



晚上的时候看到了晚点团队采访蔚来任少卿的文章,把里面关于VLA和WA的观点提炼出来分享给大家。
晚点团队原文链接:任少卿的智驾非共识:世界模型、长时序智能体与 “变态” 工程主义
任少卿认为智能驾驶真正的上限在世界模型,即以视频为核心,通过跨模态的互相预测和重建,让系统学习时空和物理规律,再叠加语言层去交互与注入知识,让机器能像人一样理解环境。
世界模型解决的是时空认知,语言模型解决的是概念认知。语言模型低带宽和稀疏性无法真正有效的建模真实世界的四维时空(时间+空间)。
世界模型的认知包含两个层面:
物理规律的内建:比如重力、惯性、速度变化,这些规律必须在模型内部形成;
时空操作能力:能理解和预测物体在三维空间 + 时间维度的运动,比如车辆绕行、机器人搬运。
但VLA本质还是语言模型的模态扩展。 这些扩展虽然加入了新模态,但 “根” 依然在语言模型上。它像是在原有的语言体系上不断 “加模态”。
但世界模型不是 “语言加法”,而是要建立一套高带宽的认知系统。因为语言通道的带宽太低了。人类如果没有眼睛,只靠嘴和耳朵交流,效率会有多低?眼睛带来的视觉带宽就大得多。世界模型要直接在视频端建立能力,而不是先转成语言。
现在的智驾系统,你和它的交互都还是闭集的。而自动驾驶的终极目标是通过 Open-set(开放集指令交互) 智能引擎实现真正的开放式交互。所谓 Open-set,就是把 L(语言)和 A(动作)彻底变成开放的:用户不再局限于输入有限的指令集,而是能够随意表达,系统也都能正确理解并执行。
从有限集到无限集——这才是语言加进去的终极意义。只是这一步我们还没做到。
本质上华为做的是世界模型,只是强调点不同。蔚来去年七月份之前就提过世界模型这个概念。
VLA、WA 这些名字,更多是表述方式的差别。关键还是要看它是否真正建立了时空认知能力,而不仅仅是在语言模型上做加法。
但任少卿认为语言仍然是很重要的,它有三大价值:
海量数据:语言模型吸收了海量互联网案例(尤其是 “彩色案例”,即有代表性和复杂性的场景)。这些数据对自动驾驶训练非常有帮助。
推理能力:通过链式推理(CoT, Chain of Thought),语言模型能带来一定的逻辑推理,弥补世界模型目前还未建立的细粒度推理。
人机交互:用户需要能像跟司机沟通一样,直接告诉车 “开进小区,左转,在楼下停”。这需要自然语言接口,而不仅仅是导航按钮或固定选项。
语言模型带来的是 “概念认知”,世界模型带来的是 “时空认知”。把这两块拼在一起,最后才会走向 AGI。
以上。
自动驾驶这两年高度内卷,前沿技术栈趋于收敛,量产方案趋同,很多小伙伴都觉得自驾卷到头了,决定转行去具身,我们也看到一些业内大佬辞职投身具身的创业洪流。如何破局成了大家讨论的最多的话题。所以我们也看到VLA/WA的路线之争,以及在这背后一轮更大的行业变革。
对于处在自驾领域的个人来说,变革是挑战更是机遇。真正留在行业内担当主力的,都是综合型人才,技术栈特别丰富。抱着“捞一波”行情的心态,不可能长久,洗牌也是早晚的事情。广屯粮,筑高墙是个一直受用的真理。

扛内卷,一个足够有料的社区
对于很多想入门的同学来说,试错成本有点高。没时间和缺乏完整的体系是最大问题,这也容易导致行业壁垒越来越高,如果想要卷赢那就更加困难了。
所以我们联合了诸多学术界和工业界的大佬,共同打造了我们维护三年之久的『自动驾驶之心知识星球』!星球目前集视频 + 图文 + 学习路线 + 问答 + 求职交流为一体,是一个综合类的自驾社区,已经超过4000人了。我们期望未来2年内做到近万人的规模。给大家打造一个交流+技术分享的聚集地,是许多初学者和进阶的同学经常逛的地方。
如果你也想和我们一起推动自驾领域的进步,欢迎加入我们的社区团队,和我们一起推动!我们推出了今年最大的优惠券给大家,欢迎微信扫码领取,还有少量~

社区内部还经常为大家解答各类实用问题:端到端如何入门?自动驾驶多模态大模型如何学习?自动驾驶VLA的学习路线。数据闭环4D标注的工程实践。快速解答,方便大家应用到项目中。
更有料的是:星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。除了上面的问题,我们还为大家梳理了很多其它的内容:
端到端自动驾驶如何入门?一段式/二段式量产中如何使用?
