



点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享伯克利&Waymo最新的工作!S4-Driver:无需人工标注,大模型驱动自动驾驶规划新范式!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
论文作者 | Yichen Xie
等编辑 | 自动驾驶之心
写在前面 && 笔者理解
虽然端到端自动驾驶,近两年被炒的火热,但是其实探索端到端自动驾驶的历史可以追溯到20世纪80年代。当时的运动规划模型直接根据原始传感器输入预测控制信号,不过由于鲁棒性的问题,早期的一些尝试,在复杂的城市环境难以泛化。最近风靡一时的多模态大语言模型(MLLMs)恰好具有强大的泛化能力,将这两者结合,似乎成了势不可挡的趋势。然而,将MLLMs直接应用于端到端运动规划很难发挥其强大的视觉理解和推理能力,因为运动规划和MLLM预训练任务之间存在显著差异,导致规划性能较差。
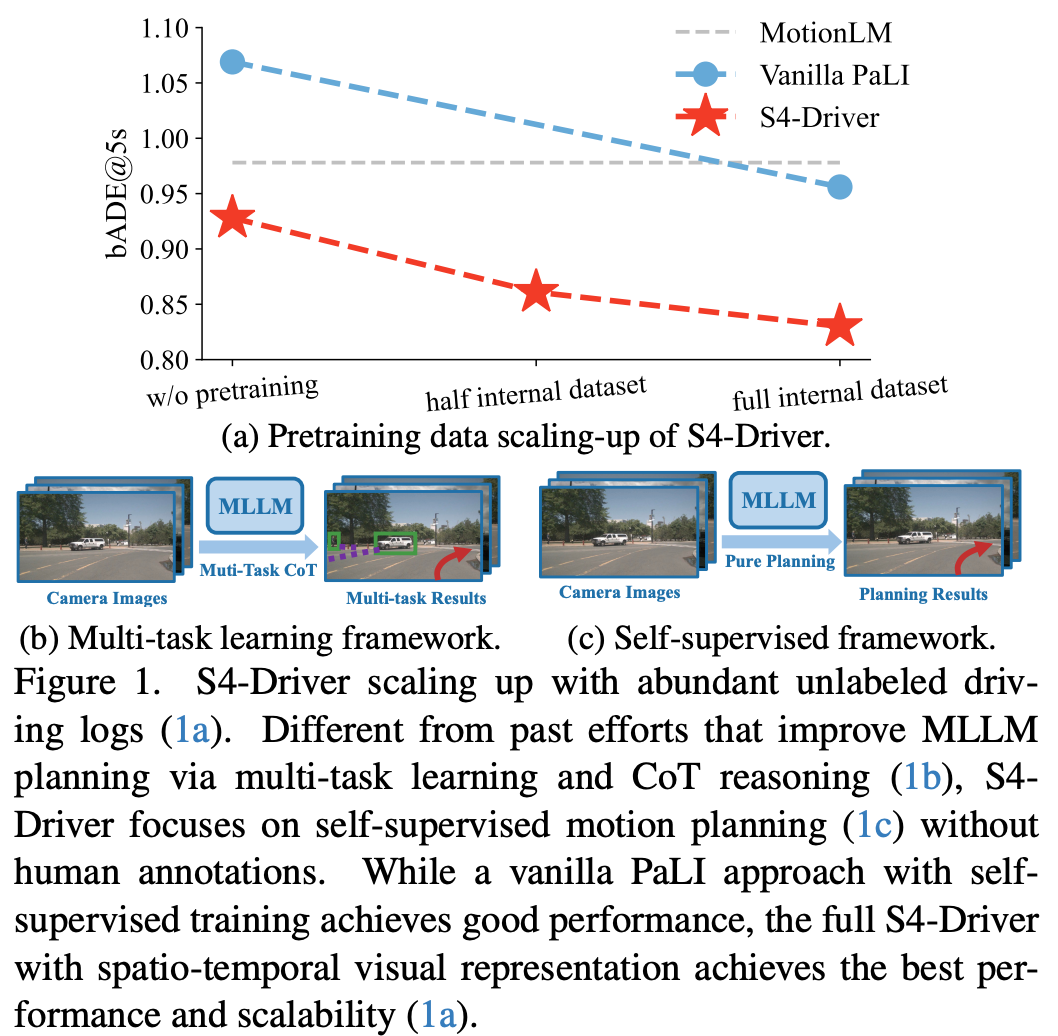
为了缩小这一差距,如图1b所示,以往的方法使用多任务学习,将多种感知和预测任务纳入训练和推理中,或者采用监督感知预训练,利用预训练的自动驾驶感知模型作为视觉token。然而,人类标注成为了这两种策略的瓶颈。相比之下,纯自监督方法虽然能够直接从传感器输入学习并利用大量未标注的驾驶数据,但通常表现不如现有的最先进方法。
论文题目: S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation
论文链接:https://arxiv.org/pdf/2505.24139
首先,作者确定了以下两个主要障碍:
非最优的表达形式:MLLMs通常为2D图像平面中的任务设计。这种图像空间表示限制了它们从多视图图像组合中进行3D推理的能力。
数据规模有限:尽管nuScenes是端到端规划非常广泛的数据集,但它也仅包含不到1k个序列,缺乏驾驶行为的多样性。这种有限的规模导致在微调具有十亿参数规模的MLLMs时出现严重的过拟合问题。
