



点击下方卡片,关注“自动驾驶之心”公众号
自动驾驶的第一性原理—数据驱动
随着近两年自动驾驶技术的不断发展,对高质量数据的要求也越来越高。近期理想汽车AD Max V13 1000万Clips模型正式全量推送。智驾能力的背后是千万级训练数据赋予的强大动力,而这动力的源头就是数据闭环源源不断的自动化4D标注数据产出。而随着端到端自动驾驶、视觉-语言-动作模型VLA的全面铺开,训练所需要的数据形式也越来越复杂。
和以往各感知任务单独标注不同,动静态障碍物、OCC的独立标注已经无法满足当下量产数据的要求。端到端数据需要时间同步后的传感器统一标注动静态元素、OCC和轨迹等等,这样才能保证训练数据的完整性。面对越来越复杂的标注需求和训练数据需求,自动化4D自动标注的重要性日益凸显。

而自动标注的核心则在于高性能的自动标注算法,面对不同城市、道路、天气和交通状况的智驾场景,如何做好不同传感器的标定和同步?如何处理跨传感器遮挡问题?算法如何保持泛化性?如何筛选高质量的自动化标注结果?又如何做好自动化质检?全都是当下业内自动标注实际面临的痛点!
自动标注难在哪里?
自动驾驶数据闭环中的4D自动标注(即3D空间+时间维度的动态标注)难点主要体现在以下几个方面:
时空一致性要求极高:需在连续帧中精准追踪动态目标(如车辆、行人)的运动轨迹,确保跨帧标注的连贯性,而复杂场景下的遮挡、形变或交互行为易导致标注断裂;
多模态数据融合复杂:需同步融合激光雷达、相机、雷达等多源传感器的时空数据,解决坐标对齐、语义统一和时延补偿问题;
动态场景泛化难度大:交通参与者的行为不确定性(如突然变道、急刹)及环境干扰(光照变化、恶劣天气)显著增加标注模型的适应性挑战;
标注效率与成本矛盾:高精度4D自动标注依赖人工校验,但海量数据导致标注周期长、成本高,而自动化算法面对复杂场景仍然精度不足;
量产场景泛化要求高:自动驾驶量产算法功能验证可行后,下一步就需要推进场景泛化,不同城市、道路、天气、交通状况的数据如何挖掘,又如何保证标注算法的性能,仍然是当前业内量产的痛点;
这些难点直接制约了数据闭环的迭代效率,成为提升自动驾驶系统泛化能力与安全性的关键瓶颈。很多小白根本不知道怎么入门,没有完整的学习体系,将会处处踩坑,久久不能入门,导致最终放弃学习,错失了机会。为此我们联合行业知名4D自动标注算法专家,出品了平台首门《自动驾驶4D自动标注算法就业小班课》教程。旨在解决大家入门难,优化进阶难的问题!什么有价值我们就教什么!