传统规划控制想转端到端VLA,求学习路线图!
自动驾驶多模态大模型预训练数据集有哪些?求自动驾驶VLA微调数据集?
多传感器融合现在还适合就业吗?
3DGS和闭环仿真如何结合?应用中需要考虑哪些元素?
世界模型是个啥?业内如何应用,研究还有切入点么?
业内哪家公司前景好一些,适合跳槽,都有什么岗位开放招聘?求星主内推~
博士入学,哪个方向容易出成果?
闭环强化学习如何入门?
端到端自动驾驶学习路线推荐。
......
我们会不定期和一线的学术界&工业界大佬畅聊自动驾驶发展趋势,探讨技术走向和量产痛点:
这是一个认真做内容的社区,一个培养未来领袖的地方。星球内部梳理了近40+自动驾驶技术方向,同时也有面向求职的问答梳理。

针对入门学习的同学,我们更是准备了全栈方向的学习课程,非常适合0基础的小白。

我们还和多家自动驾驶公司建立了岗位内推机制,欢迎大家随时艾特我们。第一时间将您的简历送到心仪公司的手上。
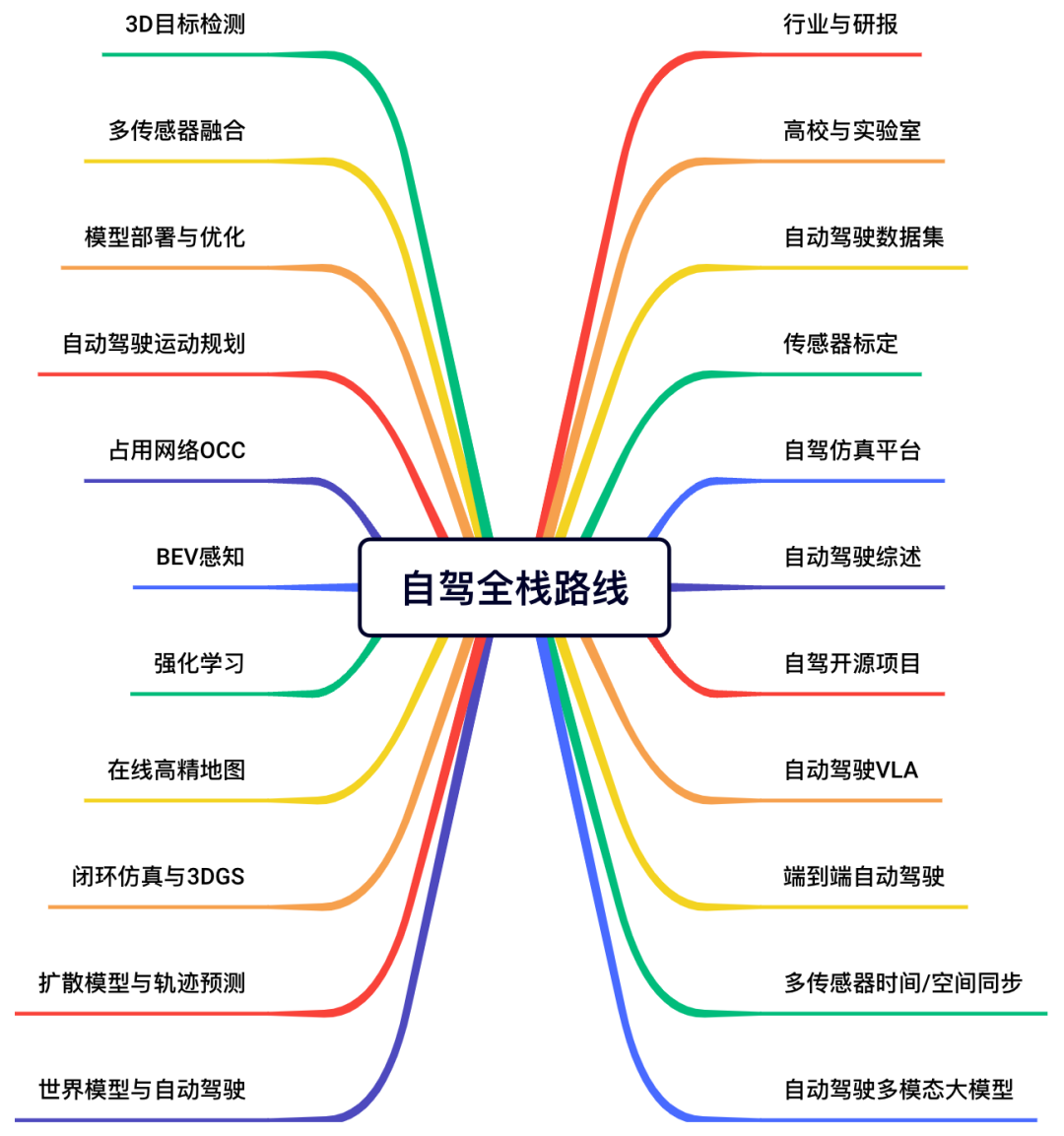
针对入门者,我们整理了完备的小白入门技术栈和全栈路线图。
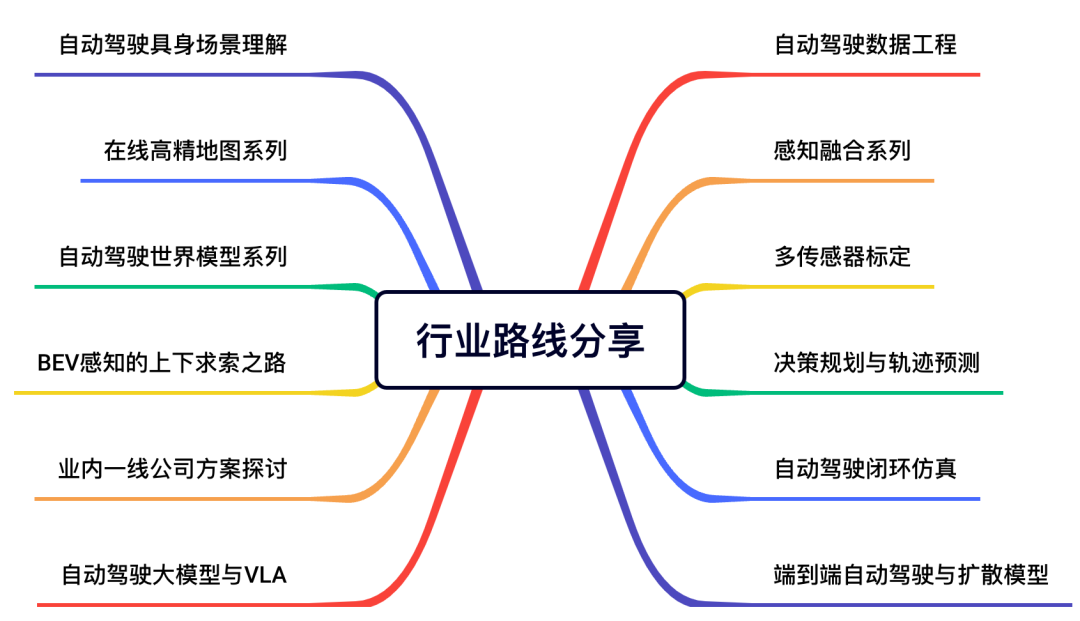
已经从事相关研究的同学,我们也给大家提供了很多有价值的产业体系和项目方案。
欢迎和我们一起打造完整的自驾生态。

国内首个自驾全栈社区:自动驾驶之心知识星球
社区创建的出发点是给大家提供一个自动驾驶相关的技术交流平台,交流学术和工程上的问题。星球内部的成员来自国内外知名高校实验室、自动驾驶相关的头部公司,其中高校和科研机构包括但不限于:上海交大、北京大学、CMU、清华大学、西湖大学、上海人工智能实验室、港科大、港大、南洋理工、新加坡国立、ETH、南京大学、华中科技大学、ETH等等!公司包括但不限于:蔚小理、地平线、华为、大疆、广汽、上汽、博世、轻舟智航、斑马智行、小米汽车、英伟达、Momenta、百度等等。前沿技术聚集地一直是自动驾驶之心的标签!
我们为大家汇总了近40+开源项目、近60+自动驾驶相关数据集、行业主流自驾仿真平台、以及各类技术学习路线,包括但不限于:
自动驾驶感知学习路线 | 自动驾驶仿真学习路线 | 自动驾驶规划控制学习路线 |
|---|---|---|
端到端学习路线 | 3DGS算法原理 | 基于搜索的规划 |
VLA学习路线 | NeRF原理 | 基于采样的规划 |
多模态大模型 | Carla仿真 | 基于车辆运动学的规划 |
占用网络 | Apollo仿真 | 基于数值优化的规划 |
BEV感知 | Autoware仿真 | 横纵解耦规划框架 |
扩散模型 | 联合仿真 | 横纵联合规划框架 |
世界模型 | 自驾仿真产品架构分析 | 基于几何的路径跟踪 |
多传感器融合 | 闭环仿真 | 模型预测控制 |
轨迹预测 | 相关数据集 | 联合预测 |
...... | ...... | ...... |
这里能够让小白快速入门,让已经入门的同学进一步提升,已经提升的同学结交更多的朋友。
日常分享和讨论的问题
端到端自动驾驶如何入门?一段式/二段式量产中如何使用?
传统规划控制想转端到端VLA,求学习路线图!
自动驾驶多模态大模型预训练数据集有哪些?求自动驾驶VLA微调数据集?
多传感器融合现在还适合就业吗?
3DGS和闭环仿真如何结合?应用中需要考虑哪些元素?
世界模型是个啥?业内如何应用,研究还有切入点么?
业内哪家公司前景好一些,适合跳槽,都有什么岗位开放招聘?求星主内推~
博士入学,哪个方向容易出成果?
闭环强化学习如何入门?
端到端自动驾驶学习路线推荐。
......
加入星球有哪些福利?
第一时间掌握自动驾驶相关的学术进展、工业落地应用;
和行业大佬一起交流工作与求职相关的问题;
优良的学习交流环境,能结识更多同行业的伙伴;
星球内部专属学习视频,搭配文档不枯燥;
自动驾驶相关工作岗位推荐,第一时间对接企业;
行业机会挖掘,投资与项目对接。
星球内容一览
星球内容一览!

0)国内外自动驾驶与机器人高校汇总
星球内部为大家汇总了自动驾驶&机器人多个研究方向的国内外知名实验室,供大家后期读研、申博、博后参考。
1)国内外自动驾驶公司汇总
星球内部为大家汇总了各类国内外各类自动驾驶相关机器人公司,涉及RoboTaxi、重卡业务、造车新势力等等!
