



作者 | AI视界引擎 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【模型部署】技术交流群
本文只做学术分享,如有侵权,联系删文
精确的3D感知系统对于自动驾驶至关重要。经典方法依赖于激光雷达点云提供的精确3D信息。然而,激光雷达传感器通常花费数千美元,阻碍了其在经济型车辆上的应用。纯基于相机的鸟瞰图(BEV)方法最近因其令人印象深刻的3D感知能力和经济的成本而显示出巨大的潜力。
为了从2D图像特征中进行3D感知,nuScenes上最先进的BEV方法要么使用隐式/显式基于深度的投影,要么使用基于Transformer的投影。然而,它们很难部署在车载芯片上:
具有深度分布预测的方法通常需要多线程CUDA内核来加速推理,这不方便在资源受限或推理库不支持的芯片上操作。
Transformer内的注意力机制需要专用芯片来支持。此外,它们在推理方面很耗时,这使它们无法进行实际部署。
1、省流阅读
本文主要对性能优秀、部署友好、推理速度高的Fast-BEV感知框架的讲解和TensorRT的落地部署
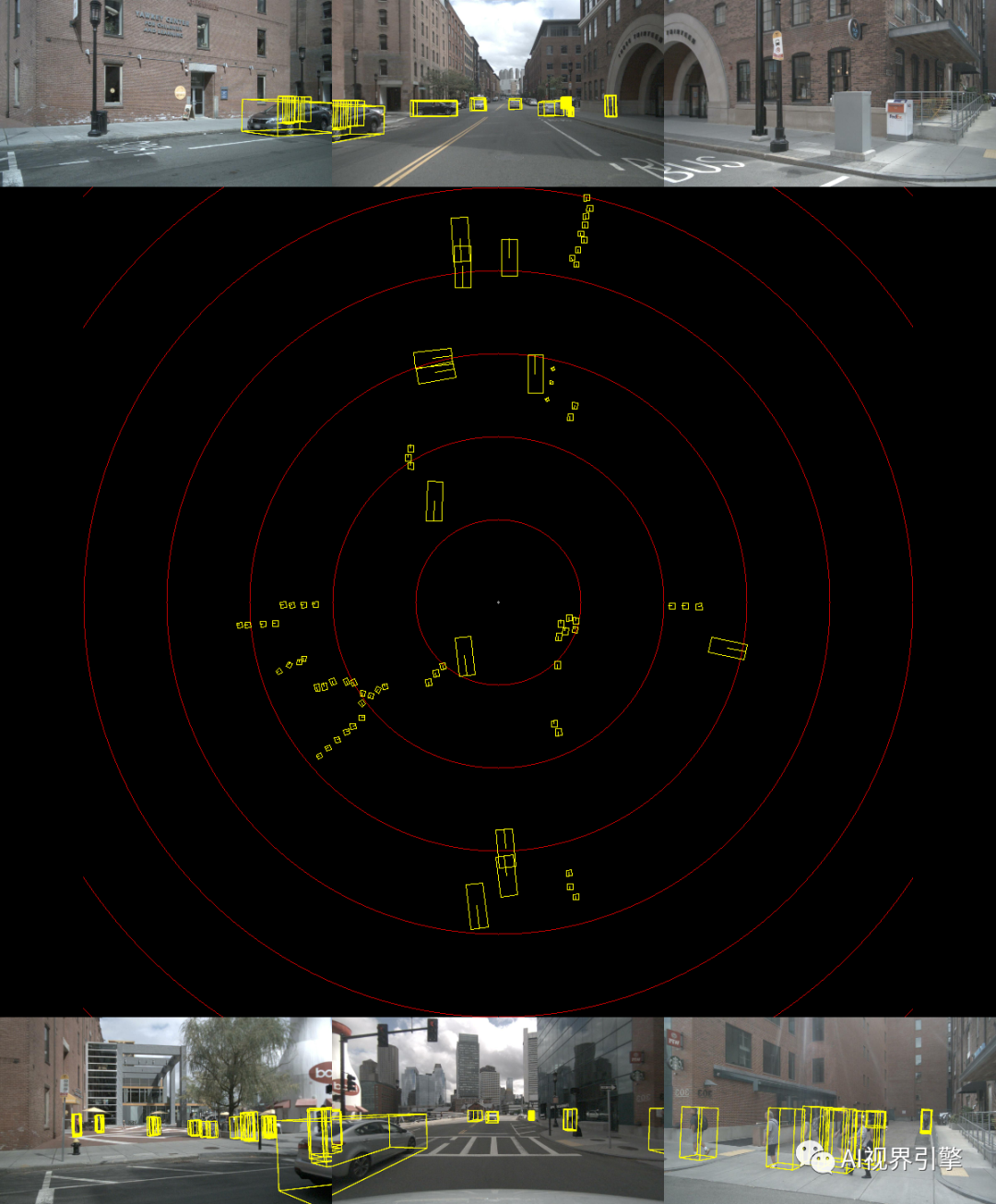
1、TensorRT落地效果
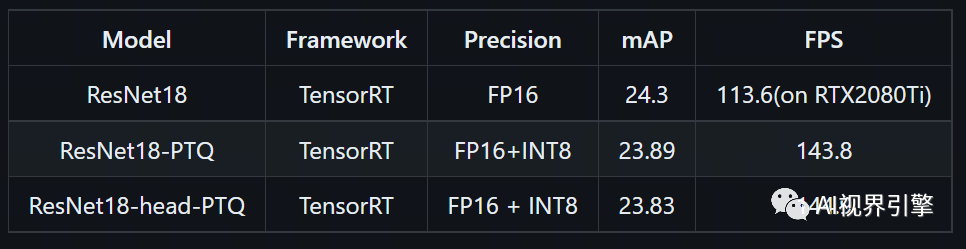
2、量化前后的精度与速度的对比
3、部署代码列表
4、环境的配置
5、开源地址
TensorRT的代码链接:https://github.com/Mandylove1993/CUDA-FastBEV
2、Fast-BEV的原理要点
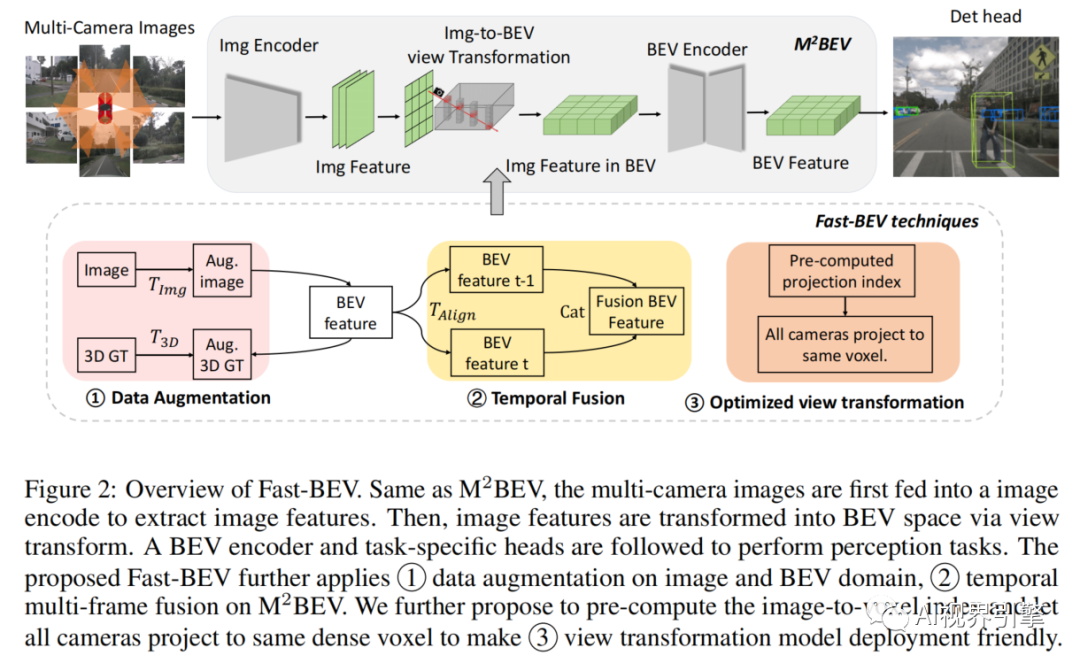
1、Fast-BEV的前世
是最早用统一的BEV表示来解决多摄像机多任务感知的作品之一。它也更适用于车载平台,因为它没有昂贵的视图Transformer或深度表示。如图2顶部所示,的输入是多摄像机RGB图像,输出是预测的3D边界框(包括速度)和地图分割结果。