全栈教程:动静态、OCC、端到端一网打尽
本课程面向想要深入自动驾驶数据闭环领域的学习者,系统讲解自动驾驶4D自动标注全流程及核心算法。结合真实落地算法,配合实战演练,全方面提升算法能力。课程核心内容如下:
全面掌握4D自动标注的整体流程和核心算法;
每章节均配套大量实战,不仅听懂更能实战;
动态障碍物检测&跟踪&问题优化&数据质检;
激光&视觉SLAM重建原理和实战演练;
基于重建图的静态元素标注;
通用障碍物OCC的标注全流程;
端到端标注的主流范式和实战教学;
数据闭环的核心痛点及未来趋势。
课程大纲如下:

第一章 4D自动标注的基础
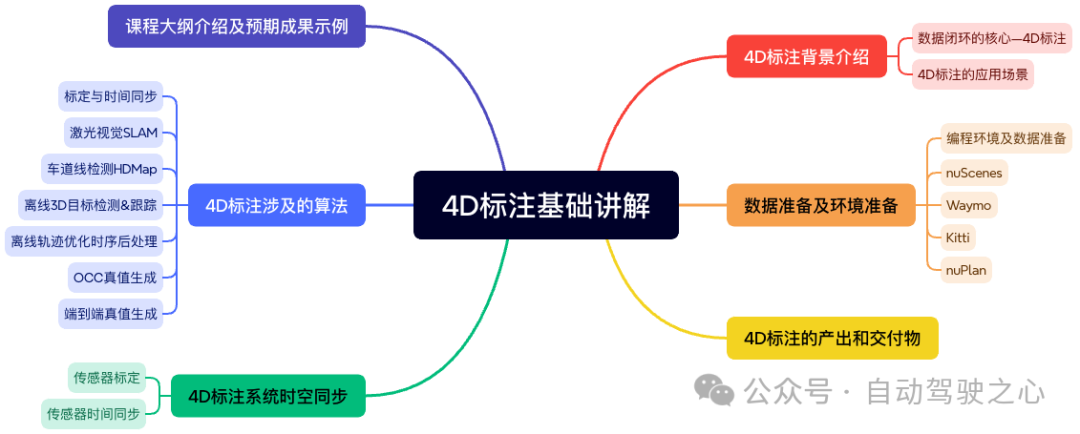
第一章主要介绍4D自动标注的相关基础。作为自动驾驶数据闭环的算法核心,这一章先从整体上帮助同学们了解4D自动标注是做什么的,有哪些应用场景。下一步延伸到课程所需要的数据及相关环境。然后重点介绍4D标出的交付物和涉及的诸多算法,从更高的层级认识4D自动标注。我们为什么需要这些算法,他们的作用究竟是什么。最后则重点介绍系统时空同步,传感器标定怎么做,时间同步如何保证精度。都会在第一章得到答案!
