



点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
>>点击进入→3D视觉之心技术交流群
单目实现动态重建
动态三维场景重建旨在从视频数据中恢复动态场景的几何、外观和运动信息。所重建的动态三维模型可以在任意时间点进行自由视角渲染,使其在虚拟现实、视频制作等方面具有实际应用价值,甚至为个人提供了一种创新方式,用于捕捉和重温他们的美好回忆。
随着三维高斯喷溅(3DGS)研究的兴起,一些方法尝试通过联合学习高斯及其变形,从多视角视频中重建动态三维场景。然而,由于信息受限,尤其是缺乏多视角一致性约束,从单目视频中进行重建仍然具有较大的挑战性。
近期的研究集中于为高斯设计更优的变形模型,以更好地整合跨帧的时间信息,从而克服单目视频中信息不足的问题。例如,Shape of Motion(SoM)提出了一组全局运动基底,为每个高斯分配决定其运动的系数,基于运动通常是平滑且简单的这一认识,换句话说是低秩的。由于整个场景只共享少量的全局运动基底,因此难以捕捉到细致的运动变化。
另一个代表性方法 MoSca 使用数百个三维节点建模运动,每个高斯从周围节点中插值得到其变形。这种大量的运动节点带来了极高的自由度,使得优化容易对训练视角产生过拟合。其他方法也面临类似的问题:要么难以捕捉精细细节,要么由于过拟合导致在空间和时间维度上无法实现平滑的高质量重建。

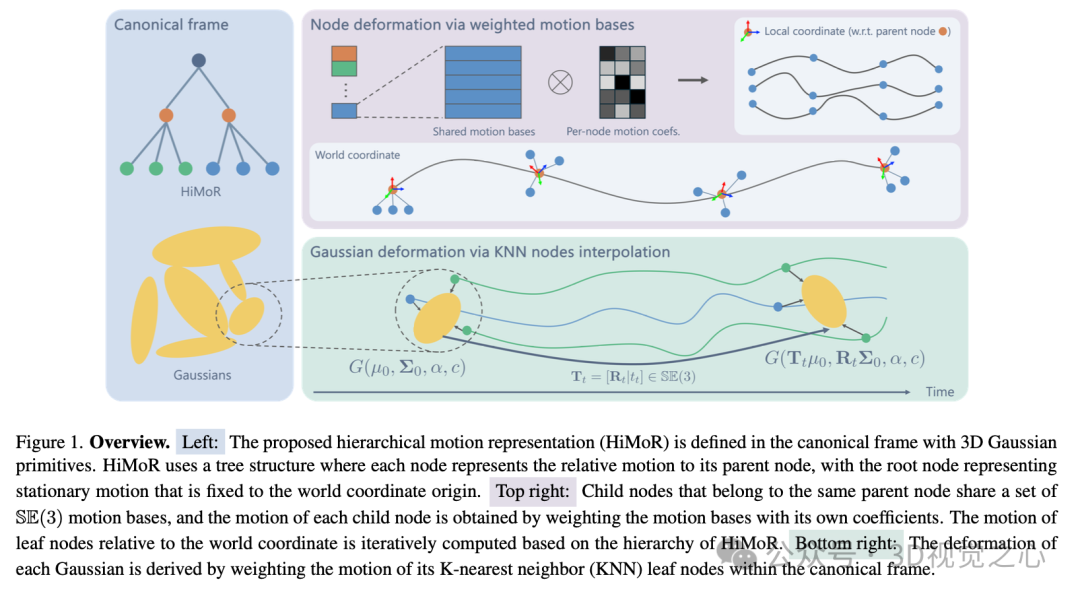
为了解决上述问题,本文介绍一种新颖的分层运动表示方法[1],能够在粗略与精细两个层面上同时建模运动。这种方法可以实现对动态三维场景的高质量单目重建,同时保持时空一致性并呈现细节。
具体来说,我们的分层运动表示采用树状结构实现,每个节点表示其相对于父节点的相对运动。在假设根节点固定在世界坐标原点的前提下,可以通过树状结构的层级关系迭代地推导出每个节点相对于世界坐标的全局运动。该设计允许不同层级的节点表达不同层次的运动细节,从而实现粗略与精细运动的有效分解。
核心思想是:在日常生活场景中,精细的运动通常与粗略的运动相关联。例如,手指的运动可以分解为手指相对于手腕的精细运动,再加上手臂的粗略运动。这种分解的优势在于,它不仅能简化复杂运动的学习过程,还能够提供更合理的运动表示:粗略运动有效捕捉时空平滑性,而精细运动则增强了细节的表达能力。
