



点击下方卡片,关注“自动驾驶之心”公众号
今日星球自动驾驶前沿算法更新:
哈工大等团队思维链最新综述;
新加坡国立最细年底思维链综述;
上交提出ChatBEV;
复旦中稿CVPR'25的端到端算法BridgeAD;
Advances in 4D Generation
论文标题:Advances in 4D Generation: A Survey
论文链接:https://arxiv.org/abs/2503.14501
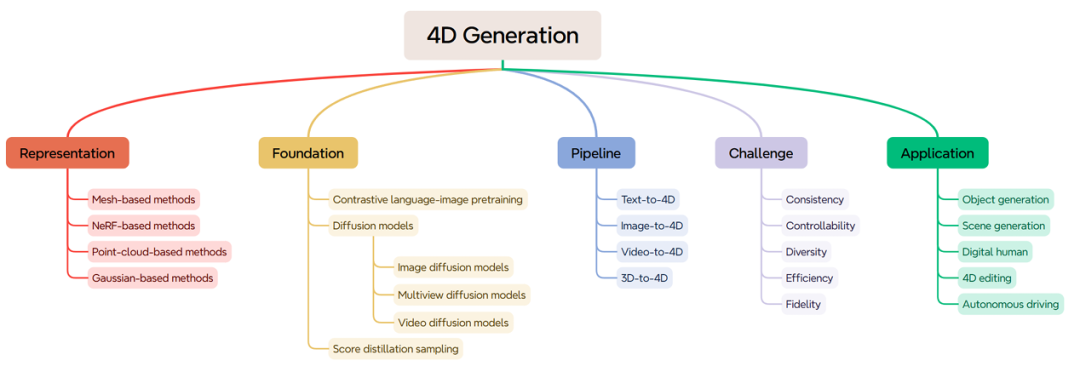
核心创新点:
1. 系统性分类框架
提出基于控制条件的四层分类法(文本、图像、视频、3D、多条件),为4D生成任务提供结构化框架(如MAV3D、AYG、TC4D等方法),帮助研究者快速定位技术路径并识别研究空白。
2. 4D表示方法的突破
4D高斯泼溅(4D Gaussian Splatting):通过时空编码与变形场建模动态场景,结合显式高斯点表示与隐式运动预测(如Wu et al.的4D GS框架),提升动态渲染效率与质量。
动态NeRF扩展:引入时空分解策略(如HexPlane、K-Planes)与紧凑特征平面(如Tensor4D),优化动态场景的渲染速度与存储开销。
3. 融合扩散模型与物理先验
分数蒸馏采样(SDS)的优化:通过多阶段扩散模型(文本-图像、文本-视频)联合优化,提升4D资产的时空一致性(如PLA4D的像素对齐策略)。
物理驱动生成:结合物质点法(MPM)模拟粒子动力学(如Sync4D、Phy124),增强运动合理性与物理真实性。
4. 关键挑战的解决方案
一致性:引入跨视角注意力层(L4GM)与多模型融合(CT4D结合高斯与网格表示),解决几何与时间一致性难题。
效率:采用显式高斯表示(DreamGaussian4D)与中间数据生成(Efficient4D),将单模型生成时间缩短至数分钟。
可控性:多条件输入(文本+轨迹、图像+骨架)与混合表征(高斯+网格),实现精细运动与外观控制。
5. 多领域应用创新
数字人合成:通过骨架感知优化(STAR4D)与身份编码(Human4DiT),生成高保真动态人体模型。
自动驾驶仿真:结合稀疏点云与视频扩散模型(MagicDrive3D、DreamDrive),构建动态4D场景世界模型。
6. 未来方向与社会影响
数据集与评估标准:呼吁构建大规模文本-4D数据集(如Diffusion4D的5.4万动态资产),并提出适配4D生成的多维度评测基准(如T2ICompBench扩展)。
社会伦理:强调技术滥用风险(如深度伪造),倡导透明化生成流程与责任机制。
本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流。这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!欢迎加入~
知识星球大额优惠!欢迎扫码加入~

EdgeRegNet
