



点击下方卡片,关注“自动驾驶之心”公众号
>>直播和内容获取转到 → 自动驾驶之心知识星球
点击按钮预约直播
在自动驾驶领域,通过大规模数据来扩展视觉-语言-动作模型,为构建更通用的驾驶智能提供了一条充满前景的道路。然而,VLA模型一直面临"监督缺失"的问题:其庞大的模型能力仅由稀疏、低维的动作信号进行监督,导致其大部分表征潜力未能得到充分利用。
为解决此问题,中科院和华为引望的团队提出了 DriveVLA-W0,一种利用世界模型来预测未来图像的训练范式。为验证DriveVLA-W0的通用性,本文在两种主流VLA架构上展开验证:针对采用离散视觉token的VLA模型,设计自回归世界模型;针对基于连续视觉特征的VLA模型,设计扩散世界模型。基于世界建模学习到的丰富表征,本文进一步引入轻量级动作专家(action expert),以解决实时部署中的推理耗时问题。
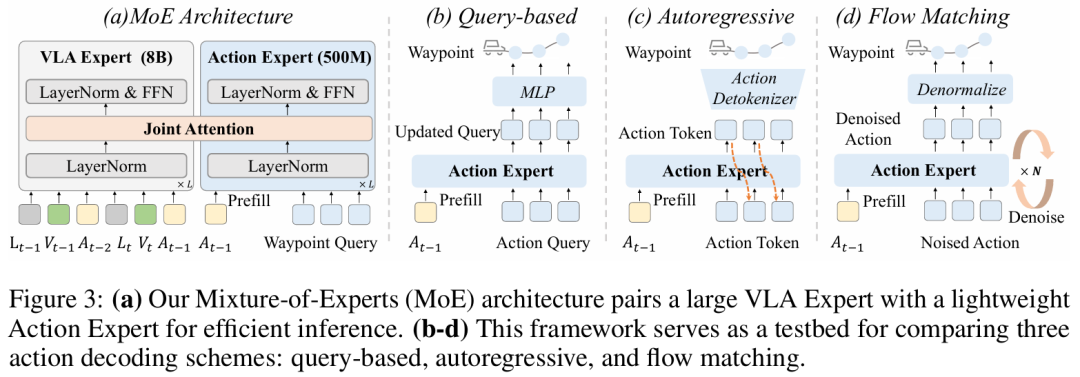
在NAVSIM v1/v2基准测试和一个规模大680倍的内部数据集上进行的大量实验表明,DriveVLA-W0显著优于BEV和VLA基线方法。关键在于,它放大了数据Scaling Law的效果,表明随着训练数据集规模的增大,性能提升速度会加快。我们很荣幸邀请到一作李颖彦博士,为大家分享这篇最新的工作!今晚七点半锁定自动驾驶之心直播间~
论文标题:DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
论文链接:https://arxiv.org/abs/2510.12796
Code:https://github.com/BraveGroup/DriveVLA-W0
分享介绍

更多精彩回顾
🚀 直播精华看不够?完整版深度内容已独家上线知识星球「自动驾驶之心」!涵盖所有技术细节、QA及未公开彩蛋。深度解析!
DriveBench:VLM在自动驾驶中真的可靠吗?(ICCV'25)
AI Day直播 | LangCoop:自动驾驶首次以“人类语言”的范式思考
干货满满,快来加入

END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









