



点击下方卡片,关注“自动驾驶之心”公众号
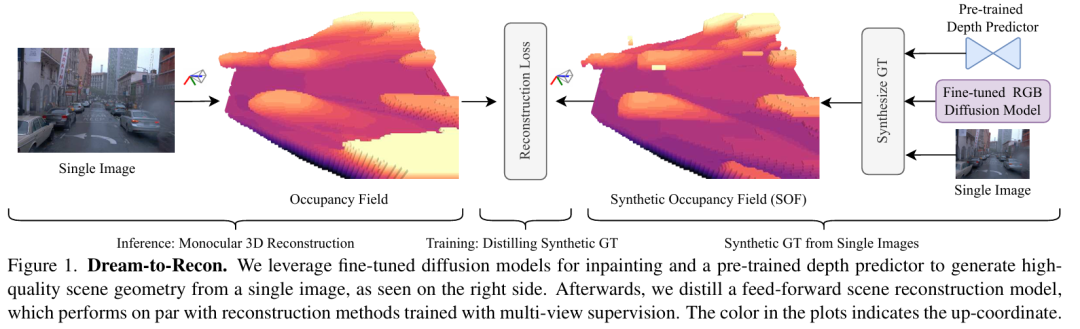
Dream-to-Recon
基于扩散-深度蒸馏的单目图像三维场景重建
慕尼黑工业大学团队提出 Dream-to-Recon,首次实现仅需单张图像训练的单目3D场景重建。该方法创新性地结合预训练扩散模型与深度网络,通过三阶段框架:
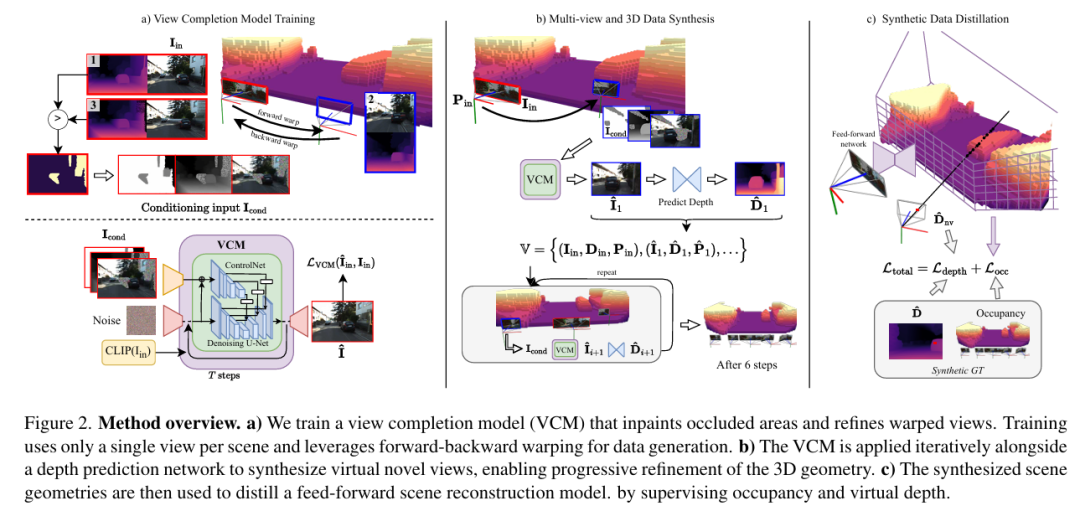
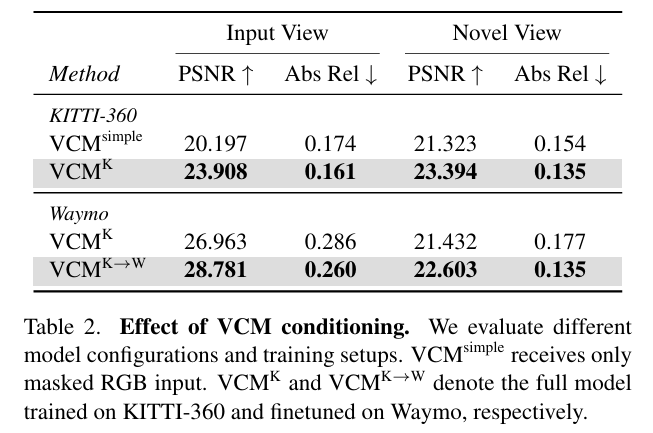
1)视图补全模型(VCM):基于ControlNet微调StableDiffusion-2.1,利用前向后向变形生成逼真遮挡修复(PSNR ↑23.9,Table 2);
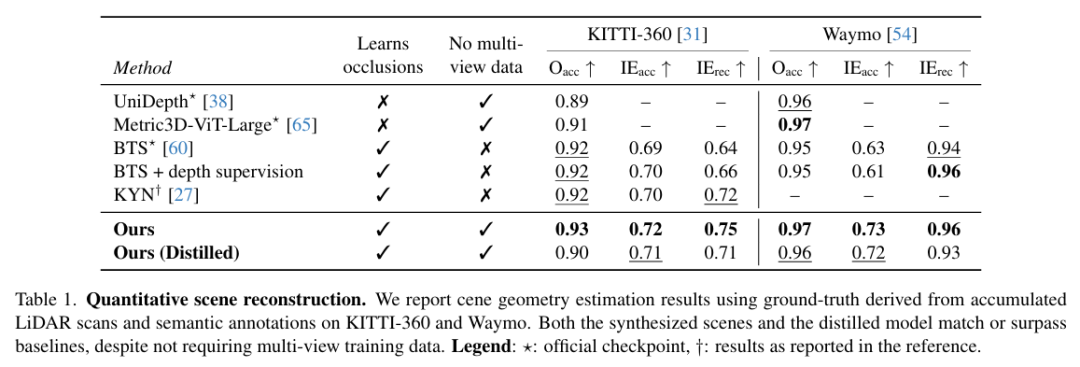
2)合成占据场(SOF):融合多虚拟视角深度图构建连续3D几何表示,在遮挡区域重建精度(IE_acc)达72%~73%(Table 1),超越多视角监督方法2%~10%;
