



点击下方卡片,关注“自动驾驶之心”公众号
>>直播和内容获取转到 → 自动驾驶之心知识星球
点击按钮预约直播
视觉语言模型(VLM)的最新进展激发了人们将其应用于自动驾驶的兴趣,尤其是通过自然语言生成可解释的驾驶决策。然而关于VLM是否能为驾驶提供基于视觉的、可靠的且可解释的解释,这一假设在很大程度上尚未得到验证。为填补这一空白,我们推出了DriveBench,这是一个基准数据集,旨在评估VLM在17种设置下的可靠性,包含19,200帧、20,498个问答对、三种问题类型、四种主流驾驶任务以及总共12个流行的VLM。
自动驾驶之心很荣幸邀请到加州大学尔湾分校在读博士生 - 谢少远,为大家分享介绍这篇ICCV 2025中稿的DriveBench。一个专为自动驾驶设计的视觉语言模型(VLMS)基准测试框架,旨在评估VLMs在不同环境和任务下的可靠性。DriveBench涵盖感知、预测、规划和行为四大核心任务,并引入 15种OoD类型,以系统性测试VLMs 在复杂驾驶场景中的可靠性。今天上午十一点,锁定自动驾驶之心直播间,我们不见不散~
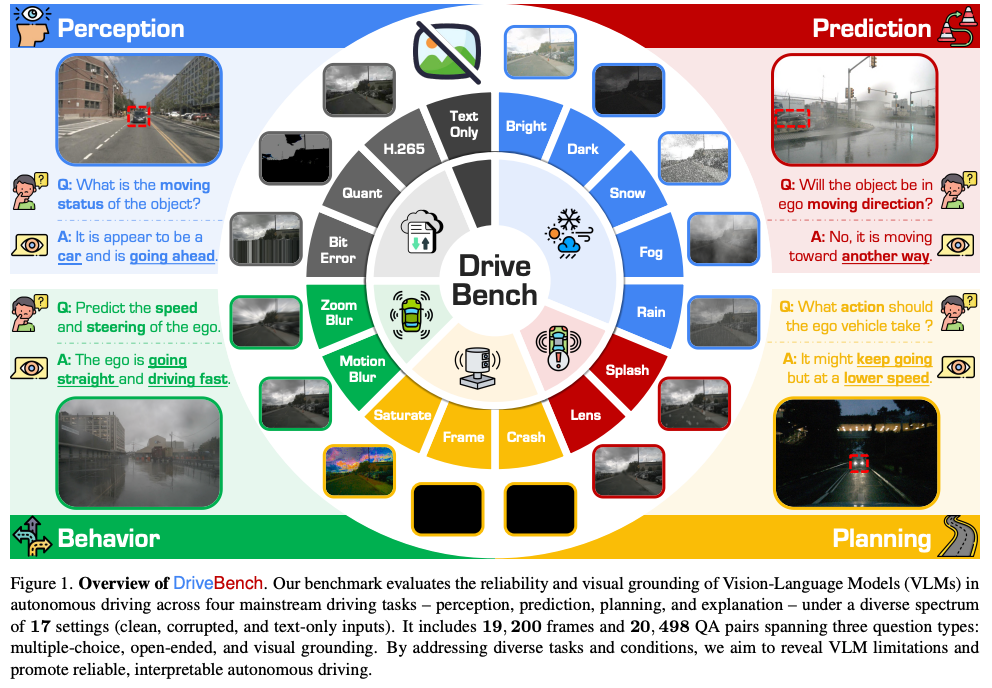
论文标题:Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
论文链接:https://arxiv.org/abs/2501.04003
项目链接:https://drive-bench.github.io/

更多精彩回顾
插入视频号视频
🚀 直播精华看不够?完整版深度内容已独家上线知识星球「自动驾驶之心」!涵盖所有技术细节、QA及未公开彩蛋。深度解析!
复旦BezierGS:利用贝塞尔曲线实现驾驶场景SOTA重建~
清华&博世开源SOTA性能纯血VLA:Impromptu-VLA告别双系统~
清华&吉利Challenger框架:自动驾驶对抗场景高效生成~
干货满满,快来加入

END

















 75
75

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









