



Occupancy Network是自动驾驶感知任务中的一个非常重要角色。这种轻语义重几何的网络模型,能够更好地辅助自动驾驶系统感知free space,也是今年各大自动驾驶公司抢先量产的目标。在3D目标检测失效的范围内,能够进一步提升感知能力,形成闭环。下面让我们一起看看Occupancy是什么?为什么需要它?
为什么需要Occupancy?
自动驾驶在动静态障碍物感知领域的发展大概分为三个阶段:1)2D图像空间检测障碍物,映射到鸟瞰空间做多相机和时序融合;2)直接在BEV空间中完成动态障碍物的3D检测和静态障碍物的识别建模;3)直接在3D空间中感知占用关系,为系统规划可行驶空间。
目前2D检测方案基本被抛弃,逐渐转为BEV空间下的3D检测任务,这种方式更加友好,可以直接输出下游可用的目标。然而BEV感知也同样面临一些难解决的问题,比如截断目标、形状不规则、未有清晰语义的目标(比如挂车、树木、垃圾、以及石子等),传统的3D检测在这类场景上很容易失效。
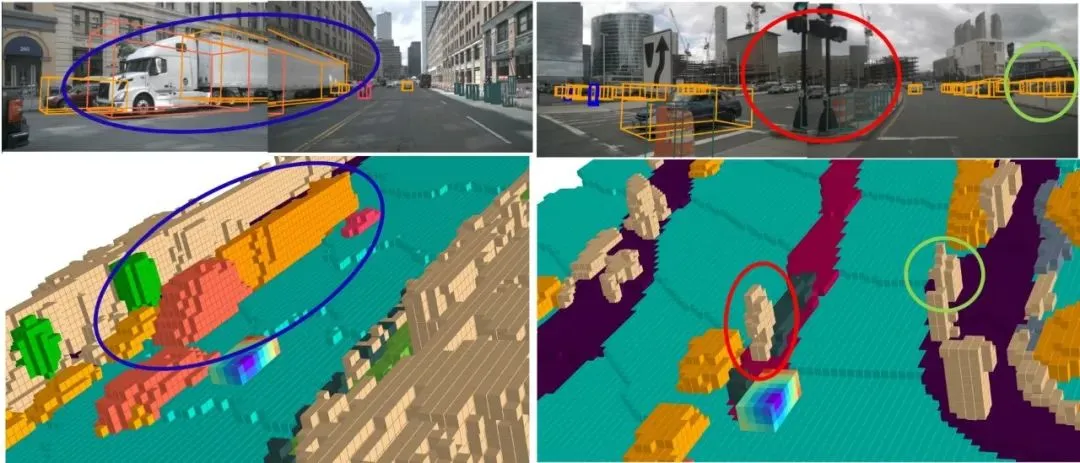
那么是否可以直接对环境建模,表达为占据栅格的形式呢?不过度区分语义、更关注是否占用,是否为空。特斯拉的Occupancy Network给出了答案,国内几乎所有主流公司也快速投入研发,期望解决感知的下半场问题。