2)自动驾驶及CV相关书籍汇总
星球内部汇总了自动驾驶和CV相关的学习书籍,涵盖数学基础、计算机视觉、深度学习入门、coding、运动规划、自动驾驶传感器、ROS系统学习指南等等~
3)开源项目汇总
星球内部针对3D目标检测、BEV感知、世界模型、闭环仿真3DGS、自动驾驶大模型、端到端自动驾驶等多个领域的开源项目进行了汇总,助力快速上手。
4)自动驾驶开源数据集
星球内部针对自动驾驶相关数据集进行了详细的梳理,针对通用CV数据集、感知相关数据集、轨迹预测等等。尤其是自动驾驶多模态大模型数据集,我们详细梳理了自动驾驶VLM预训练数据集、微调数据集、思维链数据集、强化学习数据集等等~
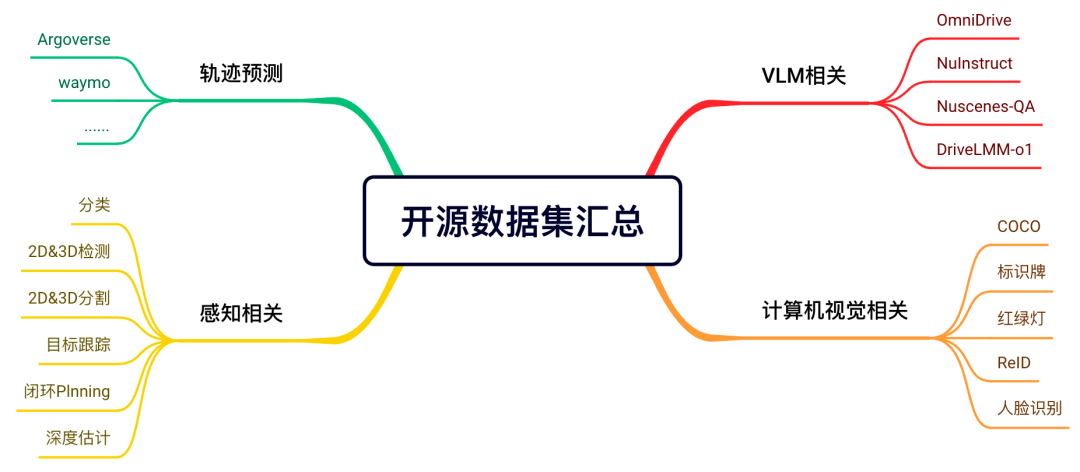
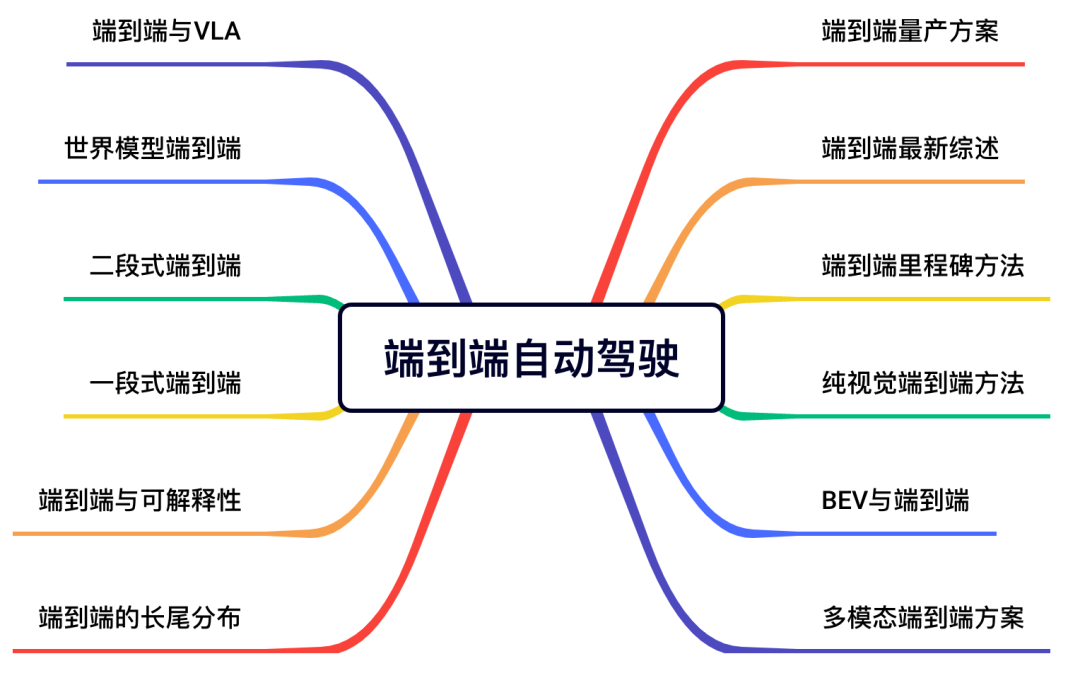
5)端到端自动驾驶
针对学术界和工业界的研究热点 - 端到端自动驾驶,我们详细梳理了一段式端到端、二段式端到端、量产方案、综述汇总、里程碑方法、VLA相关算法等等,兼顾学术界和工业界,真正做到知行合一~
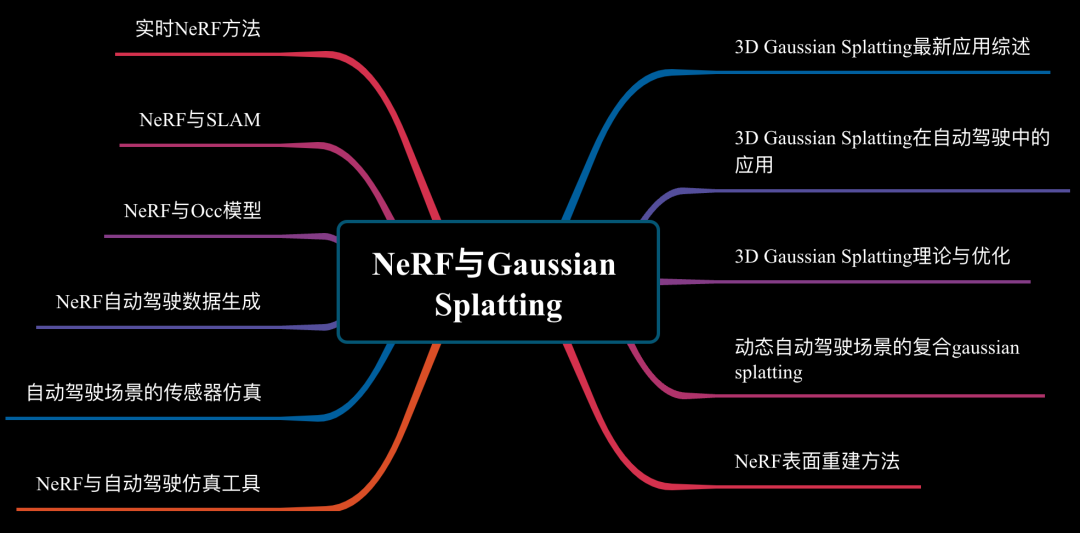
6)3DGS与NeRF
我们为大家汇总了3DGS和NeRF的相关技术领域,3DGS的算法原理、自动驾驶场景重建与闭环仿真、NeRF与自动驾驶仿真,NeRF与自动驾驶感知,同时我们也邀请到诸位学术界大佬分享3DGS和NeRF的最新工作,这里全都有!
