




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享上海交通大学严骏驰组中稿ICLR 2025的最新工作—DriveTransformer!以Decoder为核心的类GPTScalable大一统端到端自动驾驶架构。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
论文作者 | Xiaosong Jia等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
当前端到端自动驾驶架构的串行设计导致训练稳定性问题,而且高度依赖于BEV,严重限制了其Scale Up潜力。在我们ICLR2025工作DriveTransformer中,不同于以往算法Scale Up Vision Backbone,我们设计了一套以Decoder为核心的无需BEV的大一统架构。在Scale Up提出的类GPT式并行架构后,我们发现训练稳定性大幅提高,并且增加参数量对于决策的收益优于Scale Up Encoder。在大规模的闭环实验中,通过Scale Up新架构到0.6B,我们实现了SOTA效果。本篇论文三位共一中的游浚琦和张致远在参与本项目时分别为大二、大三的本科生。
端到端自动驾驶(E2E-AD)已成为自动驾驶领域的一种趋势,有望为系统设计提供一种数据驱动且可扩展的方法。然而现有的端到端自动驾驶方法通常采用感知 - 预测 - 规划的顺序范式,这会导致累积误差和训练不稳定性。任务的手动排序也限制了系统利用任务间协同效应的能力(例如,具有规划感知的感知以及基于博弈论的交互式预测和规划)。此外现有方法采用的dense BEV表示在大范围感知和长时序融合方面带来了计算挑战。为应对这些挑战,我们提出了DriveTransformer,这是一种简化的易于扩展的端到端自动驾驶框架,具有三个关键特性:任务并行(所有Agent、地图和规划查询在每个模块中直接相互交互)、稀疏表示(任务查询直接与原始传感器特征交互)和流处理(任务查询作为历史信息存储和传递)。因此,新框架由三个统一操作组成:任务自注意力、传感器交叉注意力和时序交叉注意力,这显著降低了系统的复杂性,并带来了更好的训练稳定性。DriveTransformer在模拟闭环基准测试Bench2Drive和现实世界开环基准测试nuScenes中均实现了最先进的性能,且帧率较高。
简介
近年来,自动驾驶一直是备受关注的话题,该领域也取得了显著进展。其中最令人兴奋的方法之一是端到端自动驾驶(E2E-AD),其目标是将感知、预测和规划集成到一个框架中。端到端自动驾驶因其数据驱动和可扩展的特性而极具吸引力,能够通过更多数据实现持续改进。
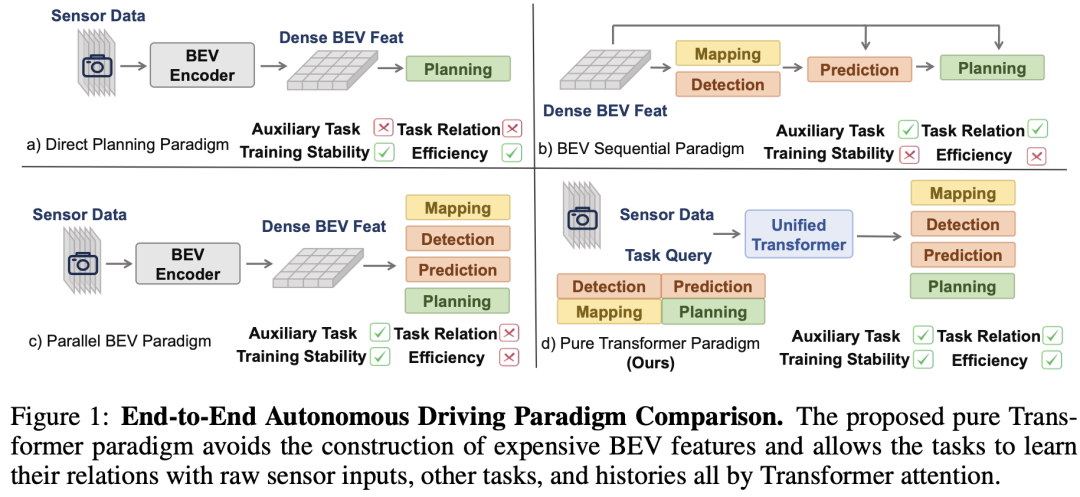
尽管具有这些优势,但现有的端到端自动驾驶方法大多采用感知 - 预测 - 规划的顺序流程,其中下游任务严重依赖于上游查询。这种顺序设计可能导致累积误差,进而导致训练不稳定。例如,UniAD的训练过程需要采用多阶段方法:首先,预训练BEVFormer编码器;然后,训练TrackFormer和MapFormer;最后,训练MotionFormer和规划器。这种分段式的训练方法增加了在工业环境中部署和扩展系统的复杂性和难度。此外,任务的手动排序可能会限制系统利用协同效应的能力,例如具有规划感知的感知以及基于博弈论的交互式预测和规划。
现有方法面临的另一个挑战是现实世界的时空复杂性。基于鸟瞰图(BEV)的表示由于BEV网格的密集性,在更大范围上的检测方面遇到计算挑战。此外,由于梯度信号较弱,基于BEV方法的图像骨干网络未得到充分优化,这阻碍了它们的扩展能力。在时序融合方面,基于BEV的方法通常存储历史BEV特征进行融合,这在计算上也非常耗时。总之,基于BEV的方法忽略了3D空间的稀疏性,丢弃了每一帧的任务查询,这导致了大量的计算浪费,从而影响了效率。
最新的工作ParaDrive试图通过切断所有任务之间的连接来缓解不稳定性问题。然而,它仍然受到昂贵的BEV表示的困扰,并且其实验仅限于开环,无法反映实际的规划能力。为解决这些不足,我们引入了DriveTransformer,这是一个高效且可扩展的端到端自动驾驶框架,具有图2所示的三个关键属性:
任务并行:所有任务查询在每个模块中直接相互交互,促进跨任务知识转移,同时在没有明确层次结构的情况下保持系统稳定。
稀疏表示:任务查询直接与原始传感器特征交互,提供了一种高效直接的信息提取方式,符合端到端优化范式。
流处理:时序融合通过先进先出队列实现,该队列存储历史任务查询,并通过时序交叉注意力进行融合,确保效率和特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









