



点击下方卡片,关注“自动驾驶之心”公众号
视觉语言模型(Vision-Language Model, VLM) 正以其独特的跨模态理解与推理能力,成为赋能下一代自动驾驶系统的关键引擎。VLM的核心在于打通视觉与语言之间的壁垒,让自动驾驶不仅能“看见”道路,更能像人类一样“理解”场景、意图并进行深层次的推理。
在自动驾驶的复杂环境中,VLM展现出强大的应用潜力:
环境感知与深度理解: VLM能够超越传统视觉模型,结合相机图像或视频流,理解交通场景中的语义信息。例如,它不仅能识别物体是“车”或“人”,更能理解“行人正在挥手示意过马路”、“前方车辆正在打开双闪可能抛锚”、“路牌上的文字是‘学校区域减速慢行’”等复杂语义,为系统提供更丰富、更贴近人类认知的环境模型。
场景描述与决策解释: VLM可以将复杂的视觉场景转化为清晰的自然语言描述,为自动驾驶系统的决策提供可解释性。这不仅有助于开发调试(理解系统“为何”做出某个决策),也为乘客或监管者提供透明的驾驶意图说明(如“我正在变道以避开前方施工区域”),增强信任感。
复杂指令理解与交互: 面向未来的智能座舱和人车交互,VLM是实现自然语言交互的核心。乘客或远程监控员可以通过口语化指令(如“在下一个便利店门口靠边停一下”、“小心右边突然冲出来的自行车”)与车辆沟通,VLM能准确理解意图并指导系统执行或预警。
可以说,VLM正将自动驾驶系统的感知与认知能力推向新高度,使其从“看得清”走向“懂得深”。它不仅是理解复杂开放世界的关键,也是实现人车自然协同、构建可信赖自动驾驶体验的重要桥梁。接下来,自动驾驶之心将为大家系统梳理VLM在基础模型中的最新研究与应用进展,探索其如何重塑自动驾驶的未来图景。本文全部文章已汇总至『自动驾驶之心知识星球』,欢迎加入我们,共同探索AI驱动的自动驾驶前沿!

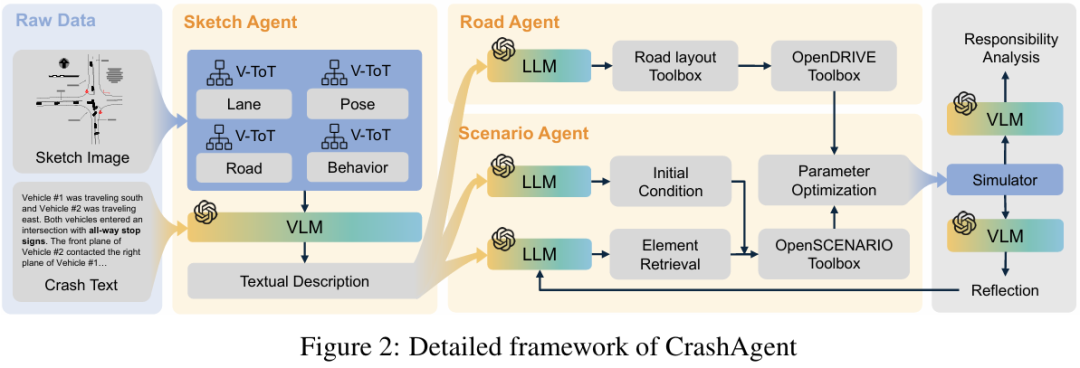
CrashAgent
标题:CrashAgent: Crash Scenario Generation via Multi-modal Reasoning
链接:https://www.arxiv.org/abs/2505.18341
作者单位:卡内基梅隆大学、NVIDIA、西北大学
自动驾驶算法的训练与评估需要多样化的场景。然而,现有数据集主要包含人类驾驶员展示的正常驾驶行为,导致安全关键案例数量有限。这种通常被称为长尾分布的不平衡性,限制了驾驶算法从涉及风险或失效的关键场景中学习的能力——而这些场景对于人类高效提升驾驶技能至关重要。为生成此类场景,本文利用多模态大语言模型 (Multi-modal Large Language Models) 将事故报告转换为结构化场景格式,该格式可直接在仿真环境中执行。具体而言,本文提出了 CrashAgent,一个多智能体框架 (multi-agent framework),旨在解析多模态的真实世界交通事故报告,以生成道路布局以及自车(ego vehicle)和周围交通参与者的行为。本文从多个角度全面评估生成的碰撞场景,包括布局重建准确性、碰撞发生率和多样性。最终产生的高质量、大规模碰撞数据集将公开提供 (publicly available),以支持开发能够处理安全关键情况的自动驾驶算法。
算法概览:
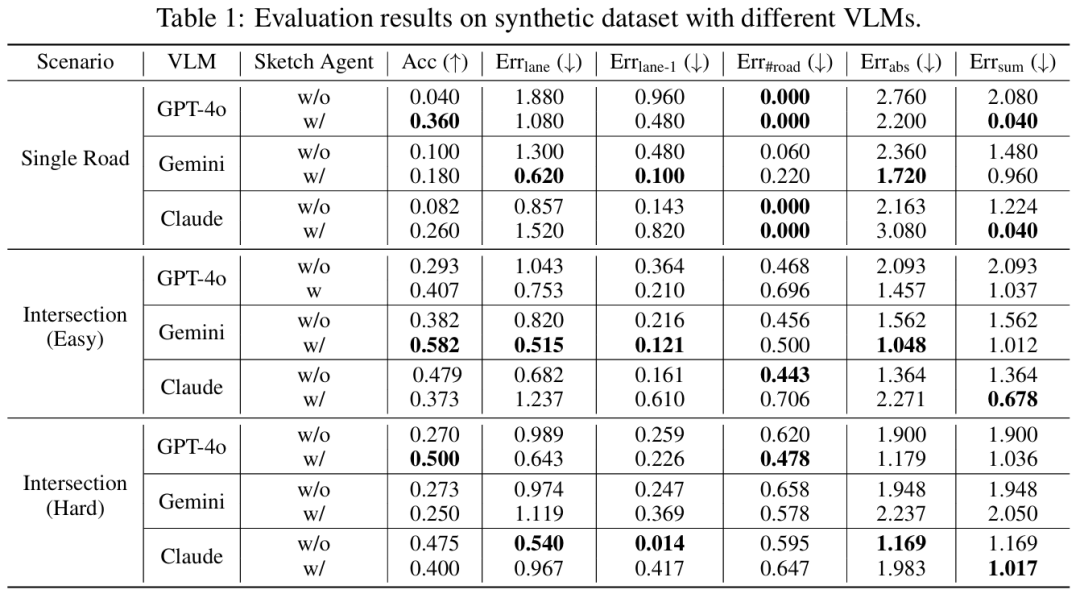
主要实验结果:
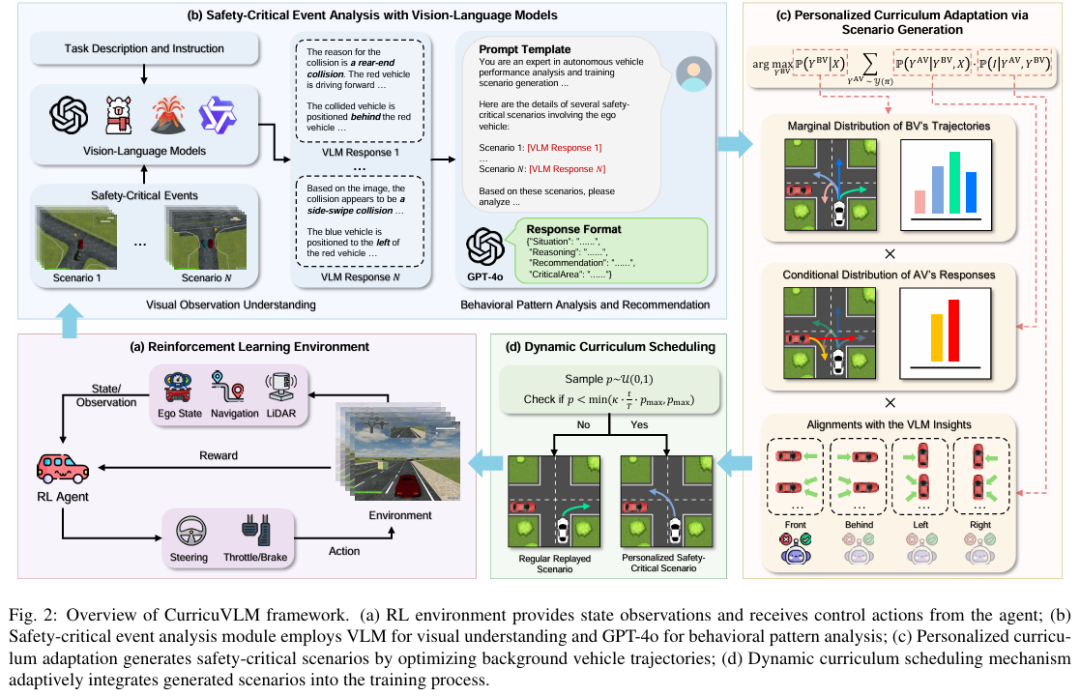
CurricuVLM
标题:CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
链接:https://arxiv.org/abs/2502.15119
项目主页:https://zihaosheng.github.io/CurricuVLM/
作者单位:美国威斯康星大学麦迪逊分校,普渡大学,谷歌
确保自动驾驶系统的安全仍然是一个关键挑战,尤其是在处理罕见但可能灾难性的安全关键场景时。虽然现有研究探索了为自动驾驶车辆(AV)测试生成安全关键场景,但如何有效地将这些场景纳入策略学习以增强安全性的工作仍然有限。此外,开发适应自动驾驶车辆不断演化的行为模式与性能瓶颈的训练课程在很大程度上尚未被探索。为应对这些挑战,本文提出了 CurricuVLM,一个利用视觉语言模型(VLMs) 为自动驾驶智能体实现个性化课程学习的新颖框架。本文的方法独特地利用了VLMs的多模态理解能力来分析智能体行为、识别性能弱点,并动态生成量身定制的训练场景以进行课程适应。通过对不安全驾驶情境的叙事描述进行综合分析,CurricuVLM执行深入推理以评估自动驾驶车辆的能力并识别关键行为模式。该框架随后合成针对这些已识别局限性的定制化训练场景,从而实现有效且个性化的课程学习。在Waymo Open Motion数据集上进行的大量实验表明,CurricuVLM在常规和安全关键场景下均优于最先进的基线方法,在导航成功率、驾驶效率和安全性指标方面均取得了卓越性能。进一步分析揭示,CurricuVLM可作为通用方法,与各种强化学习(RL)算法集成以增强自动驾驶系统。
算法概览:
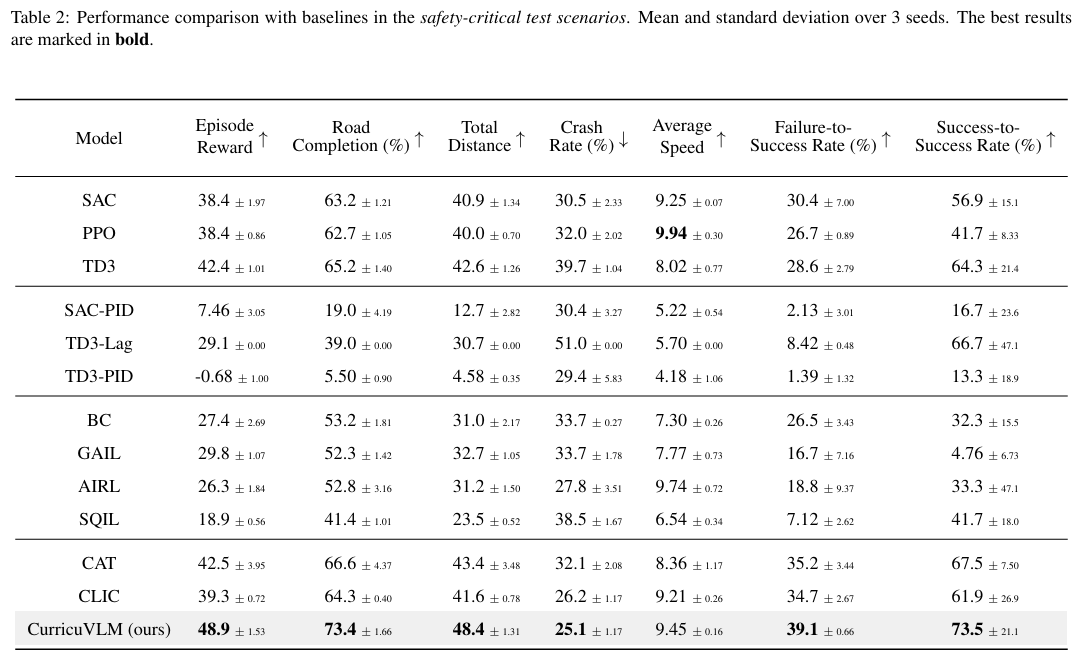
主要实验结果:
From Accidents to Insights
标题:From Accidents to Insights: Leveraging Multimodal Data for Scenario-Driven ADS Testing
链接:https://arxiv.org/abs/2502.02025
作者单位:麦考瑞大学,北德克萨斯大学
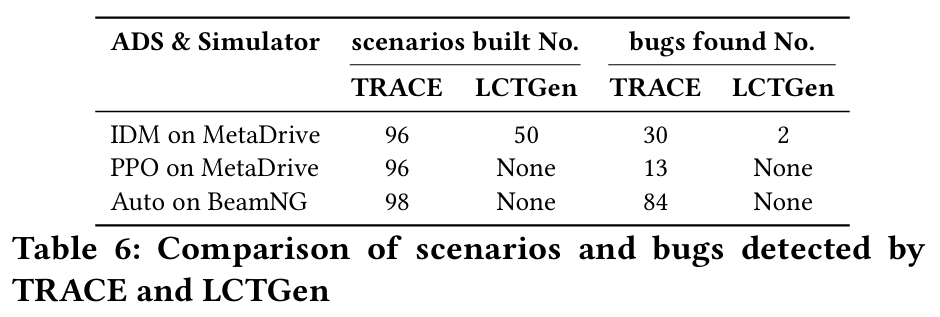
自动驾驶系统(ADS)的快速发展亟需鲁棒的软件测试来确保安全性和可靠性。然而,自动化生成可扩展且具体的测试场景仍是重大挑战。当前基于场景的测试用例生成方法常面临场景不真实、车辆轨迹不准确等局限,主要源于数据提取过程中的地图信息丢失,以及缺乏有效机制缓解大语言模型(LLM)的幻觉问题。本文提出 TRACE(基于关键场景的ADS测试用例生成框架),通过利用多模态数据从真实车祸报告中提取高挑战性场景,以较少数据构建大量关键测试用例,显著提升ADS缺陷检测效率。结合上下文学习、思维链提示和自验证技术,本文利用LLM从事故报告中提取环境与路网信息;在车辆轨迹规划中,集成含地图信息和车辆坐标的数据作为知识库,构建具备路径规划能力的LLM模型 TraceMate。基于50份真实事故报告,本方法在MetaDrive和BeamNG仿真平台上成功测试三种ADS模型。在生成的290个测试场景中,127个被识别为关键场景(引发车辆碰撞)。用户反馈表明,TRACE的场景重建准确率显著优于现有技术——77.5%的场景被评为"基本"或"完全"一致,而最佳基线方法SOTA-LCTGen仅达27%。
算法概览:
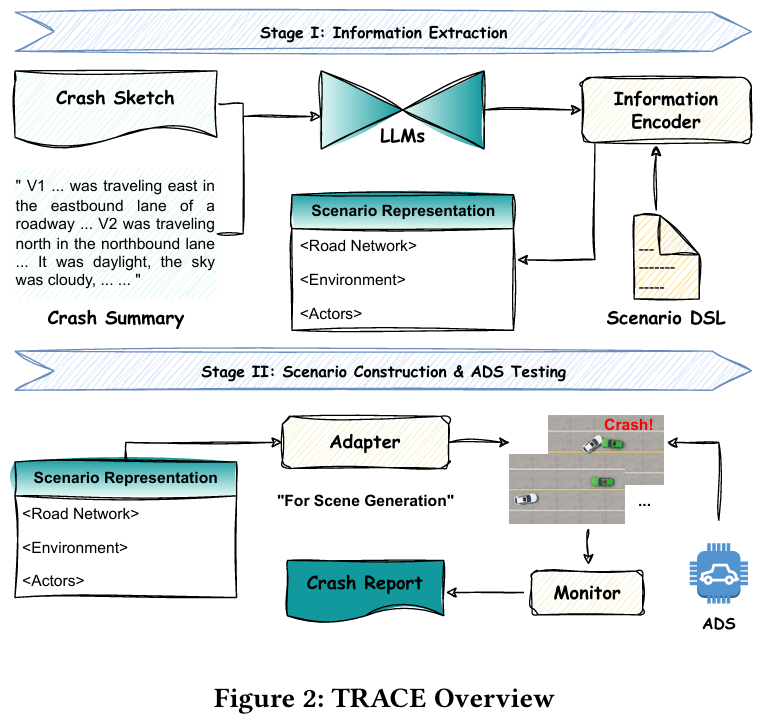
主要实验结果:
Generating OOD
标题:Generating Out-Of-Distribution Scenarios Using Language Models
链接:https://arxiv.org/abs/2411.16554
作者单位:麻省理工学院,马萨诸塞大学阿默斯特分校 ,丰田研究院