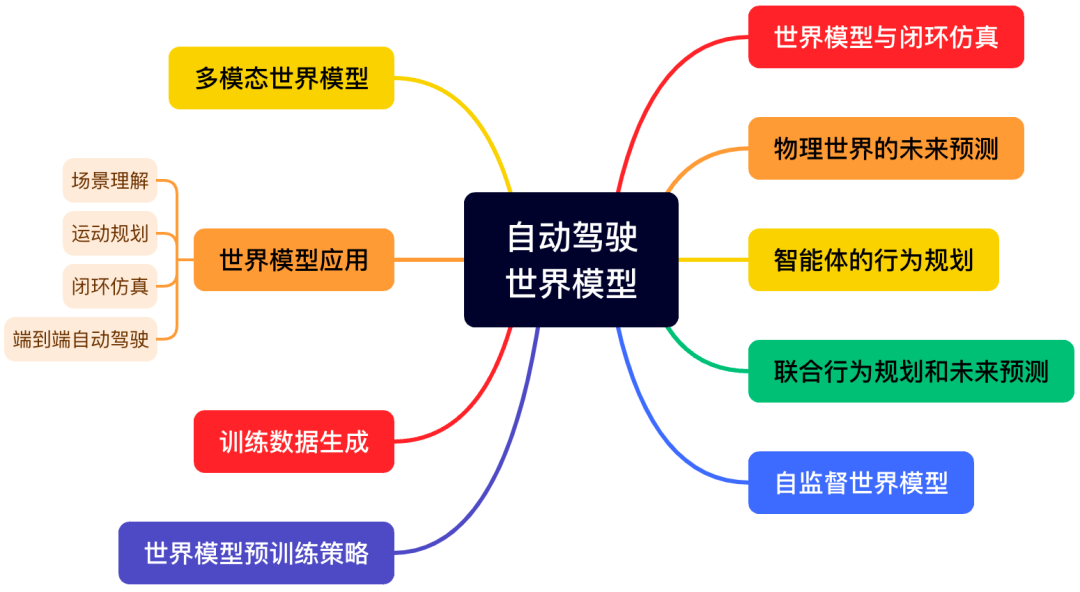
7)自动驾驶世界模型
针对当前学术界和工业界的热点 - 自动驾驶世界模型,星球内部做了详细的汇总,涵盖技术前沿和业界应用。
8)视觉语言模型(VLM)
我们汇总了自动驾驶VLM最新综述、开源数据集、思维链推理、量产方案快慢双系统DriveVLM等多项内容,让大家对这一前沿领域可以更深入的理解。
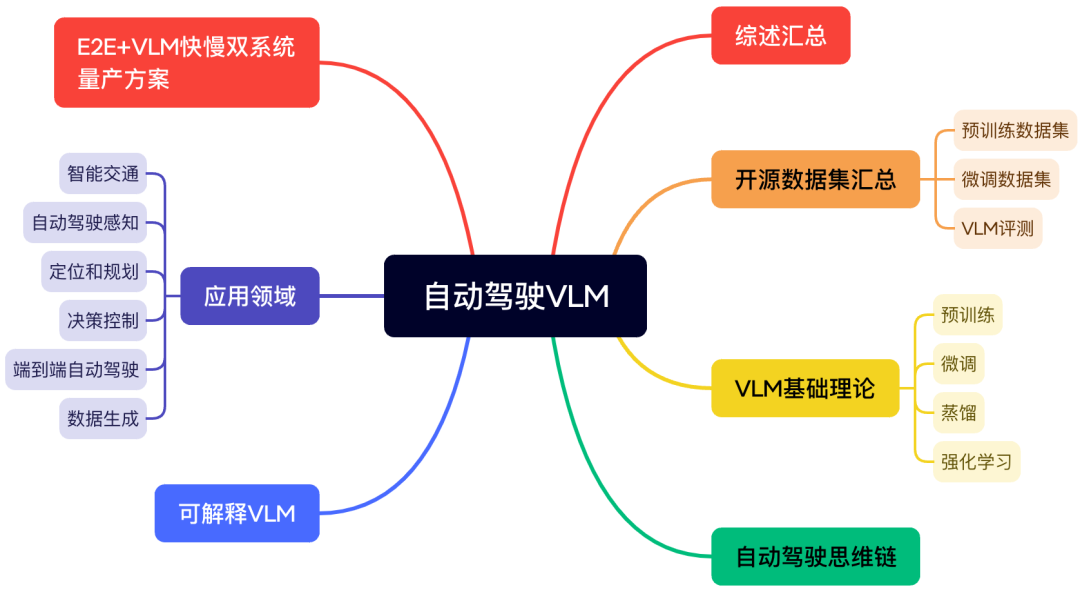
9)自动驾驶VLA
针对2025年最火的自动驾驶VLA,我们详细梳理了最新的综述、VLA开源数据集、作为语言解释器的相关算法、模块化