在本文中,作者提出了S4-Driver,这是一个简单而有效的可扩展自监督运动规划方法,具有时空视觉表示。基于通用多模态大语言模型,作者直接从相机图像预测自身车辆的航点,消除了对中间感知和预测任务的需求,从而促进了利用大量未标注驾驶数据进行模型预训练的规模化(图1a)。为了解决非最优的表达形式的障碍,作者提出了一种新颖的稀疏体积表示,能够聚合来自多视图和多帧图像的视觉信息,提升了模型在运动规划上的3D时空推理能力,并无损的保留了MLLMs预训练视觉嵌入中的世界知识。
其次,为了严格评估法并提供足够的训练数据,作者还利用了大规模的WOMD-Planning-ADE benchmark,并结合了内部相机传感器数据。该 benchmark 大约比nuScenes大100倍,因此它可以作为一个更全面的基准。
相关工作
多模态大语言模型 (MLLMs)
多模态大语言模型(MLLMs)同时包含语言和图像模态,以往的研究主要集中在将强大的大型语言模型(LLMs)与先进的图像编码器(例如LLaVA、PaLI、PaliGemma以及InstructBLIP)进行整合。通过指令微调或多模态微调,这些模型在多模态理解和推理方面展现出了不错的性能。当前的发展趋势是利用越来越大的多模态数据集来进一步提升它们在复杂感知和泛化任务中的能力。然而,尽管这些模型具有诸多优势,但它们在3D空间推理方面仍存在局限性,这给它们在自动驾驶领域的应用带来了一些挑战。
端到端自动驾驶
为了减少传统的感知、预测、规划的各模块间的信息丢失和误差累积,端到端驾驶系统利用统一的模型直接从原始传感器输入预测自身车辆未来的航点或控制信号。尽管这些系统优先考虑规划,但它们通常仍会整合感知和预测模块,还是需要对每个模块进行明确的监督。尽管一些早期的工作已经探索了无需任何中间任务的纯运动规划,但由于建模能力有限,它们在复杂的城市场景中表现不佳。
自动驾驶中的 MLLMs
大型模型的卓越推理和泛化能力正是自动驾驶领域应用需要的能力。一些研究将驾驶场景转化为大型语言模型的文本提示,或者直接用视觉语言模型处理相机图像。然而,它们的潜力受到现有benchmark数据量的限制,仅允许进行部分微调。同时,闭环模拟器在为端到端任务提供逼真的传感器数据方面也面临挑战。因此,多任务联合微调或思维链推理(CoT)被广泛采用,来简化推理过程。另一种思路,一些工作整合了预训练的感知模型,以提取鸟瞰图特征,并将其作为视觉token发送给语言模型。最近,EMMA利用强大的Gemini进行自监督运动规划。此外,它们还开发了一组训练任务,包括运动规划、3D目标检测和道路元素识别,以及用于轨迹生成的一些推理过程。相比之下,作者的工作专注于在无需额外人类标签的情况下增强自监督运动规划。