由机器学习技术驱动的自动驾驶汽车的部署,需要在多样化的现实世界环境中进行广泛测试,稳健处理边缘案例和分布外(Out-Of-Distribution, OOD)场景,并进行全面的安全验证,以确保这些系统在不可预测条件下能够安全有效地行驶。解决分布外(OOD)驾驶场景对于提升安全性至关重要,因为OOD场景有助于验证车辆自主系统技术栈中模型的可靠性。然而,由于OOD场景在长尾分布中的稀疏性及其在城市驾驶数据集中的罕见性,生成此类场景极具挑战性。近期,大语言模型(Large Language Models, LLMs)在自动驾驶领域展现出潜力,特别是在零样本泛化(zero-shot generalization)和常识推理(common-sense reasoning)能力方面。本文利用LLMs的这些优势,提出一个用于生成多样化OOD驾驶场景的框架。本文的方法利用LLMs构建一个分支树结构(branching tree),其中每条分支代表一个独特的OOD场景。这些场景随后通过一个自动化框架在CARLA仿真器中实现,该框架确保场景增强(scene augmentation)与相应的文本描述保持一致。本文通过广泛的仿真实验评估了该框架,并采用一个衡量场景丰富度的多样性指标(diversity metric)来评估其性能。此外,本文引入了一种新的“OOD偏离度”(OOD-ness)指标,用于量化所生成场景偏离典型城市驾驶条件的程度。进一步地,本文探索了现代视觉语言模型(Vision-Language Models, VLMs)在解读所仿真的OOD场景并实现安全导航方面的能力。本文的研究结果为语言模型在解决城市驾驶背景下OOD场景问题中的可靠性提供了有价值的见解。
算法概览:
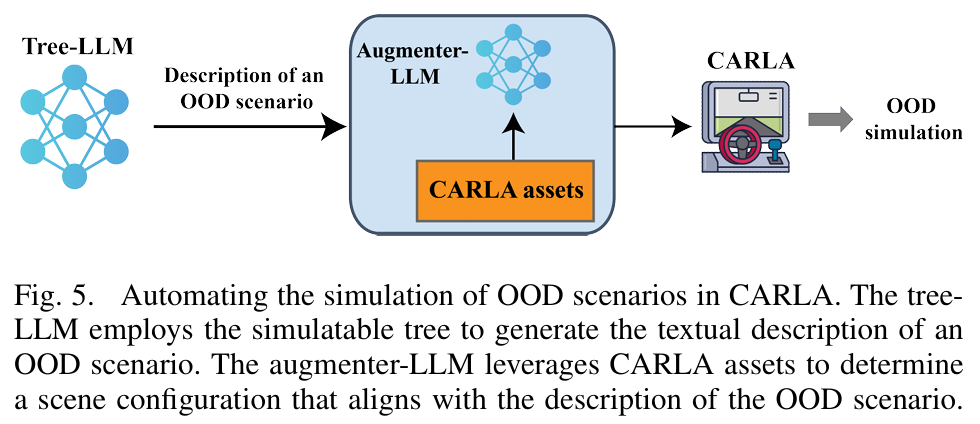
主要实验结果:

From Dashcam Videos to Driving Simulations
标题:From Dashcam Videos to Driving Simulations: Stress Testing Automated Vehicles against Rare Events
链接:https://arxiv.org/abs/2411.16027
作者单位:丰田北美研究院,伊利诺伊大学厄巴纳 - 香槟分校
在仿真环境中使用真实的驾驶场景测试自动驾驶系统(ADS)对于验证其性能至关重要。然而,将真实世界的驾驶视频转化为仿真场景面临重大挑战,这源于高维视频数据解释的复杂性以及精确手动场景重建的耗时性。在本研究中,本文提出了一种新颖的框架,可自动将真实世界的车辆碰撞视频转换为用于ADS测试的详细仿真场景。本文的方法利用提示工程优化的视频语言模型(VLM),将行车记录仪(dashcam)视频片段转换为SCENIC脚本。这些脚本定义了CARLA仿真器中的环境和驾驶行为,从而能够生成逼真的仿真场景。重要的是,本文的框架并非单纯追求一对一的场景重建,而是侧重于从原始视频中捕捉核心驾驶行为,同时提供天气或道路条件等参数的灵活性,以支持基于搜索的测试。此外,本文引入了一种相似性度量指标,通过比较真实视频与仿真视频之间驾驶行为的关键特征来提供反馈,从而迭代地优化生成的场景。本文的初步结果表明,该方法具有显著的时间效率,可在数分钟内完成全自动、无需人工干预的真实到仿真(real-to-sim)转换,同时保持对原始驾驶事件的高保真度。
算法概览:
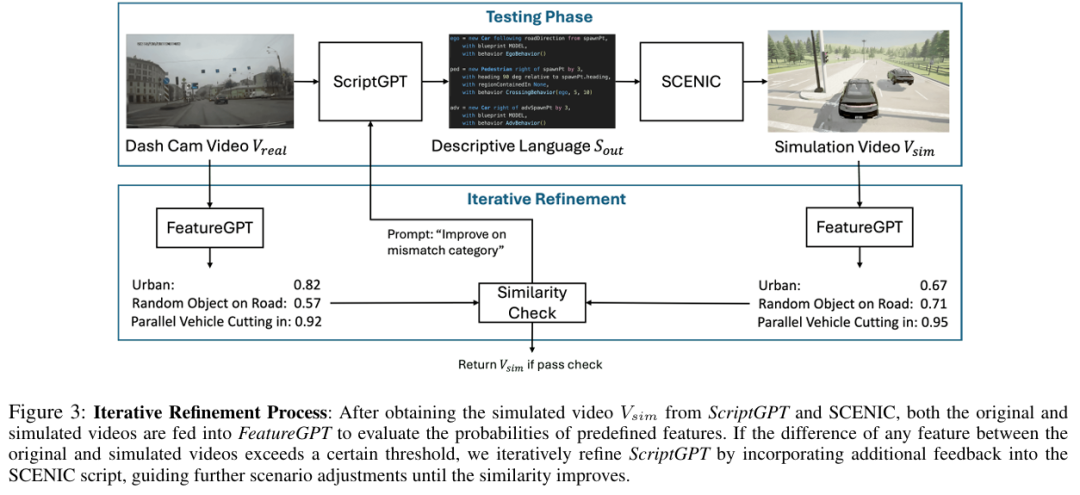
主要实验结果:
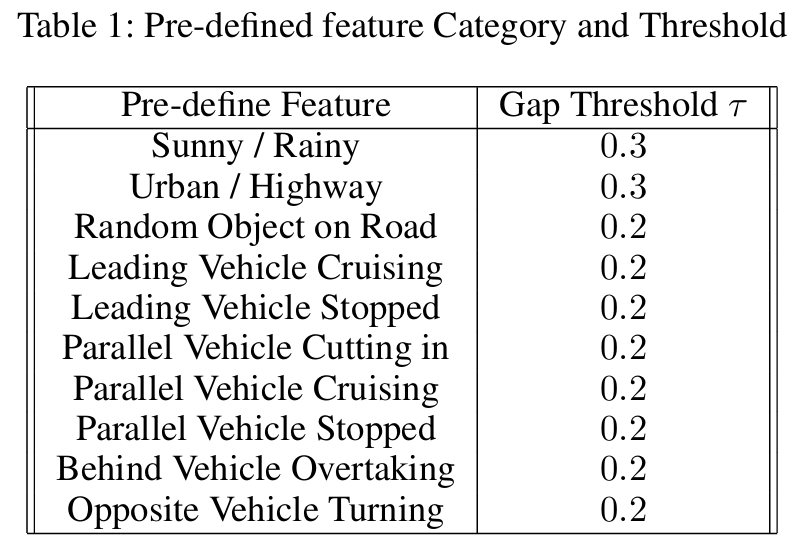
OmniTester
标题:Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles
链接:https://arxiv.org/abs/2409.06450
作者单位:清华大学,公安部道路交通安全研究院
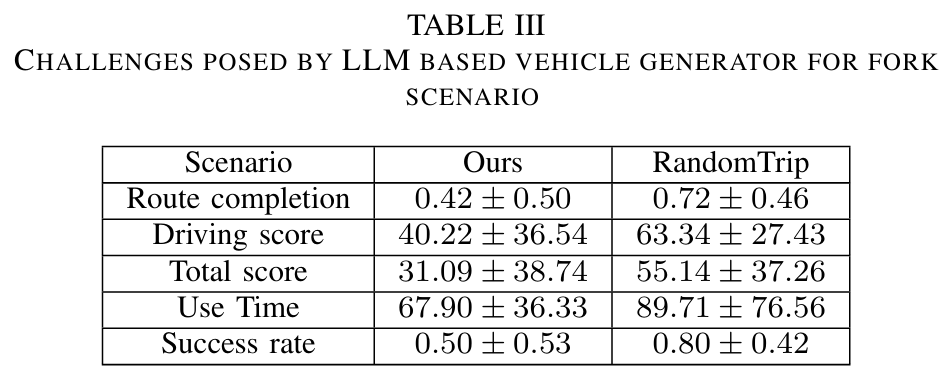
极端案例(corner cases)的生成对于自动驾驶车辆(AV)道路部署前的高效测试至关重要。然而,现有方法难以满足多样化的测试需求,且普遍缺乏对未知场景的泛化能力,从而降低了生成场景的实用性与可用性。本研究提出 OmniTester:一种基于多模态大语言模型(LLM)的框架,充分利用LLM的世界知识与推理能力,在仿真环境中生成高真实性与多样化的测试场景。除提示工程外,本文集成交通仿真工具SUMO以简化LLM生成的代码复杂度,并引入检索增强生成(RAG)与自改进机制,增强LLM对场景的理解能力,提升生成场景的真实性。实验证明,该方法在生成三类复杂挑战性场景时具备优异的可控性与真实性,同时依托LLM的泛化能力,成功实现了基于事故报告的新场景重建。
算法概览:
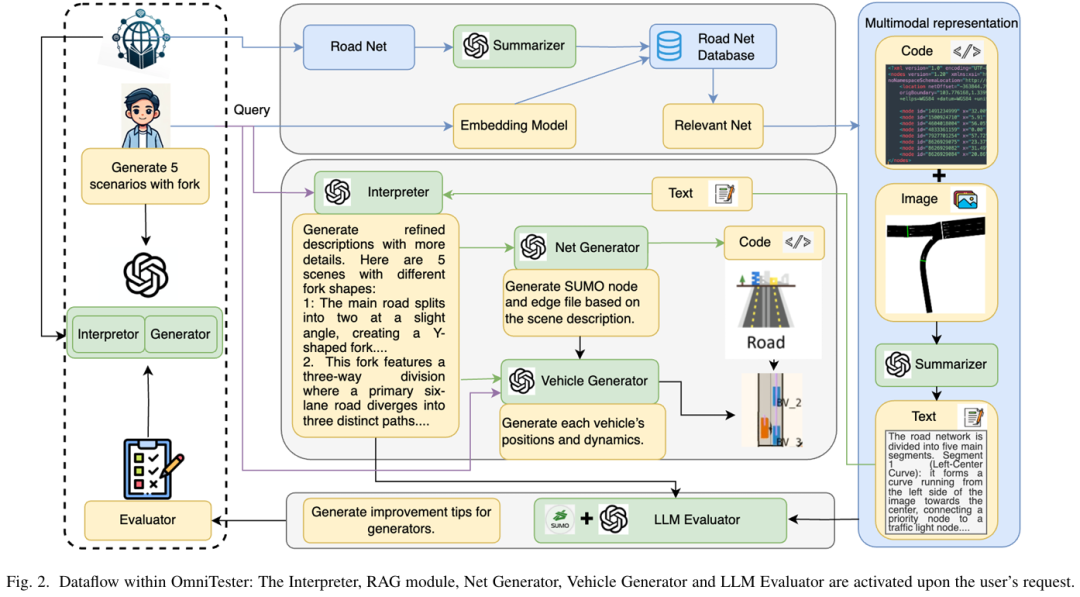
主要实验结果:
DriveGenVLM
标题:DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
链接:https://ieeexplore.ieee.org/abstract/document/10786438
作者单位:哥伦比亚大学
自动驾驶技术的进步亟需更先进的方法来理解和预测现实场景。视觉语言模型(VLMs)作为革命性工具崭露头角,在自动驾驶领域展现出巨大潜力。本文提出DriveGenVLM框架,通过生成驾驶视频并利用VLMs进行场景理解。为实现这一目标,本文采用基于去噪扩散概率模型(DDPM)的视频生成框架,旨在预测真实世界视频序列。随后通过预训练模型"第一人称视角视频高效上下文学习"(EILEV)评估生成视频在VLMs中的适用性。该扩散模型基于Waymo开放数据集训练,并采用弗雷歇视频距离(FVD)指标评估生成视频的质量与真实性。EILEV为生成视频提供场景描述,这些描述在自动驾驶领域具有重要价值:可增强交通场景理解能力、辅助导航决策并提升路径规划能力。DriveGenVLM框架将视频生成与VLMs深度融合,标志着利用先进人工智能模型解决自动驾驶复杂挑战的重大突破。
WEDGE
标题:WEDGE: A multi-weather autonomous driving dataset built from generative vision-language models
链接:https://arxiv.org/pdf/2305.07528
项目主页:https://infernolia.github.io/WEDGE
作者单位:卡内基梅隆大学,印度共生国际大学
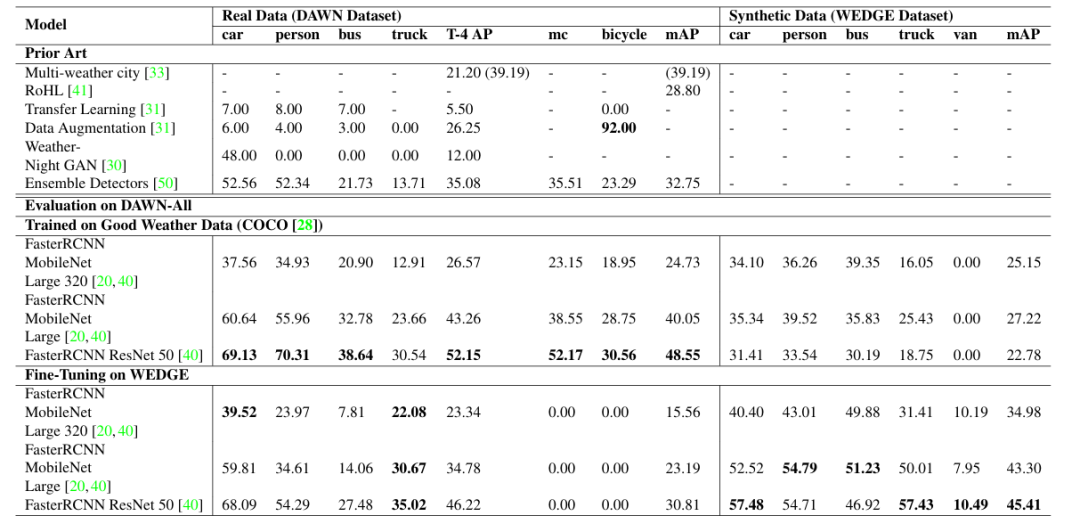
开放道路环境对自动驾驶感知提出了诸多挑战,其中极端天气条件导致的低能见度尤为突出。在良好天气数据集上训练的模型,在面对这些分布外(out-of-distribution)场景时,其检测性能往往显著下降。为增强感知系统的对抗鲁棒性(adversarial robustness),本文提出了 WEDGE(WEather images by DALL-E GEneration):一个通过提示(prompting)利用视觉语言生成模型构建的合成数据集。WEDGE 包含 3360 张图像,涵盖 16 种极端天气条件,并手工标注了 16513 个边界框,支持天气分类和 2D 目标检测任务的研究。本文从研究角度分析了 WEDGE,验证了其对于极端天气自动驾驶感知的有效性。本文为分类和检测任务建立了基线性能,测试准确率达到 53.87%,平均精度(mAP)达到 45.41。最重要的是,WEDGE 可用于微调(fine-tune) 最先进的检测器,在真实世界天气基准测试(如 DAWN)上,将 SOTA 性能提升了 4.48 AP(对于卡车等生成效果良好的类别)。WEDGE 的收集遵循 OpenAI 的使用条款,并以 CC BY-NC-SA 4.0 许可协议公开发布。
算法概览:

主要实验结果:
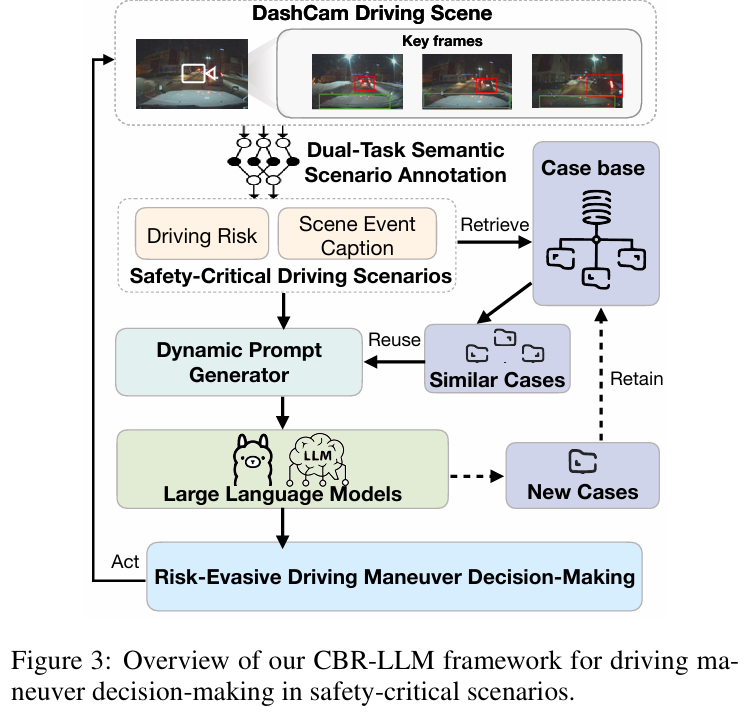
CBR-LLM
标题:Case-based Reasoning Augmented Large Language Model Framework for Decision Making in Realistic Safety-Critical Driving Scenarios
链接:https://arxiv.org/abs/2506.20531
作者单位:NICT