此外,从评估的角度来看,我们发现,由于单目动态场景重建任务本身高度不适定,常用的像素级指标(例如 PSNR)容易受到诸如深度模糊或摄像机参数估计不准确等因素的影响,因此在像素错位时难以准确反映重建质量。因此,我们提出采用感知指标来评估渲染质量。定量结果也表明,这种感知指标与人类主观感知更加一致。
我们在多个标准基准数据集上对所提出的方法进行了评估,结果在定性和定量上均优于现有方法。尤其值得注意的是,我们的方法在运动的时空平滑性以及细节还原方面实现了显著提升。
主要贡献:
提出了一种新颖的分层运动表示方法,将复杂的运动分解为平滑的粗略运动和细致的精细运动,为高斯提供了更具结构性的变形方式,从而提升了对动态三维场景的表达能力。
指出现有像素级指标在评估单目动态场景渲染质量方面存在的局限性,并提出采用更合适的感知指标进行评估。
在定性和定量评估中均达到了当前最先进的效果。
项目链接:https://pfnet-research.github.io/himor/
具体方法
给定一个具有已校准相机参数的单目视频,该视频表示一个动态场景,我们的目标是重建一个动态的三维高斯表示,其中包括规范帧中的高斯和用于对其进行变形的运动序列。
预备知识:三维高斯喷溅
三维高斯喷溅使用一组各向异性的三维高斯基元来表示静态场景,从而实现实时的真实感渲染。每个三维高斯基元 的参数包括:
均值
协方差矩阵
不透明度
通过球谐系数 所决定的视角相关颜色,其中 是球谐系数的阶数
从参数为 的相机进行渲染时,每个三维高斯首先被投影为图像平面上的二维高斯,其均值和协方差分别为:
然后,二维高斯按照深度排序,并通过高效的可微光栅化器使用 alpha 混合进行渲染,计算如下:
其中,
为像素位置, 为与该像素射线相交的高斯数量。
为了将三维高斯扩展至动态场景,可对高斯施加变形,将其从静态的规范帧变换至目标帧。设从规范帧到时间 的变换为 ,则变形后的高斯为:
其中 与 在时间上保持不变。
分层运动表示
我们方法的核心在于提出一种分层运动表示,用于对三维高斯进行变形,以实现动态三维场景重建。具体而言,分层运动表示是一个树状图结构,每个节点表示相对于其父节点的 运动序列。高斯的变形通过其在规范帧中附近叶子节点的运动加权计算得出。
表达形式
我们首先介绍分层运动表示的表达形式。树中的每个节点都表示一个随时间变化的 变换序列:
其中 表示该节点从规范帧到时间 的变换。虽然可以直接为每个节点分配一个独立的运动序列,但我们考虑到运动的低秩特性,提出使用共享的运动基底来建模节点的运动。