VLA、端到端VLA和推理增强VLA,更有诸多关于VLA量产的讨论,在这里有你想知道的一切~
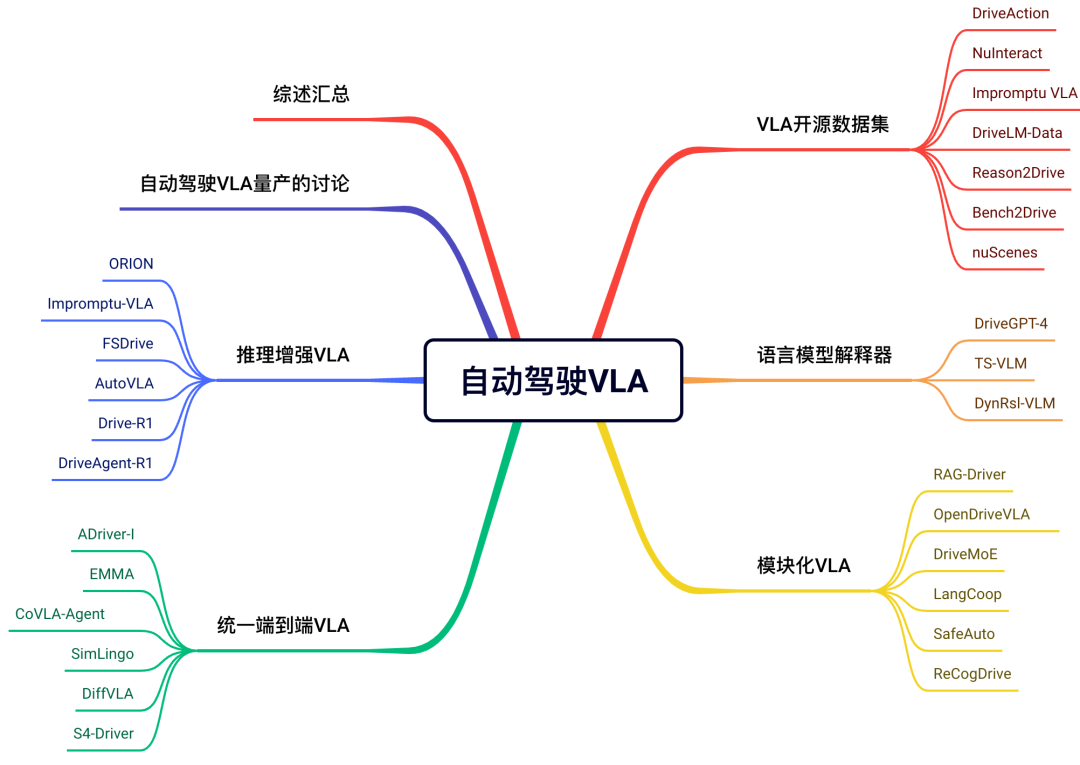
10)自动驾驶规划控制
星球内部汇总了传统规划内容的相关技术栈,包括但不限于规划控制基础算法、决策规划框架和常用控制算法。
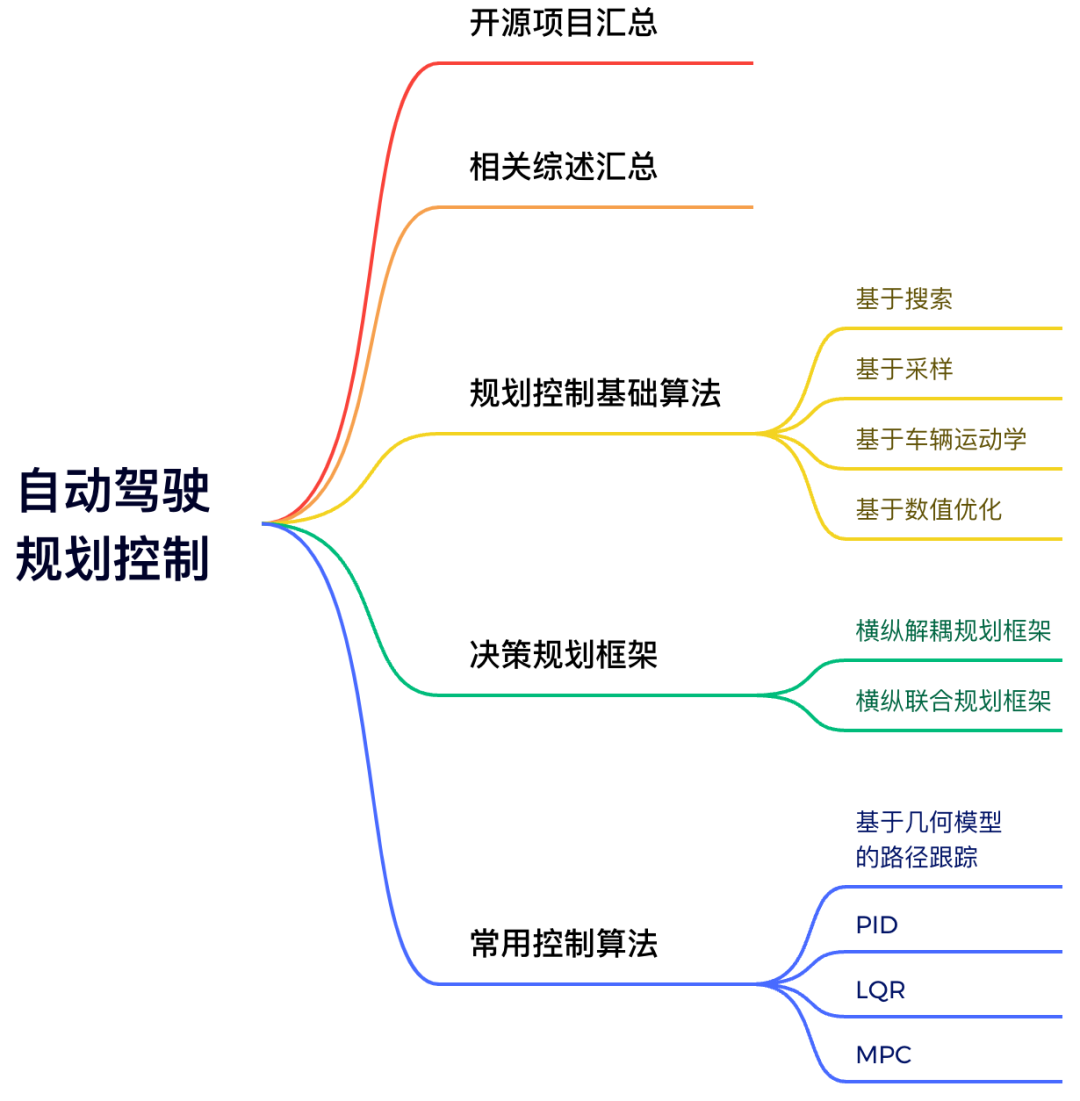
11)扩散模型
扩散模型作为当下的研究热点,星球内部也做了非常详细的梳理,从算法原理,到数据生成、场景重建、端到端、世界模型结合、大模型结合等等!
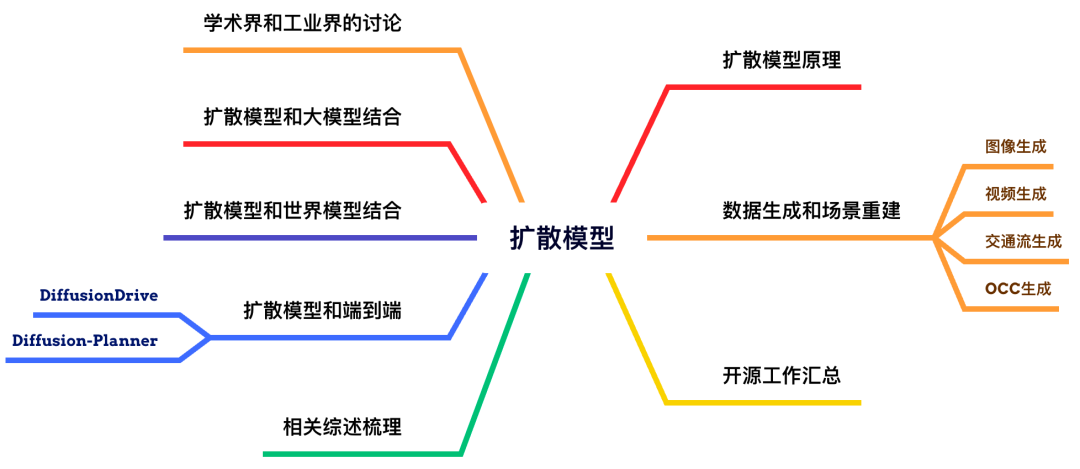