在安全关键场景中驾驶需要快速、具有情境感知的决策,这种决策既要基于情境理解,又要依托经验推理。大语言模型(LLMs)凭借其强大的通用推理能力,为这类决策提供了颇具前景的基础。然而,由于在领域适配、情境锚定以及缺乏在动态、高风险环境中做出可靠且可解释决策所需的经验知识等方面存在挑战,它们在自动驾驶中的直接应用仍受到限制。为填补这一空白,本文提出了一种基于案例推理增强的大语言模型(CBR-LLM)框架,用于复杂风险场景中的规避机动决策。我们的方法将行车记录仪视频输入中的语义场景理解与相关过往驾驶案例的检索相结合,使 LLMs 能够生成既符合情境又与人类行为一致的机动建议。在多个开源 LLMs 上进行的实验表明,我们的框架提高了决策准确性、推理合理性以及与人类专家行为的一致性。风险感知提示策略进一步提升了在不同风险类型下的性能,而基于相似度的案例检索在引导上下文学习方面始终优于随机抽样。案例研究进一步证明了该框架在具有挑战性的现实世界条件下的稳健性,突显了其作为智能驾驶系统中一种自适应且可信的决策支持工具的潜力。
算法概览:
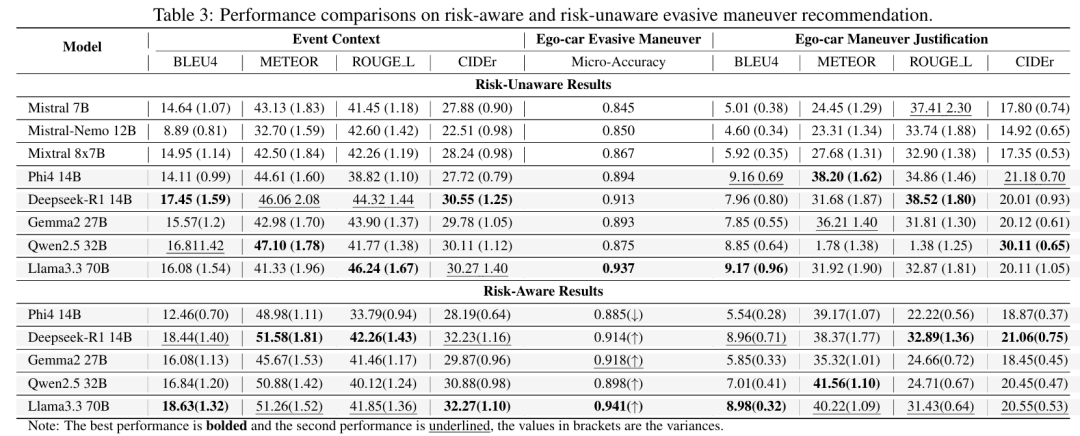
主要实验结果:
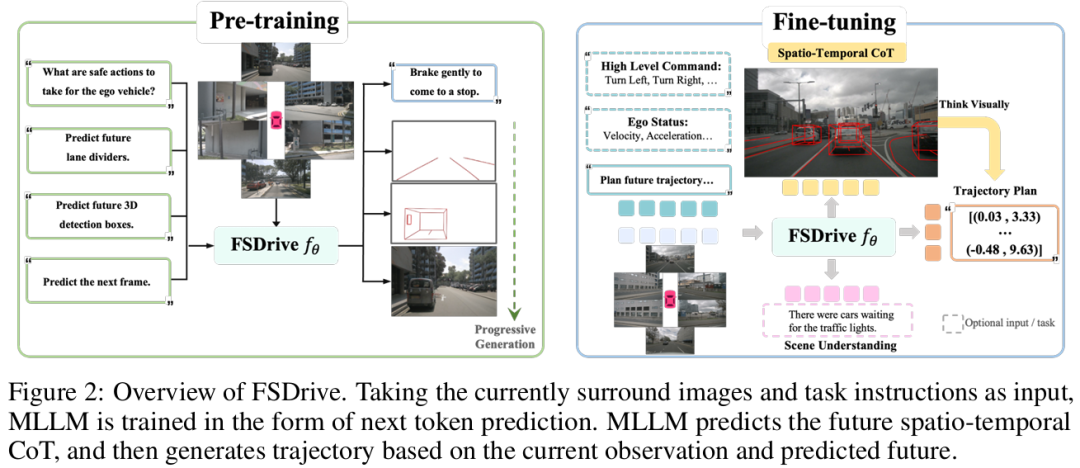
FutureSightDrive
标题:FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
链接:https://arxiv.org/abs/2505.17685
项目主页:
作者单位:阿里巴巴集团高德,西安交通大学,阿里巴巴集团达摩院
视觉语言模型(VLMs)凭借其强大的推理能力在自动驾驶领域引起了越来越多的关注。然而,现有的视觉语言模型通常采用针对当前场景的离散文本思维链(CoT),这本质上是对视觉信息的高度抽象和符号化压缩,可能导致时空关系模糊和细粒度信息丢失。自动驾驶的建模是否更适合基于真实世界的模拟与想象,而非纯粹的符号逻辑。本文提出一种时空思维链推理方法,使模型能够进行视觉化思考。首先,视觉语言模型作为世界模型生成统一图像帧以预测未来世界状态:其中感知结果(如车道分隔线和 3D 检测结果)表征未来空间关系,普通未来帧表征时间演化关系。这种时空思维链随后作为中间推理步骤,使视觉语言模型能够作为逆动力学模型,基于当前观测和未来预测进行轨迹规划。为了在视觉语言模型中实现视觉生成,我们提出一种融合视觉生成与理解的统一预训练范式,以及一种增强自回归图像生成的渐进式视觉思维链。大量实验结果证明了所提方法的有效性,推动自动驾驶向视觉推理方向发展。
算法概览:
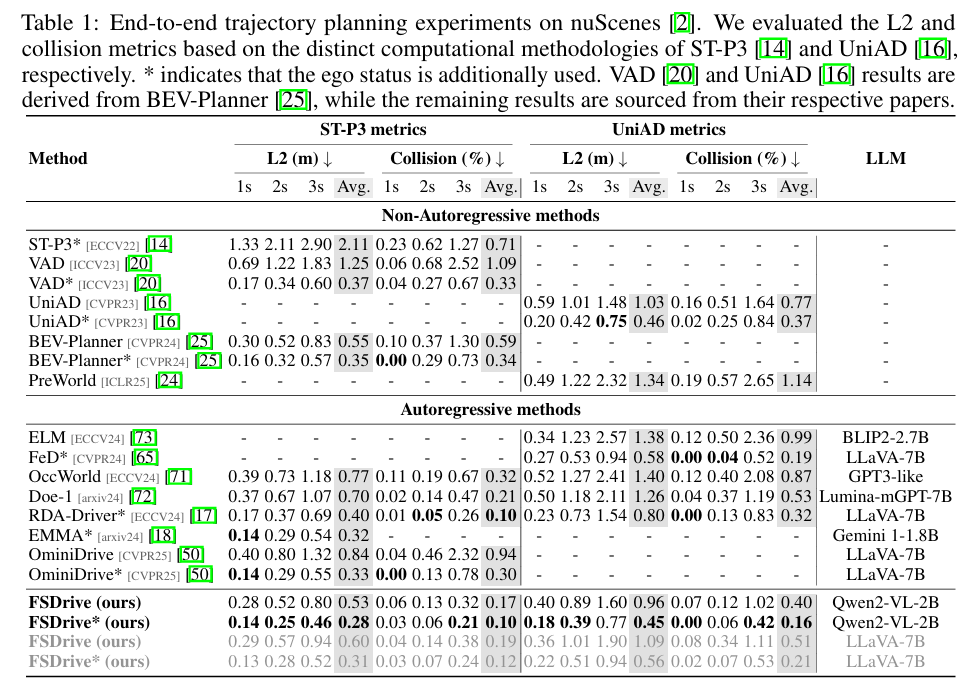
主要实验结果:
OpenLKA-Alert
标题:Bridging Human Oversight and Black-box Driver Assistance: Vision-Language Models for Predictive Alerting in Lane Keeping Assist systems
链接:https://arxiv.org/abs/2505.11535
作者单位:美国南佛罗里达大学
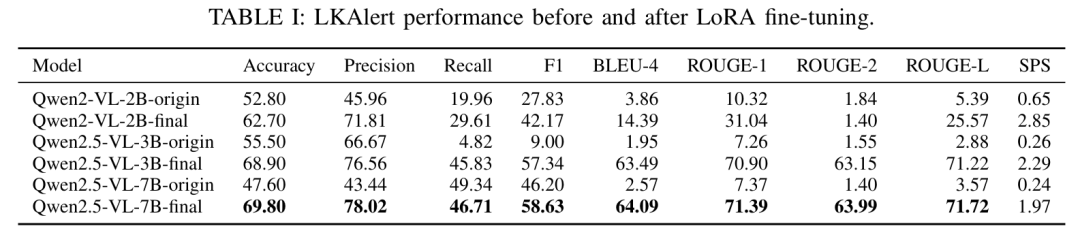
车道保持辅助(LKA)系统虽然日益普及,但在实际应用中常出现不可预测的失效情况,这在很大程度上归因于其不透明的黑箱特性,限制了驾驶员的预判能力和信任度。为弥合自动化辅助与有效人类监督之间的差距,我们提出了 LKAlert—— 一种新型监督警报系统,该系统利用视觉 - 语言模型(VLM)提前 1-3 秒预测潜在的 LKA 风险。LKAlert 处理行车记录仪视频和 CAN 数据,整合来自并行可解释模型的替代车道分割特征作为自动化引导注意力。与传统的二元分类器不同,LKAlert 不仅发出预测性警报,还提供简洁的自然语言解释,从而增强驾驶员的情境感知能力和信任度。为支持此类系统的开发和评估,我们引入了 OpenLKA-Alert,这是首个专为预测性和可解释性 LKA 失效预警设计的基准数据集。该数据集包含同步的多模态输入以及在带注释的时间窗口内由人工编写的解释。我们还贡献了一个可推广的基于 VLM 的黑箱行为预测方法框架,该框架将替代特征引导与 LoRA 相结合。此框架使 VLM 能够在不改变其视觉主干的情况下对结构化视觉上下文进行推理,使其广泛适用于其他需要可解释监督的复杂、不透明系统。实证结果显示,该系统对即将发生的 LKA 失效的预测准确率为 69.8%,F1 分数为 58.6%。该系统还能为驾驶员生成高质量的文本解释(ROUGE-L 得分为 71.7),且运行效率约为 2 Hz,证实其适用于实时车载场景。我们的研究结果表明,LKAlert 是提升现有先进驾驶辅助系统(ADAS)安全性和可用性的实用解决方案,并为将 VLM 应用于以人类为中心的黑箱自动化监督提供了可扩展的范式。
算法概览:
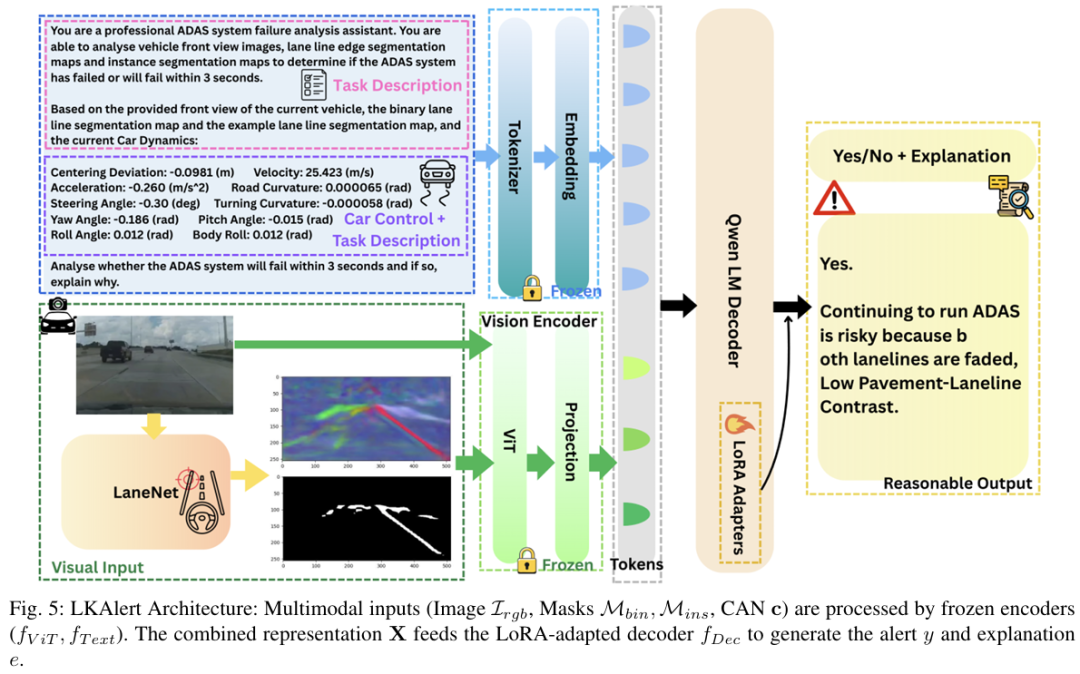
主要实验结果:
OpenLKA
标题:OpenLKA: An Open Dataset of Lane Keeping Assist from Recent Car Models under Real-world Driving Conditions
链接:https://arxiv.org/abs/2505.09092
项目主页:https://github.com/OpenLKA
作者单位:美国南佛罗里达大学
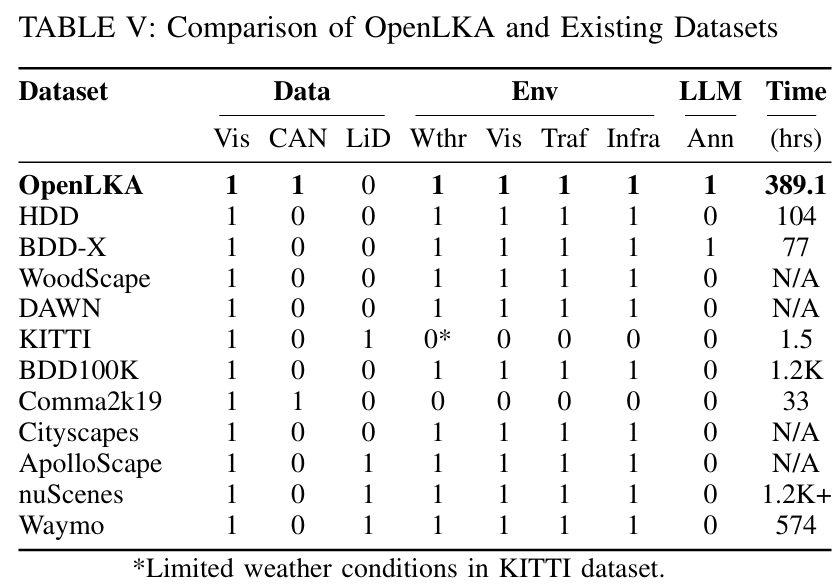
车道保持辅助(LKA)在现代量产车辆中得到广泛应用,但其实际性能仍不透明,这是由于该系统的专有控制栈导致研究人员无法对这项技术进行诊断或改进。为填补这一空白,本文提出了 OpenLKA,这是首个用于 LKA 评估和改进的开放式大规模数据集。该数据集包含来自 62 款量产车型的 389.1 小时 LKA 控制数据,这些数据通过在佛罗里达州坦帕市进行的广泛道路测试以及开源社区的全球贡献者收集而来。数据集涵盖了多种具有挑战性的场景,包括车道标记退化、复杂道路几何形状、恶劣天气、光照条件以及各种周边交通状况。该数据集是多模态的,包括:i)解码的车辆内部消息,其中包含关键的 LKA 信号(如系统退出、车道检测失败等);ii)来自车载 dash 摄像头的同步高分辨率视频;iii)由视觉语言模型生成的丰富场景标注,涵盖车道可见性、路面质量、天气、光照和交通状况等。总体而言,OpenLKA 提供了一个全面的平台,用于基准测试量产 LKA 系统的实际性能、识别安全关键操作场景以及评估当前道路基础设施对自动驾驶的就绪程度。
算法概览:
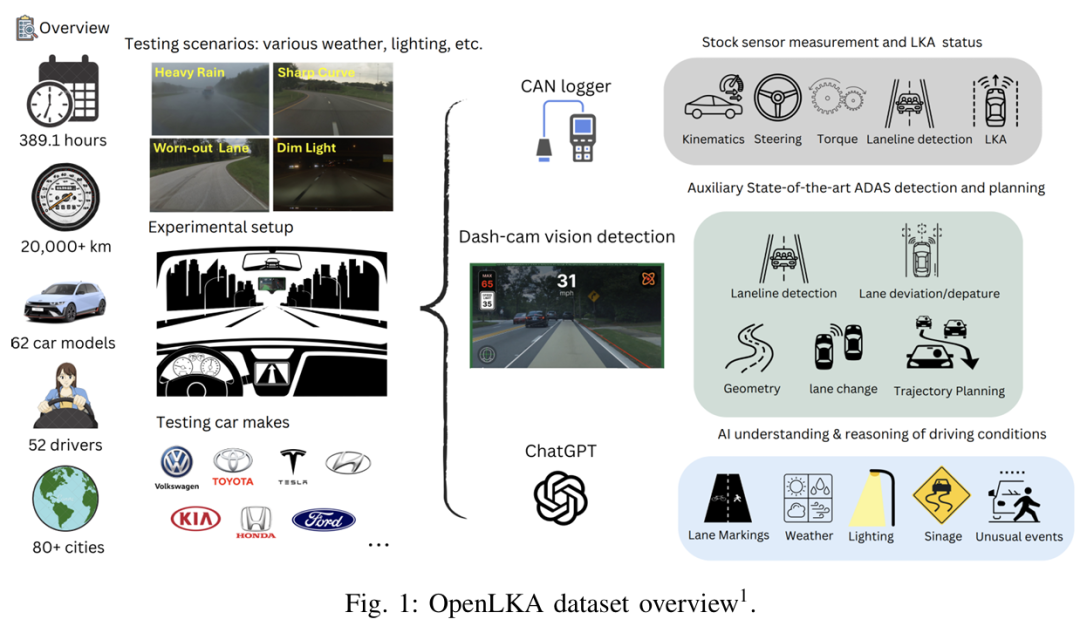
主要实验结果:
Vision Foundation Model
标题:Vision Foundation Model Embedding-Based Semantic Anomaly Detection
链接:https://arxiv.org/abs/2505.07998
作者单位:斯坦福大学,NVIDIA等
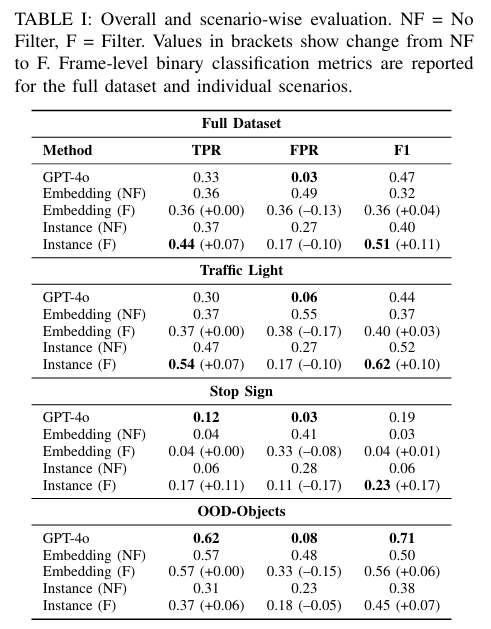
ICRA 2025中稿的工作,语义异常是熟悉视觉元素在语境中无效或不寻常的组合,可能导致自主系统在系统级推理中出现未定义行为和故障。本研究通过利用最先进的视觉基础模型的语义先验知识,直接对图像进行处理,探索语义异常检测。我们提出了一个框架,将运行时图像的局部视觉嵌入与自主系统被认为安全且性能良好的正常场景数据库进行比较。在本研究中,我们考虑了所提框架的两种变体:一种使用原始的基于网格的嵌入,另一种利用实例分割获取以对象为中心的表示。为进一步提高鲁棒性,我们引入了一种简单的过滤机制来抑制误报。我们在 CARLA 模拟异常上的评估表明,结合过滤的基于实例的方法性能可与 GPT-4o 媲美,同时能提供精确的异常定位。这些结果凸显了基础模型的视觉嵌入在自主系统实时异常检测中的潜在效用。
算法概览:
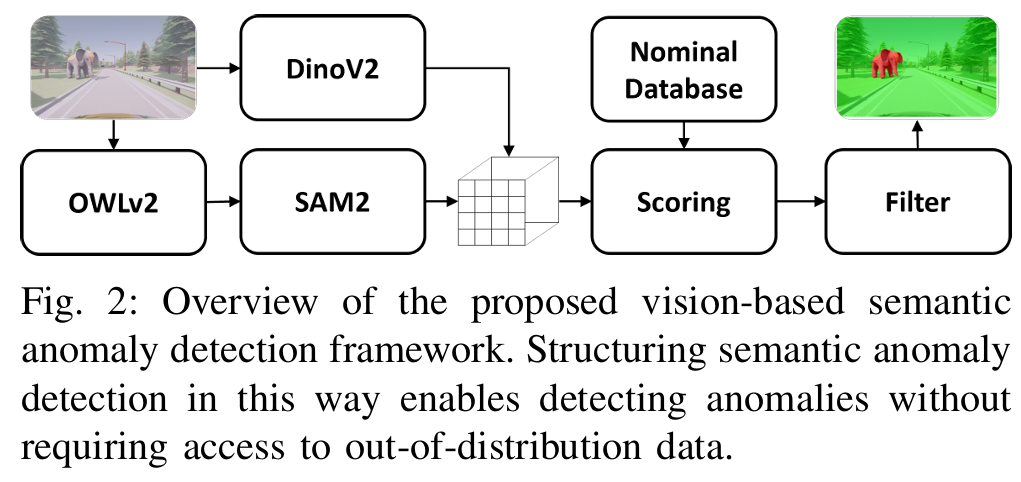
主要实验结果:
ORION
标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
链接:https://www.arxiv.org/abs/2503.19755
项目主页:https://xiaomi-mlab.github.io/Orion/
作者单位:华中科技大学,小米汽车
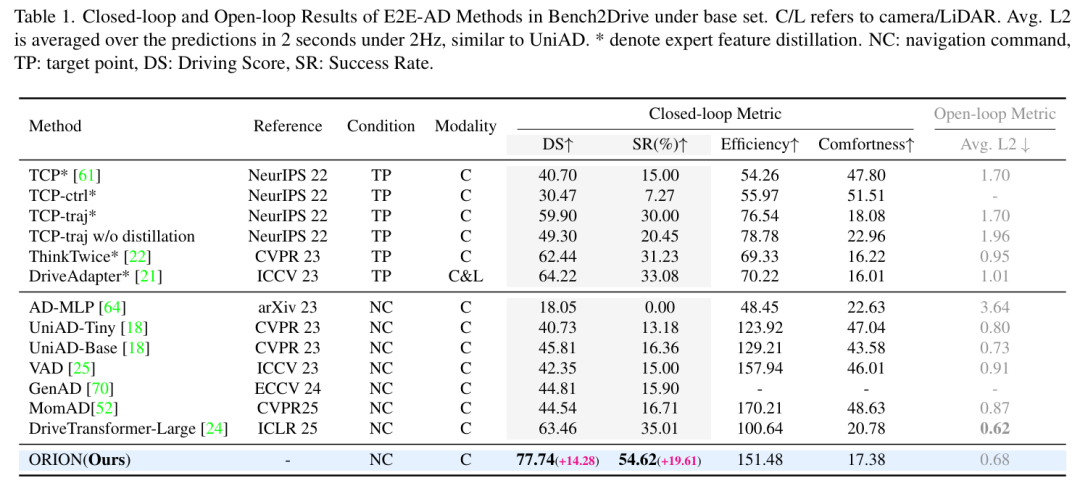
端到端(E2E)自动驾驶方法由于因果推理能力有限,在交互式闭环评估中仍难以做出正确决策。现有方法尝试利用视觉 - 语言模型(VLMs)强大的理解与推理能力来解决这一困境。然而,由于语义推理空间与动作空间中纯数值轨迹输出之间存在差距,很少有适用于端到端方法的 VLMs 能在闭环评估中表现良好,这一问题仍未得到解决。为解决该问题,我们提出 ORION—— 一种基于视觉 - 语言指令动作生成的整体端到端自动驾驶框架。ORION 独特地融合了用于聚合长期历史上下文的 QT-Former、用于驾驶场景推理的大语言模型(LLM)以及用于精确轨迹预测的生成式规划器。此外,ORION 通过对齐推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。我们的方法在 Bench2Drive 挑战数据集上取得了令人瞩目的闭环性能,驾驶得分(DS)达 77.74,成功率(SR)达 54.62%,大幅超越了最先进(SOTA)方法,领先 14.28 个驾驶得分和 19.61% 的成功率。
算法概览:
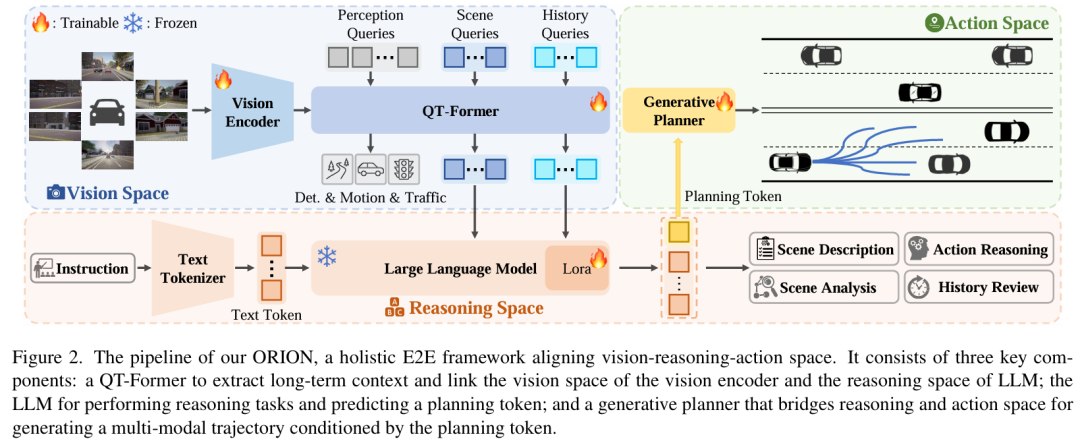
主要实验结果:
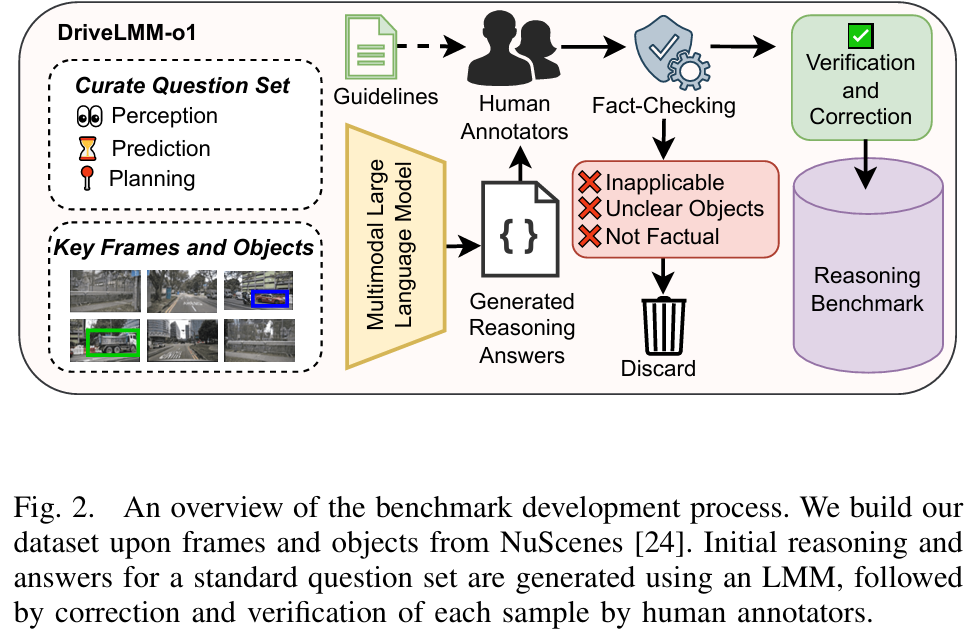
DriveLMM-o1
标题:DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
链接:https://arxiv.org/abs/2503.10621
项目主页:https://github.com/ayesha-ishaq/DriveLMM-o1
作者单位:穆罕默德・本・扎耶德人工智能大学,澳大利亚国立大学
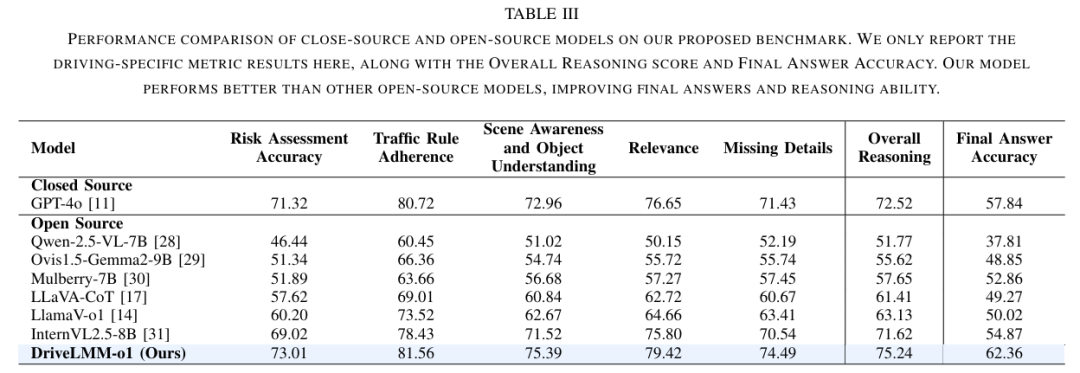
尽管大型多模态模型(LMMs)在各种视觉问答(VQA)任务中表现出了较强的性能,但某些挑战需要复杂的多步骤推理才能得出准确答案。自动驾驶就是一项极具挑战性的任务,在做出决策之前需要进行全面的认知处理。在这一领域,对视觉线索的顺序性和解释性理解对于有效的感知、预测和规划至关重要。然而,常见的 VQA 基准往往侧重于最终答案的准确性,却忽视了生成准确响应所依赖的推理过程。此外,现有方法缺乏一个全面的框架来评估真实驾驶场景中的逐步推理能力。为了填补这一空白,我们提出了 DriveLMM-o1,这是一个专门为推进自动驾驶领域的逐步视觉推理而设计的新数据集和基准。我们的基准在训练集中包含超过 18k 个 VQA 示例,在测试集中包含超过 4k 个,涵盖了关于感知、预测和规划的各种问题,每个问题都配有逐步推理过程,以确保在自动驾驶场景中的逻辑推理。我们进一步介绍了一个在我们的推理数据集上进行微调的大型多模态模型,该模型在复杂驾驶场景中表现出稳健的性能。此外,我们在提出的数据集上对各种开源和闭源方法进行了基准测试,系统地比较了它们在自动驾驶任务中的推理能力。我们的模型相较于之前最佳的开源模型,在最终答案准确性上提升了 7.49%,在推理得分上提升了 3.62%。
算法概览:
主要实验结果:
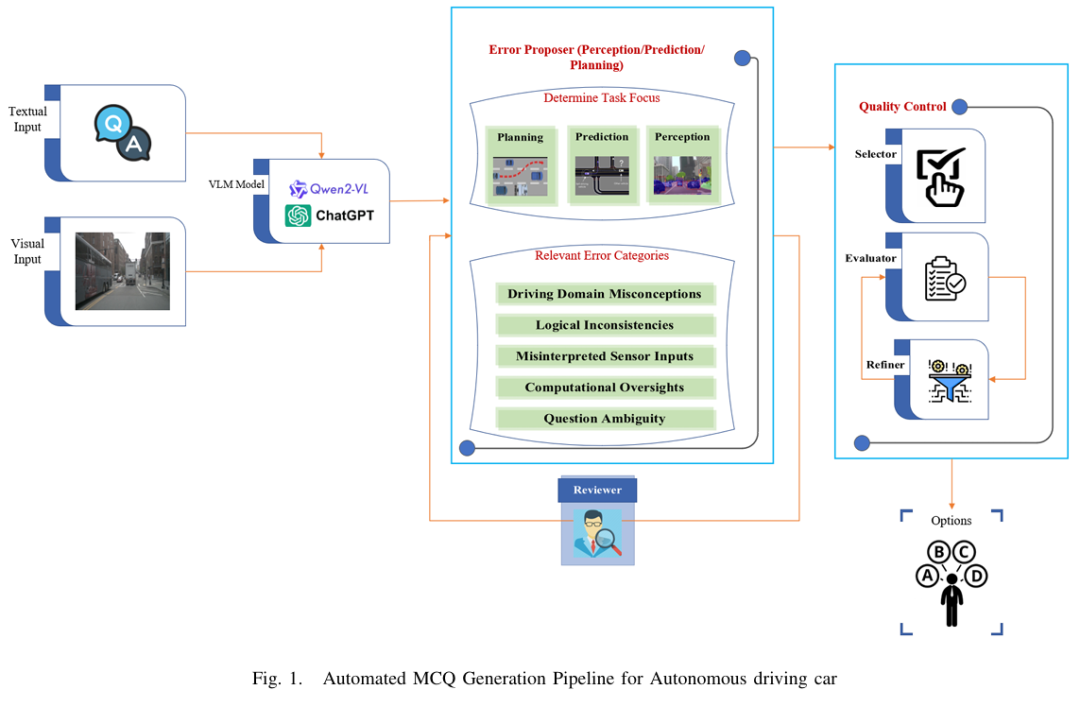
AutoDrive-QA
标题:AutoDrive-QA - Automated Generation of Multiple-Choice Questions for Autonomous Driving Datasets Using Large Vision-Language Models
链接:https://arxiv.org/abs/2503.15778
项目主页:https://github.com/Boshrakh/AutoDrive-QA
作者单位:哥伦比亚大学
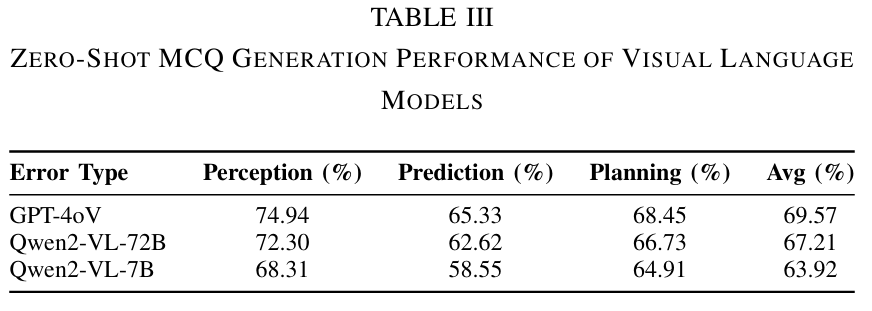
在自动驾驶领域,开放式问答往往因自由形式的回答需要复杂的评估指标或主观的人工判断而面临评估不可靠的问题。为应对这一挑战,我们提出了 AutoDrive-QA —— 一个自动流水线,可将现有的驾驶问答数据集(包括 DriveLM、NuScenes-QA 和 LingoQA)转换为结构化的多项选择题(MCQ)格式。该基准系统地评估感知、预测和规划任务,提供了一个标准化且客观的评估框架。AutoDrive-QA 采用自动流水线,利用大语言模型(LLMs),基于自动驾驶场景中常见的特定领域错误模式生成高质量、与上下文相关的干扰项。为评估模型的通用能力和泛化性能,我们在三个公开数据集上测试了该基准,并在一个未见过的数据集上进行了零样本实验。零样本评估显示,GPT-4V 以 69.57% 的准确率领先 —— 在感知任务中达到 74.94%,预测任务中达到 65.33%,规划任务中达到 68.45%,这表明所有模型在感知任务中表现出色,但在预测任务中存在困难。因此,AutoDrive-QA 建立了一个严格、无偏的标准,用于整合和评估不同视觉语言模型在各种自动驾驶数据集上的表现,从而提高该领域的泛化能力。
算法概览:
主要实验结果:
NuGrounding
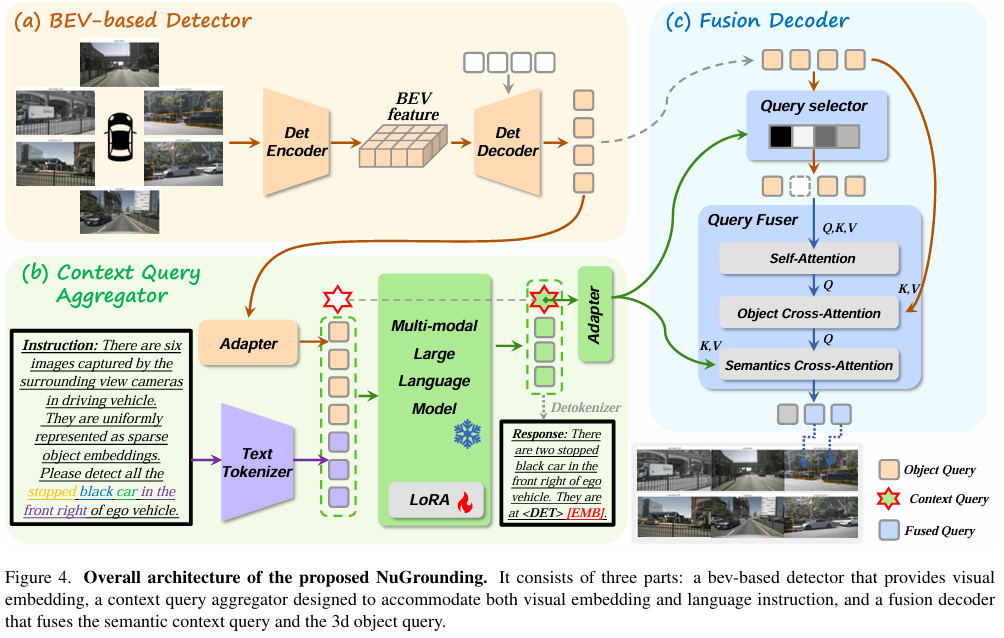
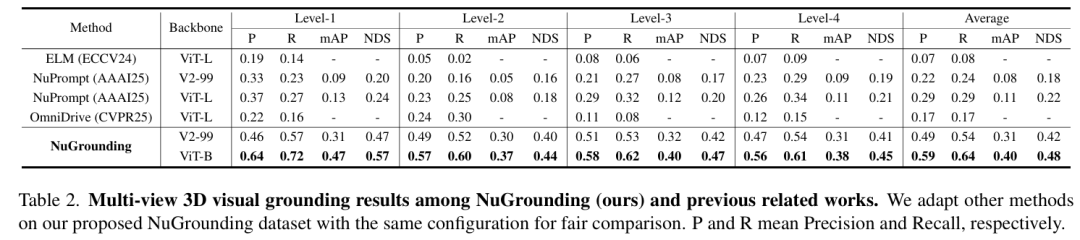
标题:NuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
链接:https://arxiv.org/abs/2503.22436
作者单位:清华大学,华为诺亚方舟实验室,香港大学
多视图 3D 视觉定位对于自动驾驶车辆在复杂环境中理解自然语言并定位目标物体至关重要。然而,现有数据集和方法存在语言指令粒度粗糙、3D 几何推理与语言理解融合不足等问题。为此,我们提出了 NuGrounding,这是首个面向自动驾驶多视图 3D 视觉定位的大规模基准数据集。我们设计了定位层次结构(HoG)方法来构建该数据集,生成具有层次结构的多级指令,确保全面覆盖人类指令模式。为应对这一具有挑战性的数据集,我们提出了一种新范式,将多模态大语言模型(MLLMs)的指令理解能力与专业检测模型的精确定位能力无缝结合。我们的方法引入了两个解耦的任务令牌和一个上下文查询,用于聚合 3D 几何信息和语义指令,随后通过融合解码器优化空间 - 语义特征融合以实现精确定位。大量实验表明,我们的方法显著优于从代表性 3D 场景理解方法改编而来的基线方法,精确率达到 0.59,召回率达到 0.64,分别提升了 50.8% 和 54.7%。
算法概览:
主要实验结果:
ViLA
标题:Evaluating Multimodal Vision-Language Model Prompting Strategies for Visual Question Answering in Road Scene Understanding
HTML:https://openaccess.thecvf.com/content/WACV2025W/LLVMAD/html/Keskar_Evaluating_Multimodal_Vision-Language_Model_Prompting_Strategies_for_Visual_Question_Answering_WACVW_2025_paper.html
作者单位:加州大学默塞德分校
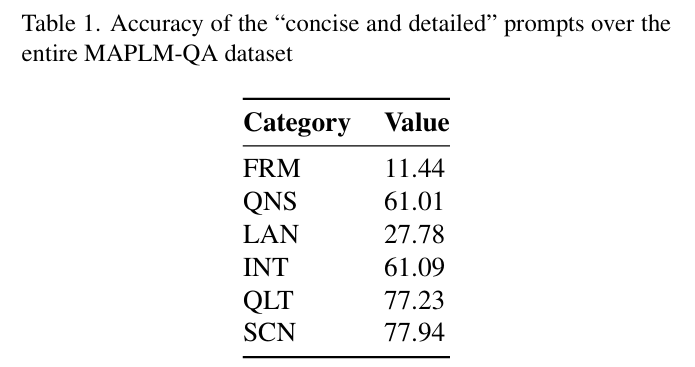