一个运动基底表示为一组随时间变化的 变换序列:
我们的目标是将目标运动序列表示为若干运动基底的加权和。设某父节点有 个子节点,使用 个运动基底 ,每个子节点有权重系数 ,则该子节点的运动为:
这种表达是递归定义的,其中根节点的运动固定为单位矩阵。作为父节点时,节点拥有一组运动基底;作为子节点时,节点拥有相应的加权系数。树结构中,根节点只作为父节点,叶子节点只作为子节点,中间节点既作为父节点也作为子节点。
由于该结构具有层级性,每个节点的运动表示其相对于父节点的相对运动,而非绝对运动。这种建模方式允许将运动分解为浅层节点表示的粗略部分和深层节点表示的精细部分,保留细节表达能力的同时简化了复杂运动的学习。每个节点相对于世界坐标的全局运动可以通过层层组合其上级节点的 变换获得。
我们提出分层结构的动机有两方面:一是日常生活中的运动通常可以分解为粗略、细致甚至更细致的部分,因此我们采用层次树结构以实现从粗到细的建模;二是运动具有低秩性质,且邻近区域的运动通常相似,因此我们仅使用有限的运动基底和节点进行建模。
高斯的变形
根据上述分层运动结构,我们可以计算所有节点的运动序列。对于非叶子节点(有子节点的节点),其运动表示为下一层更精细节点提供粗略的运动基础;而叶子节点则拥有最精细的运动,我们用它们来指导高斯的变形。
设高斯 的变形为 ,其由附近的叶子节点集合 中的 个最近邻节点的运动加权插值得出:
其中, 表示高斯 在规范帧中最接近的 个叶子节点的索引, 是权重,通过以下高斯函数计算:
其中 和 分别是第 个节点在规范帧中的位置和影响半径, 是归一化因子。我们使用双四元数进行插值以获得更好的插值效果。
与对每个高斯单独建模变形的方法不同,从运动节点插值得到的变形场在空间上更加平滑。同时,运动节点可以从更大范围内的高斯接收梯度,从而使变形优化更加稳定。
初始化
由于单目动态三维重建问题本身具有高度的不适定性,我们参考以往工作,使用预训练模型(如二维跟踪、深度估计)来初始化运动表示。
在优化初期,分层结构仅包含一层节点(即图中的橙色节点,其父节点为根节点)。随着优化进行,节点层级逐步扩展。
初始化阶段需确定第一层节点共享的运动基底及每个节点的系数。我们首先通过相对深度图对前景的二维轨迹进行反投影,获得三维轨迹。然后使用 K-Means 聚类得到 个聚类中心,从而定义 条三维轨迹。由于这些轨迹仅包含平移分量,我们通过时间序列上的 Procrustes 配准求解其旋转部分,获得 个完整的 序列作为运动基底。我们选择三维轨迹可见点最多的帧作为规范帧,从该帧中采样节点位置,并使用基于距离的反比加权方式初始化每个节点的运动基底系数。