3)轻量蒸馏模型:将生成几何转化为实时推理网络,在KITTI-360/Waymo上整体精度(O_acc)达90%~97%,推理速度70倍提升(75ms/帧),且成功重建动态物体(图3)。 该方法为自动驾驶与机器人提供无需复杂传感器标定的高效三维感知新范式。
论文标题:Dream-to-Recon: Monocular 3D Reconstruction with Diffusion-Depth Distillation from Single Images
论文链接:https://arxiv.org/abs/2508.02323
项目主页:https://philippwulff.github.io/dream-to-recon
更多学术界和工业界的前沿和讨论,欢迎加入自动驾驶之心知识星球,截止到目前,星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。

主要贡献:
专门的视图补全模型(View Completion Model, VCM):设计了一种基于ControlNet的扩散模型,能够仅使用单张图像进行训练,有效完成遮挡区域填充并消除扭曲图像中的伪影,解决了现有扩散模型在自动驾驶场景中应用的域适应问题。
合成占用场(Synthetic Occupancy Field, SOF)表征:提出了一种从多个合成视图构建密集3D场景几何的公式化方法,通过二进制占用场表示场景几何,能够有效处理不可见区域的重建。
单视图场景重建模型:通过将合成的高质量3D场景几何蒸馏(distill)到轻量级前馈网络中,实现了仅需单张图像输入的实时3D重建,性能匹配甚至超越了依赖多视图监督的最先进方法,特别在处理动态场景方面具有独特优势。
算法框架:
实验结果:
可视化:

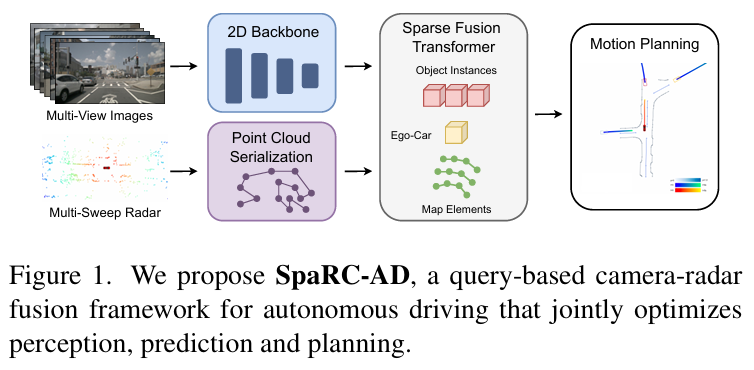
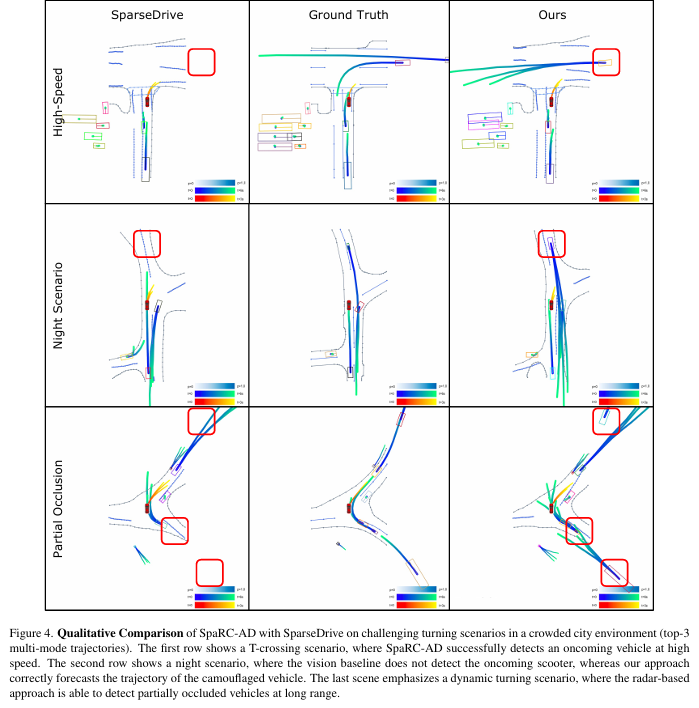
SpaRC-AD
面向端到端自动驾驶的RV融合基线框架
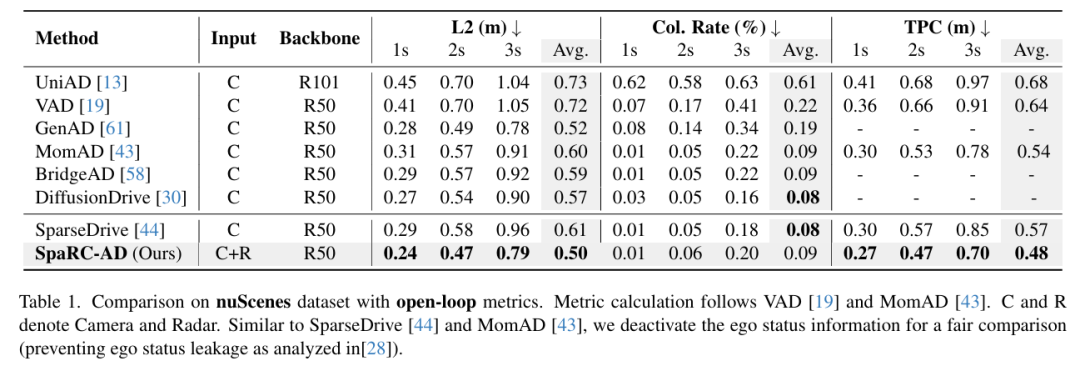