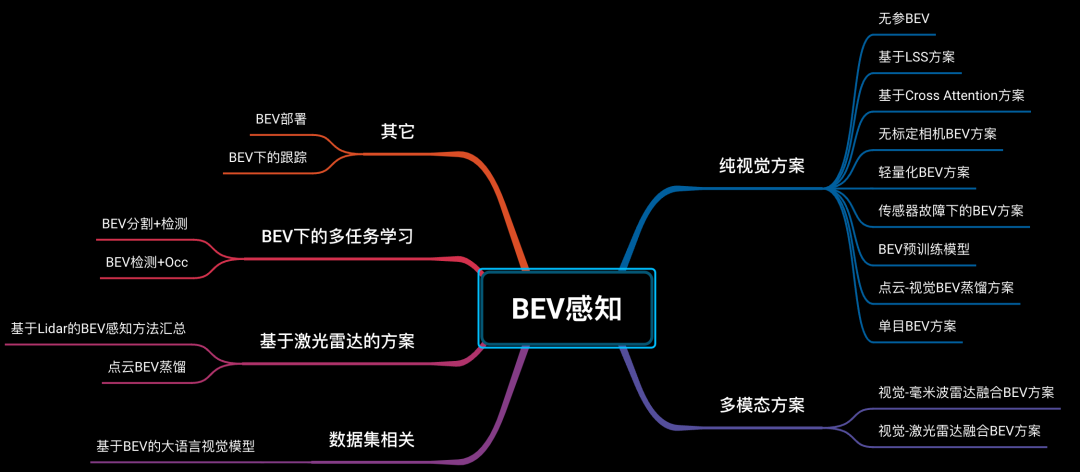
12)BEV感知
BEV感知作为当下量产的基石,星球内部做了非常成熟的梳理,纯视觉、多模态、多任务、激光雷达和相关数据集以及工程部署等等~
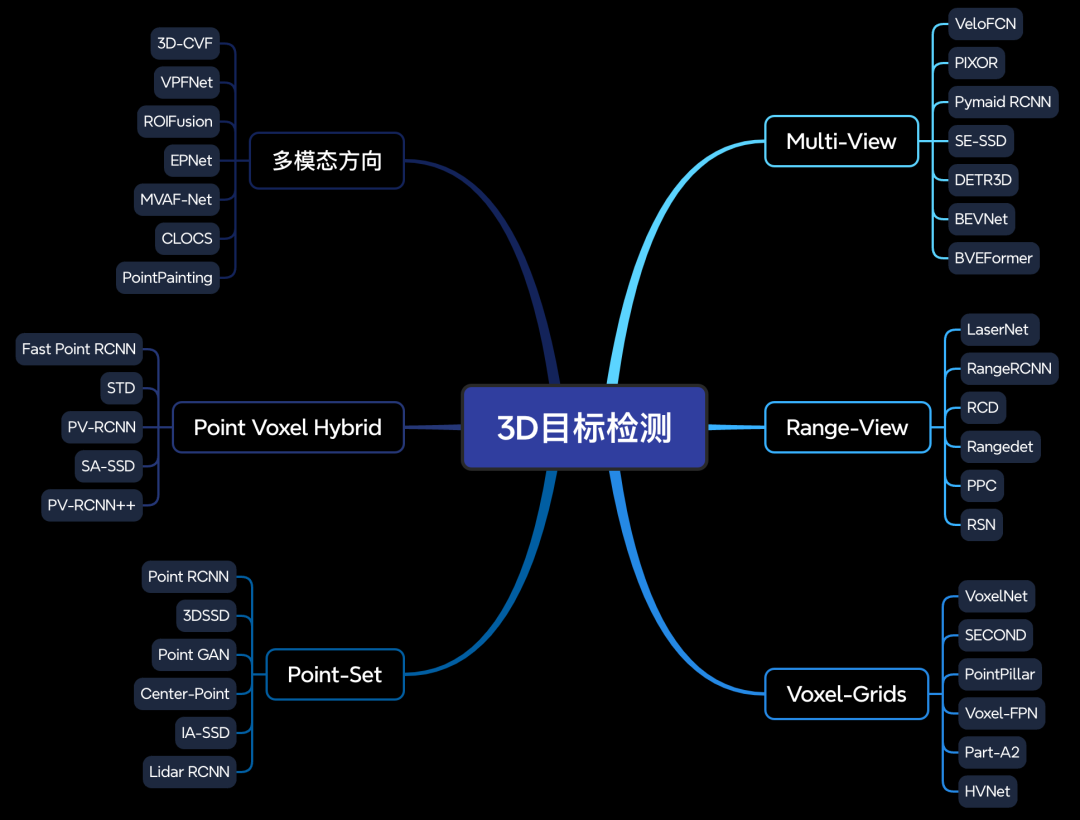
13)3D目标检测
针对3D目标检测领域,我们梳理了环视方法、range-view、基于voxel、Point及多模态方向。
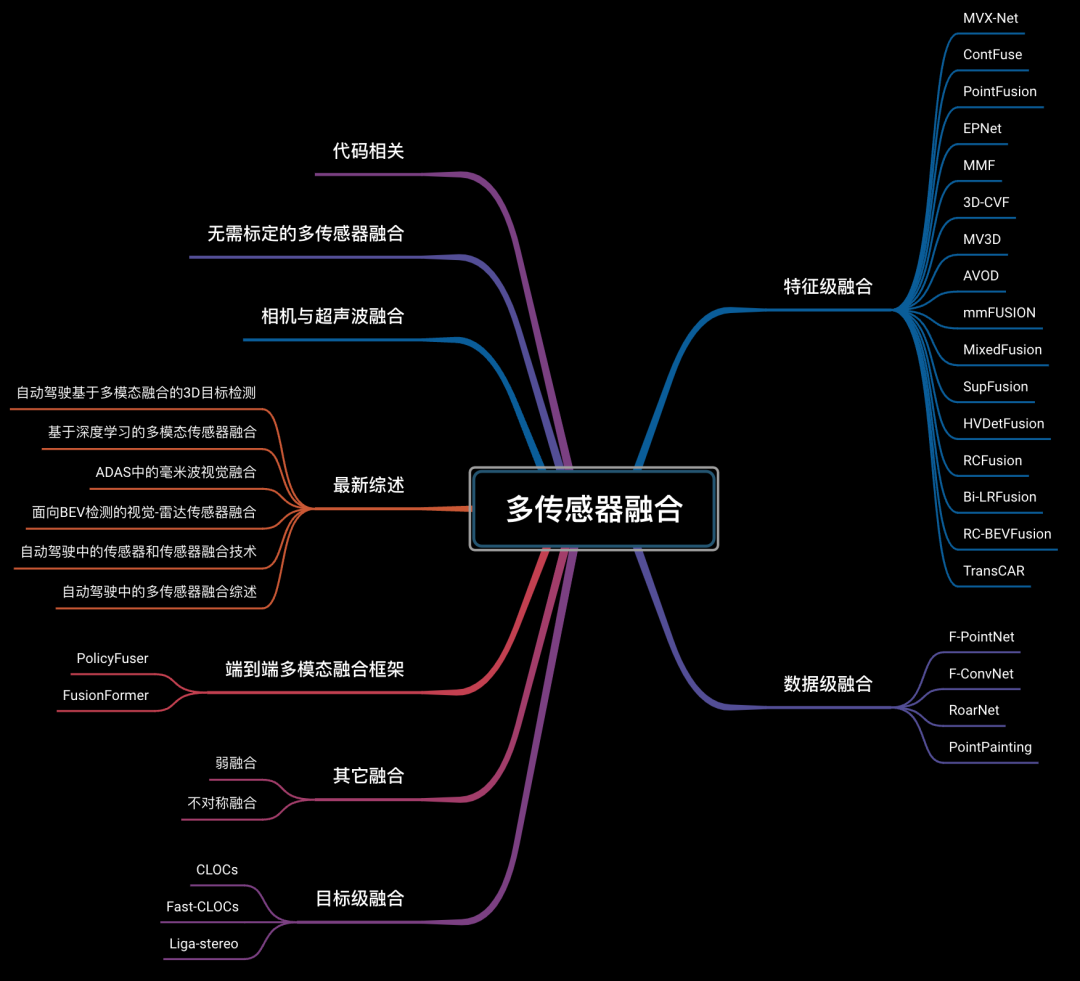
14)多传感器融合
