



作者 | 哈喽WoW君 编辑 | 大模型之心Tech
原文链接:https://zhuanlan.zhihu.com/p/1939744959143086058
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
一、主流AI AGENT框架
当前主流的AI Agent框架种类繁多,各有侧重,适用于不同的应用场景。目前收集了几个主流并且典型Agent框架,先给出本文描述的有哪些框架图表。
框架 | 描述 | 适用场景 |
|---|---|---|
LangGraph | 基于LangChain搭建的状态驱动的多步骤 Agent | 复杂状态机、审批流 |
AutoGen | 多 Agent 协作、对话式 | 研究报告生成、任务拆解 |
CrewAI | 轻量级“角色扮演”多 Agent | 内容团队、市场分析 |
Smolagents | Hugging Face 系、专注小模型 | 私有化、小模型场景 |
RagFlow | 专注 RAG 的端到端流程 | 新增多模态文档解析节点 |
二、CrewAI
crewAI 是一个开源多智能体协调框架。这个基于 Python 的框架通过协调角色扮演的自主 AI 智能体,利用人工智能 (AI) 协作,作为一个内聚的集合体或“团队”共同完成任务。
CrewAI 是一款专注于多智能体自动化的先进框架,其核心特点可总结如下:
独立架构
完全自主研发,不依赖LangChain或其他现有框架,提供原生解决方案。
高性能设计
强调速度和资源效率优化,实现快速任务执行与低消耗。
深度可定制化
支持从宏观工作流到微观行为的全栈定制:
可调整系统架构与整体流程
能精细控制单个Agent的决策逻辑、内部提示词等底层细节
全场景适用
既适合简单任务,也能支撑企业级复杂自动化需求,通过两种模式实现:智能协作团队(Crews模式)、事件工作流(Flows模式)
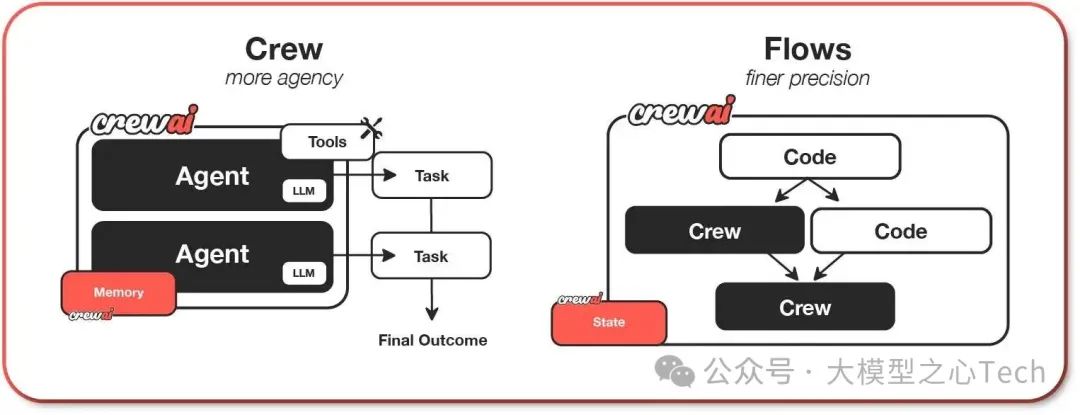
CrewAI 功能介绍
CrewsAI支持两个功能,分别为Crews与Flows,具体如下
Crews(智能协作团队)
由具备真实自主性与决策权的AI智能体组成的团队,通过角色化协作完成复杂任务。其核心特点包括:自主决策:智能体之间可自然、自主地做出决策
动态协作:支持任务灵活分配与实时协同
角色专精:每个智能体有明确目标、专业领域和职能
弹性问题解决:能自适应调整解决路径
Flows(事件工作流)
面向生产环境的自动化流程引擎,提供精准控制能力:精细化执行控制:满足现实场景的多路径执行需求
可靠状态管理:跨任务的安全、一致性数据维护
无缝代码集成:AI智能体与生产级Python代码的清洁对接
条件分支逻辑:支持复杂业务规则的动态路由
两者共同构成「自主协作+精准流程」的AI自动化体系,兼顾灵活性与生产可靠性。
活跃生态支持
拥有超过10万认证开发者组成的社区,提供强大的技术支持和资源库。
该框架通过平衡易用性、灵活性与性能,帮助开发者和企业高效构建智能自动化系统,尤其擅长处理需要多智能体协作的复杂场景。
Crews 智能协作模式示例
步骤1:创建CrewAI项目
首先,使用CLI创建一个新的CrewAI项目。该命令生成完整的项目结构及所需文件。
crewai create crew research_crew
cd research_crew步骤2:生成的项目结构
research_crew/
├── .gitignore
├── pyproject.toml
├── README.md
├── .env
└── src/
└── research_crew/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yaml了解CLI生成的项目结构。CrewAI遵循Python项目最佳实践,便于维护和扩展:
crewAI会生成完成的项目结构,我们只需要在对应内容做修改调整,大大降低了操作的门槛。
配置文件(YAML)与实现代码(Python)分离,便于调整行为而无需修改底层代码。
步骤3:AI agent配置
定义具有特定角色、目标和背景的AI agent。例如:
研究员:擅长查找和组织信息
分析师:解读研究结果并生成报告
修改agents.yaml文件:
researcher:
role: "{topic}高级研究专家"
goal: "查找关于{topic}的全面准确信息,重点关注近期进展和关键见解"
backstory: "您是一位经验丰富的研究专家,擅长从多来源获取信息并清晰组织内容。"
llm: "model-id" # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude
analyst:
role: "{topic}数据分析师兼报告撰写人"
goal: "分析研究发现并撰写结构清晰的综合报告"
backstory: "您是一位擅长数据解读和技术写作的分析师,能有效提炼见解并形成专业报告。"
llm: "model-id" # e.g. openai/gpt-4o, google/gemini-2.0-flash, anthropic/claude步骤4:个性化定义任务
为agent分配具体工作。
示例任务:
研究任务:收集信息
分析任务:生成报告
修改tasks.yaml文件:
research_task:
description: "深入研究{topic},涵盖关键概念、趋势、挑战、案例和未来展望。"
expected_output: "结构化的研究文档,包含事实数据和案例。"
agent: researcher
analysis_task:
description: "分析研究结果并生成专业报告,需包含摘要、趋势分析和建议。"
expected_output: "格式规范、易于阅读的最终报告。"
agent: analyst
context: [research_task] # 分析师可访问研究员输出
output_file: "output/report.md"步骤5:配置Crew
在crew.py中整合代理和任务,设置协作流程:
@CrewBase
class ResearchCrew():
@agent
def researcher(self) -> Agent:
return Agent(config=self.agents_config['researcher'], tools=[SerperDevTool()])
@agent
def analyst(self) -> Agent:
return Agent(config=self.agents_config['analyst'])
@crew
def crew(self) -> Crew:
return Crew(agents=self.agents, tasks=self.tasks, process=Process.sequential)通过几行代码实现agent的协同工作流程。
步骤6:设置main脚本
在main.py中指定研究主题并启动Crew:
inputs = {'topic': '医疗领域的人工智能'}
result = ResearchCrew().crew().kickoff(inputs=inputs)
print(result.raw) # 打印报告步骤7:配置环境变量
在项目根目录的.env文件中添加API密钥:
SERPER_API_KEY=您的密钥
LLM_API_KEY=您的密钥步骤8:安装依赖
运行以下命令自动安装依赖:
crewai install
步骤9:运行Crew
启动协作流程:
crewai run
实时观察代理的思考、行动和输出。
步骤10:查看输出
最终报告将保存至output/report.md,包含:执行摘要、详细分析、建议与展望
三、LangChain
LangGraph 由LangChain创建,是一个开源 AI 代理框架,旨在构建、部署和管理复杂的生成式 AI 代理工作流。其核心是利用基于图的架构的强大功能来建模和管理AI 代理工作流中各个组件之间的复杂关系。
LangChain 功能介绍
LangChain基于图的架构视为一个强大的可配置的“超级地图”。用户可以将AI 工作流程想象成这张“超级地图”的“导航员”。最后,在这个例子中,用户是“制图员”。从这个意义上讲,导航员绘制出“超级地图”上各点之间的最佳路线,而所有这些路线都是由“制图员”创建的。基于图的架构(“超级地图”)中的最佳路线是通过 AI 工作流(“导航器”)绘制和探索的。
LangGraph 阐明了 AI 工作流程中的流程,使代理的状态完全透明。在 LangGraph 中,“状态”功能充当存储库,记录并追踪 AI 系统处理的所有有价值的信息。它类似于一个数字笔记本,系统在工作流程或图形分析的各个阶段中捕获并更新数据。
LangGraph使用示例
前置条件
在开始本教程前,请确保满足以下条件:
拥有Anthropic API密钥
1.安装依赖
如果尚未安装,请先安装LangGraph和LangChain:
pip install -U langgraph "langchain[anthropic]"2.创建agent
使用create_react_agent创建智能体:
from langgraph.prebuilt import create_react_agent
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
return f"{city}的天气永远晴朗!"