理解复杂交通场景是推动自动驾驶系统发展的关键挑战。视觉问答(VQA)任务作为一种新兴方法,能够从多模态交通数据中提取可操作信息,使车辆做出精准的实时决策。作为2025年WACV自动驾驶大语言视觉模型挑战赛(LLVM-AD)的重要组成部分,MAPLM-QA数据集为此任务提供了强有力的基准。该数据集包含14,000个多模态帧,融合了高分辨率全景图像与LiDAR三维点云渲染生成的鸟瞰图(BEV)。本研究探索了应用英伟达视觉语言模型(ViLA)解决MAPLM-QA中VQA任务的方法。通过针对数据集设计精细提示工程,我们系统评估了ViLA的性能:在质量评估等指标上展现出优势,同时揭示了其在车道计数、交叉路口识别及场景细微差异理解方面的挑战。研究结果证实了视觉语言模型(VLM)在增强交通场景分析与自动驾驶能力方面的潜力,为未来利用VLM和多模态数据集实现可扩展、鲁棒的交通场景理解奠定了坚实基础,并明确了技术局限性。
算法概览:
主要实验结果:
INSIGHT
标题:INSIGHT: Enhancing Autonomous Driving Safety through Vision-Language Models on Context-Aware Hazard Detection and Edge Case Evaluation
链接:https://www.arxiv.org/abs/2502.00262
作者单位:美国马里兰大学帕克分校,美国北卡罗来纳州立大学
自动驾驶系统在处理不可预测的边缘案例场景时面临重大挑战,例如具有对抗性的行人运动、危险的车辆操作以及突发的环境变化。当前的端到端驾驶模型由于传统检测和预测方法的局限性,在泛化到这些罕见事件时表现不佳。为解决这一问题,我们提出了 INSIGHT(用于广义危险跟踪的语义与视觉输入集成),这是一种分层视觉 - 语言模型(VLM)框架,旨在增强危险检测和边缘案例评估能力。通过多模态数据融合,我们的方法整合了语义和视觉表征,能够精确解读驾驶场景并准确预测潜在危险。通过对视觉 - 语言模型进行监督微调,我们利用基于注意力的机制和坐标回归技术优化了空间危险定位。在 BDD100K 数据集上的实验结果表明,与现有模型相比,该模型在危险预测的直观性和准确性方面有显著提升,泛化性能也得到了明显改善。这一进展增强了自动驾驶系统的鲁棒性和安全性,确保在复杂的现实世界场景中提升态势感知能力和潜在决策能力。
算法概览:
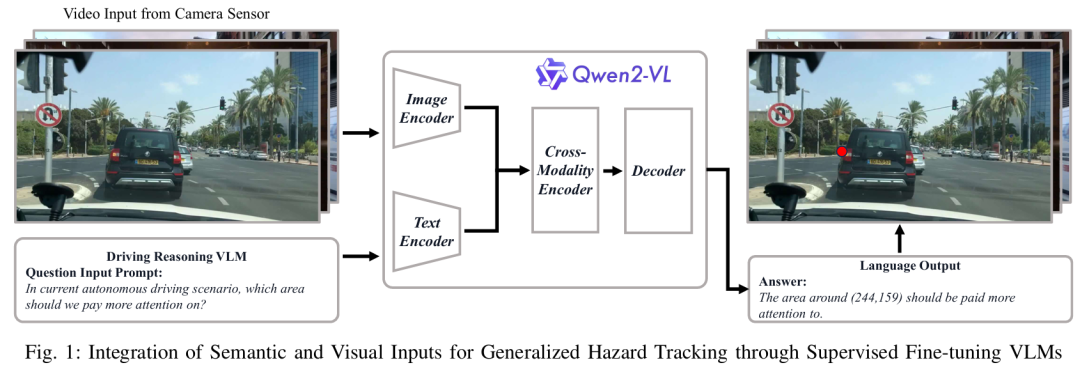
主要实验结果:

Scenario Understanding
标题:Scenario Understanding of Traffic Scenes Through Large Visual Language Models
链接:https://arxiv.org/pdf/2501.17131
作者单位:慕尼黑工业大学
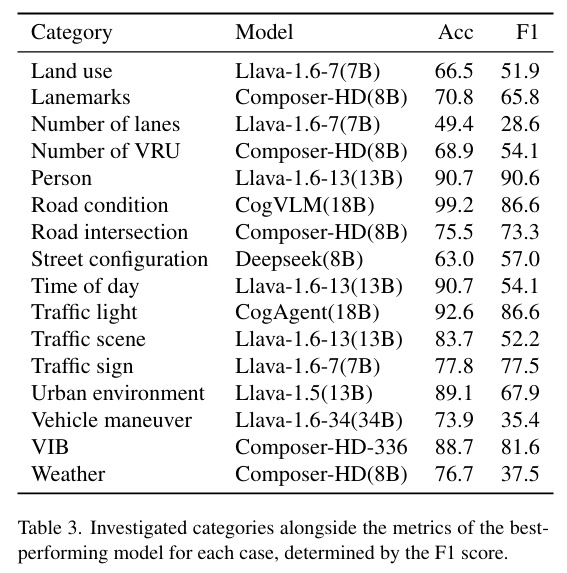
WACV2025中稿的工作,深度学习模型在自动驾驶领域(包括感知、规划和控制)的高性能依赖于海量数据集。然而,由于特定领域的数据分布,这些模型的泛化能力往往受限,因此需要对样本进行有效的基于场景的分类,以提高其在不同领域的可靠性。人工标注虽有价值,但既耗费人力又耗时,成为数据标注过程中的瓶颈。大型视觉语言模型(LVLMs)通过上下文查询实现图像分析和分类的自动化,且通常无需为新类别重新训练,为解决这一问题提供了极具吸引力的方案。在本研究中,我们评估了包括 GPT-4 和 LLaVA 在内的大型视觉语言模型在内部数据集和 BDD100K 数据集上对城市交通场景的理解与分类能力。我们提出了一个可扩展的标注管道,整合了最先进的模型,能够灵活部署于新数据集。通过定量指标与定性分析相结合的方式,我们的研究证实了大型视觉语言模型在理解城市交通场景方面的有效性,并凸显了其作为自动驾驶领域数据驱动进展的高效工具的潜力。
算法概览:
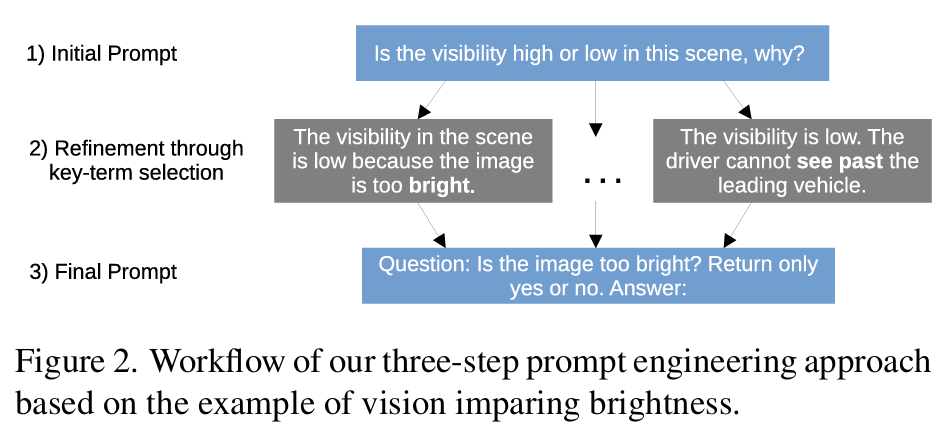
主要实验结果:
DriveLM
标题:DriveLM: Driving with Graph Visual Question Answering
链接:https://arxiv.org/abs/2312.14150
项目主页:https://github.com/OpenDriveLab/DriveLM
作者单位:上海人工智能实验室,香港大学,图宾根大学
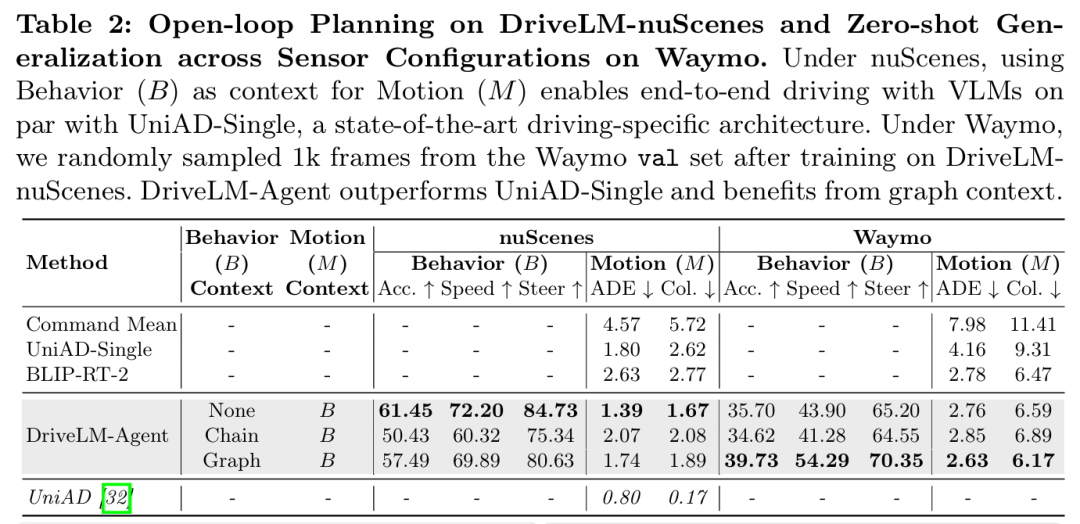
ECCV 2024中稿的工作,我们研究了如何将基于网络规模数据训练的视觉语言模型(VLMs)集成到端到端驾驶系统中,以增强泛化能力并实现与人类用户的交互。尽管近年来的方法通过单轮视觉问答(VQA)使 VLMs 适应驾驶场景,但人类驾驶员在做决策时会进行多步骤推理:从关键目标的定位开始,在采取行动前先估计目标间的交互。核心见解是,通过我们提出的图视觉问答(Graph VQA)任务 —— 该任务通过感知、预测和规划问答对来建模图结构推理 —— 我们获得了一个合适的代理任务,以模拟人类的推理过程。我们基于 nuScenes 和 CARLA 构建了数据集(DriveLM-Data),并提出了一种基于 VLM 的基线方法(DriveLM-Agent),用于联合执行图视觉问答和端到端驾驶。实验表明,图视觉问答为驾驶场景推理提供了一个简单、有原则的框架,而 DriveLM-Data 为该任务提供了一个具有挑战性的基准。我们的 DriveLM-Agent 基线在端到端自动驾驶方面的表现与最先进的特定驾驶架构相当。值得注意的是,在对未见过的传感器配置进行零样本评估时,其优势尤为明显。我们的逐问题消融研究表明,性能提升来自于图结构中预测和规划问答对的丰富标注。
算法概览:

主要实验结果:
POTGui
标题:Enhancing Large Vision Model in Street Scene Semantic Understanding through Leveraging Posterior Optimization Trajectory
链接:https://arxiv.org/abs/2501.01710
作者单位:香港大学,南方科技大学,中国科学院深圳先进技术研究院
为提高自动驾驶(AD)感知模型的泛化能力,车辆需要基于持续收集的数据随时间更新模型。随着时间推移,AD 模型拟合的数据量不断扩大,这显著有助于提升模型的泛化能力。然而,这种不断膨胀的数据对 AD 模型而言是把双刃剑。具体来说,当拟合的数据量超过 AD 模型的拟合能力时,模型容易出现欠拟合问题。为解决这一问题,我们提出采用预训练的大型视觉模型(LVMs)作为主干网络,结合下游感知头来理解 AD 语义信息。这种设计不仅能凭借 LVMs 强大的拟合能力克服上述欠拟合问题,还能借助 LVMs 海量且多样的训练数据增强感知泛化能力。另一方面,为减轻车辆在运行 LVM 主干网络时训练感知头的计算负担,我们引入后验优化轨迹(POT)引导的优化方案(POTGui)以加速收敛。具体而言,我们设计了 POT 生成器(POTGen),提前生成后验(未来)优化方向,用于指导当前的优化迭代,使模型通常能在 10 个 epoch 内收敛。大量实验表明,与现有的最先进方法相比,所提方法性能提升超过 66.48%,收敛速度加快 6 倍以上。
算法概览:
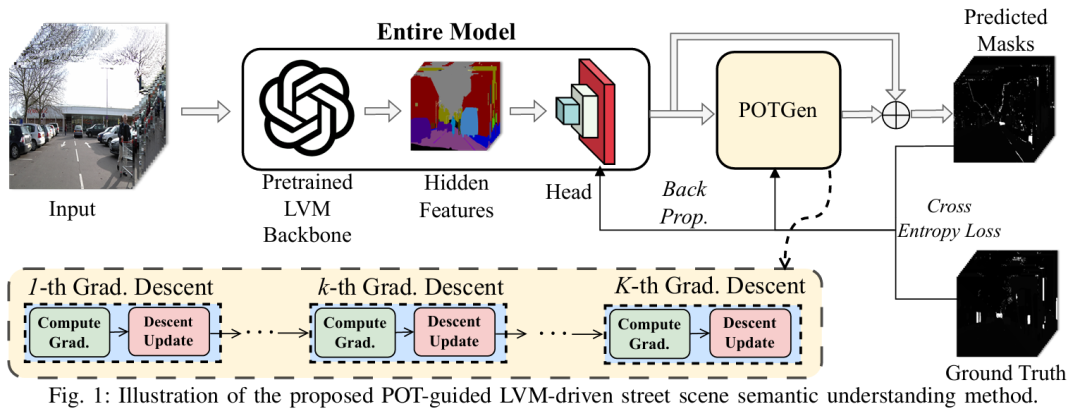
主要实验结果:

VLM综述
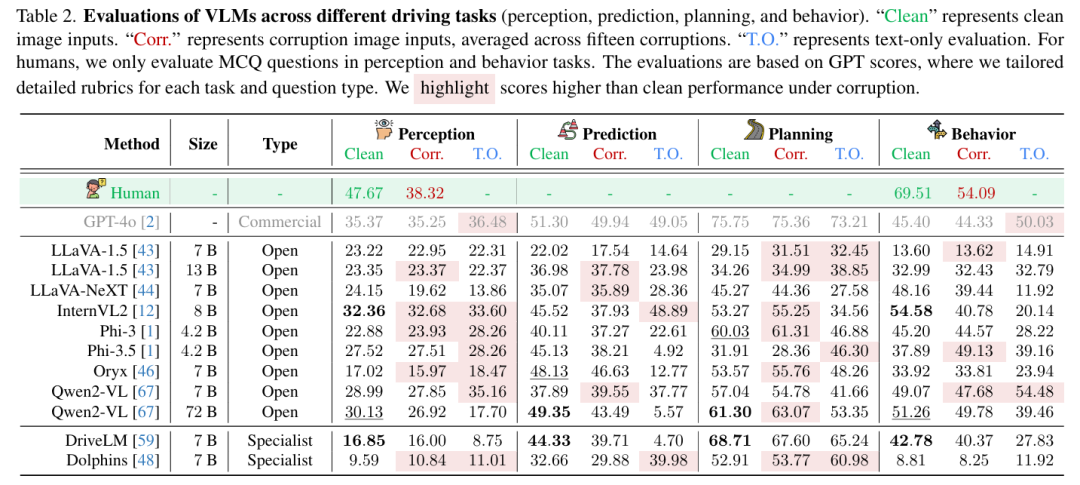
标题:Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
链接:https://arxiv.org/abs/2501.04003
项目主页:https://drive-bench.github.io/
作者单位:加州大学欧文分校,上海人工智能实验室,南洋理工大学S-Lab等