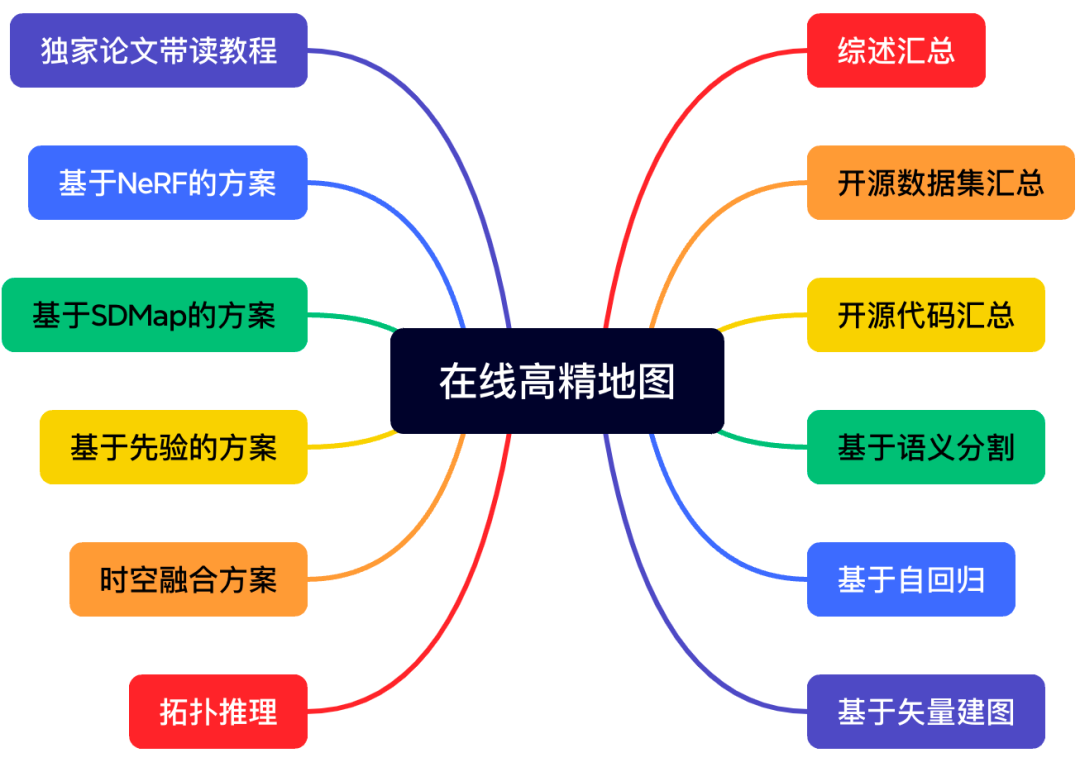
15)在线高精地图
在线高精地图是无图NOA量产方案的核心,星球详细梳理了近几年学术界和工业界关注最多的工作。
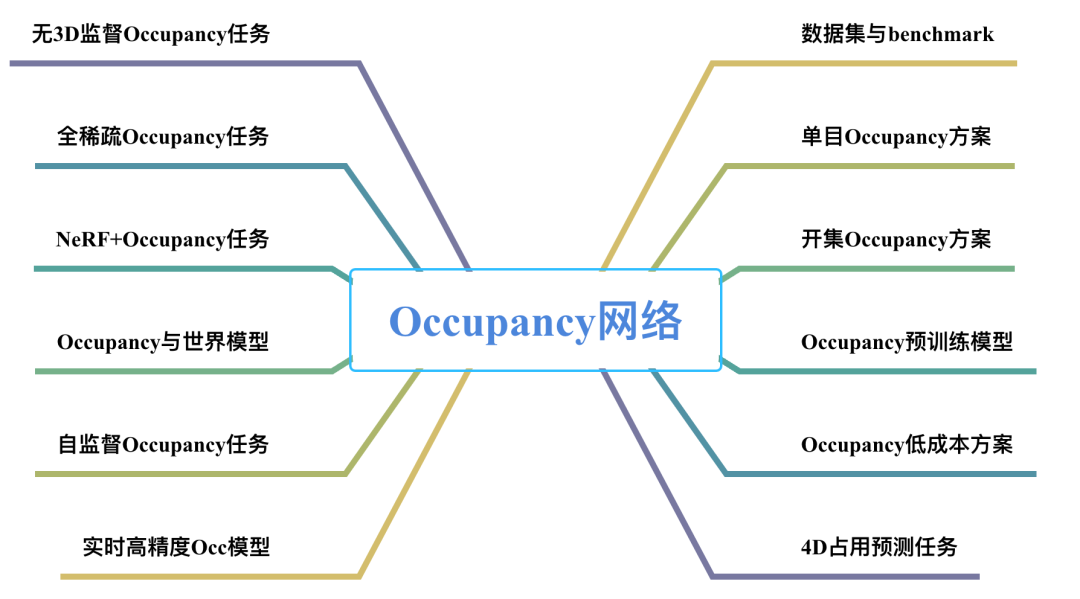
16)Occupancy Network
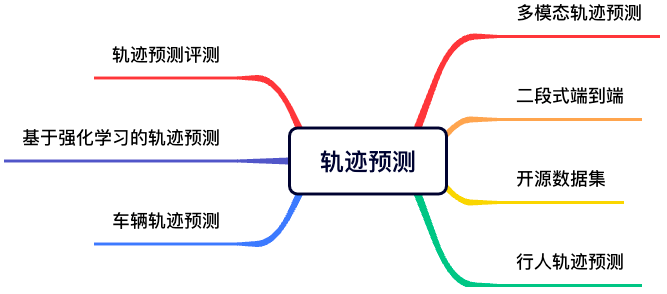
17)轨迹预测
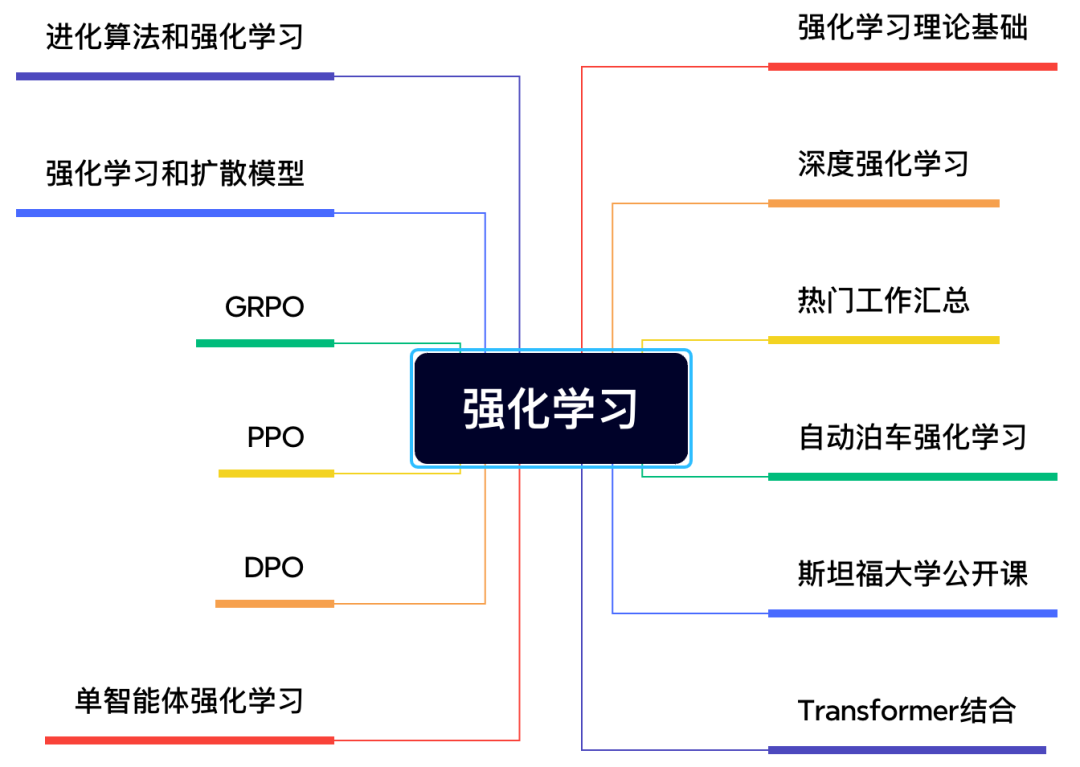
18)自动驾驶-强化学习
强化学习是VLM必备的组件,星球内部梳理了强化学习理论、常用算法、优秀公开课、热门工作等等内容,一应俱全!