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
prompt="你是一个乐于助人的助手"
)
# 运行智能体
agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样"}]}
)3.配置大语言模型(LLM)
配置LLM参数(如模型、温度参数),使用init_chat_model:
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import create_react_agent
model = init_chat_model(
"anthropic:claude-3-7-sonnet-latest",
temperature=0 # 控制随机性
)
agent = create_react_agent(
model=model,
tools=[get_weather],
)4.添加自定义提示
提示词用于指导LLM的行为。可选择以下两种提示类型:
静态提示: 字符串形式,作为系统消息。
动态提示: 根据运行时输入或配置生成的消息列表。
4.1 静态提示
定义一个固定的prompt
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
# A static prompt that never changes
prompt="Never answer questions about the weather."
)
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)4.2 动态提示
定义函数,根据智能体状态和配置返回消息列表:
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.prebuilt import create_react_agent
def prompt(state: AgentState, config: RunnableConfig) -> list[AnyMessage]:
user_name = config["configurable"].get("user_name")
system_msg = f"你是一个乐于助人的助手。请称呼用户为{user_name}。"
return [{"role": "system", "content": system_msg}] + state["messages"]
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
prompt=prompt
)
agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样"}]},
config={"configurable": {"user_name": "张三"}}
)5.添加记忆功能
为实现历史多轮对话记忆功能,需通过检查点(checkpointer)启用持久化。运行时需提供包含thread_id(会话唯一标识)的配置:
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
checkpointer=checkpointer # 启用记忆存储
)
# 运行智能体
config = {"configurable": {"thread_id": "1"}}
sf_response = agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样"}]},
config
)
ny_response = agent.invoke(
{"messages": [{"role": "user", "content": "纽约呢?"}]},
config
)启用检查点后,智能体的状态会存储到指定的数据库(若使用InMemorySaver则存储在内存中)。
6.配置结构化输出
如需生成符合模式的结构化响应,使用response_format参数。模式可通过Pydantic模型或TypedDict定义,结果将通过structured_response字段访问。
from pydantic import BaseModel
from langgraph.prebuilt import create_react_agent
class WeatherResponse(BaseModel):
conditions: str # 天气状况字段
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
response_format=WeatherResponse # 指定响应格式
)
response = agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样"}]}