论文标题:EdgeRegNet: Edge Feature-based Multimodal Registration Network between Images and LiDAR Point Clouds
论文链接:https://arxiv.org/abs/2503.15284
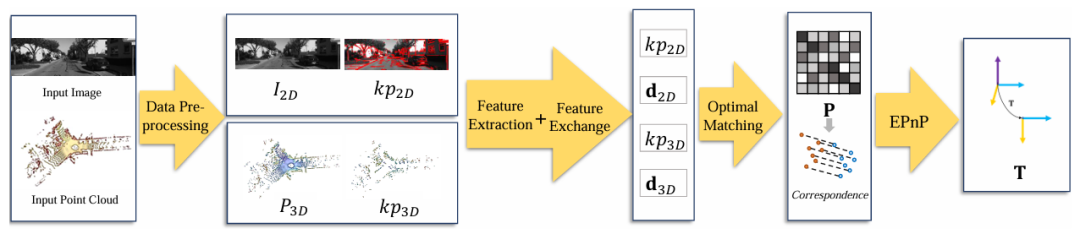
核心创新点:
1. 基于边缘特征的跨模态全局配准框架
提出首种利用2D图像边缘像素与3D点云边缘点进行全局配准的方法。通过融合深度不连续点与反射率不连续点(点云)以及LSD算法提取的线结构(图像),保留原始空间信息,避免下采样导致的信息损失,显著提升配准精度。
2. 注意力驱动的跨维度特征交互模块
设计基于自注意力与交叉注意力机制的特征交换模块,通过多层堆叠实现跨模态特征空间对齐。该模块利用位置编码与线性变换生成Q/K/V矩阵,在2D图像特征(CNN提取)与3D点云特征(PointNet++提取)间进行双向信息融合,有效缓解模态差异。
3. 基于最优传输的轻量化匹配优化层
引入LightGlue的轻量级最优匹配策略,通过可学习线性层计算相似性矩阵,结合Sigmoid激活的匹配概率预测,构建部分分配矩阵。采用Sinkhorn算法高效求解最优对应关系,提升匹配鲁棒性,同时降低计算复杂度。
4. 多任务驱动的混合损失函数
设计三阶段联合损失函数:
FOV损失( :通过二元交叉熵约束点云特征是否在相机视野内;
匹配概率损失( :监督2D像素与3D点的可匹配性概率;
分配矩阵损失(:最大化真实匹配对的分配概率。
通过加权融合( + + )实现端到端优化。
5. 高效全局配准性能
在KITTI与nuScenes数据集上,相比DeepI2P、CorrI2P等方法,EdgeRegNet在相对平移误差(RTE)、相对旋转误差(RRE)与推理速度(RTX 3090平台达25ms/帧)上均达到SOTA,成功解决传统方法对初始校准依赖及大偏移场景的失效问题。
HAD-Gen
论文标题:HAD-Gen: Human-like and Diverse Driving Behavior Modeling for Controllable Scenario Generation
论文链接:https://arxiv.org/abs/2503.15049
论文代码:https://github.com/RoboSafe-Lab/Sim4AD
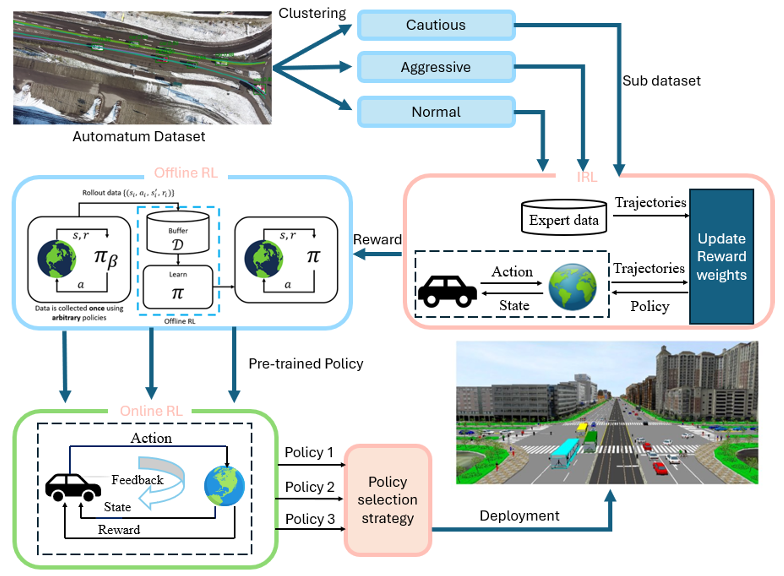
核心创新点:
1. 驾驶风格聚类方法
提出基于风险特征(THW时间头距、iTTC逆时碰撞时间)的驾驶行为聚类框架,将驾驶风格划分为攻击型/正常型/谨慎型,通过轨迹片段比例(ratiorli)量化风险偏好,解决传统方法行为多样性不足的问题。
2. 分风格奖励函数重建
采用最大熵逆强化学习(MaxEnt IRL)为每类驾驶风格独立构建奖励函数,通过多项式轨迹采样近似配分函数,显式编码不同风格的底层驾驶动机(如攻击型赋予横向加速度高权重),突破传统IRL平均化策略的局限性。
3. 混合强化学习训练范式