具体工作
Vanilla PaLI as Planner
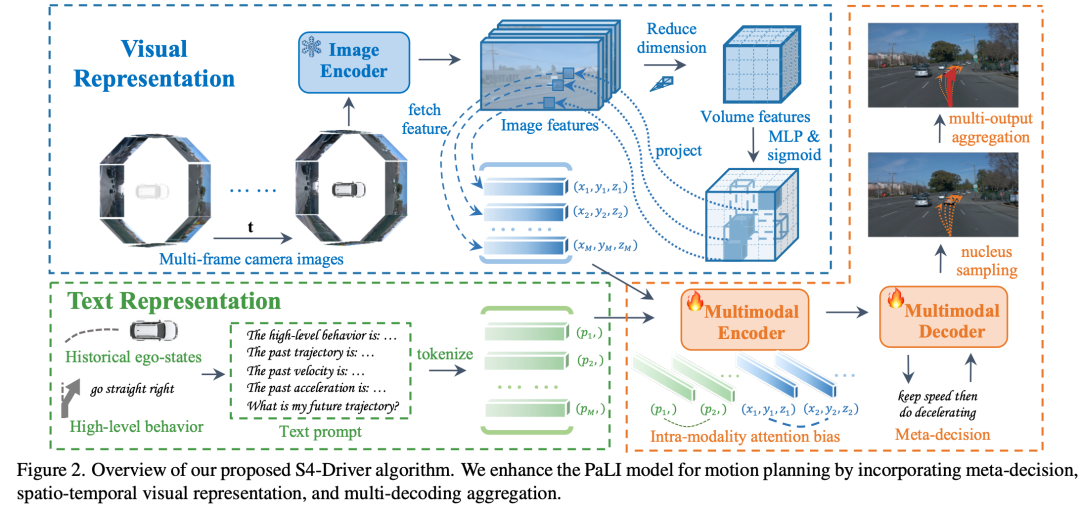
端到端运动规划模型根据多视图相机图像 和高级行为指令 来确定自身车辆的未来轨迹 。未来轨迹包括自身车辆在鸟瞰图坐标系中每个未来时刻的位置,即 。高级行为指令可以理解为导航系统,对于蔚来轨迹的规划是非常重要的,至少要知道车往哪里开。此外,自身车辆的历史状态 对于获得平滑且可行的规划结果也很重要,其中作者将历史位置、速度和加速度视为 ,即
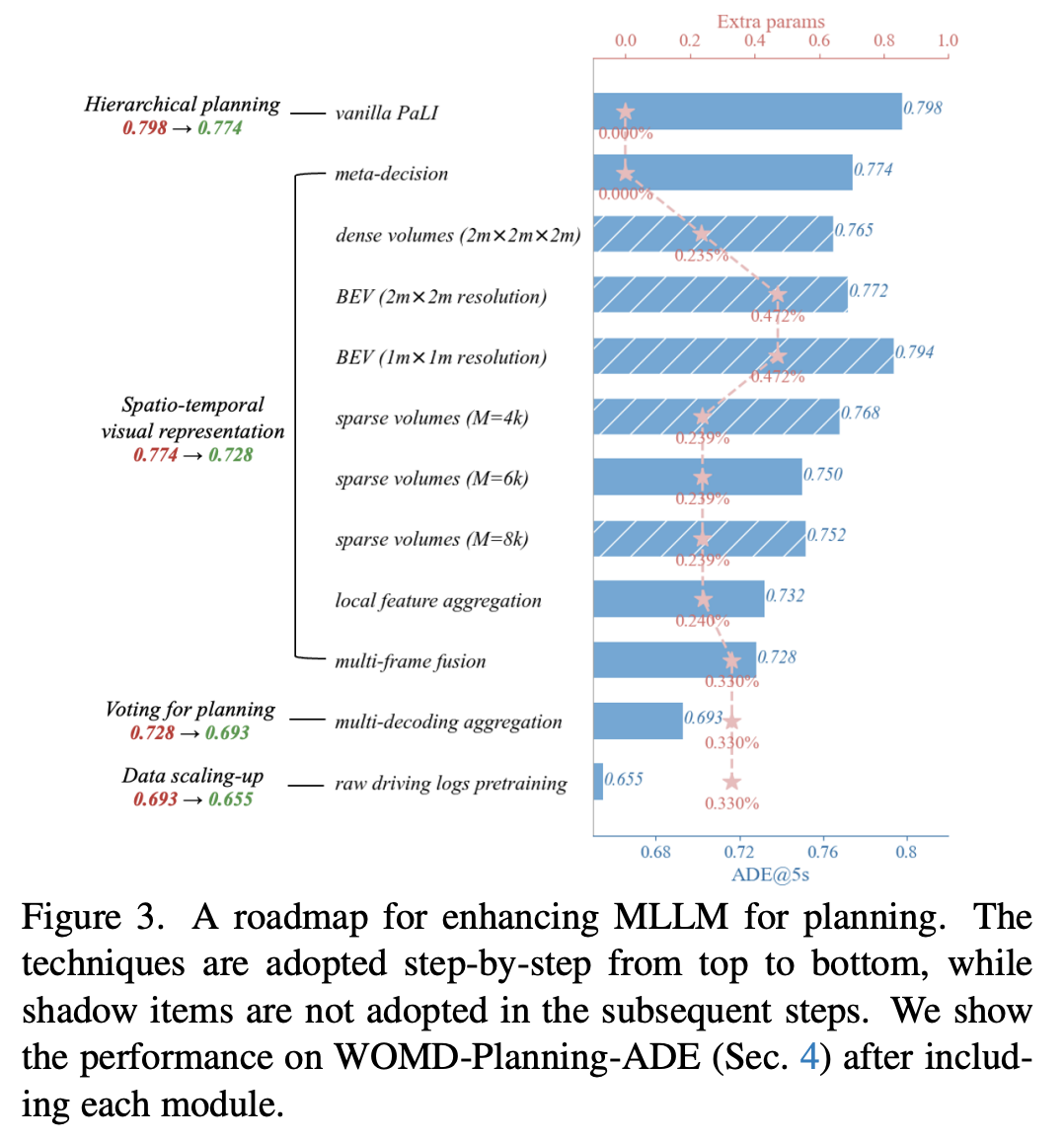
其中 就是规划模型。作者将自身车辆的历史状态和高级指令作为文本提示提供给模型。位置、速度和加速度直接以两位小数的浮点数表示。预测的未来轨迹随后从模型解码的文本输出中提取。在没有前面的感知和预测任务的情况下,以自监督方式微调的原始 PaLI 在运动规划中的表现还可以,但并不理想(见图 3)。
Hierarchical Planning with Meta-Decision
直接输出未来轨迹而不进行任何推理对于 MLLMs 来说,是一个具有挑战的任务。为了解决这个问题,作者借鉴了链式思考(Chain-of-Thought, CoT) 的灵感,采用了一种从粗到细的思路,采用分层规划方法,从语义决策到数值规划。
作者首先给模型提供一个关于未来加速度状态 的估计的prompt,有效地将运动规划任务分解为两个步骤:
作者定义 包括四个元决策:保持静止、保持速度、加速和减速。与以往在基于 VLM 的规划中需要人类标注进行训练的 CoT 应用不同(例如 DriveVLM 中的场景分析),作者将这些元决策作为“free lunch”引入其中,以简化运动规划过程,而无需任何额外的标注。基于未来自身车辆速度和加速度的启发式规则生成真实决策。图 3 展示了这种简单的设计在规划性能上带来了的较大改进。
Scene Representation in 3D Space
高质量的运动规划需要对周围 3D 场景有一个稳健的理解,包括静态和动态元素。虽然传统上是通过单独的感知和预测模块来实现的,但作者的自监督端到端框架依赖于 MLLM 来隐式地学习这种理解,而无需明确的监督。然而,尽管具有强大的 2D 推理能力,MLLMs 在 3D 空间推理方面存在困难。