)
response["structured_response"] # 获取结构化响应LangGraph 还推出了 LangGraph Studio,一个用于工作流开发的可视化界面。使用 LangGraph Studio,用户可以通过图形界面设计和构建工作流,而无需编写代码。可下载的桌面应用程序使 LangGraph Studio 更适合初学者使用。
四、AutoGen
AutoGen 是微软推出的一款开源框架,用于构建能够通过对话模式协作完成任务的代理。AutoGen 简化了 AI 开发和研究,支持使用多种大型语言模型 (LLM)、集成工具和高级多代理设计模式。
AutoGen 可作为通用基础架构,用于构建各种复杂程度和 LLM 功能的应用程序。实证研究证明了该框架在许多示例应用程序中的有效性,这些应用程序涵盖数学、编程、问答、运筹学、在线决策、娱乐等领域。您可以将此应用程序视为ChatGPT + 代码解释器 + 插件 + 完全可定制。
AutoGen 的设计模式采用统一的界面,展现了用于座席交互的标准化接口。它还具有自动回复机制,可实现持续的对话流程。此外,它还支持动态对话,支持静态和动态流程。它为自适应对话提供了可自定义的回复功能。
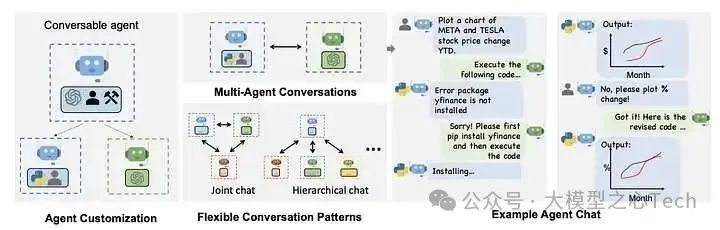
AutoGen 是一个开源的编程框架,用于构建AI智能体并促进多智能体协作完成任务。它旨在提供一个易用且灵活的开发框架,加速智能体AI(如PyTorch之于深度学习)的研发进程。其核心功能包括: 支持智能体间对话、大语言模型(LLM)与工具调用、自主工作流与人机协同流程,以及多智能体会话模式 。
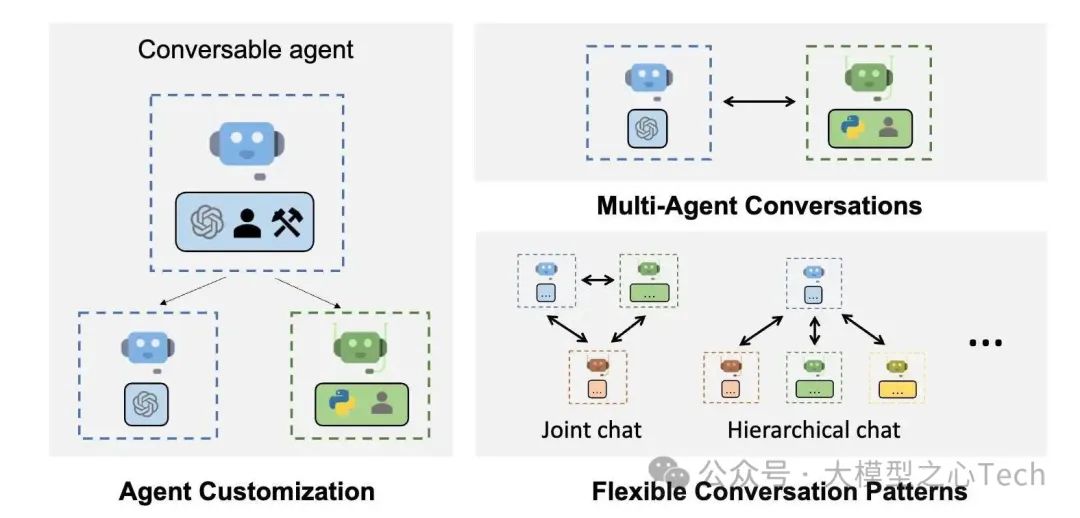
AutoGen概览
核心特性
下一代LLM应用构建:通过多智能体对话轻松构建复杂LLM应用,简化工作流的编排、自动化与优化,最大化模型性能并弥补其缺陷。
多样化会话模式:支持自定义可对话智能体,开发者能构建不同自主性、智能体数量和拓扑结构的会话流程。
开箱即用案例系统:提供涵盖多领域、多复杂度的现成系统,展示框架对各种会话模式的广泛支持。
AutoGen使用方法
1.安装命令:
pip install autogen-agentchat~=0.22.执行模式:
2.1无代码执行
import os
from autogen import AssistantAgent, UserProxyAgent
llm_config = { "config_list": [{ "model": "gpt-4", "api_key": os.environ.get("OPENAI_API_KEY") }] }
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
# 发起对话
user_proxy.initiate_chat(
assistant,
message="给我讲个关于英伟达和特斯拉股价的笑话。",
)2.2本地代码执行
在 AutoGen 中,代码执行器是一个组件,它接收输入消息,然后执行并输出包含结果的消息。命令行代码执行器,它在命令行环境(例如 UNIX shell)中运行代码。
下图显示了本地命令行代码执行器的架构
autogen.coding.LocalCommandLineCodeExecutor
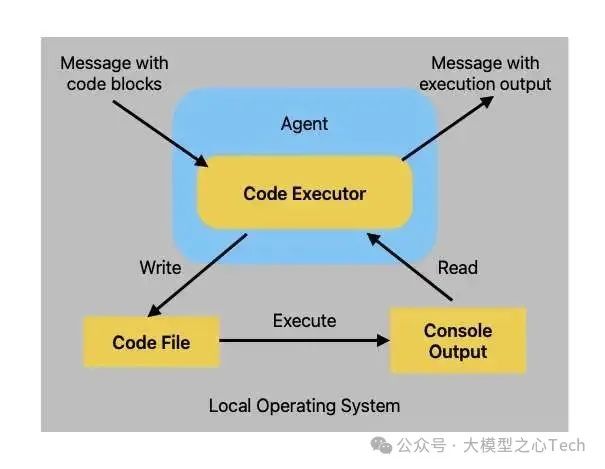
当本地命令行代码执行器收到包含代码块的消息时,首先将代码块写入代码文件,然后启动一个新的子进程来执行该代码文件。执行器读取代码执行的控制台输出,并将其作为回复消息发送回去。
以下是使用代码执行器运行 Python 代码块并打印随机数的示例。
首先,我们使用代码执行器创建一个代理,该代理使用临时目录来存储代码文件。
import tempfile
from autogen import ConversableAgent
from autogen.coding import LocalCommandLineCodeExecutor
# Create a temporary directory to store the code files.
temp_dir = tempfile.TemporaryDirectory()
# Create a local command line code executor.
executor = LocalCommandLineCodeExecutor(
timeout=10, # Timeout for each code execution in seconds.
work_dir=temp_dir.name, # Use the temporary directory to store the code files.