创新性整合离线RL(TD3+BC)预训练与多智能体在线RL(SAC-CTDE),前者利用历史数据避免分布偏移,后者通过集中训练分散执行(CTDE)提升交互鲁棒性,解决单一RL方法泛化性差的挑战。
4. 可控场景生成机制
通过策略渗透率调控实现场景多样性(如提升攻击型策略比例生成高风险场景),在Automatum数据集验证中达成90.96%目标到达率,较传统BC/TD3+BC/SAC基线提升超20%,同时保持微观指标(JSD<0.1)的人类行为相似性。
DRoPE
论文标题:DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
论文链接:https://arxiv.org/abs/2503.15029
核心创新点:
1. 方向感知的旋转位置编码(DRoPE)
针对自动驾驶轨迹生成中周期性角度建模难题,提出改进的旋转位置编码(RoPE)方法。通过引入统一标量参数 重构2D旋转矩阵,将代理航向角与旋转角度对齐,首次实现显式相对角度编码 ,克服传统RoPE因周期性导致的相对角度信息丢失问题。
2. 时空复杂度优化
在保持Transformer架构O(N)空间复杂度的前提下,通过绝对位置编码隐式表达相对位置关系 ,避免传统RPE方法O(N²)的显式存储开销。理论证明其满足相对位置编码的等变性约束,同时支持全局长程交互建模。
3. 双模态集成架构
提出两种DRoPE-RoPE集成方案:头间分离式(Head-by-Head)和 头内分解式(Intra-Head) ,分别通过多头注意力机制分离位置/方向编码或向量分解,实验证明前者在轨迹预测指标(minADE↓0.052)和交互真实性(REALISM↑0.7625)上更优。
Generating Multimodal Driving Scenes via Next-Scene Prediction
论文标题:Generating Multimodal Driving Scenes via Next-Scene Prediction
论文链接:https://arxiv.org/abs/2503.14945
项目主页:https://yanhaowu.github.io/UMGen/
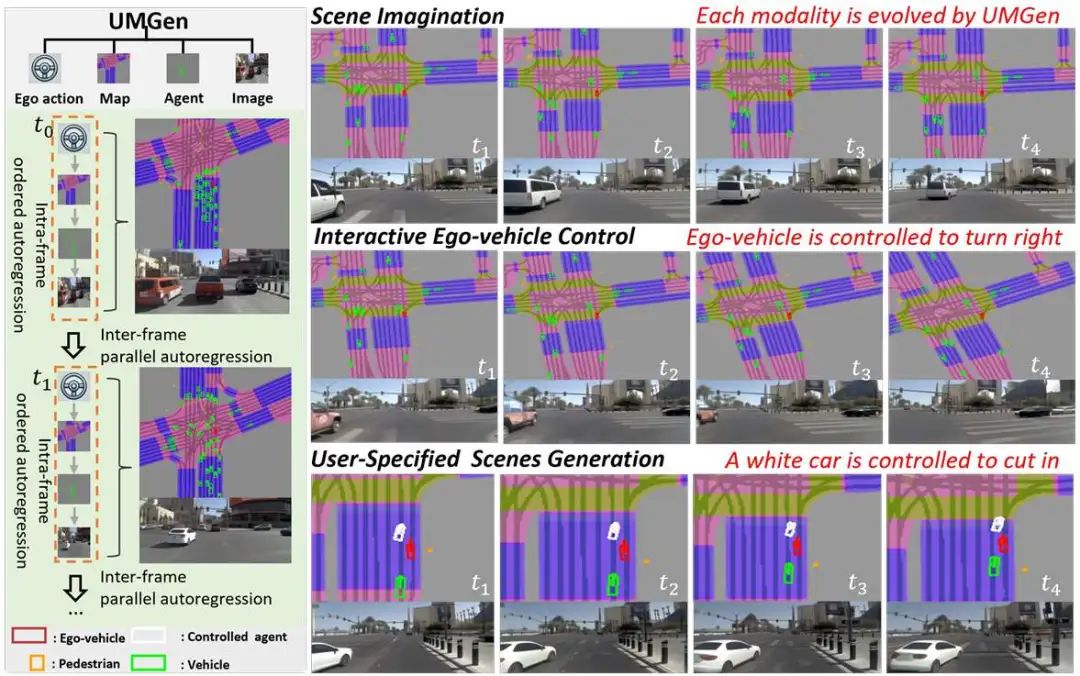
核心创新点:
1. 多模态动态场景建模:
首次在自动驾驶场景生成中同时整合自车动作(ego-action)、交通参与者(road users)、动态地图(traffic map)与图像(image)四模态,新增地图模态的动态生成能力,突破传统方法静态地图或单一模态生成的限制,实现场景表征的完整性与可控性。
2. 分层自回归框架(TAR + OAR):
时序自回归模块(TAR):通过因果注意力机制(causal attention)捕捉跨帧时序依赖,降低长序列建模复杂度(计算成本从O 降至O( ))。
有序自回归模块(OAR):在单帧内按固定模态顺序(ego → map → agent → image)进行令牌(token)级自回归解码,确保跨模态对齐与一致性,减少代理碰撞率(CR降低8.9%)。