3D Visual Representation with Dense Volumes
为了克服上述限制,作者借鉴了以往成功的感知任务的经验,采用3D体积表示。MLLM的视觉编码器提取多视图特征图 ,其中 是视图的数量。作者基于多视图图像特征构建一个以自身车辆为中心的3D特征体积 。为了避免引入的模块过于复杂,破坏预训练MLLM并使后续多模态编码器 - 解码器与视觉特征错位,作者采用了一种轻量级的投影方法,类似于SimpleBEV,对于3D体积中的每个体素,作者将它的 坐标投影到每个视角视图 ,得到对应的2D坐标 。然后作者在这些投影位置从每个视图中双线性采样局部特征。最后,体素的特征表示计算为所有视图中局部语义特征的平均值,其中体素投影在图像范围内。这个过程有效地整合了3D空间信息,同时保持了与后续多模态编码器 - 解码器的兼容性。
这种简单高效的投影策略确保了3D体积特征 与原始多视图特征 具有相似的分布。这种相似性有助于无缝整合到MLLM的后续多模态编码器 - 解码器中。如图3所示,这种3D体积表示在运动规划性能上有所提升。另外,作者发现使用全连接层减少 轴以获得鸟瞰图表示会略微降低性能,因为这种降维操作可能会给场景表示带来一些歧义。
Sparse Volume Representation
尽管3D体积表示有效地捕捉了空间信息,但周围的3D空间大部分是空的。另外,对于运动规划来说,远离道路的物体(如建筑物和树木)的详细信息并不那么重要。基于此,作者提出了一种稀疏体积表示,以减少体素的数量,在给定的内存限制下实现更高的分辨率,并提高效率。为了确定每个场景中有用的体积及其位置和语义,作者为每个体积坐标 定义了一个门控值 。为了获得这个门控值,作者从多视图图像特征 开始,通过一个全连接(FC)层降低其维度:
然后作者从 构建一个降低维度的体积特征 。较小的通道数允许更大的体积分辨率,并且足以表明体积是否与运动规划相关。之后,通过一个小型的MLP模块从 中得出门控值:
因此,作者可以轻松地选择 个体积( ),使其门控值最大,坐标为 。由于作者无法获得真实占据状态,作者提出隐式地学习门控值。作者假设门控值较小的区域应该是空的或与规划无关。对于这些空白空间,作者分配一个可学习的特征 。作者期望模型可以通过在每个3D位置权衡语义特征和这个空白特征来学习门控值,因此作者为选定的稀疏体积获取特征:
其中 是具有较大门控值的选定体积。当稀疏体积特征 被输入到后续的多模态编码器中时,它们显著提升了规划性能(见图3)。
Local Feature Aggregation in 3D Space
由于缺乏深度信息,上述过程会导致沿每个相机光线的重复体积特征。这种空间歧义可以通过3D局部操作(如卷积或可变形注意力)来缓解,所以,作者通过定制自注意力来注入一些相对位置偏差,如下所示:
给定 个稀疏体积,其坐标为 ,距离矩阵 是每对稀疏体积沿 轴的距离,即 。偏差通过函数 计算,其中 被划分为多个bins,并通过 、 、 映射到每个bin的可学习偏差值。作者还对具有1维位置 的文本标记之间应用了单独的偏差。这种相对位置偏差优雅地将局部归纳偏差插入到预训练的全局自注意力模块中,几乎不需要额外成本。这可以促进3D空间中局部信息的聚合,增强了场景理解和空间推理能力,性能提升的收益可见图3。
Multi-frame Temporal Fusion
多帧输入组合有助于补偿相机图像中缺乏深度信息的问题。作者将稀疏体积表示扩展到聚合多帧时间信息,通过纳入T帧历史图像,时间间隔为0.5秒。给定总共T+1帧的图像,分别对每帧应用上述公式来获得多视图图像特征 ,其中 , 。在进行自身运动补偿后,作者基于当前自身车辆坐标和每帧图像特征构建门控特征体积 。将多帧体积特征沿通道维度拼接以生成门控值。
作者根据门控值选择M个体积。分别从每帧图像特征图中获取体积特征 , ,然后通过全连接层将它们融合为具有时间感知能力的稀疏体积特征。
如图3所示,时间融合通过促进对环境的理解,有助于提升运动规划性能。
Voting for Planning via Multi-Decoding
MLLMs倾向于为运动规划中的比较简单的行为分配高置信度,比如直接保持静止。为了缓解这种偏差,作者聚合多个输出,并通过投票获得最终的规划输出。作者采用核采样(nucleus sampling)来为自身车辆生成K条未来轨迹,记为 。它们通过简单平均来产生唯一的规划结果,如下所示:
这种无权重平均方法减轻了MLLM对简单行为的偏好。如图3所示,这种简单的多解码聚合方法也带来了显著的性能提升。
Scaling to Large-scale Raw Driving Logs