近年来,视觉 - 语言模型(VLMs)的进步引发了将其应用于自动驾驶的兴趣,尤其是在通过自然语言生成可解释的驾驶决策方面。然而,VLMs 是否天生能为驾驶提供基于视觉的、可靠且可解释的解释这一假设在很大程度上尚未得到检验。为填补这一空白,我们引入了 DriveBench,这一基准数据集旨在评估 VLMs 在 17 种设置(清洁、受损和纯文本输入)下的可靠性,涵盖 19,200 帧、20,498 个问答对、三种问题类型、四项主流驾驶任务,以及共 12 个主流 VLMs。我们的研究发现,VLMs 往往会基于常识或文本线索生成看似合理的响应,而非真正基于视觉,尤其是在视觉输入退化或缺失的情况下。这种行为被数据集不平衡和评估指标不足所掩盖,在自动驾驶等安全关键场景中构成重大风险。我们还观察到,VLMs 在多模态推理方面存在困难,且对输入损坏高度敏感,导致性能不一致。为应对这些挑战,我们提出了改进的评估指标,优先考虑稳健的视觉接地和多模态理解。此外,我们强调了利用 VLMs 对损坏的感知来提高其可靠性的潜力,为开发更可信、可解释的现实世界自动驾驶决策系统提供了路线图。
算法概览:
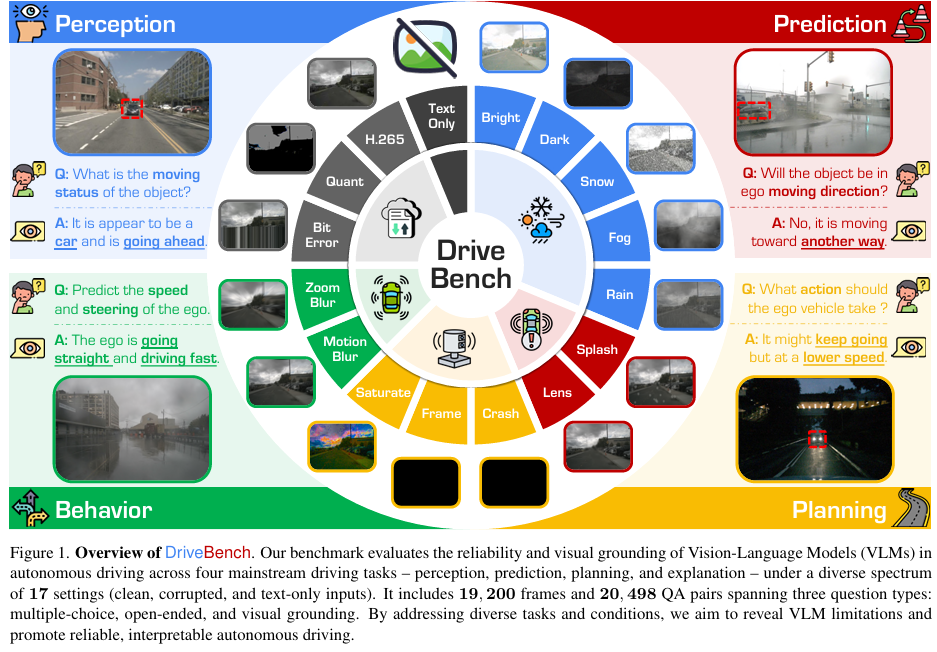
主要实验结果:
VisionLLM
标题:SFF Rendering-Based Uncertainty Prediction using VisionLLM
链接:https://openreview.net/forum?id=q8ptjh1pDl
作者单位:韩国延世大学
本研究提出了一种基于VisionLLM的创新框架,用于自动驾驶中的不确定性预测。通过利用CARLA仿真平台采集的驾驶数据,我们生成了与后续驾驶动作及不确定性分值配对的BEV。为模拟真实驾驶挑战,我们在BEV中引入遮挡掩膜,以表征传感器局限导致的视野盲区。该模型通过融合额外图像输入,在遮挡严重的复杂场景中同步预测后续驾驶动作与不确定性分值,显著提升了推理能力。采用参数高效微调技术(PEFT)如LoRA对VisionLLM进行微调,实验结果证实了该方法在解决遮挡相关不确定性问题的效能,为高阶驾驶自动化系统实现更安全可靠的决策机制奠定了技术基础。
算法概览:
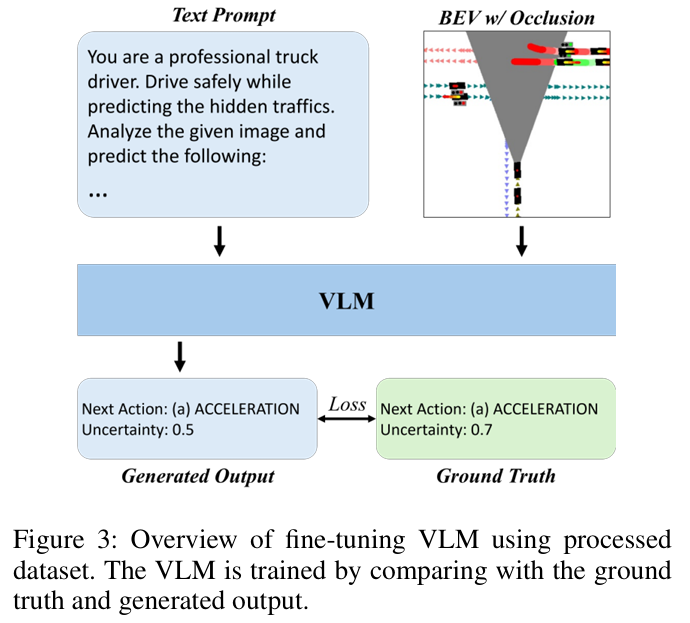
主要实验结果:

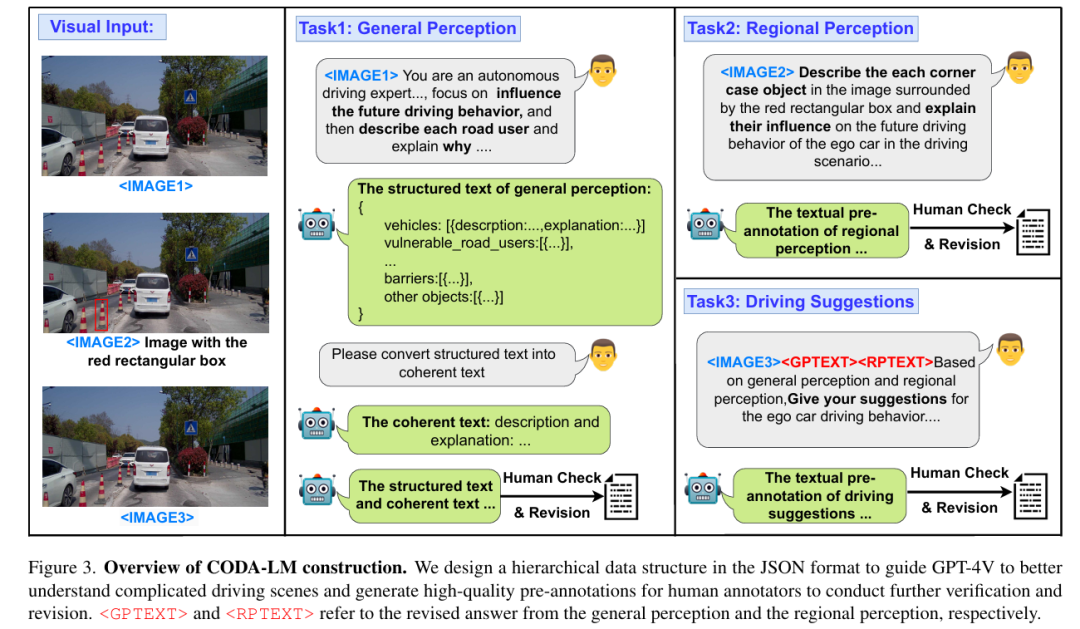
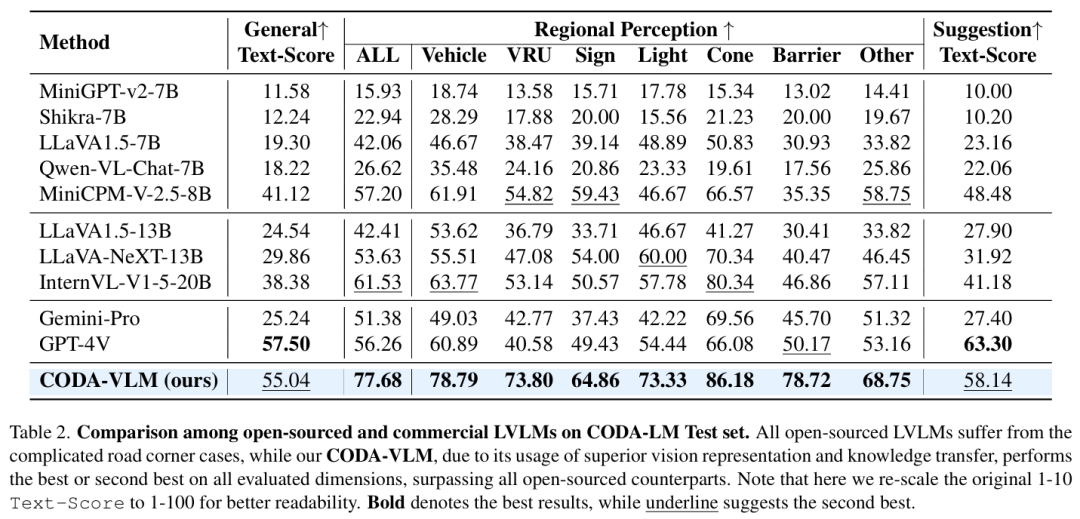
CODA-LM
标题:Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
链接:https://arxiv.org/abs/2404.10595
项目主页:https://coda-dataset.github.io/coda-lm/
作者单位:香港科技大学,大连理工大学,香港中文大学,华为诺亚方舟实验室
WACV 2025中稿的工作,大型视觉语言模型(LVLMs)在推动可解释自动驾驶方面受到了广泛关注。现有的 LVLMs 评估主要集中于自然场景下的多方面能力,缺乏针对自动驾驶的自动化、可量化评估,更不用说对严峻的道路极端场景的评估了。在本研究中,我们提出了 CODA-LM,这是首个用于自动驾驶极端场景下 LVLMs 自动评估的基准。我们采用分层数据结构,提示强大的 LVLMs 分析复杂驾驶场景,并为人工标注者生成高质量的预标注;而在 LVLM 评估方面,我们发现使用纯文本大语言模型(LLMs)作为评判者,与人类偏好的一致性甚至优于 LVLM 评判者。此外,借助我们的 CODA-LM,我们构建了 CODA-VLM—— 一种新的驾驶 LVLM,其在 CODA-LM 上的表现超过了所有开源同类模型。CODA-VLM 的性能与 GPT-4V 相当,在区域感知任务上甚至超过 GPT-4V 达 21.42%。我们希望 CODA-LM 能成为推动 LVLMs 赋能的可解释自动驾驶发展的催化剂。
算法概览:
主要实验结果:
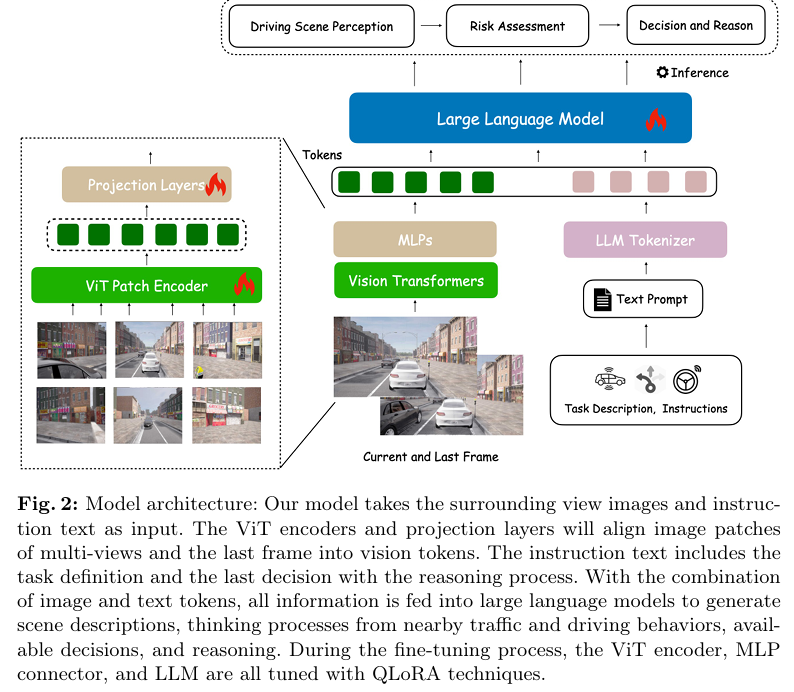
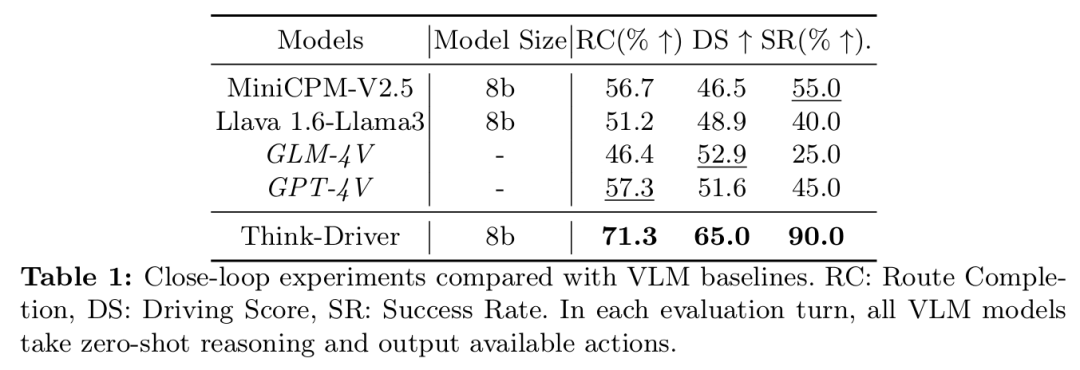
Think-Driver
标题:Think-Driver: From Driving-Scene Understanding to Decision-Making with Vision Language Models
PDF:https://mllmav.github.io/papers/Think-Driver:%20From%20Driving-Scene%20Understanding%20to%20Decision-Making%20with%20Vision%20Language%20Models.pdf
作者单位:香港科技大学(广州),约翰斯・霍普金斯大学
自动驾驶近期在仿真环境与现实场景中的表现均取得了显著突破,端到端方法尤其令人瞩目。然而,这类模型往往如同黑盒般运作,缺乏可解释性。大语言模型(LLM)的出现为解决此问题提供了可能,它将模块化自动驾驶与语言解释能力相结合。目前主流的LLM方案将驾驶输入信息转化为语言描述,但这通常依赖人工设计的提示语,且可能导致信息效率不尽理想。视觉语言模型(VLM)虽可直接从图像中提取信息,但在涉及连续驾驶场景理解与上下文推理的任务中有时表现欠佳。
本文提出ThinkDriver模型,这是一种利用多视角图像生成理性驾驶决策及推理过程的视觉语言模型。该模型能够评估感知到的交通状况,并对当前驾驶行为的风险进行研判,从而助力形成理性决策。通过闭环实验验证,ThinkDriver的表现优于其他基于视觉语言模型的基线方案,其生成的驾驶决策具备可解释性,充分证明了该模型的有效性及其在未来应用中的潜力。
算法概览:
主要实验结果:
LLM-Augmented-MTR
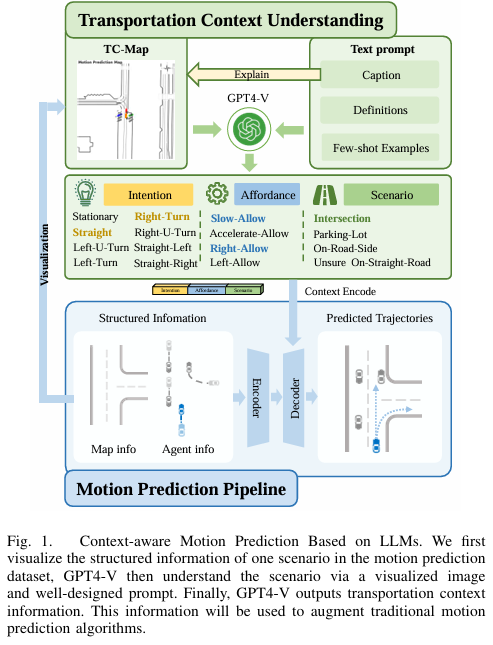
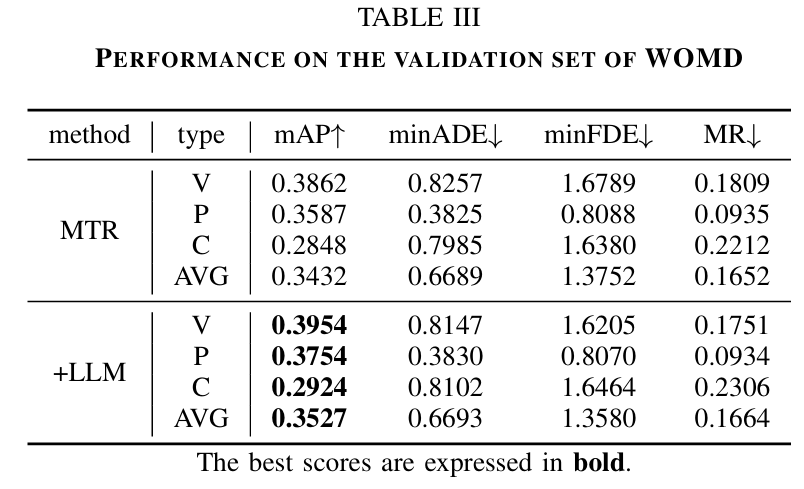
标题:Large Language Models Powered Context-aware Motion Prediction in Autonomous Driving
链接:https://arxiv.org/abs/2403.11057
项目主页:https://github.com/AIR-DISCOVER/LLM-Augmented-MTR
作者单位:清华大学
运动预测是自动驾驶中最基础的任务之一。传统的运动预测方法主要对地图的向量信息和交通参与者的历史轨迹数据进行编码,缺乏对整体交通语义的全面理解,进而影响预测任务的性能。在本文中,我们利用大语言模型(LLMs)来增强运动预测任务中的全局交通上下文理解。我们首先进行了系统的提示词工程,将复杂的交通环境和交通参与者的历史轨迹信息可视化到图像提示 —— 交通场景图(TC-Map)中,并辅以相应的文本提示。通过这种方法,我们从大语言模型中获取了丰富的交通上下文信息。将这些信息集成到运动预测模型中后,我们证明此类上下文能够提高运动预测的准确性。此外,考虑到大语言模型的成本,我们提出了一种经济高效的部署策略:使用 0.7% 的大语言模型增强数据集,大规模提升运动预测任务的准确性。我们的研究为增强大语言模型对交通场景的理解以及自动驾驶的运动预测性能提供了有价值的见解。
算法概览:
主要实验结果:
Reason2Drive
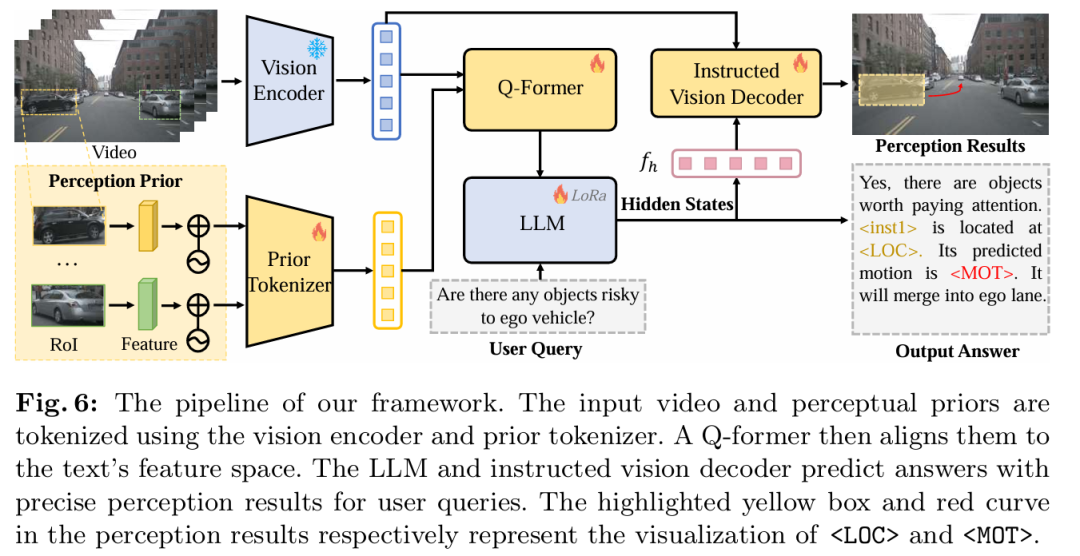
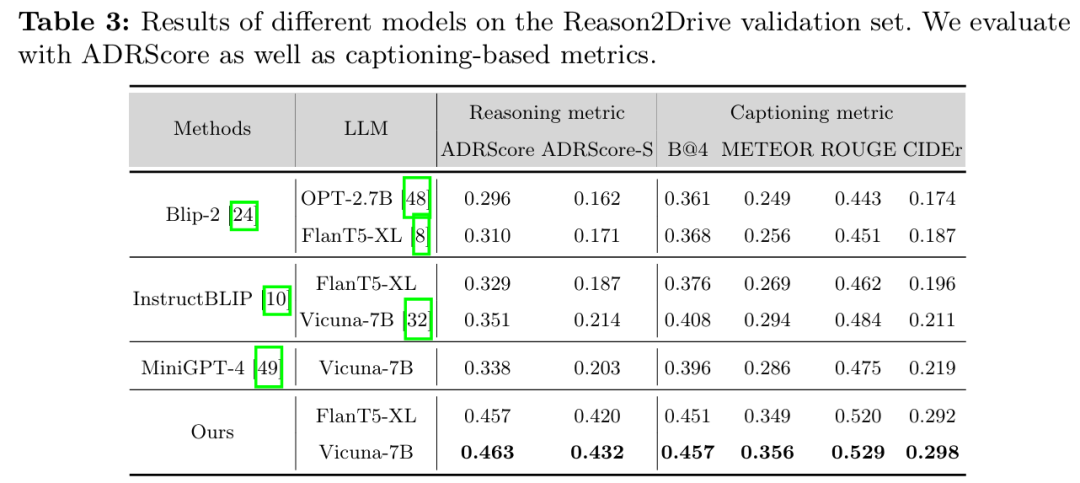
标题:Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
链接:https://arxiv.org/abs/2312.03661
项目主页:https://github.com/fudan-zvg/reason2drive