更精细层级的节点在优化过程中迭代添加。操作过程与第一层节点初始化类似:对每个叶子节点,先选取一定范围内的高斯,并计算其相对于该节点的相对运动。再对这些相对运动使用 K-Means 聚类,聚类中心作为子节点共享的运动基底。子节点从这些高斯中下采样得到,并根据其位置与运动基底中心的距离初始化系数。与第一层节点不同的是,此处使用的是已配向的高斯,因此不再需要求解 Procrustes 问题。
节点加密
由于初始节点仅由规范帧中可见区域的三维轨迹构建,难以有效建模规范帧中不可见区域的运动。因此,我们采用逐步节点加密策略来覆盖整个场景中的运动。
类似于三维高斯密度增强的策略,可依据光度损失梯度添加新高斯。以往工作也采用了类似的基于梯度的节点添加策略。但我们发现,仅依赖该策略可能不足。例如,对于颜色较为均匀但初始节点稀疏的区域,仍可能无法生成新节点,导致运动无法被充分建模。
因此我们提出更直观的策略:对于每个高斯,若其附近的节点密度不足以提供有效的运动插值,则在其周围添加新节点。我们通过计算高斯与其 个最近邻节点之间的轨迹曲线距离来衡量节点密度:
其中 表示两个点随时间变化的轨迹, 为欧氏范数。对于曲线距离超过设定阈值的高斯,我们在其附近添加新节点。
我们在优化初期周期性地应用该策略,在若干步之后,再结合以往方法中提出的基于梯度的策略进一步添加或剪枝节点。
损失函数设计
刚性损失
刚性损失通过限制相邻区域中的位移、速度等变化,来对变形进行约束,从而实现局部刚性运动,并更好地保持几何结构。已有工作采用了类似的刚性损失来约束运动。
然而,这些方法常面临两难局面:约束过弱可能不起作用,导致运动发散;而约束过强则可能抑制对精细运动的表达。
得益于我们分层结构的设计,我们可以根据节点所在的层级,施加不同强度的约束。具体来说,对浅层节点施加更强的刚性约束,以强化其平滑、粗略的运动;对深层节点则施加更弱的约束,从而使其能灵活地捕捉精细运动。分层结构与层级约束强度的结合,使得我们能够以从粗到细的方式分解运动。
总体损失
为了缓解单目视频重建问题的病态性,我们在优化过程中引入了预训练模型的知识,并通过多项损失函数来约束学习过程。总损失包括以下项:
渲染损失
前景掩膜损失
深度损失
跟踪损失
刚性损失