第二章 动态障碍物标注
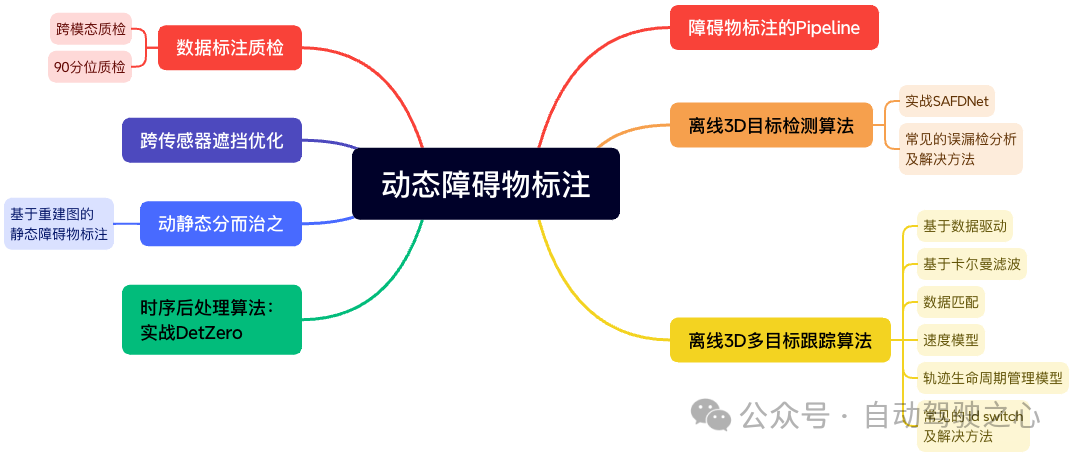
第二章正式进入到动态障碍物标注的相关内容。首先介绍动态障碍物标注的整体流程。然后重点讲解离线3D目标检测算法,常用检测算法的Image/Lidar数据增广怎么做、Backbone/检测头有哪些、BEV/多帧时序融合方案是哪些,老师都会一一介绍!之后实战聚焦在CVPR 2024的SAFDNet算法,让大家实际感受下3D检测算法的输出是什么,以及面对工程上最常见的误漏检问题我们都有哪些解决方法!下一步则展开讲解3D多目标跟踪算法,数据匹配怎么做、速度模型如何实现、轨迹的生命周期如何管理、ID跳变如何解决,全都是问题!全都有答案!!!进一步老师会展开时序后处理算法DetZero的实战讲解,以及实际工程中遇到传感器遮挡时如何优化。最后则是数据质检部分,结果好不好,质检来把关。
第三章 激光&视觉SLAM重建
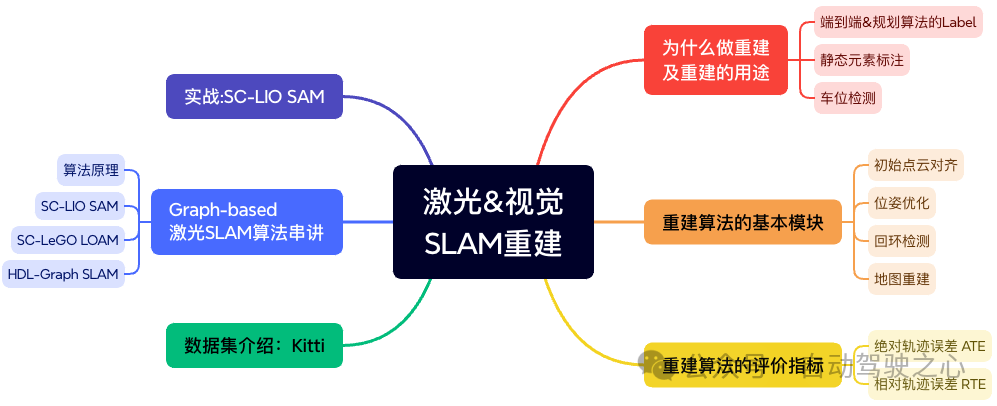
第三章的内容聚焦在激光&视觉SLAM重建。我们首先回答一个问题:为什么要做重建?在4D自动标注中都有哪些用途?先把这个问题搞清楚,咱们在进一步介绍重建算法的基本模块和评价指标。然后讲解Graph-based的常用激光SLAM算法。