慕尼黑工业大学团队提出首个雷达-相机融合的端到端自动驾驶框架 SpaRC-AD,通过稀疏3D特征对齐与多普勒测速技术,在nuScenes基准上实现3D检测mAP提升4.8%、跟踪AMOTA提升8.3%、运动预测mADE降低4.0%、轨迹规划L2误差降低0.11m。
论文标题:SpaRC-AD: A Baseline for Radar-Camera Fusion in End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2508.10567
代码:https://phi-wol.github.io/sparcad/
主要贡献:
提出首个基于雷达的端到端自动驾驶基线,在关键基准数据集上实现了性能突破。
扩展稀疏融合设计,支持检测、跟踪和规划查询的协同优化。
基于雷达的整体融合策略在多项任务中实现显著提升:3D 检测(+4.8% mAP)、多目标跟踪(+8.3% AMOTA)、在线地图构建(+1.8% mAP)、运动预测(-4.0% mADE),同时优化了轨迹预测一致性(-9.0% TPC)和仿真成功率(+10.0%)。
在 open-loop nuScenes 和 closed-loop Bench2Drive 等多个基准上完成了全面评估,并通过定性分析验证了其在增强感知范围、提升运动建模精度和恶劣环境鲁棒性上的优势。
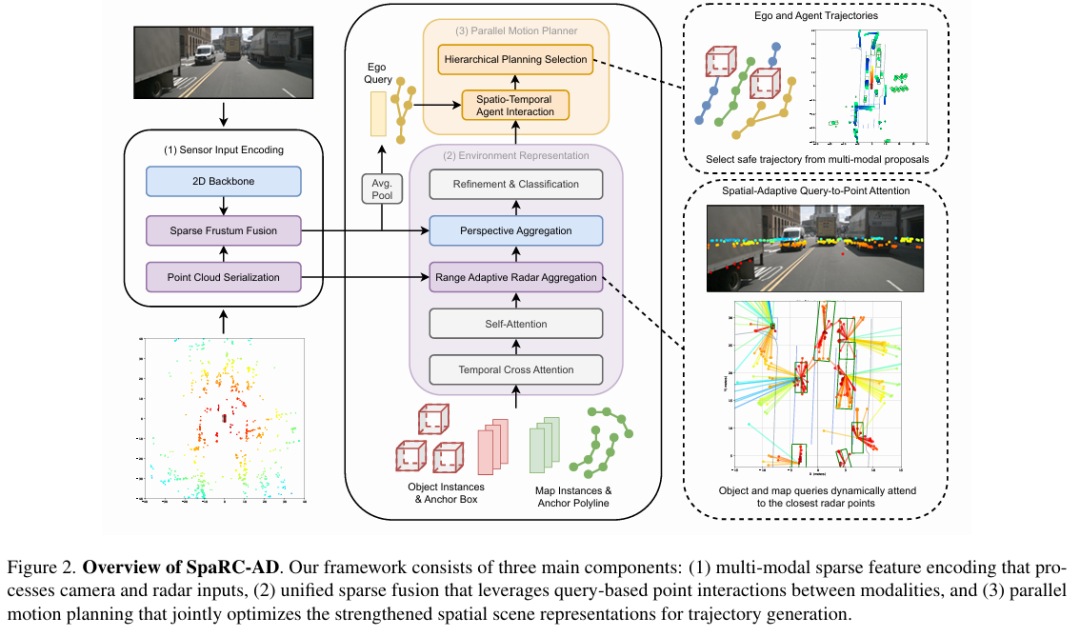
算法框架:
实验结果:

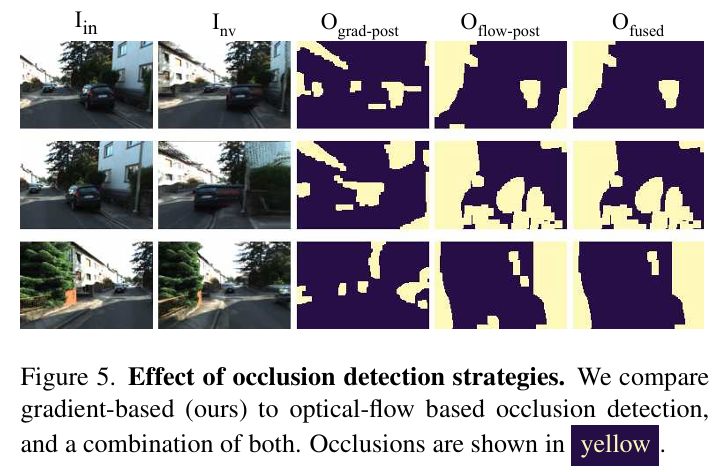
可视化:

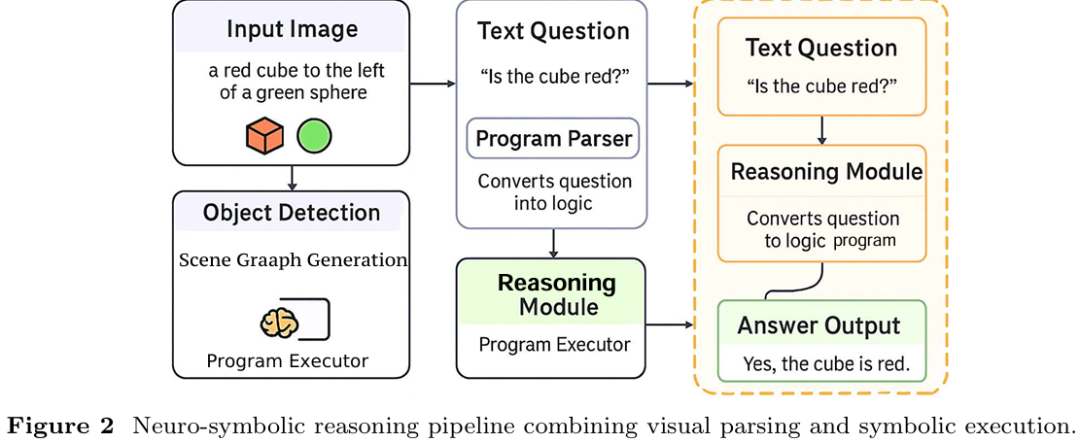
Reasoning in Computer Vision
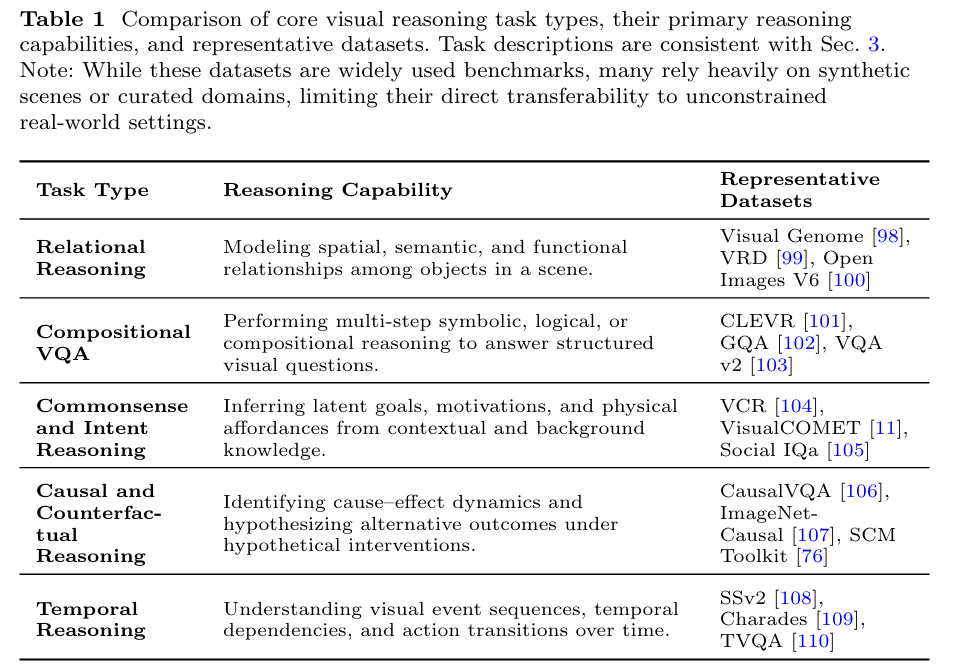
五大类别的统一框架、模型演进与评估挑战
本综述为视觉推理建立首个跨范式统一框架,揭示当前方法在开放环境泛化性和评估可靠性上的不足,呼吁社区向多模态因果基准与自适应弱监督学习演进,以推动安全关键领域(自动驾驶/医疗)的可信AI发展。