当下,行业普遍把Occ作为下一代的感知范式,成为各大自动驾驶公司抢占的高地。2024年的量产车型中,几乎成了标配,无论是在行车或泊车场景,都发挥了巨大的作用。
Occ任务为什么难做?
BEV模型和Occupancy有较多相似之处,BEV的特征生成范式几乎和Occ完全相同,时序方法也完全适用。但为什么Occ任务这么困难呢?各家自动驾驶公司虽然投入了较多人力物力,但效果并不是很好。这就要说到几个关键部分:数据生成、数据优化、模型优化、模型监督等;
数据生成与优化占据了Occ任务的主要部分,和检测任务不同,Occupancy真值很难通过人工标注,需要借助3D box的位置和语义信息间接生成。那么怎么从原始点云生产出比较优质的Occ真值呢?一般认为,优质的真值需要包含以下几个部分:真值稠密化(不能太稀疏)、动静态目标不能有拖影、地面干净无误检、区分遮挡和非遮挡元素、类别划分正确、细粒度足够等等;这就涉及到前景稠密化、背景稠密化、多帧如何有效拼接?如何分割地面?如何清理地面等多个方面,实施起来难度较大,需要很多trick,很多同学训出来的模型往往误检测一大堆......
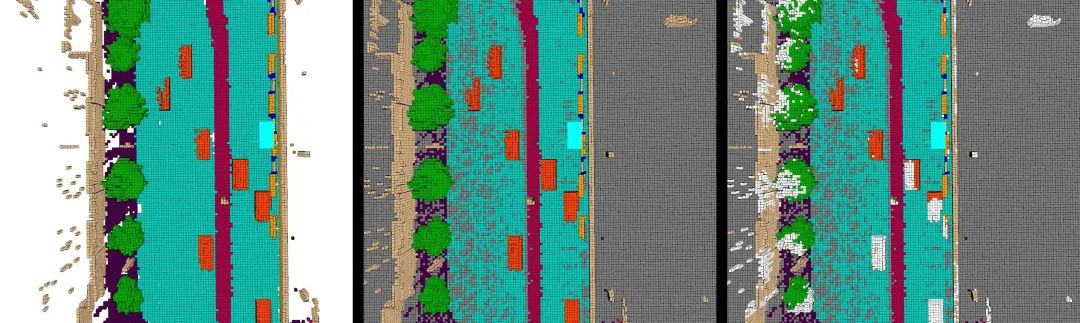
模型的优化部分关注模型在已有数据下的性能上限提升,如何设计更好的特征提取模式,如何将2D特征有效投影到3D空间,如何把计算量较大的模型轻量化部署等,都是行业比较关注的难题。
模型的监督部分关注监督模式,是直接用Occ真值监督还是通过点云监督,抑或是自监督?如果没有3D真值怎么办?能否借助NeRF完成2D层面上的监督,直接绕开3D真值?这些都是学术界和工业界比较关注的部分。
不得不说,看似简单的Occ任务,想要搭建一套完整的系统并不简单,不仅仅刚入门的小白不知道如何下手,即使是感知领域的老鸟想要快速开展起来也很难。
如何彻底搞懂Occ任务呢?
自动驾驶之心前期调研了学术界和工业界关于Occupancy Network的一些痛点和难点问题,联合了业界知名算法专家,针对数据生成、数据优化、模型优化、模型监督等多类问题展开了详述。彻底解决Occ入门难、关键问题卡脖子的痛处。
微信扫码领取,早鸟优惠券!

先到先得
本课程适用刚入门的小白、以及正在从事自动驾驶感知的算法工程人员、想要转入自动驾驶感知领域的同学。大纲如下:

主讲老师
Kimi,清华大学博士,研究方向人工智能和自动驾驶,在TPAMI、CVPR、ICLR等国际顶级期刊及会议上发表相关论文20余篇,申请发明专利10余项,担任10余个国际期刊及会议审稿人。在自动驾驶算法设计和模型部署等方面具有丰富经验,主导10余项开源项目,其中star数过千的项目1个,过百的项目7个。
Michael, 清华大学在读博士,深耕自动驾驶感知算法设计多年,在计算机视觉国际顶会上发表多篇论文,在Occupancy感知方面有多项原创成果,独立搭建学术界首个基于环视的Occupancy开源代码库,被几十项工作引用。
课程亮点
1)从0到1带你生成和优化Occ真值数据
2)多个Occ实战代码详解,知其然知其所以然