自监督训练使得作者提出的S4-Driver能够扩展到大规模驾驶logs,无需人工标注。为了发挥基于MLLM的规划器的潜力,作者在内部数据集上对模型进行预训练。图3中的结果表明,由于大规模预训练,S4-Driver在具有挑战性的尾部行为上取得了显著的性能提升。
Waymo Open Motion Dataset for Planning
为了大规模训练和评估具有大型模型的规划算法,作者基于WOMD数据集设计了一个WOMD-Planning-ADE基准。

该数据集包含10.3万个真实世界的驾驶场景,涵盖了多样化城市和郊区场景。这些场景进一步被划分为9秒样本,包含1秒历史和8秒未来。为了端到端规划评估,除了每个样本中自身车辆的轨迹作为真值外,该数据集中还有以下关键项目:
相机数据:大多数端到端规划方法依赖于相机图像作为模型输入。在作者的数据集中,每个帧包含由八个多视图相机捕获的图像。
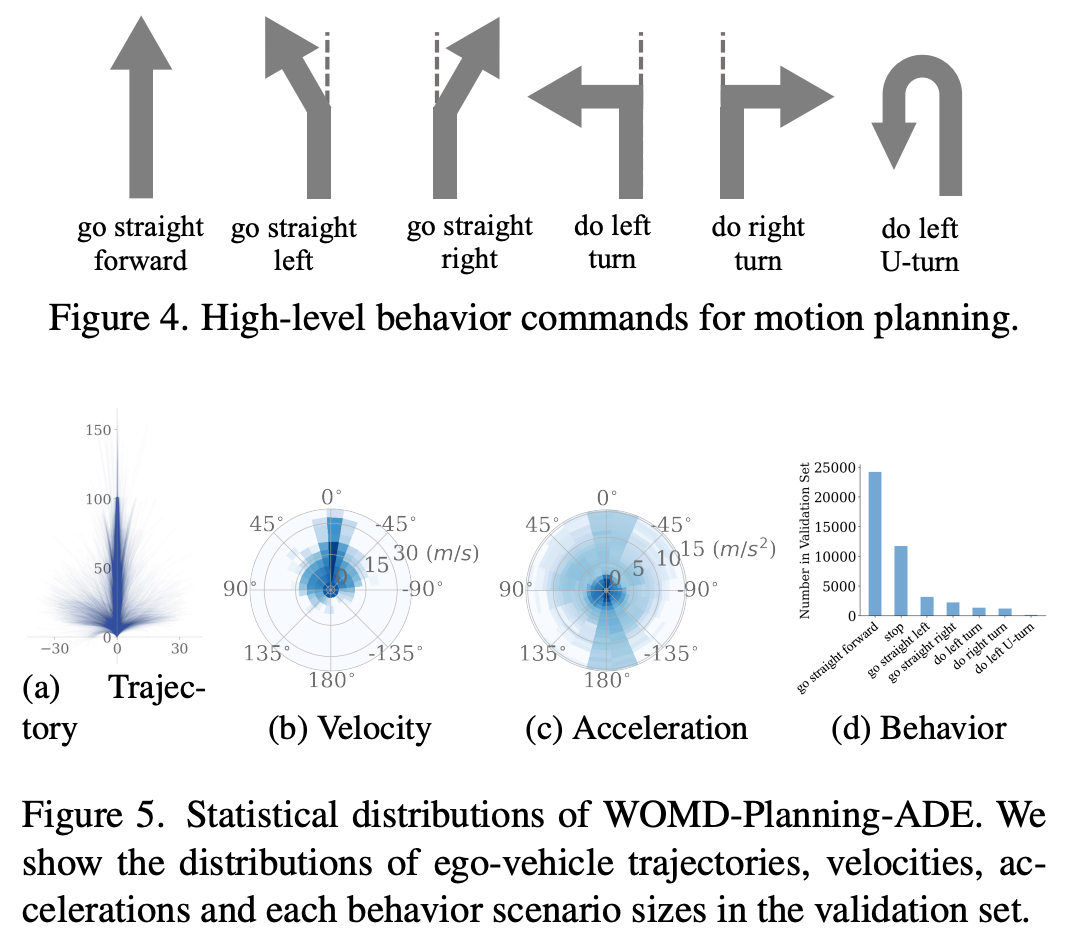
高级行为指令:像导航系统一样,端到端规划系统也需要导航信号来指示行驶方向。作者考虑了六个高级行为指令(见图4),即直行、左转、右转、左转调头等。这些指令可以覆盖现实世界中的多样化驾驶情况,例如“直行右转”描述了驶离高速公路的情况。作者根据长期未来轨迹来决定行为指令,而不是仅仅考虑最后一步的位置,这样可以处理低速或停车的情况。
评估指标:驾驶场景中数据分布的不平衡是不可避免的。例如,在WOMD-Planning-ADE基准测试中,直行和停车占所有样本的70%以上,如图5所示。在这种情况下,作者认为当前广泛使用的样本平均位移误差和碰撞率无法全面反映运动规划算法的性能,因为具有挑战性但频率较低的行为(如转弯)被简单的直行移动场景所淹没。因此,作者提出了类似预测中的mAP指标的行为指标。例如,作者将行为平均位移误差表示为bADE,定义如下:
其中 是特定行为的ADE指标。具体来说, 种行为被考虑在内——包括六个高级指令(见图4)和一个额外的停车行为。
实验及结论
实验细节
模型和微调:作者的模型基于预训练的 PaLI3-5B 模型构建,该模型包括一个 ViT-G(2B)视觉编码器和一个 3B 的多模态编码器 - 解码器。作者冻结了 ViT 编码器,仅对插入的模块和多模态编码器 - 解码器进行微调。