第四章 基于重建图的静态元素标注
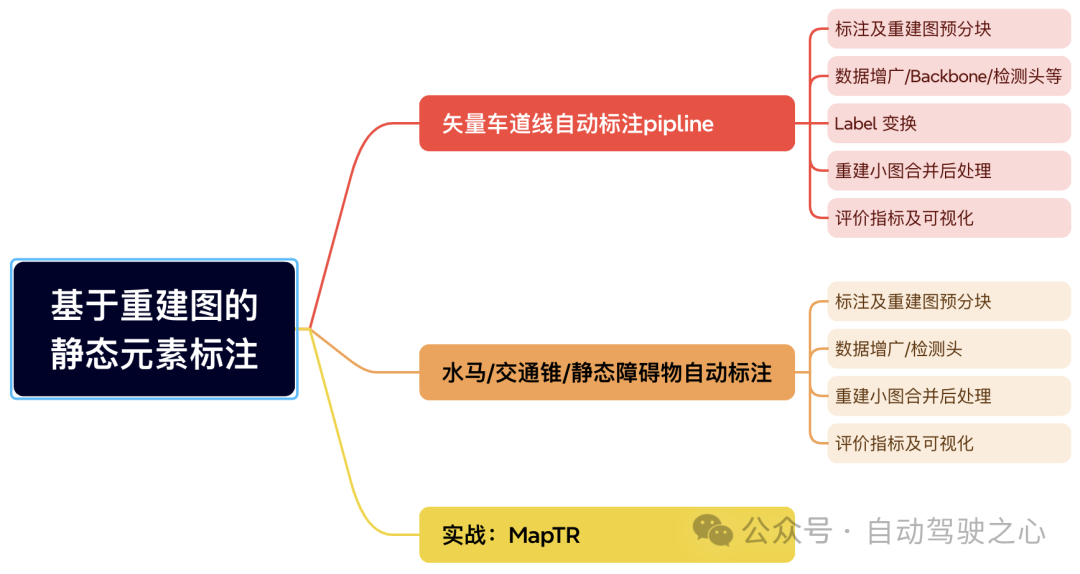
第四章承上启下关注静态元素的自动化标注。静态元素和动态标注不同,动态元素需要单帧检测再通过跟踪把时序的结果串起来。如果静态元素也采用单帧感知,投影得到的整条道路则可能会存在偏差。所以基于第三章SLAM的重建输出,我们就可以得到全局clip的道路信息,进而基于重建图的得到静态元素的自动化标注结果。
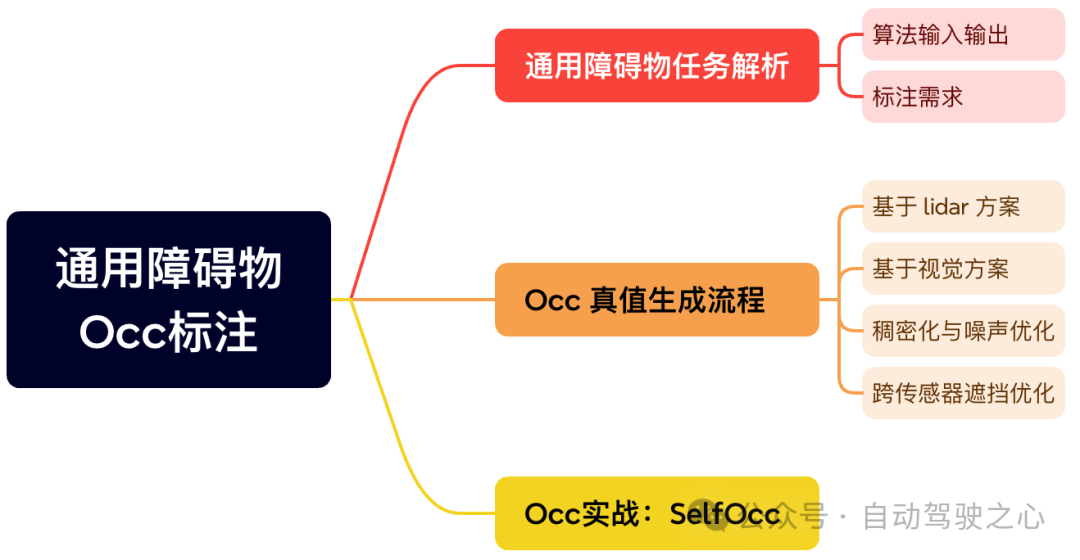
第五章 通用障碍物OCC标注
第五章聚焦在通用障碍物OCC标注上。自从2022年特斯拉宣布Occupancy Network量产以来,OCC基本上成为了自动驾驶感知的标配。所以第五章我们聚焦在通用障碍物OCC标注上。我们首先解析通用障碍物算法的输入输出和标注需求。再进一步讲解OCC真值的生成流程,基于lidar的方案怎么做、基于视觉的方案怎么做、工程上如何稠密化点云和优化噪声、跨传感器遮挡的场景如何优化。都会在这一章得到答案!