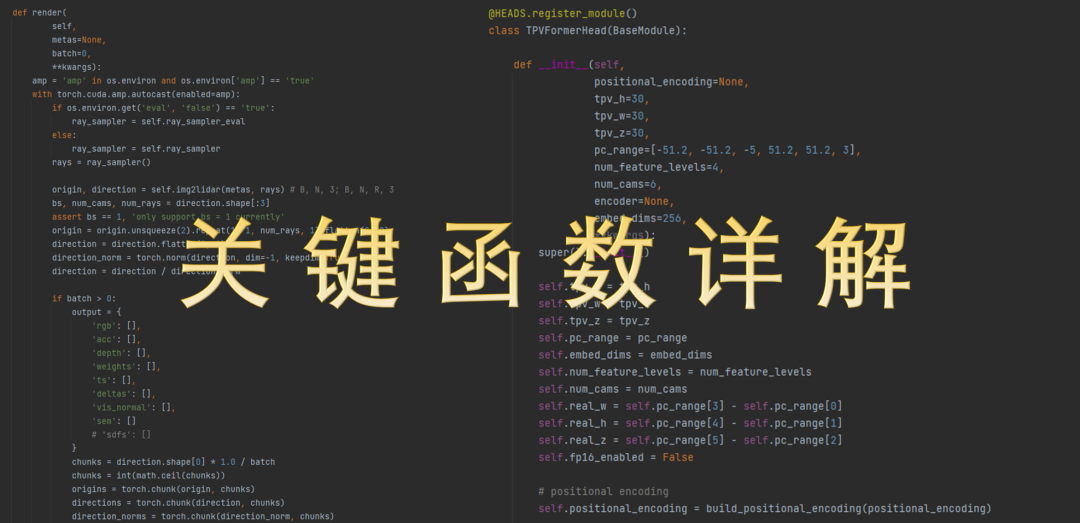
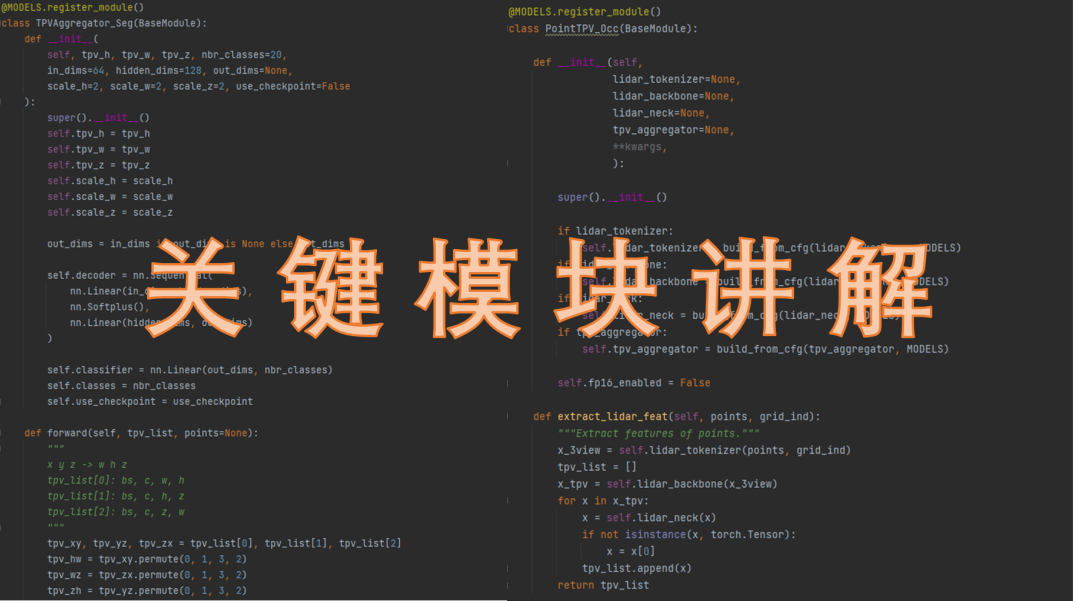
3)彻底搞懂NeRF是怎么监督Occ任务的
4)多个监督方式详解,熟悉常见的2D/3D/点云监督方案
5)丰富的大作业,让每个同学都学有所成
面向群体
1.计算机视觉与自动驾驶感知相关研究方向的本科/硕士/博士;
2.CV与自动驾驶2D/3D感知相关算法工程人员;
3.量产和预研工作需要的同学,面向L2~L4级应用;
4.想要转到自动驾驶领域的相关同学;
需要的基础
1.熟悉pytorch和python开发,一定的BEV和Occ任务基础;
2.一定的训练资源支持,建议显存在RTX3060及以上;
3.一定的线性代数和矩阵论等数学基础;
4.对自动驾驶有着充足的自信和热情,期望投入到行业潮流中;
开课时间
2024.5.28号,正式开课!离线视频教学+vip群内答疑。
扫码咨询
微信扫码领取,早鸟优惠券!

欢迎咨询小助理了解更多!

版权声明
自动驾驶之心所有课程最终版权均归自动驾驶之心团队及旗下公司所属,我们强烈谴责非法盗录行为,对违法行为将第一时间寄出律师函。也欢迎同学们监督举报,对热心监督举报的同学,我们将予以重报!
投诉微信:AIDriver004(备注:盗版举报)

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









