



作者 | CodeGoat24 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/29089560801
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
Title: Unified Reward Model for Multimodal Understanding and Generation
面向多模态生成与理解的统一奖励模型
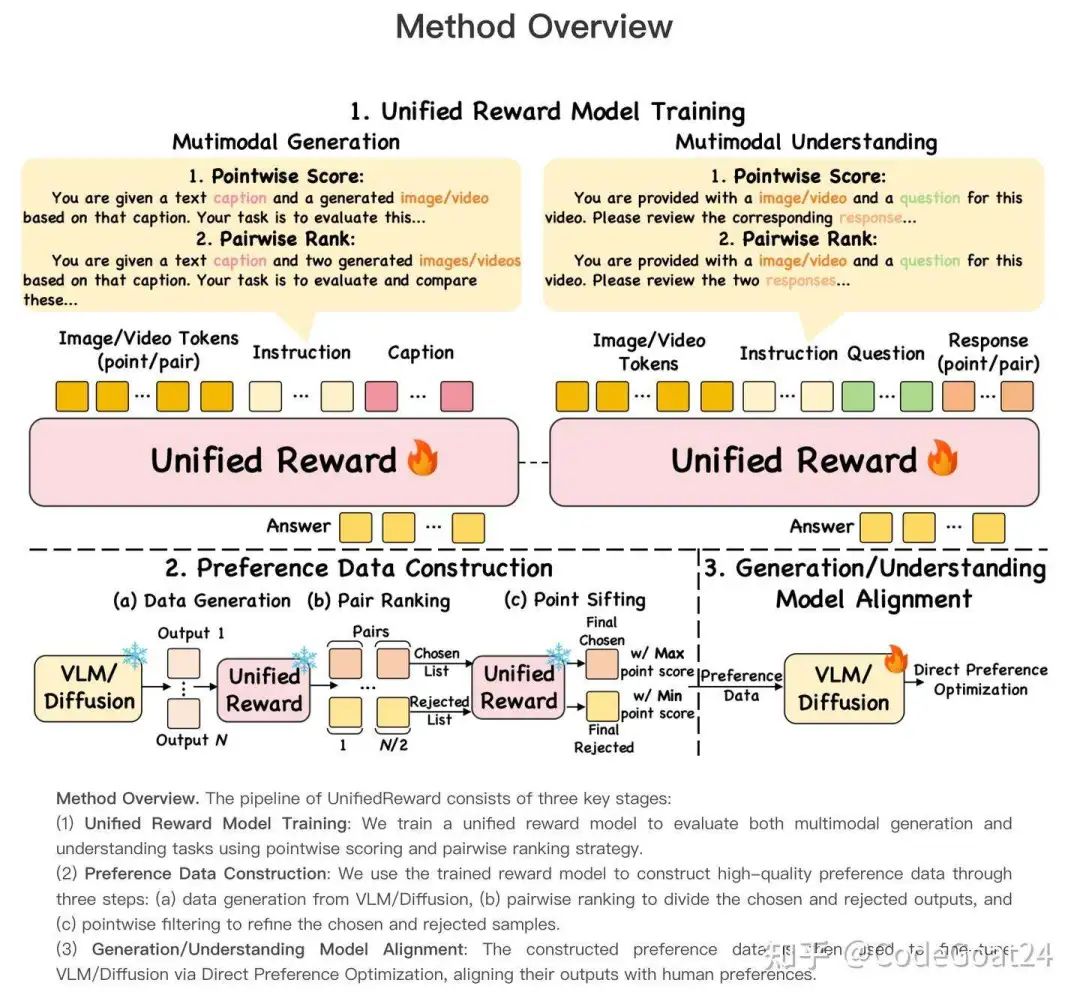
主要工作:
我们提出UnifiedReward,一个视觉领域通用的奖励模型,能够对图像/视频的生成与理解进行pairwise(成对比较)或 pointwise(单样本打分)评估,可用于视觉各领域的直接偏好优化 (DPO),提升各类视觉模型的表现

研究动机:
缺乏通用的视觉奖励模型 – 现有的奖励模型普遍较为专门化,尚未有一个统一的模型能够有效评估多模态生成与理解任务。
多任务学习的相互促进作用 – 我们认为联合学习多个任务可以实现跨任务增强,例如:
(1)提高图像理解的评估能力,有助于图像生成评估,因为更准确的主体、场景理解可以更好衡量生成质量。
(2)强化图像评估能力,有助于视频评估,因为更细粒度的逐帧分析可以提升视频质量评估的精准性。
☺️实验与核心贡献:
超越现有视觉奖励模型 – UnifiedReward在主流视觉评测基准上全面超越现有方法。
验证跨任务的相互促进作用 – 通过实验,我们证明了多任务学习在图像/视频的生成和理解评估之间具有互相增强的效果。
DPO优化带来显著提升 – 我们利用UnifiedReward对图像/视频的生成与理解模型进行DPO优化,在各个领域均取得了显著性能提升。
我们希望该工作能拓展奖励模型的应用范畴,使其在多种视觉任务中更具适应性、泛化性与高效性。
数据,代码和模型均已全面开源,README也写的很详细,欢迎大家批评指正!
Project page: UnifiedReward
Paper: https://arxiv.org/pdf/2503.05236
Github: GitHub - CodeGoat24/UnifiedReward: Official implementation of Unified Reward Model for Multimodal Understanding and Generation.
Huggingface: https://huggingface.co/papers/2503.05236
Models: https://huggingface.co/collections/CodeGoat24/unifiedreward-models-67c3008148c3a380d15ac63a
Datasets: https://huggingface.co/collecti
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