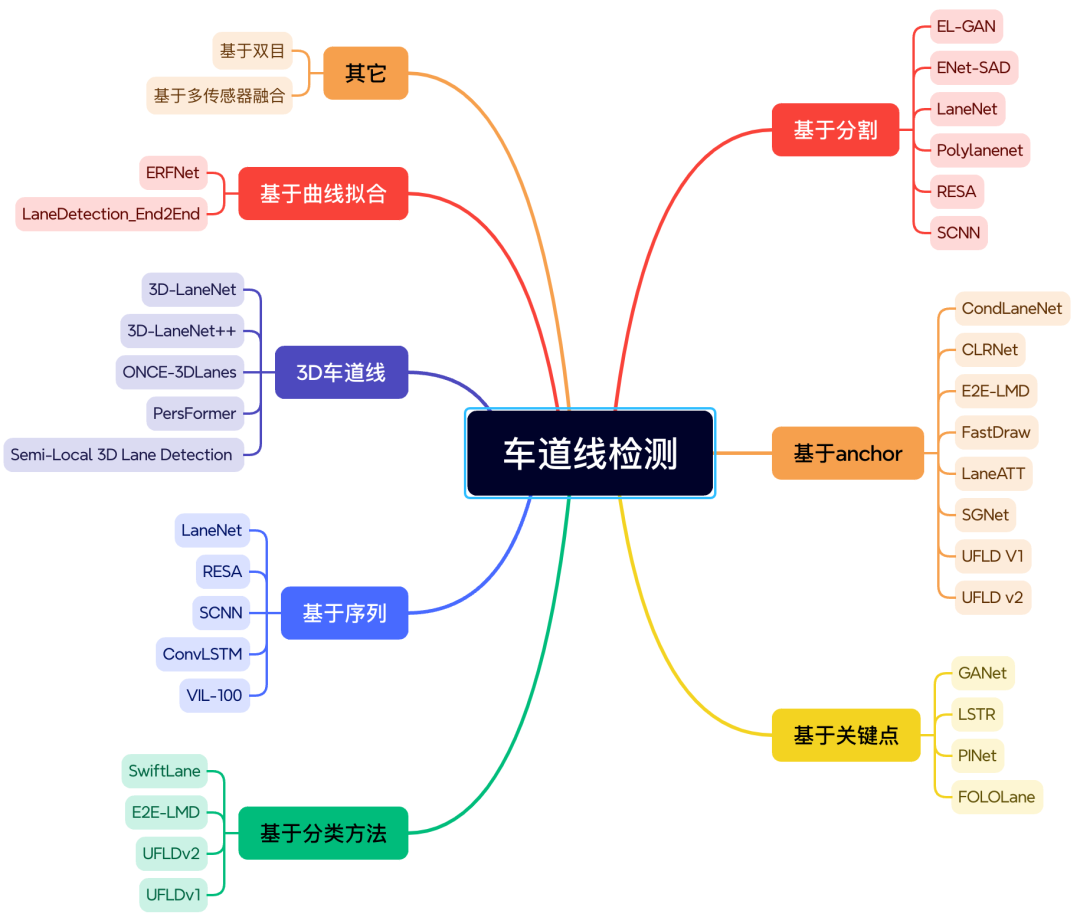
19)车道线检测
20)标定工具
21)分割任务
22)CUDA与模型部署
23)模型部署实战
24)目标跟踪
25)2D目标检测
26)V2X
27)SLAM
28)自动驾驶仿真
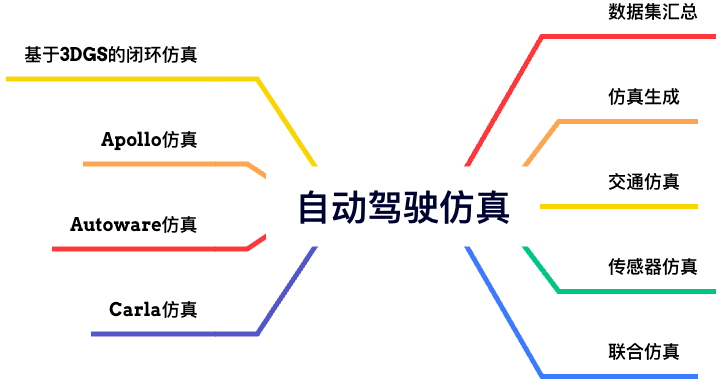
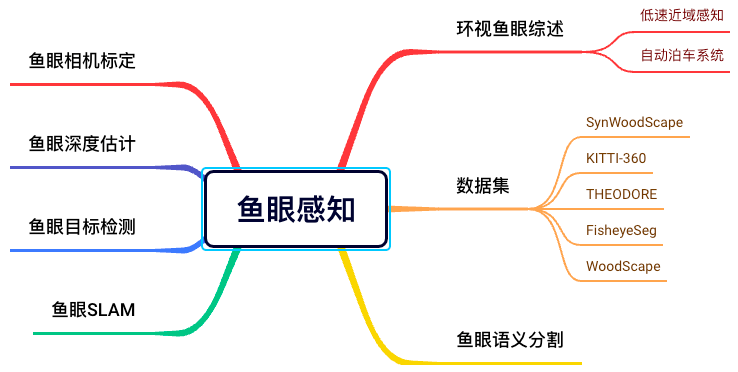
29)鱼眼感知
30)3D分割

31)大模型与自动驾驶

星球内部学习教程
星球内部会员独享七大福利视频教程!涵盖世界模型、自动驾驶大模型、Transformer、3D目标检测、毫米波感知等等...

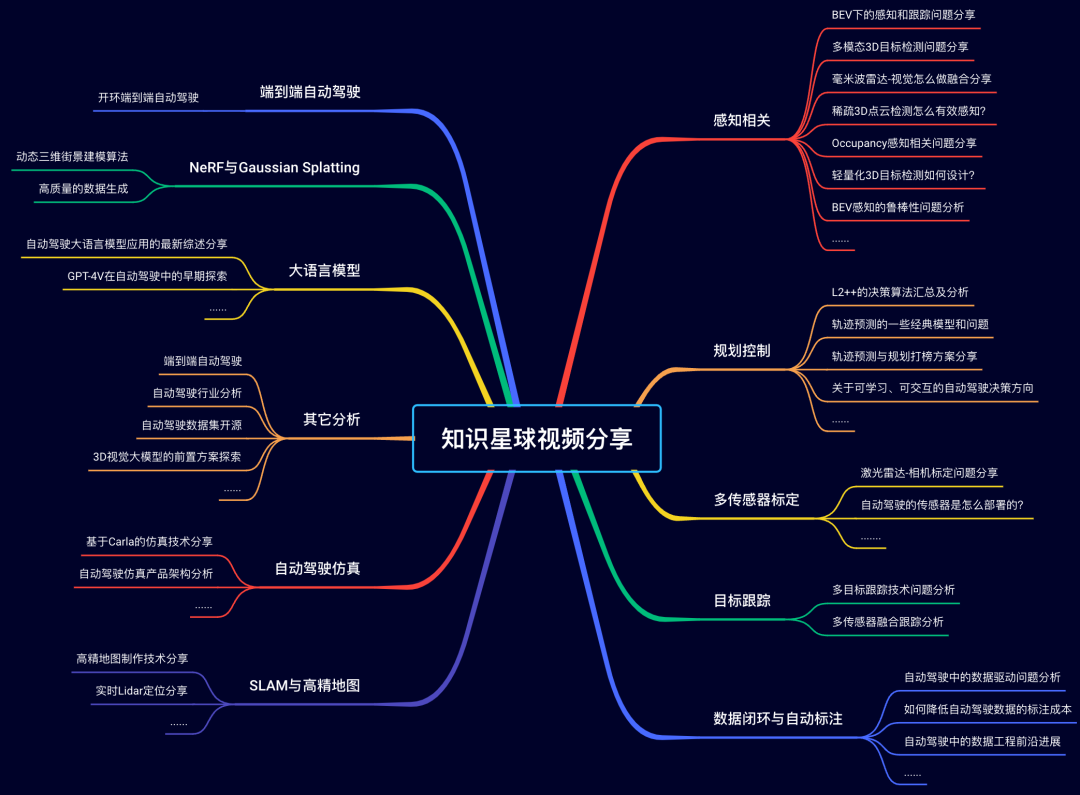
星球内部直播分享
星球内部不定期邀请行业大佬直播分享,直播内容可以反复观看,部分直播内容一览!目前已经超过一百场专业技术直播!!!

星球内部交流
星球成员可以在星球内部自由提问,无论是工作选择还是研究方向选择,都能得到解答~

行业大佬交流
不定期分享和业内大佬的观点交流!

扫码加入
欢迎扫码加入我们的社区,和近300家机构与自驾公司成员一起交流产业、产品、求职等内容。


















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