第六章 端到端真值标注
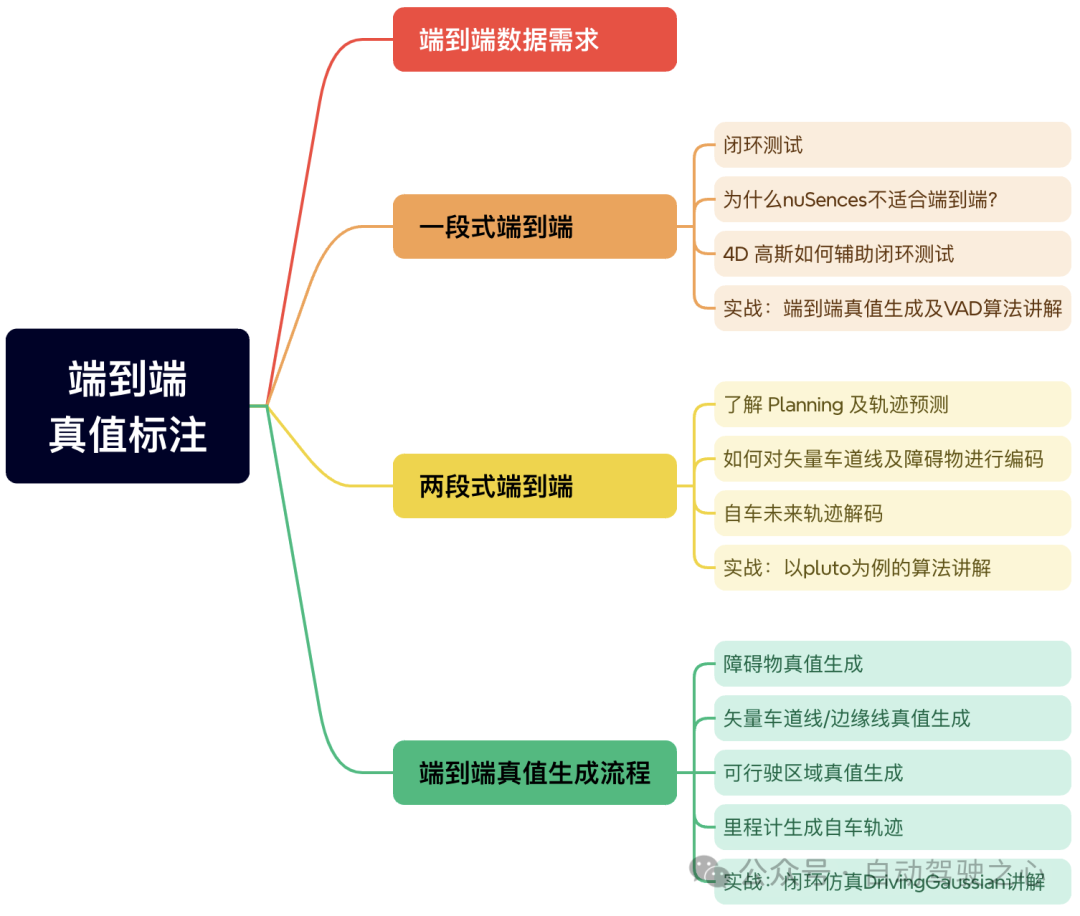
第六章则是咱们课程最重要的章节:端到端真值生成!首先明确下端到端的数据需求,然后进一步展开讲解业内应用最广泛的一段式和两段式端到端如何实现?最后则是把端到端真值生成的流程整体串起来:动态障碍物、静态元素、可行驶区域、自车轨迹全部打通!老师还特别准备了闭环仿真DrivingGaussian算法的讲解,闭环仿真是端到端自动驾驶的刚需,在4D自动标注的基础上,进一步扩展同学们的视野。总结来说第六章三大实战,全面搞定端到端真值生成!
第七章 数据闭环专题
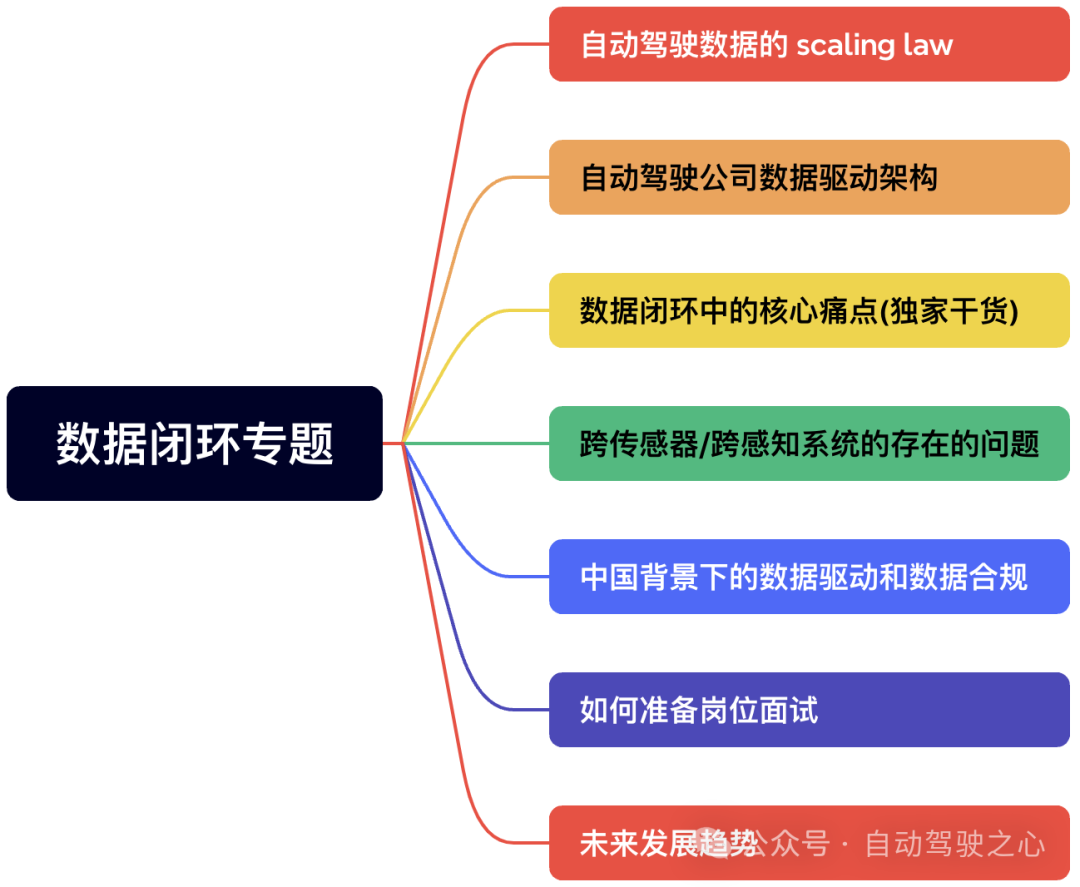
有了前面六个章节的算法基础,第七章我们聚焦在更高层面的经验输出,这一章都是实打实老师工作多年的经验积累。自动驾驶数据的scaling law还奏效么?业内主流公司的数据驱动架构是怎样的?数据闭环当前面临哪些痛点?跨传感器/跨感知系统又存在什么问题?我们又如何准备相关岗位的面试,什么内容是公司真正关注的?在这一章都会有答案!
讲师介绍
Mark老师!c9院校硕士毕业,业内一线大厂数据闭环算法专家。从事自动驾驶感知算法多年,聚焦于多模态3D感知、数据闭环等方向。在4D自动标注算法开发、工程化落地上具有丰富经验。参与过多个量产交付项目,已发表多篇量产专利和专业论文。
课程收获
掌握4D自动标注的落地全流程;
掌握4D自动标注学术界&工业界的前沿算法;
具备4D自动标注算法研发的实际能力;
具备4D自动标注解决实际问题的能力;
提升工作核心竞争力。
授课方式 & 课程计划
开课时间:2025年4月12日(预计3个月完成)
课程模式:
线上直播 + 代码讲解 + 线上答疑
配套资料、源码示例
微信群内答疑
购买后1年有效,可反复观看
退款说明:课程为虚拟商品,购买后不支持退款
课程表如下:
章节 | 第一章 | 第二章 | 第三章 | 第四章 | 第五章 | 第六章 | 第七章 |
|---|---|---|---|---|---|---|---|
授课时间 | 4.12 | 4.26 | 5.10 | 5.24 | 6.7 | 6.28 | 7.5 |
适合人群
高校研究人员与学生;
初创企业技术团队;
企业技术专家、骨干;
想要转行从事数据闭环的同学;
所需基础
一定的深度学习与自动驾驶感知算法基础;
了解Transformer模型结构;
Python和PyTorch基础,具备代码读写的能力;
需要自备GPU,显存不低于12G;
课程咨询
早鸟优惠中,扫码学习课程



















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