论文标题:Reasoning in Computer Vision: Taxonomy, Models, Tasks, and Methodologies
论文链接:https://arxiv.org/abs/2508.10523
主要贡献:
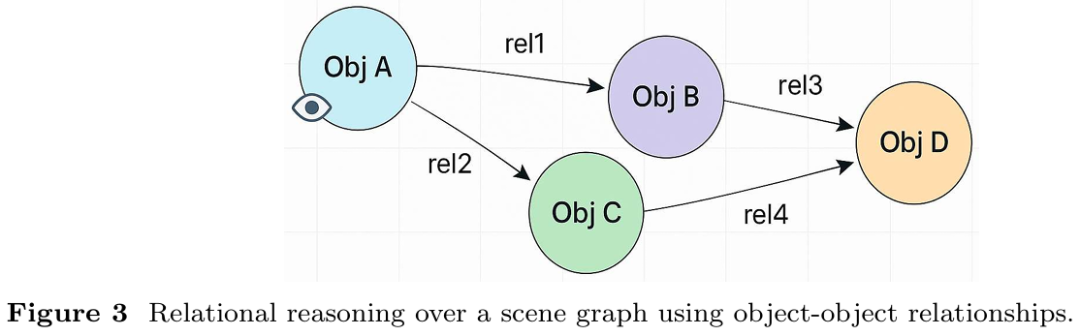
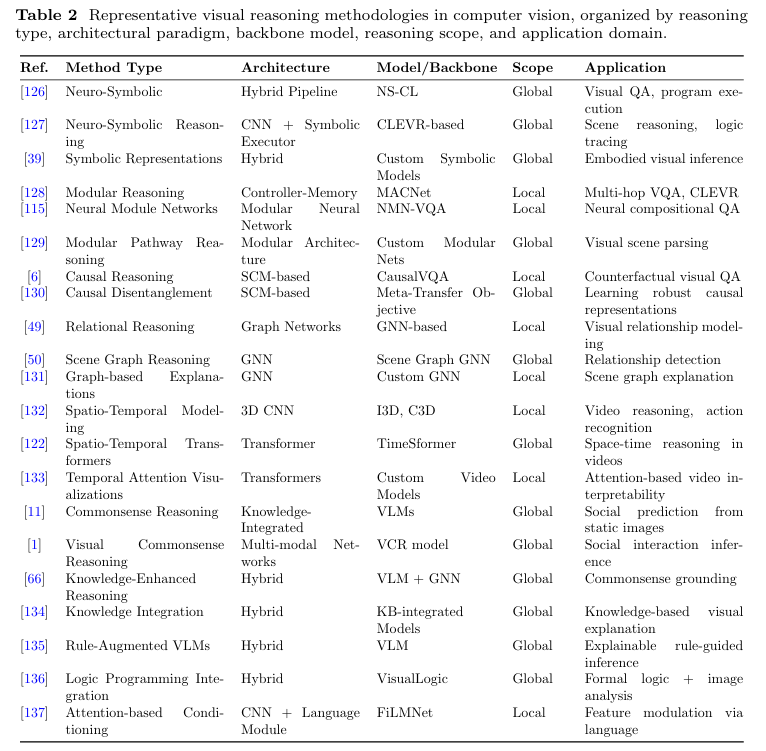
提出统一的视觉推理分类框架,将关系推理、符号推理、时序推理、因果推理和常识推理五大类型整合,系统关联方法、任务与评估指标,揭示不同推理范式的内在联系与差异。
整合新兴研究方向(如多模态思维链推理、视觉推理基础模型、跨任务基准数据集更新)到比较思维推理框架中,评估其技术优势、适用范围与局限性。
提出下一代视觉推理系统的前瞻性研究议程,指出当前方法在可扩展性、跨域泛化、弱监督下的可解释性等方面的不足,并明确符号与亚符号推理融合、跨域自适应架构设计、多类型推理基准测试等研究方向。
