



作者 | 自动驾驶专栏 编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文

论文链接:https://arxiv.org/pdf/2502.18042

摘要

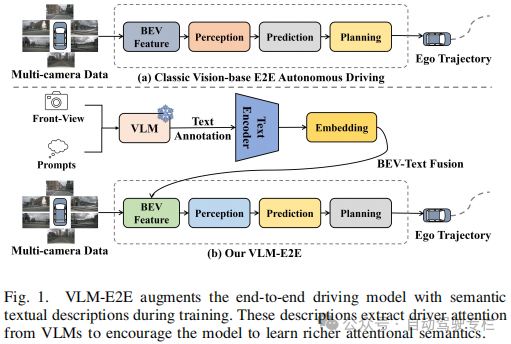
本文介绍了VLM-E2E:通过多模态驾驶员注意力融合来增强端到端自动驾驶。人类驾驶员通过利用丰富的注意力语义来熟练地在复杂场景中导航,但是目前的自动驾驶系统难以复制这种能力,因为它们在将2D观测转换到3D空间时往往会丢失关键的语义信息。从这个意义而言,这阻碍了它们在动态且复杂的环境中的有效部署。利用视觉语言模型(VLMs)卓越的场景理解和推理能力,本文提出了VLM-E2E,这是一种使用VLMs通过提供注意力线索来增强训练的新框架。本文方法将文本表示集成到鸟瞰图(BEV)特征中以进行语义监督,这使得模型能够学习更丰富的特征表示,这些表示显式地捕获驾驶员的注意力语义。通过着重于注意力语义,VLM-E2E能够更好地与类人驾驶行为相一致,这对于在动态且复杂的环境中导航是至关重要的。此外,本文还引入了一种BEV-文本可学习的加权融合策略,以解决融合多模态信息时模态重要性不平衡的问题。该方法动态地平衡了BEV和文本特征的贡献,确保了视觉和文本模态的互补信息得以有效利用。通过显式地解决多模态融合中的不平衡问题,本文方法有助于更全面、更鲁棒地表示驾驶环境。本文在nuScenes数据集上评估了VLM-E2E,并且证明了其优于最先进的方法,展现了性能的显著提升。

主要贡献

本文的主要贡献总结如下:
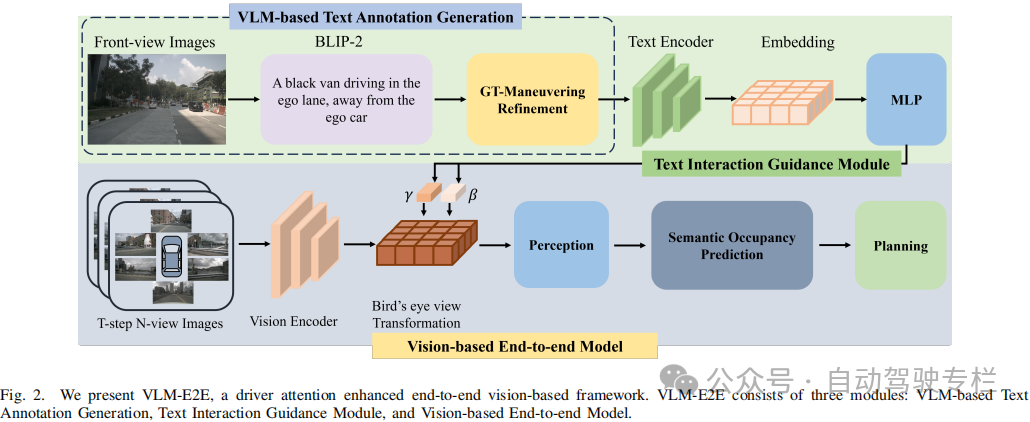
1)本文提出了VLM-E2E,这是一种利用VLMs通过注意力理解来丰富训练过程的新框架。通过结合语义和上下文信息,VLM-E2E显式地捕获了驾驶员的注意力语义,这使其能够在复杂的驾驶场景中做出更人性化的决策;
2)本文引入了一种BEV-文本可学习的加权融合策略,该策略动态地平衡了BEV和文本模态的贡献。这种自适应融合机制在计算上是高效的,它需要最少的额外开销,同时显著地增强了模型的适应性和鲁棒性;
3)为了解决VLMs的幻觉问题,本文结合了从前视图像中生成的文本描述的语义细化。通过利用真值(GT)标签和高级行为意图,确保了文本表示既准确又与驾驶任务高度相关,从而增强了模型对关键驾驶线索的推理能力;
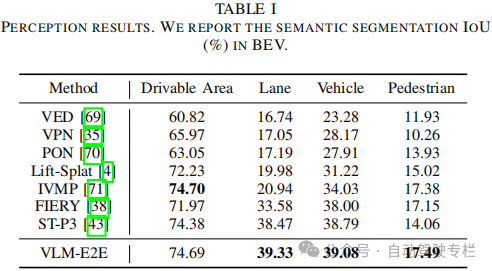
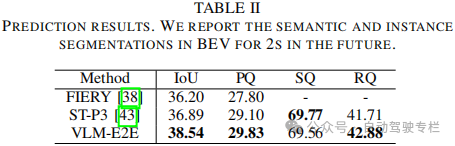
4)在nuScenes数据集上进行的大量实验证明了VLM-E2E优于现有的方法。本文框架在处理复杂的驾驶场景方面取得了重大改进,展现了其将几何精度与高级语义推理相结合的能力,以实现更安全、更可解释的自动驾驶。

