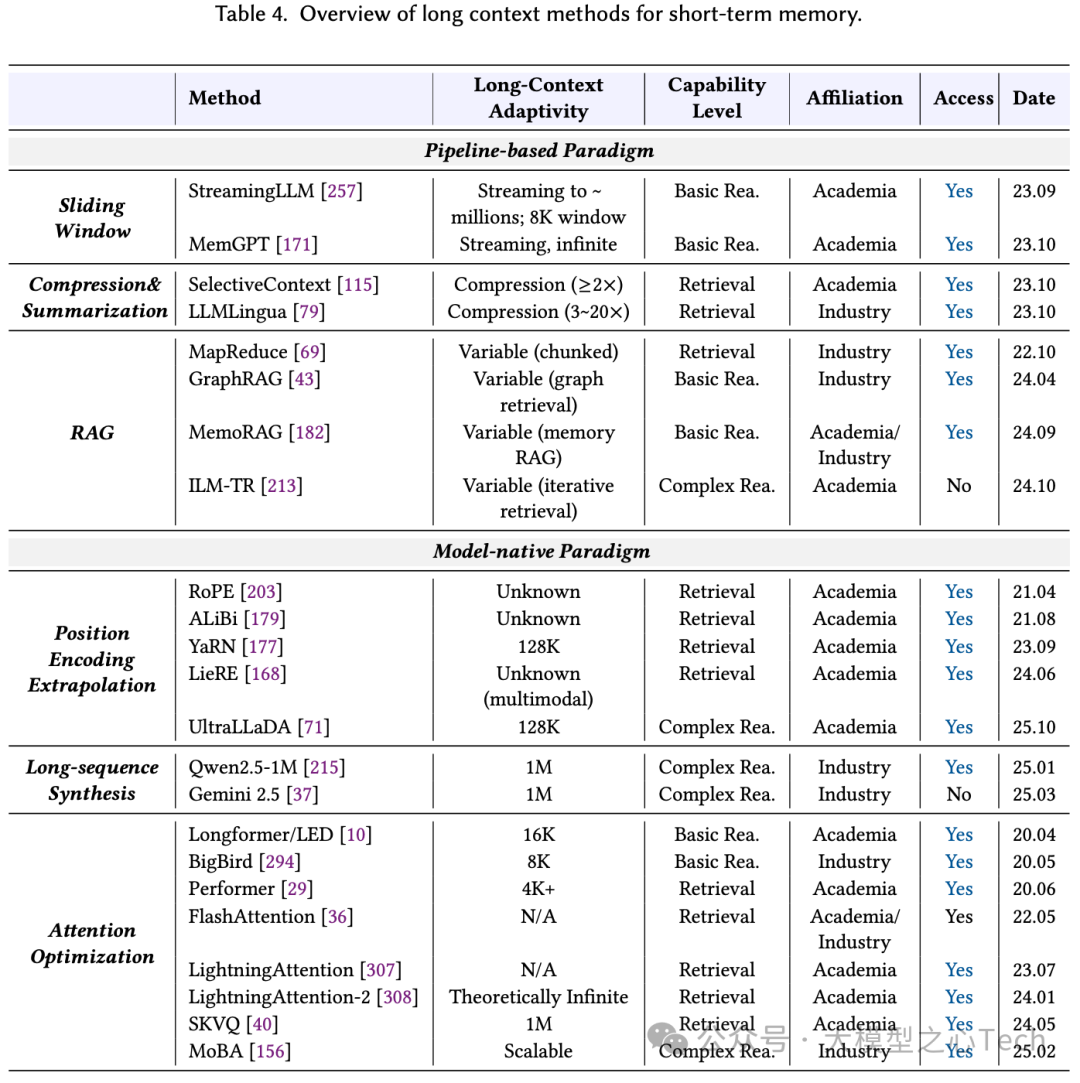
短期记忆(会话内):流水线范式通过滑动窗口、压缩/摘要(证据卡+可回溯锚点)、RAG(会话感知、多路径重排),长窗与会话RAG常互补使用以控噪。模型原生范式则通过位置编码外推+长序列合成/课程训练(针堆检索、跨文档推理)+注意力优化,把长上下文从工程管线过渡到端到端能力。
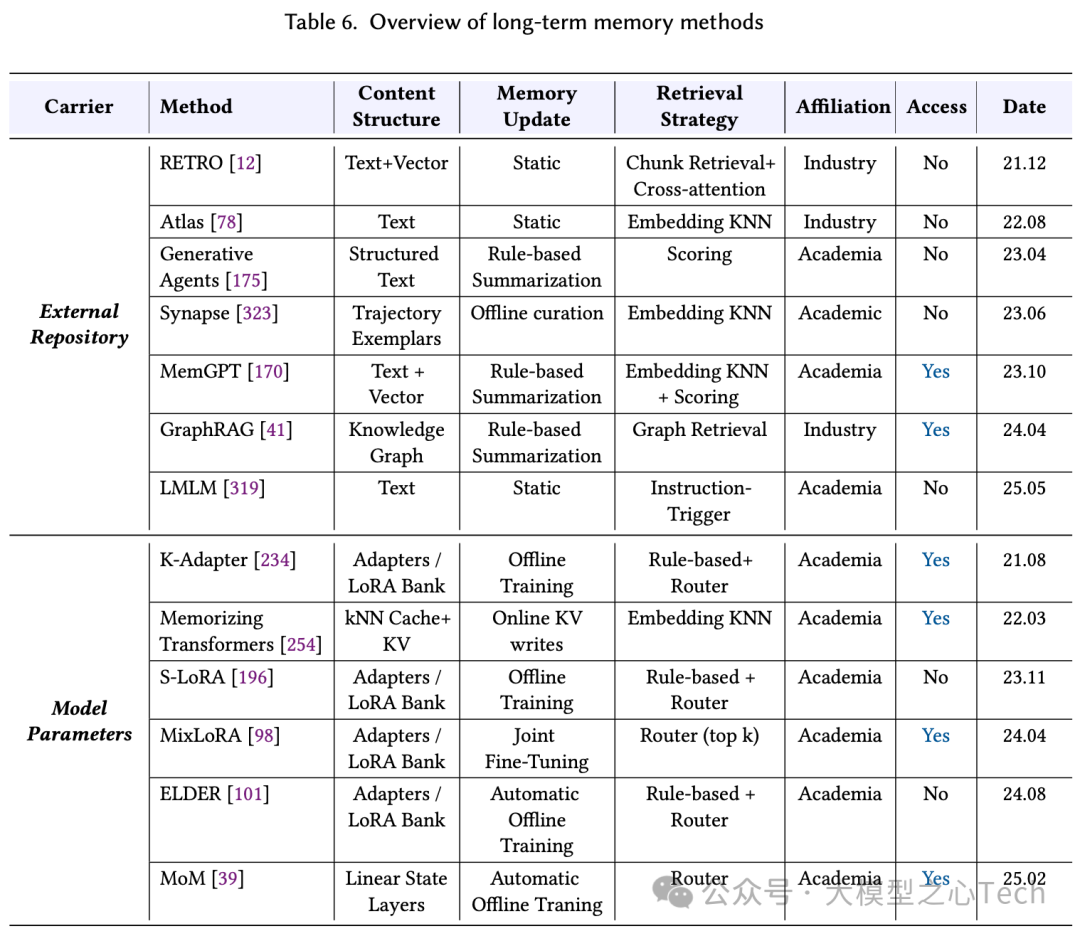