作者单位:复旦大学、华为诺亚方舟实验室
ECCV 2024中稿的工作,大型视觉 - 语言模型(VLMs)在自动驾驶领域引起了越来越多的关注,这得益于其在高度自主车辆行为所必需的复杂推理任务中展现出的先进能力。尽管潜力巨大,但自主系统领域的研究因缺乏带有标注推理链(用于解释驾驶决策过程)的数据集而受阻。为填补这一空白,我们提出了 Reason2Drive—— 一个包含超过 60 万对视频 - 文本对的基准数据集,旨在推动复杂驾驶环境中可解释推理的研究。我们将自动驾驶过程明确描述为感知、预测和推理步骤的顺序组合,其问答对自动从多种开源户外驾驶数据集(包括 nuScenes、Waymo 和 ONCE)中收集而来。此外,我们引入了一种新颖的聚合评估指标,用于评估自主系统中基于链的推理性能,以解决现有指标(如 BLEU 和 CIDEr)存在的推理模糊性问题。基于所提出的基准,我们开展实验评估了多种现有 VLMs,揭示了它们在推理能力方面的见解。另外,我们开发了一种高效方法,使 VLMs 能够在特征提取和预测中利用目标级感知元素,进一步提高了其推理准确性。可扩展实验表明,Reason2Drive 对视觉推理和下游规划任务具有支持作用。
算法概览:
主要实验结果:
OmniDrive
标题:OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
链接:https://arxiv.org/abs/2405.01533
项目主页:https://github.com/NVlabs/OmniDrive
作者单位:NVIDIA,香港理工大学,北京理工大学
视觉语言模型(VLMs)的进步引发了人们在自动驾驶领域对其强大推理能力的关注。然而,将这些能力从 2D 扩展到全面的 3D 理解对于实际应用至关重要。为应对这一挑战,我们提出了 OmniDrive,这是一个全面的视觉语言数据集,通过反事实推理使智能体模型与 3D 驾驶任务相匹配。这种方法通过评估潜在场景及其结果来增强决策能力,类似于人类驾驶员考虑替代行动的方式。我们基于反事实的合成数据标注过程生成了大规模、高质量的数据集,提供了更密集的监督信号,连接了规划轨迹与基于语言的推理。此外,我们探索了两个先进的 OmniDrive-Agent 框架,即 Omni-L 和 Omni-Q,以评估视觉 - 语言对齐与 3D 感知的重要性,揭示了设计高效 LLM 智能体的关键见解。在 DriveLM 问答基准和 nuScenes 开环规划任务上的显著改进,证明了我们的数据集和方法的有效性。
算法概览:
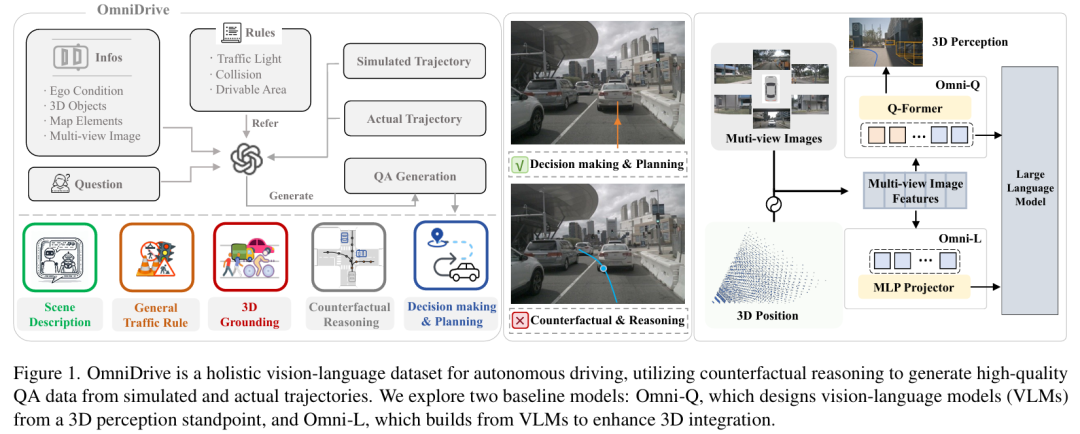
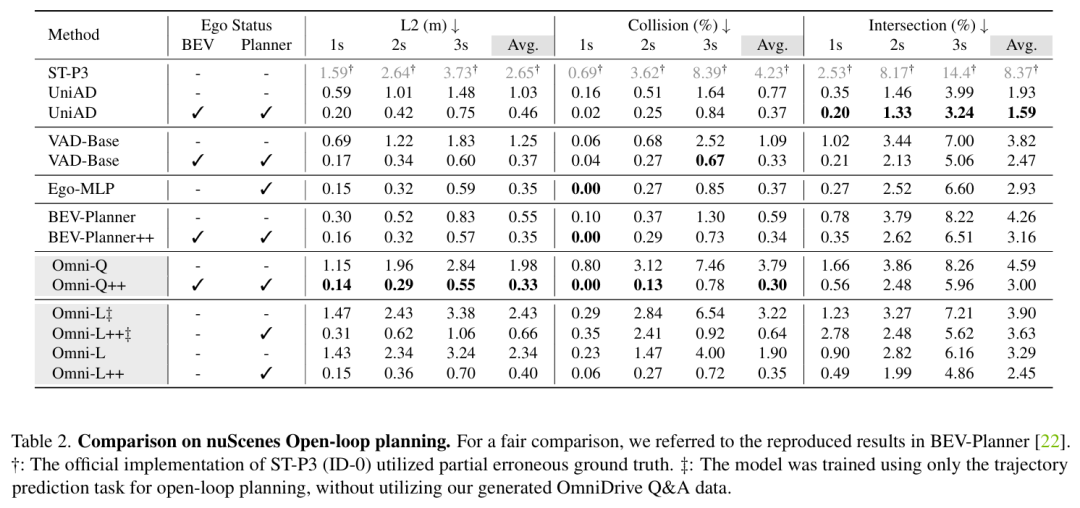
主要实验结果:
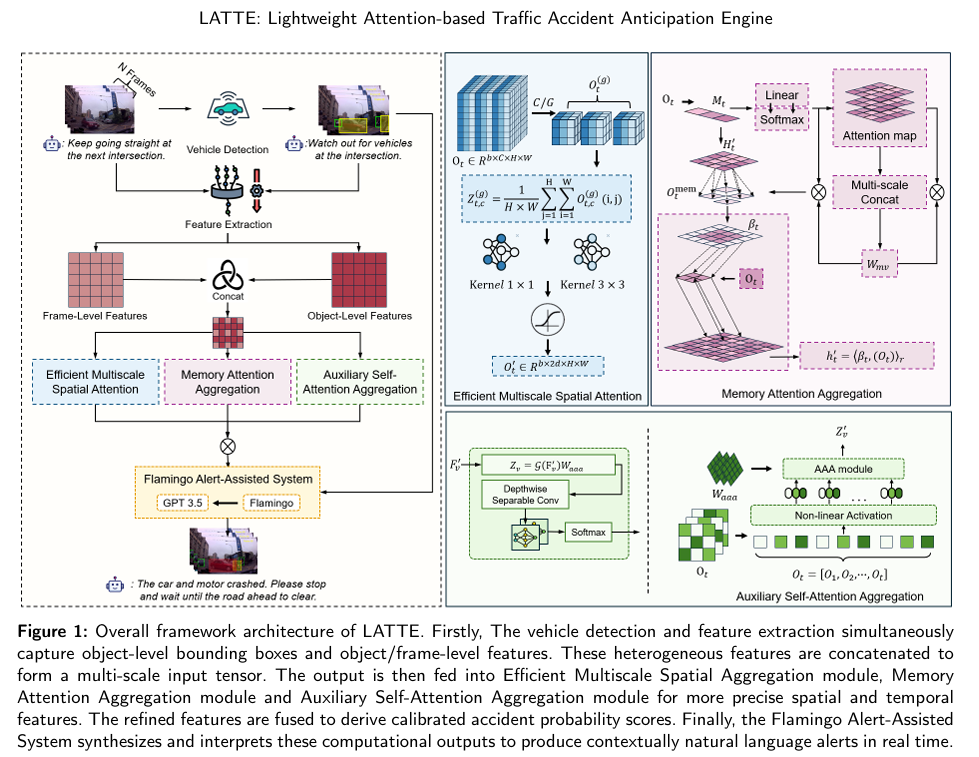
LATTE
标题:LATTE: A Real-time Lightweight Attention-based Traffic Accident Anticipation Engine
链接:https://arxiv.org/abs/2504.04103
作者单位:澳门大学
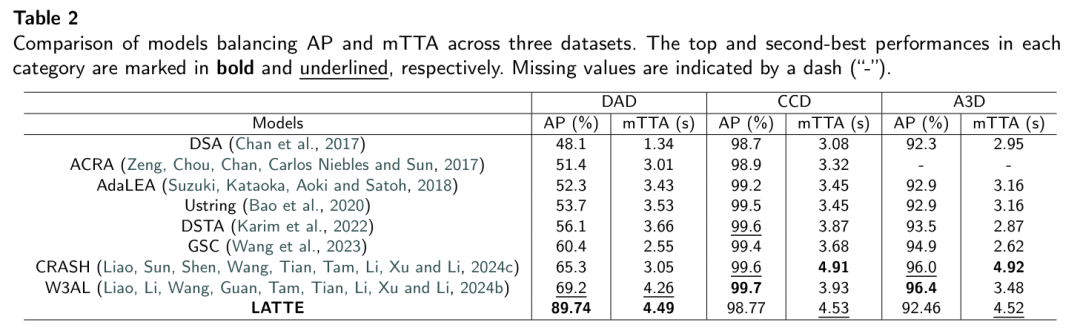
准确预测交通事故是自动驾驶领域的一项关键挑战,尤其在资源受限环境中。现有解决方案往往存在计算开销大的问题,或无法充分应对交通场景演化的不确定性。本文提出了 LATTE(轻量级注意力基交通事故预测引擎),该引擎融合了计算效率与最先进性能。LATTE 采用高效多尺度空间聚合(EMSA)捕捉跨尺度空间特征,记忆注意力聚合(MAA)增强时序建模,辅助自注意力聚合(AAA)提取长序列潜在依赖关系。此外,LATTE 集成了火烈鸟警报辅助系统(FAA),利用视觉 - 语言模型提供实时、易于理解的语音危险警报,提升乘客情境感知能力。在基准数据集(DAD、CCD、A3D)上的评估表明,LATTE 具有卓越的预测能力和计算效率。在 DAD 基准上,LATTE 实现了 89.74% 的平均精度(AP),平均事故提前时间(mTTA)比第二好的模型高 5.4%,在召回率为 80% 时保持有竞争力的 mTTA(TTA@R80 为 4.04 秒),且在不同驾驶条件下均能稳健预测事故。其轻量级设计使浮点运算(FLOPs)减少 93.14%,参数数量(Params)减少 31.58%,可在资源有限的硬件上实现实时运行且不损失性能。消融研究证实了 LATTE 各架构组件的有效性,可视化和失败案例分析突显了其实用性及需改进的方向。
算法概览:
主要实验结果:
EM-VLM4AD
标题:Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
链接:https://arxiv.org/abs/2403.19838
项目主页:https://github.com/akshaygopalkr/EM-VLM4AD/tree/main
作者单位:加利福尼亚大学圣迭戈分校
视觉 - 语言模型(VLMs)和多模态语言模型(MMLMs)在自动驾驶研究中已占据重要地位,这些模型能够利用交通场景图像和其他数据模态,为端到端自动驾驶安全任务提供可解释的文本推理和响应。然而,当前这些系统的实现方案采用了昂贵的大语言模型(LLM)骨干网络和图像编码器,使得这类系统不适用于存在严格内存限制且需要快速推理时间的实时自动驾驶系统。为解决上述问题,我们开发了 EM-VLM4AD,这是一种高效、轻量的多帧视觉 - 语言模型,用于执行自动驾驶领域的视觉问答任务。与现有方法相比,EM-VLM4AD 所需内存和浮点运算至少减少 10 倍,同时在 DriveLM 数据集上的 CIDEr 和 ROUGE 评分也高于现有基线。此外,EM-VLM4AD 还能够从与提示相关的交通视图中提取关键信息,并能回答各种自动驾驶子任务的相关问题。
算法概览:
主要实验结果:

Is it safe to cross
标题:Is it safe to cross? Interpretable Risk Assessment with GPT-4V for Safety-Aware Street Crossing
链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10597464
作者单位:马萨诸塞大学阿默斯特分校
安全穿越街道交叉口对盲人而言是一项复杂挑战,这要求对周边环境进行精细感知——而该任务高度依赖视觉线索。传统的决策辅助方法往往存在局限,无法提供全面的场景分析与安全等级评估。本文提出一种创新方案,利用视觉语言模型解析复杂的过街场景,较之传统交通信号识别技术具有显著进步。通过生成自然语言描述的安全评分与场景解析,本方法可为视障群体提供安全决策支持。我们采集了包含四足机器人多视角第一人称图像的斑马线交叉口数据集,并依据预设的安全评分分级标准对图像进行标注评分。基于从图像和文本提示中提取的视觉知识,我们评估了视觉语言模型在安全评分预测与场景描述方面的性能。研究表明,该模型通过多样化的提示词激活的推理能力与安全评分预测机制,为开发可信赖决策支持系统提供了关键路径,这对需要高可靠性决策辅助的应用场景至关重要。
NuScenes-MQA
标题:NuScenes-MQA: Integrated Evaluation of Captions and QA for Autonomous Driving Datasets using Markup Annotations
链接:https://ieeexplore.ieee.org/abstract/document/10495633
数据集:https://github.com/turingmotors/NuScenes-MQA
作者单位:图灵