数据集:作者在 nuScenes 和 上述 WOMD-Planning-ADE 基准测试上评估 S4-Driver。
主要结果及对比
nuScenes 数据集:表 2 显示,S4-Driver 显著优于所有先前的算法。与现有方法不同,S4-Driver 不需要任何感知预训练或人类标注。这种自监督特性使得 S4-Driver 能够利用所有可获取的原始轨迹数据。
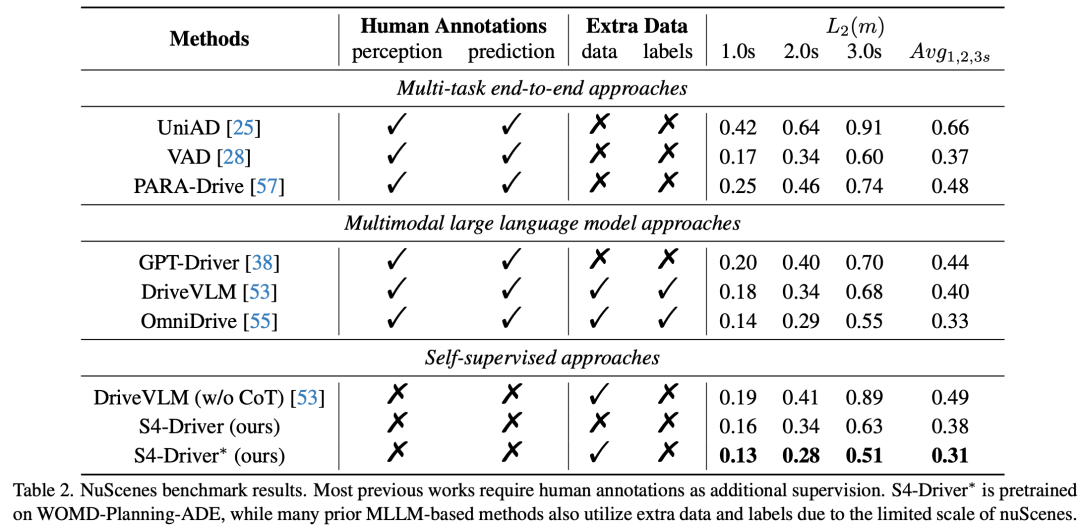
WOMD-Planning-ADE 基准测试:在表 3 中,作者主要将 S4-Driver 与原始 PaLI3-5B 基线和模块化算法 MotionLM 进行了比较。与原始 PaLI3-5B 相比,样本指标和行为指标之间存在显著差距。为了对比,作者还将最新运动预测算法 MotionLM(内部增强的复现版本)适应于规划任务,仅预测自身车辆的未来轨迹,并将高级指令注入模型中。因为它使用了高质量的对象、轨迹和道路图信号作为模型输入,所以直接与作者的端到端方法进行比较并不公平。然而,如表 3 所示,即使 S4-Driver 仅使用原始相机图像作为输入,与 MotionLM 相比,S4-Driver 仍然取得了有利的性能,尤其是在行为指标方面。
一些分析
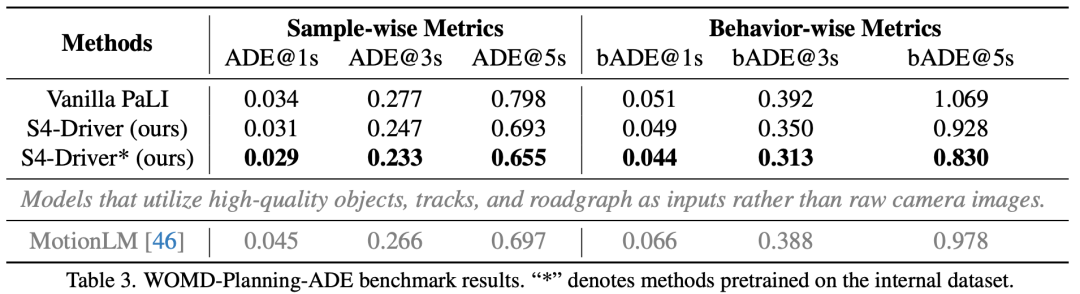
定性结果:图 6 可视化了在多样化场景中的规划结果。作者提出的 S4-Driver 能够根据交通灯和道路车道确定未来自身行为,可以应对不同的光照条件。

元决策可靠性:图 7 展示了在 WOMDPlanning-ADE 验证集上元决策预测的准确性。在所有行为中,模型提供了可靠的元决策估计。在没有任何人类标注的情况下,这一初步预测可以简化数值运动规划的推导。
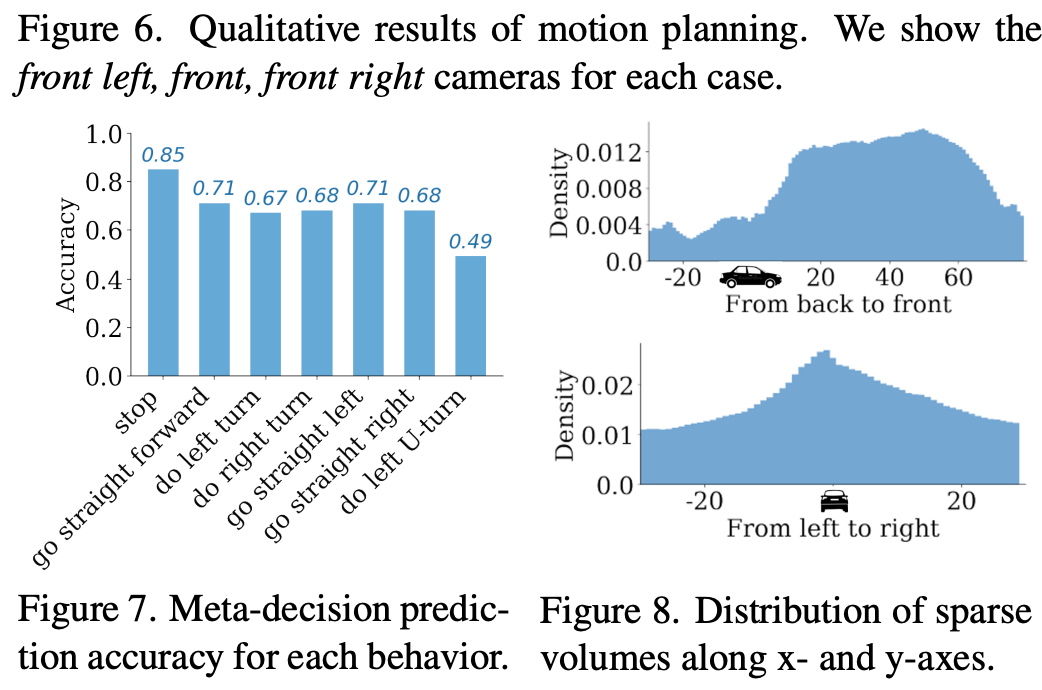
稀疏体积分布:作者在图 8 中可视化了沿 x 轴和 y 轴的自监督学习稀疏体积的分布。从后到前,稀疏体积集中在前面区域。从左到右,稀疏体积覆盖了所有区域,因为存在转弯场景,但大多数体积集中在中间区域。这些分布与人类驾驶经验一致。
消融实验