算法框架:
实验结果:
可视化:
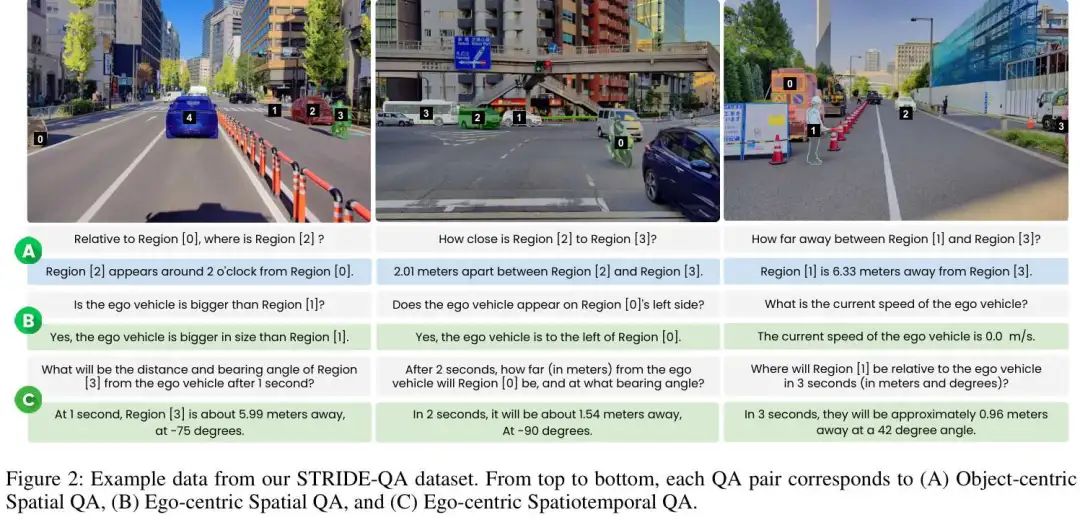
STRIDE-QA
面向城市驾驶场景时空推理的大规模视觉问答数据集
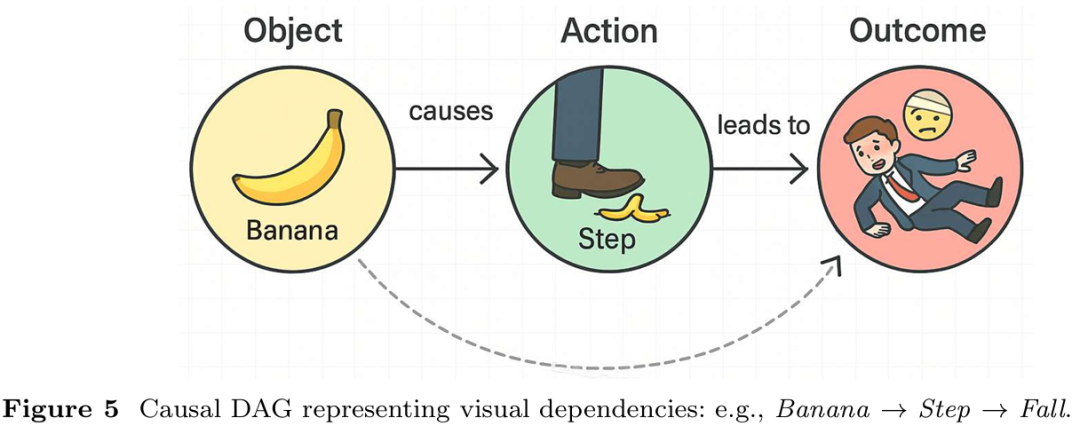
图灵、筑波大学等团队构建了目前最大规模自动驾驶时空推理VQA数据集STRIDE-QA(100小时数据/285K帧/16M QA对),通过多传感器自动标注实现厘米级几何精度,微调模型时空定位成功率(MLSR)达55.0%。
论文标题:STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
论文链接:https://arxiv.org/abs/2508.10427
项目主页:https://turingmotors.github.io/stride-qa/
主要贡献:
定义了三个新颖的以自我为中心的视觉问答(VQA)任务,联合要求空间定位和短期预测推理,解决自动驾驶系统在复杂交通场景中的核心挑战。