)
# Create an agent with code executor configuration.
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # Turn off LLM for this agent.
code_execution_config={"executor": executor}, # Use the local command line code executor.
human_input_mode="ALWAYS", # Always take human input for this agent for safety.
)现在我们让代理根据带有 Python 代码块的消息生成回复。
message_with_code_block = """This is a message with code block.
The code block is below:
```python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
```
This is the end of the message.
"""
# Generate a reply for the given code.
reply = code_executor_agent.generate_reply(messages=[{"role": "user", "content": message_with_code_block}])
print(reply)agent执行之后,生成的内容如下
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 0 (execution succeeded)
Code output:
Scatter plot saved to scatter.png在生成响应的过程中,需要人工输入,以便有机会拦截代码执行。在这种情况下,我们选择继续执行,代理的回复包含代码执行的输出。
import os
print(os.listdir(temp_dir.name))
# We can see the output scatter.png and the code file generated by the agent.输出的结果,我们可以在临时目录中查看生成的图
['scatter.png', '6507ea07b63b45aabb027ade4e213de6.py']五、Smolagents

Smolagents项目介绍
smolagents是HuggingFace官方推出的Agent开发库,HF出品的库,往往的设计理念是“低门槛,高天花板,可拓展”,所以知道HF出了Agent相关的框架后,也是很快体验了一下。smolagents是一个开源 Python 库,旨在仅使用几行代码即可极其轻松地构建和运行代理。
主要特点smolagents包括:
简洁:代理逻辑只需约千行代码即可实现。我们将抽象保持在原始代码之上,使其保持最小形式!
一流的代码代理支持:CodeAgent将其操作写入代码(而不是“使用代理编写代码”)以调用工具或执行计算,从而实现自然的可组合性(函数嵌套、循环、条件)。为了确保安全,我们支持通过E2B或 Docker在沙盒环境中执行。
通用工具调用代理支持:除了 CodeAgents 之外,ToolCallingAgent还支持通常的基于 JSON / 文本的工具调用,适用于优先使用这种范式的场景。
Hub 集成:无缝地与 Hub 共享和加载代理和工具,就像 Gradio Spaces 一样。
模型无关:轻松集成任何大型语言模型 (LLM),无论它是通过推理提供程序托管在 Hub 上,还是通过 OpenAI、Anthropic 等 API 或 LiteLLM 集成访问,亦或使用 Transformers 或 Ollama 在本地运行。使用您首选的 LLM 为代理提供支持既简单又灵活。
支持多种模态:除了文本,代理还可以处理视觉、视频和音频输入,从而拓展其应用范围。查看视觉相关教程。
支持工具:您可以使用来自任何MCP 服务器、来自LangChain的工具,甚至可以使用Hub Space作为工具。
smolagents示例
安装pip包
pip install smolagents[toolkit]定义agent,并执行结果