3. 动作感知地图对齐(AMA):
基于自车动作(位移dx,dy与转角θ)对地图特征进行仿射变换(affine transformation),动态调整地图空间表示,解决自车运动与地图演化的时空一致性难题(实验显示地图偏移误差降低42%)。
4. 用户导向的交互控制:
支持通过指定自车动作(如急转、变道)或交通参与者行为(如切入)生成复杂交互场景(如紧急避障),结合多模态联合仿真,为AD系统测试提供高保真闭环环境。
5. 高效长序列生成:
框架可生成长达60秒的连续驾驶场景(21帧/秒),在nuPlan与Waymo数据集上MMD指标优于基线模型30%以上,GPU内存占用仅为传统自回归模型的1/4。
Learning-based 3D Reconstruction in Autonomous Driving
论文标题:Learning-based 3D Reconstruction in Autonomous Driving: A Comprehensive Survey
论文链接:https://arxiv.org/abs/2503.14537

核心创新点:
1. 数据范式革新
提出从多传感器标定数据(如对齐点云与图像)转向未标定图像序列的重建框架,显著降低数据采集门槛
发展基于单目/多目无约束图像的动态场景解耦技术(如SUDS、EmerNeRF),减少对3D标注的依赖
2. 3D表示突破
3D高斯泼溅(3D Gaussian Splatting)技术革新,实现高保真场景表征与低计算开销的平衡
混合高斯表示(HGS-Mapping)结合几何先验约束,提升城市场景重建精度
动态高斯神经点渲染(DGNR)实现大范围驾驶场景的密度引导重建
3. 大规模优化策略
空间划分范式(Spatial Partitioning)突破硬件限制,支持城市级场景分治重建
分布式高斯优化(DOGS)通过高斯共识机制实现超大规模场景并行处理
4. 动态场景建模
时序属性解耦框架(如VDG)分离静态/动态成分,引入周期振动高斯模型处理交通振动干扰
神经场景图(Neural Scene Graphs)实现动态物体轨迹与场景结构的联合建模
5. 生成式重建体系
组合生成模型CityDreamer与GaussianCity构建无界城市生成框架
隐式神经辐射场(UrbanNeRF)融合语义先验,实现城市场景可控生成
6. 系统级集成
PreSight框架集成NeRF先验记忆,提升感知系统语义-几何联合推理能力
UniPAD通过重建补全解决驾驶场景的部分可观测性问题
7. 基准创新
构建多模态自动驾驶专用数据集(MatrixCity、Argoverse2)
提出动态场景评估指标,涵盖几何保真度、时序一致性、语义完整性等维度
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~
知识星球大额优惠!欢迎扫码加入~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