其中,掩膜损失 使用预训练的分割模型生成的前景掩膜作为监督;深度损失 使用由单目深度估计模型预测的相对深度图作为监督,并与 Lidar 深度或 COLMAP 深度对齐。为了更好地恢复运动,我们引入了跟踪损失 ,该损失度量渲染出的点与预训练二维跟踪模型预测的点之间的误差。
将这些损失结合后,最终总损失函数表达如下:
其中各项的权重为经验设定。我们对规范帧中的高斯和分层运动表示(HiMoR)进行联合优化以最小化上述总损失。
实验效果
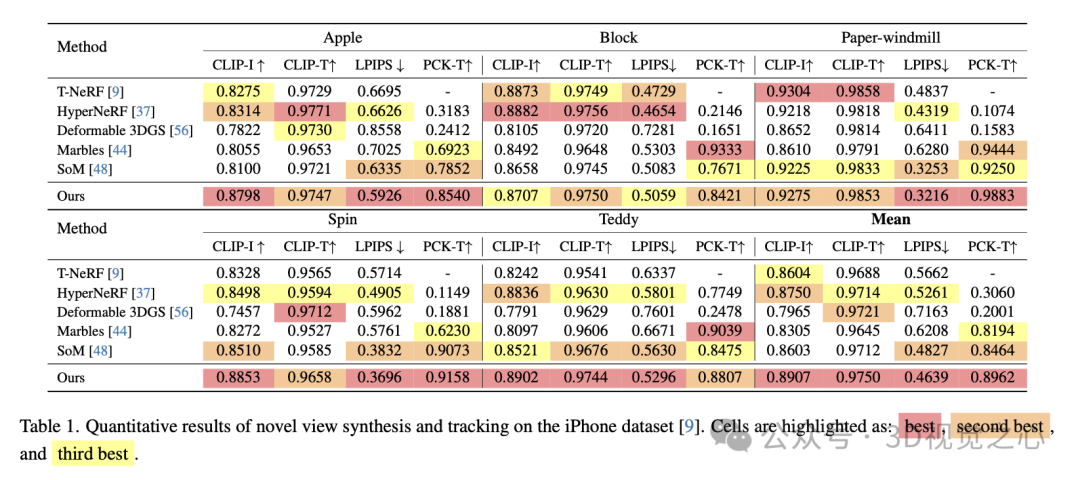
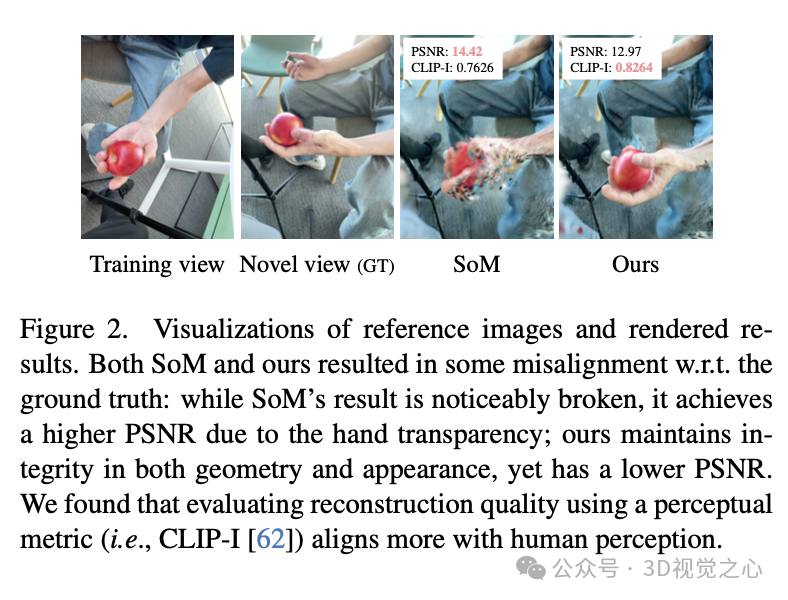
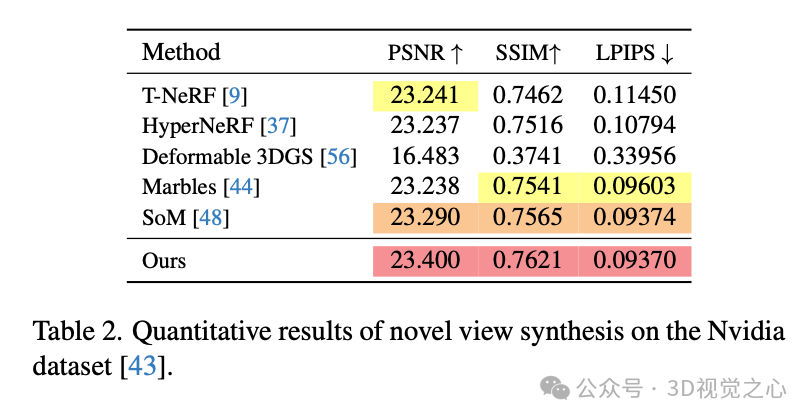

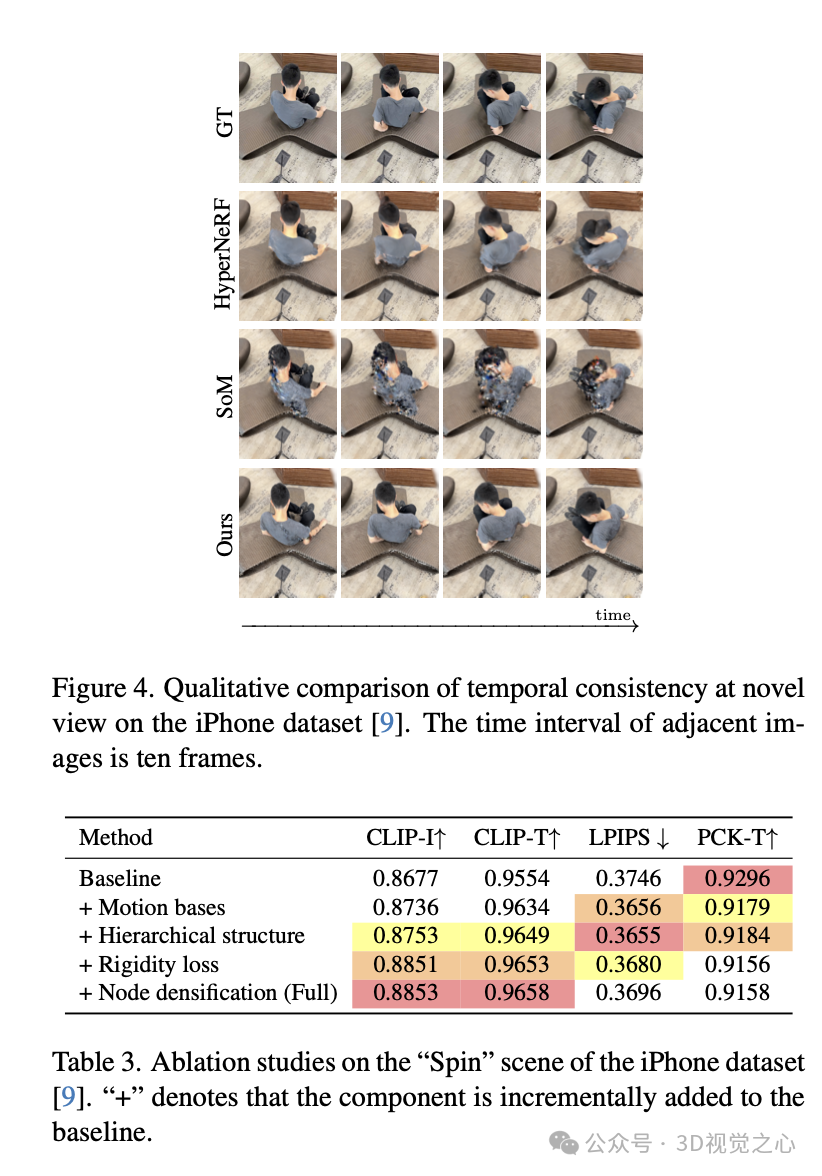

总结一下
HiMoR是一种结合3D高斯表示的全新分层运动表示方法,显著提升了单目动态三维重建的质量。HiMoR 利用树状结构,以由粗到细的方式表示运动,为高斯提供了更具结构性的变形方式。我们还指出了像素级指标在评估单目动态三维重建时的局限性,并提出使用更可靠的感知指标作为替代。
局限性:对于在规范帧中不存在的部分(例如新出现的物体或新暴露的场景区域),难以进行准确的建模。
未来方向:可以考虑为新出现的物体提供单独的分支,或设计一个自适应的规范空间。
参考
[1] HiMoR: Monocular Deformable Gaussian Reconstruction with Hierarchical Motion Representation
本文仅做学术分享,论文汇总于『3D视觉之心知识星球』,欢迎加入交流!
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【3D视觉之心】知识星球
3D视觉之心知识星球主打3D感知全技术栈学习,星球内部形成了视觉/激光/多传感器融合SLAM、传感器标定、点云处理与重建、视觉三维重建、NeRF与Gaussian Splatting、结构光、工业视觉、高精地图等近15个全栈学习路线,每天分享干货、代码与论文,星球内嘉宾日常答疑解惑,交流工作与职场问题。


















 3372
3372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