提出 STRIDE-QA 数据集,这是一个大规模数据集,包含 1600 万条问答对,在 28.5 万帧城市驾驶视频上进行密集标注,支持 VLMs 在细粒度空间和短期时间推理上的有监督训练,且这些推理基于真实交通动态。
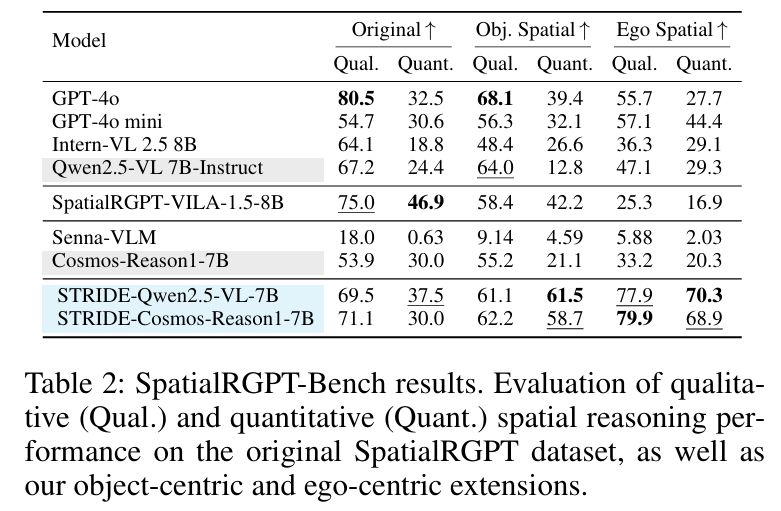
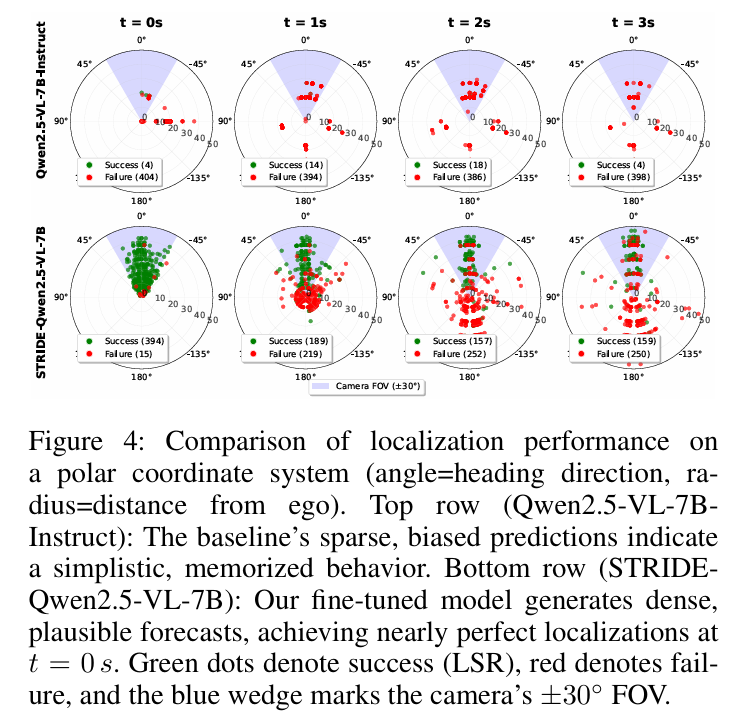
实验表明,现有通用 VLMs 在时空推理上表现不佳,而在 STRIDE-QA 上微调的模型性能显著优于基线,其中最优模型 STRIDE-Qwen2.5-VL-7B 达到当前最佳性能,证明该数据集对驾驶场景时空理解的有效性。
算法框架:
实验结果:
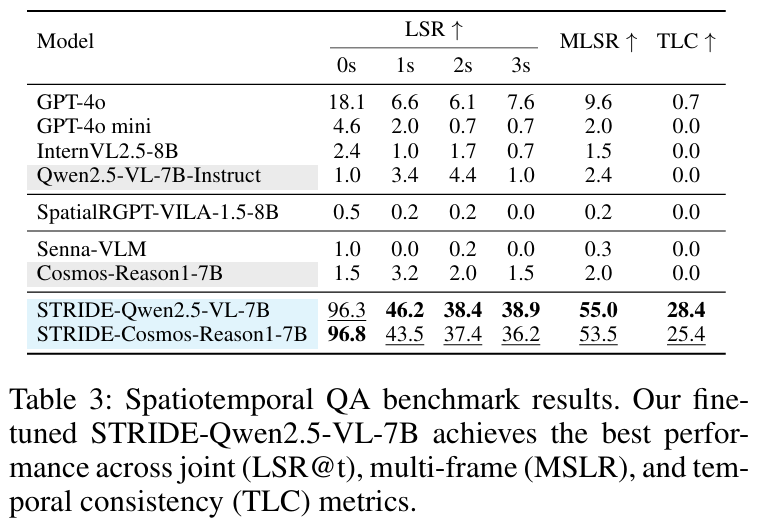
可视化:

更多学术界和工业界的前沿和讨论,欢迎加入自动驾驶之心知识星球,截止到目前,星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