长期记忆(跨会话):一种以外部库为载体,使用混合索引、重排、去重与一致性检查,强调可追溯;关键在精确检索与可靠使用。另一种以参数为载体:持续预训练/蒸馏做全局内化;或做定点编辑与轻量注入(适配器/LoRA/线性状态层),在延迟与可解释性间权衡。
总的来说,记忆从外部模块转向“面向行动的证据治理”的模型原生能力,负责保存状态、检索与将证据注入推理流程,短期记忆的转变尤为明显。而当前瓶颈在长序列数据合成与课程设计,未来应显式训练检索、压缩、校验等操作,外部向量库等将退居后台合规/持久存储。许多基础技术先扩了短期记忆能力,从而在工程上RAG成了默认基线。当前的趋势是把已验证的管线功能逐步内化,并推动短期—长期记忆的统一、检索与生成的联合训练与个性化治理。下表总结了短期记忆和长期记忆的典型方法:
应用
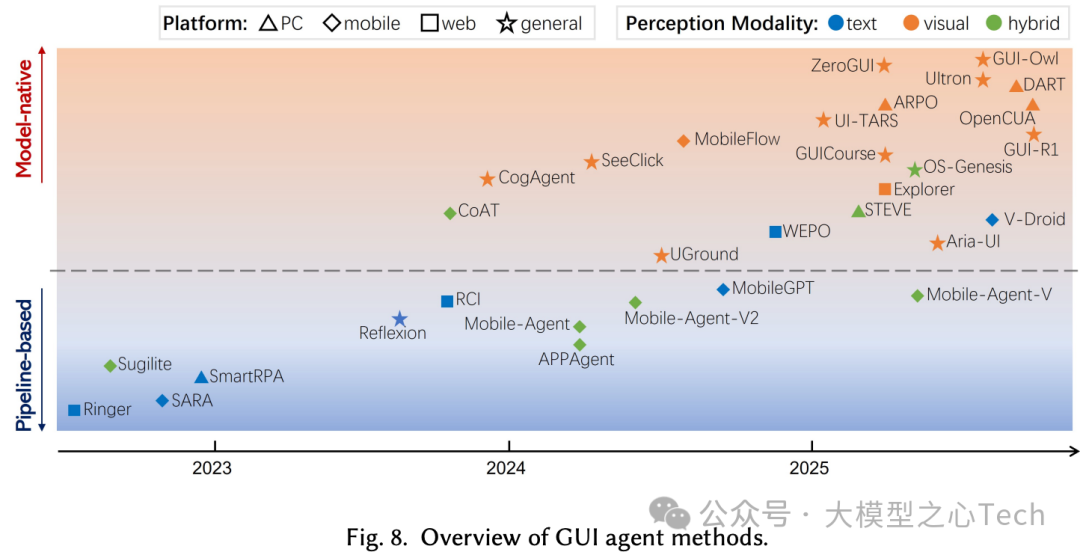
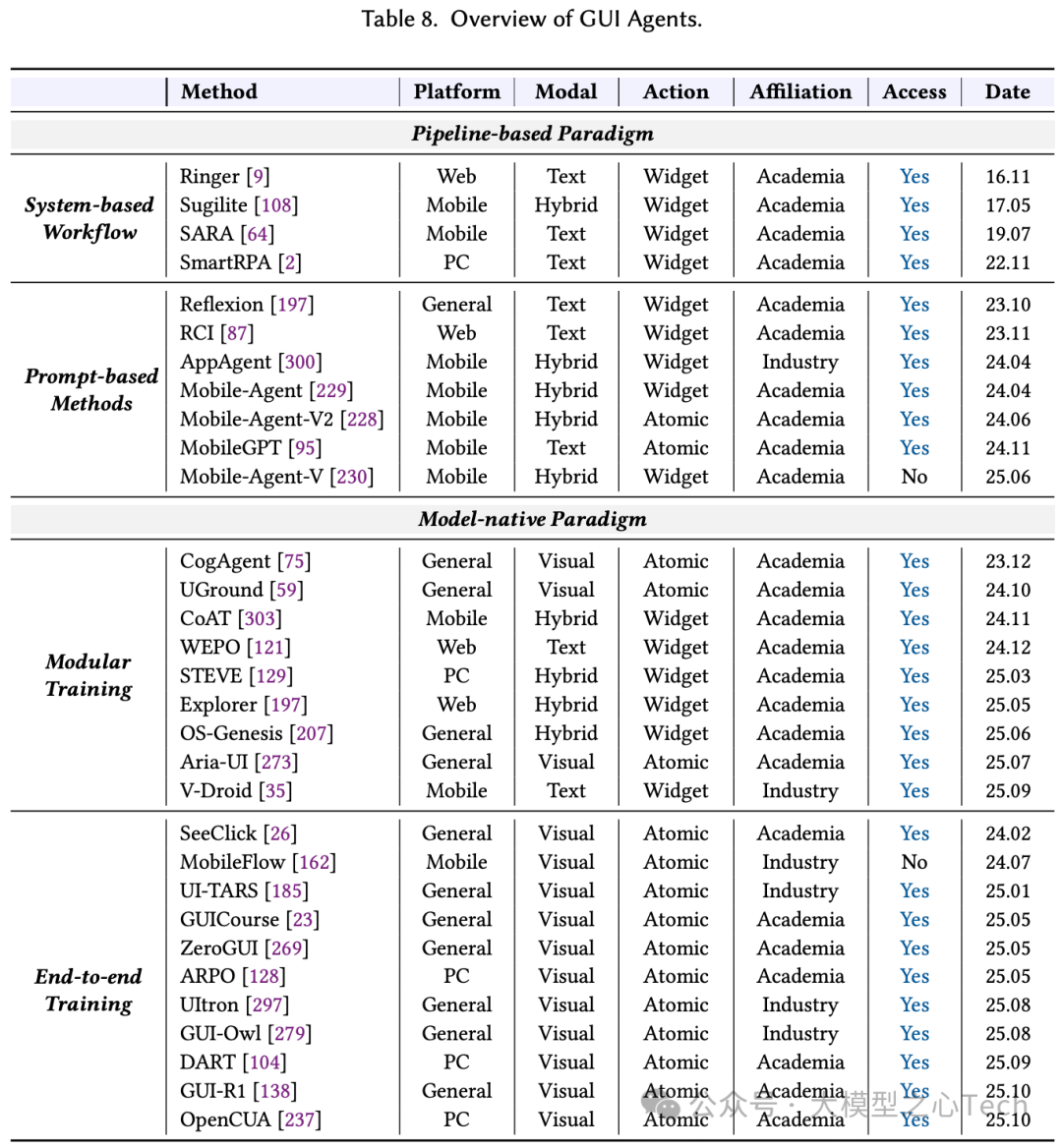
未来方向
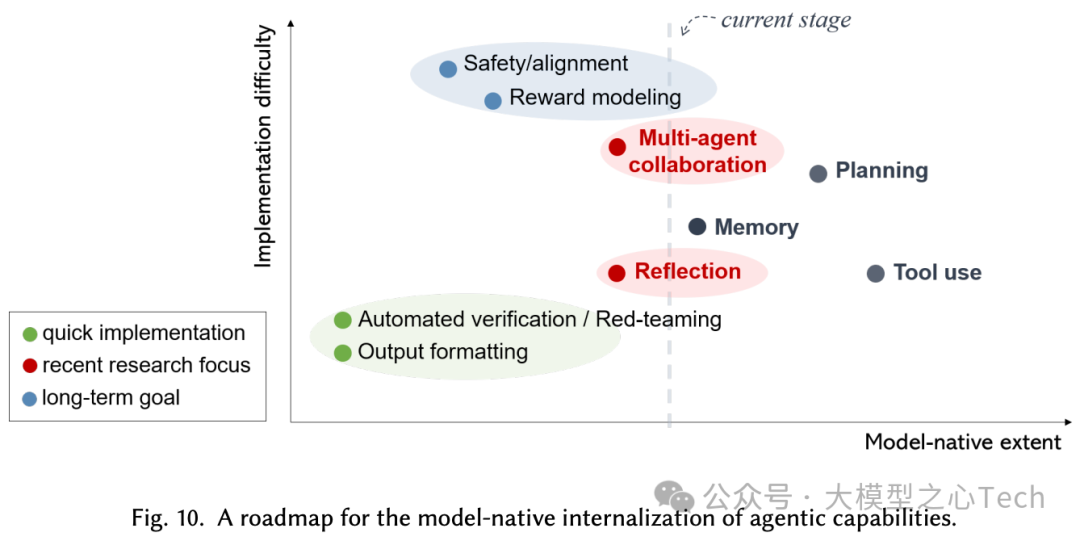
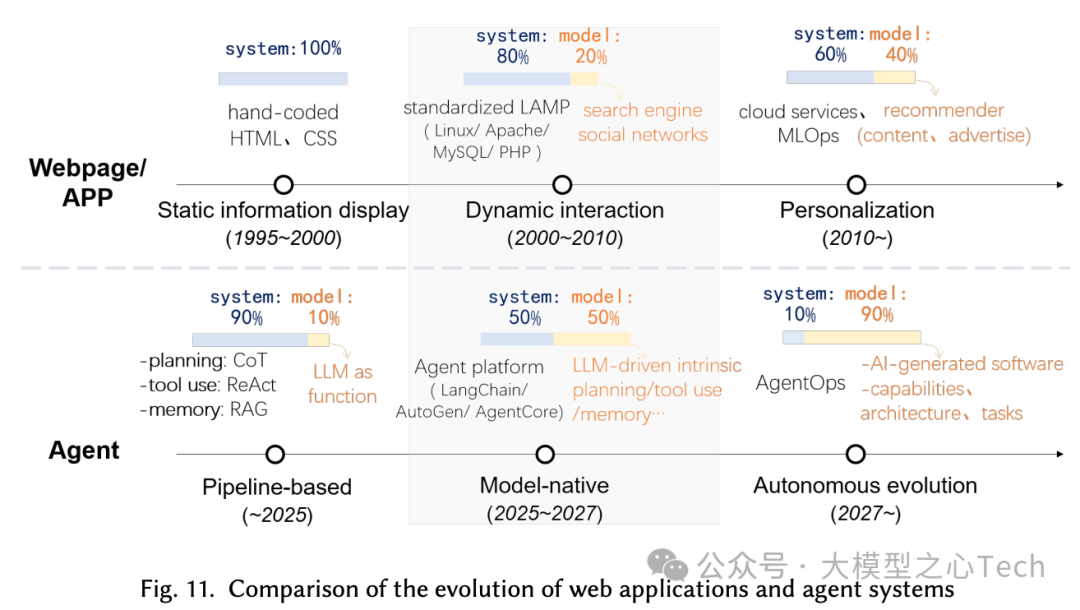
总结
Agentic AI的演变反映了智能本身如何被构想、训练和部署的更深层次的转变。从基于管道的系统(推理、记忆和行动由外部支架协调)到将这些能力内化的本地范式模型,我们正在见证Agentic AI的根本性重新定义。强化学习作为经验的引擎,连接感知和行动,将静态模型转变为能够从与环境的交互中学习的自适应、目标导向的实体。
通过这项调查,我们回顾了计划、工具使用和记忆是如何逐渐被吸收到模型的内在策略中的。统一原则𝐿𝐿𝑀 +𝑅𝐿+𝑇𝑎𝑠𝑘 正在成为现代人工智能的方法论奇点。该框架通过预训练、后训练和推理的循环将计算转化为智能。
最终,Agentic AI的发展轨迹不仅仅是朝着更大的自主性发展,而是朝着模型与其所处环境之间更深入的综合发展。因此,从外部管道到模型原生的范式转变标志着从构建使用智能的系统到增长智能的系统的转变。人工智能的下一个时代将不再由我们如何设计代理来定义,而更多地由我们如何使它们通过经验学习、协作和进化来定义。


















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