MLLM 输入:在表 5 中,作者分别对比分析了相机图像和历史自身状态的作用。作者假设 WOMD-Planning-ADE 涵盖了更多多样化的驾驶场景,包括许多比较大的速度和方向变化,这使得传感器数据变得重要。这也展示了 WOMDPlanning-ADE 在全面评估方面的优势。表 5 还显示,如果没有 MLLM 预训练,随机初始化的模型无法收敛。说明:尽管领域不同,S4Driver 仍可从大规模 MLLM 在一般任务上的预训练中受益。
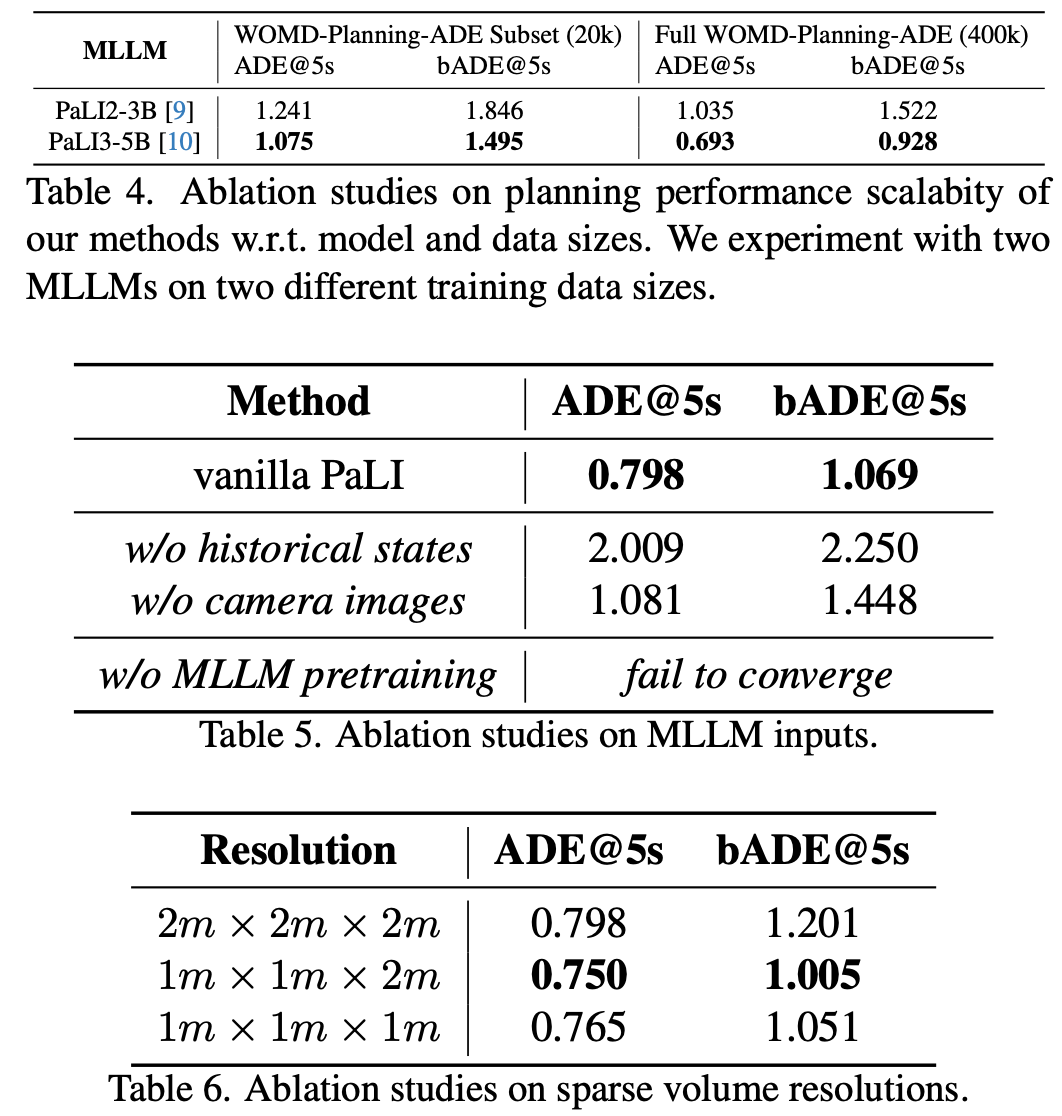
MLLM 能力:除了在其他部分中使用的 PaLI3-5B 外,作者还针对运动规划使用了 PaLI2-3B。如表 4 所示,基于 PaLI2-3B 的 S4Driver 表现明显不如基于 PaLI3-5B 的 S4Driver。作者在 WOMD-Planning-ADE 上进行了两个不同规模的训练数据实验,即 20k(nuScenes 规模)对比 400k(完整 WOMD-Planning-ADE)。在有足够的训练数据时,差距尤为明显。这也证明了在大规模数据集上进行实验的必要性,这可以充分发挥强大 MLLMs 的潜力。
稀疏体积分辨率:表 6 显示了具有相同数量的稀疏体积(M = 6000)的不同稀疏体积分辨率的结果。与图 3 一致,低分辨率导致相对较差的性能,因为它限制了 3D 空间推理的精度。有趣的是,沿 z 轴的更高分辨率并不一定能提高模型性能,因为运动规划主要在 xy 平面上工作,而太低的稀疏比率往往会使优化不稳定。
结论和展望
本文介绍了 S4-Driver,这是一个利用多模态大语言模型(MLLMs)用于自动驾驶的可扩展自监督运动规划框架。为了增强 MLLMs 中的 3D 推理能力,作者提出了一种新颖的稀疏体积表示,通过聚合多视图和多帧图像输入,实现了有帮助的时空推理。此外,作者还为大规模 WOMD-Planning-ADE 基准设计了行为指标,用于做全面评估。S4-Driver 不需要任何人为标注的情况下,在 nuScenes 和 WOMD-Planning-ADE 基准测试中均取得了最先进的性能。这证明了自监督学习在端到端自动驾驶中的潜力。
未来的工作将持续探索应用其他强大的 MLLM 架构。将作者的大规模自监督学习方法与针对小规模标记数据的监督微调相结合,可能会进一步提升系统的性能和可解释性。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