论文图片和表格


总结

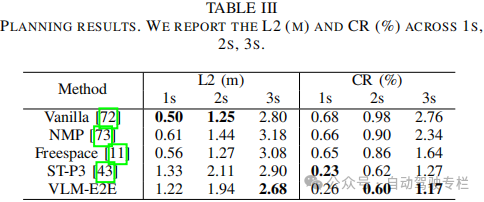
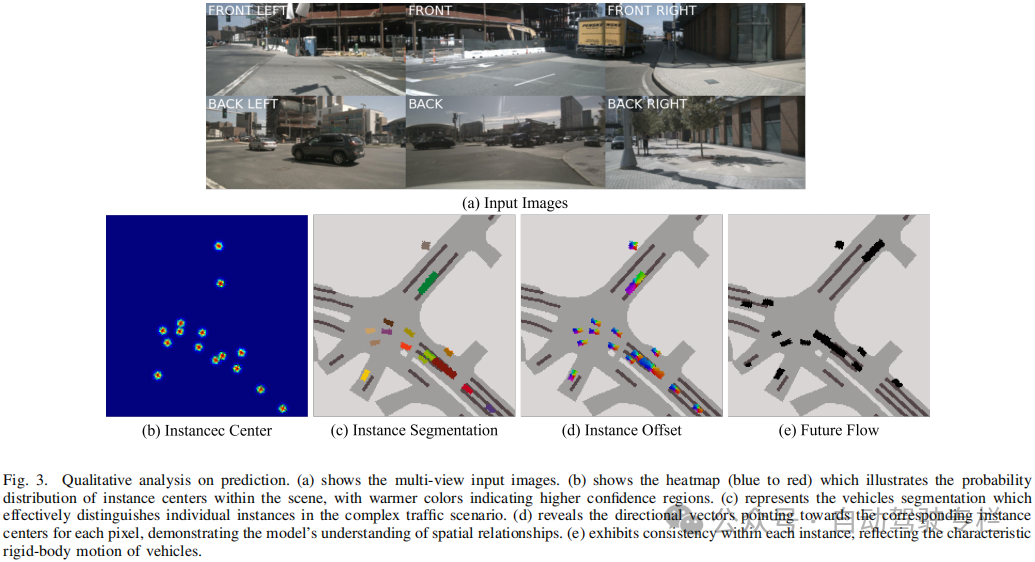
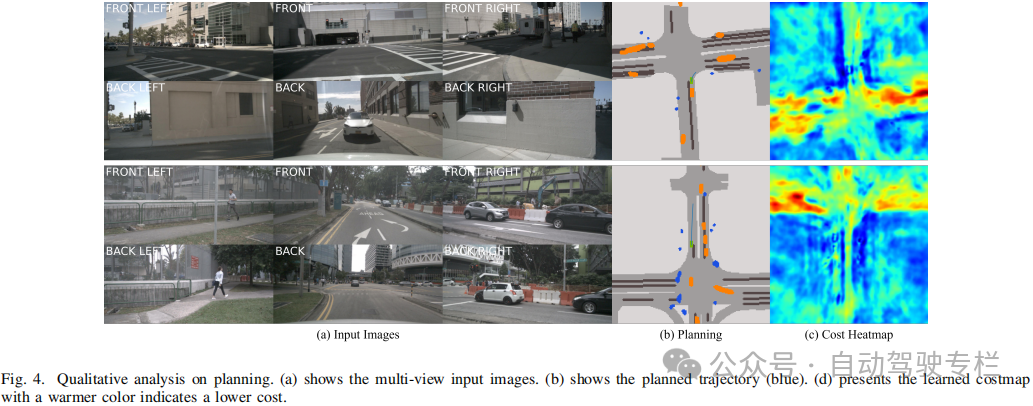
本文提出了VLM-E2E,这是一种利用VLMs来增强对驾驶员注意力语义理解的新端到端自动驾驶框架。本文方法的目标是为了解决现有系统中的关键局限性,例如多传感器融合中的模态不平衡、高级语义上下文的利用不足以及轨迹规划中缺乏可解释性。为此,本文引入了一种BEV-文本可学习的加权融合策略来动态地平衡几何和语义特征、一个时空模块来确保动态场景中的时间连贯性以及一个具有注意力引导轨迹优化的概率未来预测模块。这些组件共同使本文框架能够在感知、预测和规划任务中实现鲁棒且可解释的性能。未来工作将着重于扩展该框架,以将VLMs和E2E加入一个统一的框架中,并且利用激光雷达和雷达模态在长尾场景中泛化所提出的模型。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