from smolagents import CodeAgent, WebSearchTool, InferenceClientModel
model = InferenceClientModel()
agent = CodeAgent(tools=[WebSearchTool()], model=model, stream_outputs=True)
agent.run("How many seconds would it take for a leopard at full speed to run through Pont des Arts?")六、RAGFlow
RAGFlow作为一款端到端的RAG解决方案,RAGFlow 旨在通过深度文档理解技术,解决现有RAG技术在数据处理和生成答案方面的挑战 。它不仅能够处理多种格式的文档,还能够智能地识别文档中的结构和内容,从而确保数据的高质量输入。
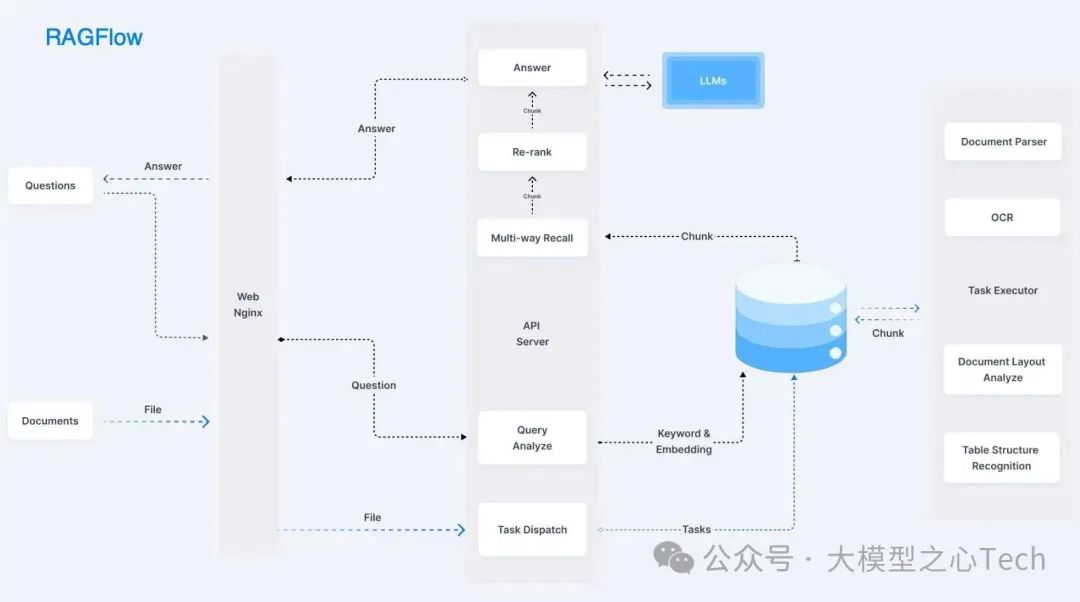
深度文档理解 :"Quality in, quality out",RAGFlow 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。真正在无限上下文(token)的场景下快速完成大海捞针测试。对于用户上传的文档,它需要自动识别文档的布局,包括标题、段落、换行等,还包含难度很大的图片和表格。对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格等。并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”。
可控文本切片 :RAGFlow 提供多种文本模板,用户可以根据需求选择合适的模板,确保结果的可控性和可解释性。因此 RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用... 。当然,这些分类还在不断继续扩展中,处理过程还有待完善。后续还会抽象出更多共通的东西,使各种定制化的处理更加容易。
支持各类异构数据源 :RAGFlow 支持 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据, 网页等。对于无序文本数据,RAGFlow 可以自动提取其中的关键信息并转化为结构化表示;而对于结构化数据,它则能灵活切入,挖掘内在的语义联系。最终将这两种不同来源的数据统一进行索引和检索,为用户提供一站式的数据处理和问答体验。
七、总结
当前主流的AI Agent框架各具特色,适用于不同的应用场景和技术需求。以下是各框架的核心特点及适用场景的总结:
CrewAI
特点 :专注于多智能体协作,提供独立架构、高性能设计和深度可定制化。支持智能协作团队(Crews模式)和事件工作流(Flows模式),适合复杂任务和企业级自动化需求。
适用场景 :内容团队协作、市场分析、复杂任务自动化。
LangGraph
特点 :基于图的架构,用于构建和管理复杂的生成式AI代理工作流。
适用场景 :复杂状态机、审批流、多步骤任务编排。
AutoGen
特点 :微软开源框架,强调多智能体对话协作,支持多种LLM和工具调用。提供动态对话和自适应工作流,适合研究型任务和交互式应用。
适用场景 :研究报告生成、任务拆解、数学和编程问题求解。
Smolagents
特点 :Hugging Face推出的轻量级库,设计简洁,支持代码代理和工具调用,模型无关且易于扩展。适合快速开发和私有化部署。
适用场景 :小模型场景、私有化部署、快速原型开发。
RAGFlow
特点 :端到端RAG解决方案,专注于深度文档理解和可控文本切片,支持多模态数据源和高质量信息检索。
适用场景 :文档解析、知识问答、多模态数据处理。
框架对比与选择建议
协作需求 :选择CrewAI(多智能体协作)或AutoGen(对话式协作)。
复杂流程 :LangGraph适合状态驱动的多步骤任务,AutoGen适合动态对话流程。
轻量级开发 :Smolagents适合快速构建和扩展。
文档处理 :RAGFlow是处理多模态文档和高质量检索的首选。
这些框架共同推动了AI Agent技术的发展,开发者可根据具体需求选择最合适的工具。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