视觉问答(VQA)作为自动驾驶领域的关键技术,需实现精准环境识别与复杂场景评估。然而,目前尚缺乏基于行车场景构建的问答格式标注数据集,此类数据集对保证语言生成精确性与场景识别能力至关重要。本研究提出创新性标注技术Markup-QA——通过标记语言封装问答对,该框架可同步评估模型在语句生成与视觉问答的双重能力。基于此标注方法,我们构建了NuScenes-MQA数据集,聚焦描述能力与精准问答的双重特性,为自动驾驶任务的视觉语言模型开发提供新范本。
LLM Multimodal Traffic Accident Forecasting
标题:LLM Multimodal Traffic Accident Forecasting
链接:https://www.mdpi.com/1424-8220/23/22/9225
作者单位:歌德大学,瓦伦西亚理工大学等
随着城市中心交通拥堵日益加剧,交通事故预测对于城市规划和公共安全已变得至关重要。本文系统评估了现代深度学习(DL)方法在预测交通事故以及通过可操作的视听提示增强L4/L5级驾驶辅助系统方面的效能。基于详细记录交通事故发生情况的丰富数据集,我们对比验证了Transformer模型与传统时间序列模型(如ARIMA)及较新的Prophet模型的性能。此外,通过细致的分析,我们运用主成分分析(PCA)载荷深入探究了特征重要性,揭示了导致事故的关键因素。我们创新性地提出在自动驾驶中利用轻量级紧凑型大语言模型(LLM)(如LLaMA-2和Zephyr-7b-𝛼)进行实时干预的思路。我们的探索还延伸至多模态领域:通过结合大型语言视觉助手(LLaVA)——一种利用视觉语言模型(VLM)桥接视觉与语言提示的技术——与深度概率推理,提升了自动驾驶系统的实时响应能力。本研究阐明了在深度学习和深度概率编程中运用大型多模态模型,对于提升时间序列预测及特征权重重要性的性能和实用性的优势,尤其在自动驾驶场景中。此项工作为构建依托数据驱动决策的更安全、更智能的城市奠定了重要基础。
主要实验结果:
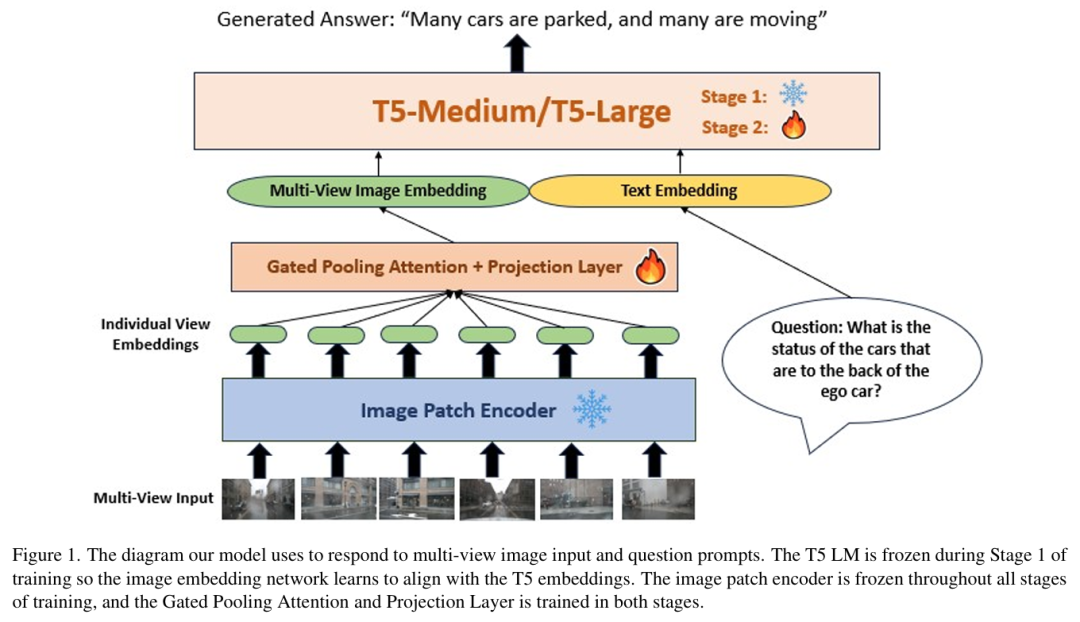
Talk2BEV
标题:Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
链接:https://arxiv.org/abs/2310.02251
项目主页:https://llmbev.github.io/talk2bev/
作者单位:麻省理工学院,不列颠哥伦比亚大学、塔尔图大学等
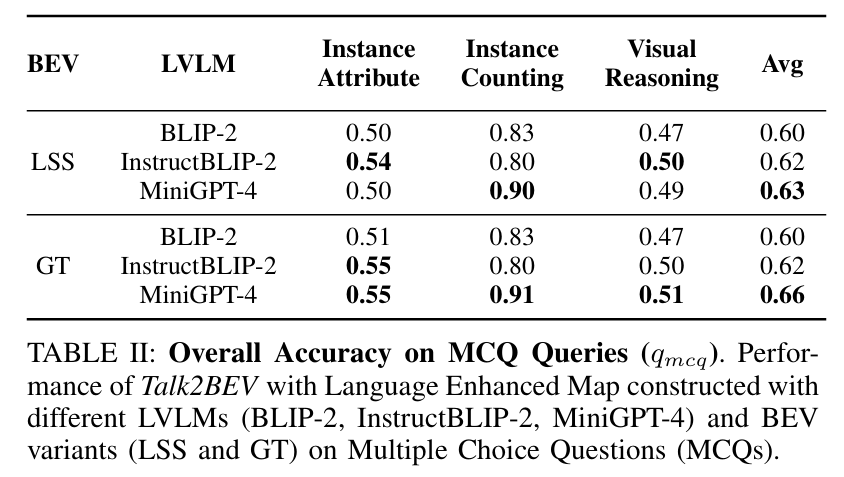
本文介绍了 Talk2BEV,这是一种用于自动驾驶场景下BEV地图的大型视觉 - 语言模型(LVLM)接口。现有自动驾驶感知系统主要聚焦于预定义(封闭)的对象类别和驾驶场景,而 Talk2BEV 将通用语言和视觉模型的最新进展与 BEV 结构的地图表示相结合,无需特定任务模型。这使得单一系统能够应对多种自动驾驶任务,包括视觉与空间推理、预测交通参与者意图以及基于视觉线索的决策。我们在大量场景理解任务上对 Talk2BEV 进行了广泛评估,这些任务既依赖于解释自由形式自然语言查询的能力,也依赖于将这些查询与嵌入语言增强 BEV 地图中的视觉上下文相关联的能力。为了推动大型视觉 - 语言模型在自动驾驶场景中的进一步研究,我们开发并发布了 Talk2BEV-Bench 基准,该基准包含 1000 个人工标注的 BEV 场景,以及来自 NuScenes 数据集的 20000 多个问题和真实标注答案。
算法概览:
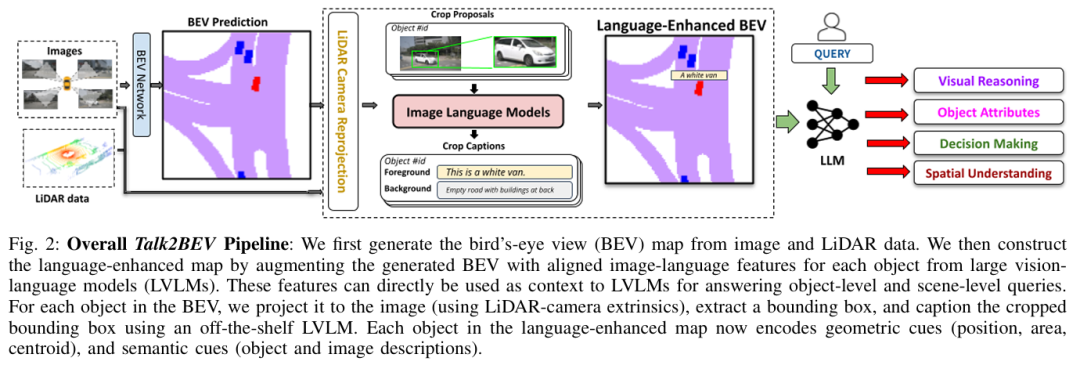
主要实验结果:
On the Road with GPT-4V
标题:On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
链接:https://arxiv.org/abs/2311.05332
项目主页:https://github.com/PJLab-ADG/GPT4V-AD-Exploration
作者单位:上海人工智能实验室、华东师范大学、香港中文大学等
自动驾驶技术的追求取决于感知、决策和控制系统的复杂整合。无论是数据驱动还是基于规则的传统方法,都因无法把握复杂驾驶环境的细微差别以及其他道路使用者的意图而受阻。这一点已成为显著瓶颈,尤其体现在开发安全可靠的自动驾驶所需的常识推理和精细场景理解方面。视觉语言模型(VLM)的出现为实现完全自动驾驶开辟了新领域。本报告对最先进的 VLM——GPT-4V(视觉版)及其在自动驾驶场景中的应用进行了全面评估。我们探究了该模型理解和推理驾驶场景、做出决策并最终以驾驶员身份采取行动的能力。我们的综合测试涵盖了从基本场景识别到复杂因果推理,以及不同条件下的实时决策。研究结果表明,与现有自动驾驶系统相比,GPT-4V 在场景理解和因果推理方面表现更优。它展示出处理分布外场景、识别意图以及在真实驾驶环境中做出明智决策的潜力。然而,挑战依然存在,尤其在方向辨别、交通灯识别、视觉定位和空间推理任务中。这些局限性凸显了进一步研发的必要性。

OpenAnnotate3D
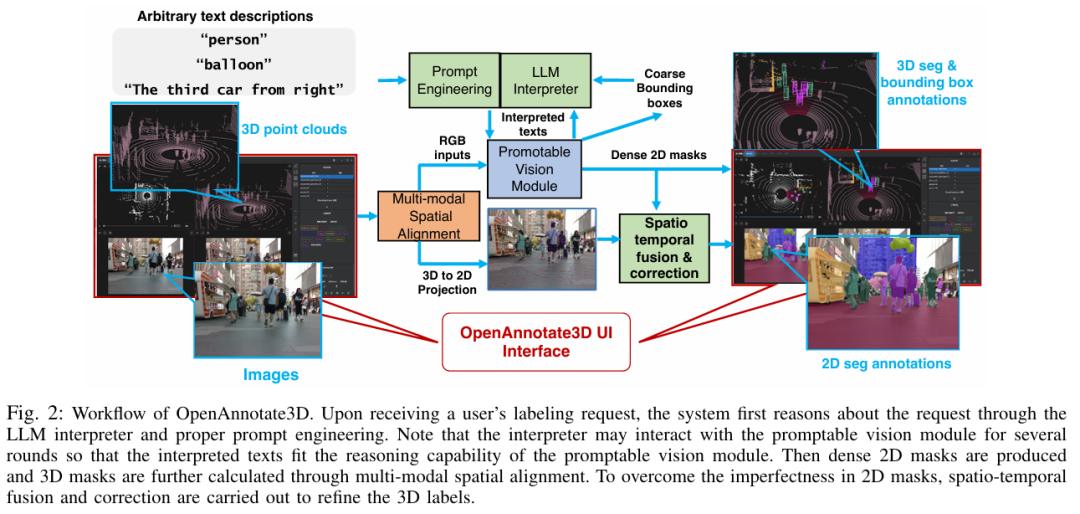
标题:OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
链接:https://arxiv.org/abs/2310.13398
项目主页:https://github.com/Fudan-ProjectTitan/OpenAnnotate3D
作者单位:复旦大学,多伦多大学
在大数据和大模型时代,多模态数据的自动标注功能对于现实世界中人工智能驱动的应用(如自动驾驶和具身智能)具有重要意义。与传统的闭集标注不同,开放词汇标注是实现人类级认知能力的关键。然而,针对多模态 3D 数据的开放词汇自动标注系统较少。在本文中,我们介绍 OpenAnnotate3D,这是一个开源的开放词汇自动标注系统,能够为视觉和点云数据自动生成 2D 掩码、3D 掩码和 3D 边界框标注。该系统整合了大语言模型(LLMs)的思维链能力和视觉 - 语言模型(VLMs)的跨模态能力。据我们所知,OpenAnnotate3D 是开放词汇多模态 3D 自动标注领域的开创性工作之一。我们在公共数据集和内部真实世界数据集上进行了全面评估,结果表明,与人工标注相比,该系统显著提高了标注效率,同时提供了准确的开放词汇自动标注结果。
算法概览:
主要实验结果:

Unsupervised 3D Perception
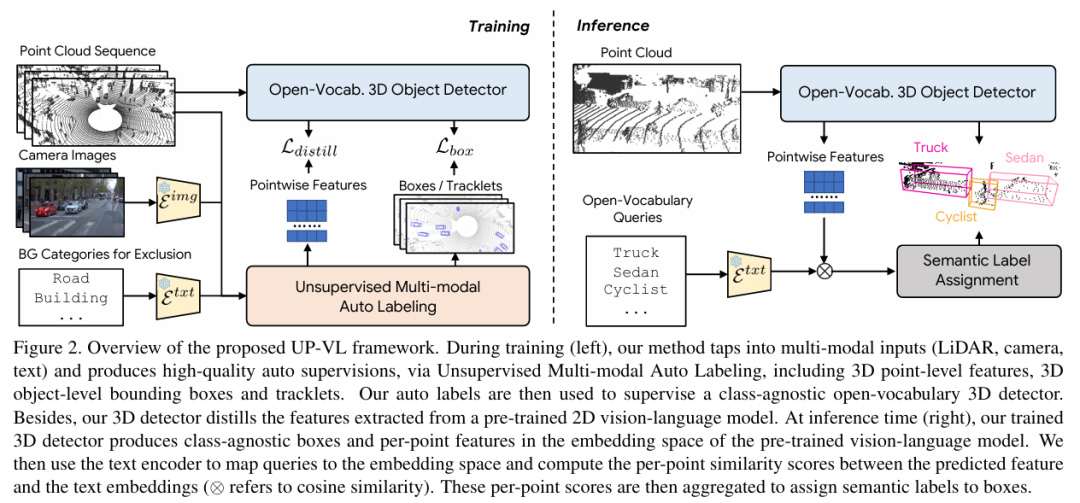
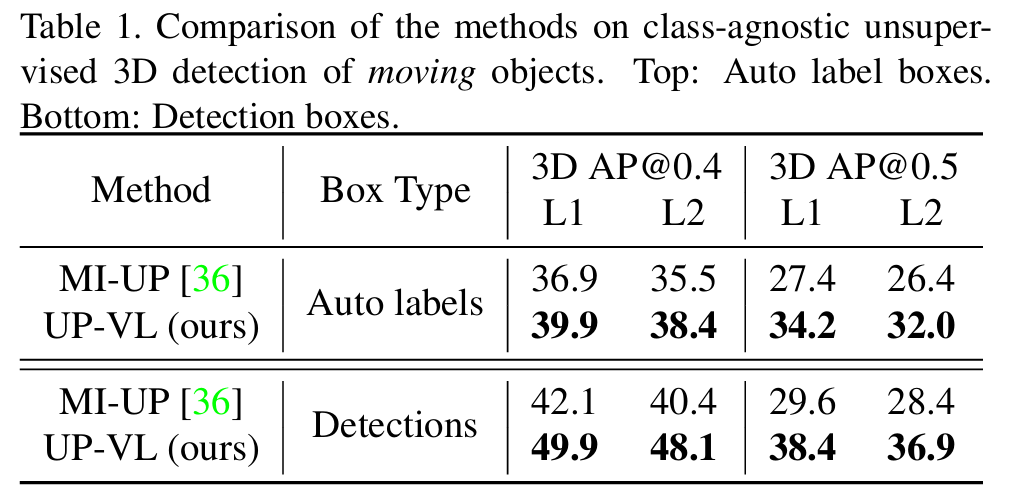
标题:Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
链接:https://arxiv.org/abs/2309.14491
项目主页:
作者单位:WaymoLLC
ICCV 2023中稿的工作,闭集3D感知模型仅在预定义的物体类别集上训练,对于自动驾驶等安全关键应用而言可能存在不足,因为部署后可能会遇到新的物体类型。本文提出了一种多模态自动标注流程,能够生成无模态 3D 边界框和轨迹片段,用于在无 3D 人工标注的情况下训练开放集类别的模型。我们的流程利用点云序列中固有的运动线索,结合可免费获取的 2D 图像 - 文本对,来识别和跟踪所有交通参与者。与该领域近期的研究相比,那些研究仅能提供限于移动物体的无类别自动标注,而我们的方法能够以无监督方式处理静态和动态物体,并且由于所提出的视觉 - 语言知识蒸馏,能够输出开放词汇语义标签。在 Waymo 开放数据集上的实验表明,我们的方法在各种无监督 3D 感知任务上显著优于先前的工作。
算法概览:
主要实验结果:
本文全部文章已汇总至『自动驾驶之心知识星球』,欢迎加入我们,共同探索AI驱动的自动驾驶前沿!



















 5120
5120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