有4个关键模块:
从多摄像头图像中提取图像特征的2D图像编码器;
图像到BEV(2D→3D)视图转换模块,其将2D图像特征映射到3D BEV空间中;
处理3D特征的3D BEV编码器;
执行感知任务(例如3D检测)的任务专用头。
2、Fast-BEV的今生
尽管可以取得有竞争力的成绩,但我们发现它的性能和效率可以进一步提高。如图2底部所示,我们将三种技术集成到中,从而实现了更强、更快的快速BEV。
Data augmentation:从经验上观察到,在的后期训练时期发生了严重的过度拟合问题。这是因为在原始中没有使用Data augmentation。受最近工作[BevDet,BevDepth]的启发,在图像和BEV空间上添加了强大的3D augmentation,如随机翻转、旋转等。
Temporal fusion:在真实的自动驾驶场景中,输入在时间上是连续的,并且在时间上具有巨大的互补信息。例如,在当前帧中被部分遮挡的一名行人可能在过去的几帧中完全可见。因此,通过引入时间特征融合模块,将从BEV空间扩展到时空空间,类似于[Bevformer,Bevdet4d]。更具体地说,使用当前帧BEV特征和存储的历史帧特征作为输入,并以端到端的方式训练快速BEV。
Optimized view transformation:作者发现从图像空间到体素空间的投影主导了延迟。作者建议从2个角度优化投影:
-
预先计算固定的投影索引,并将它们存储为静态查找表,这在推理过程中非常有效。
让所有的相机投影到同一个体素,以避免昂贵的体素聚集。不像基于Lift Splat Shoot的改进视图转换方案[ Bevdepth, Bevdet,Bevfusion]那样需要开发繁琐而困难的DSP/GPU并行计算,它足够快,只使用CPU计算,这非常方便部署。更多细节见第3.5节
重中之重——优化 View Transformation
iew transformation是将特征从2D图像空间变换到3D BEV空间的关键组件,这通常需要在整个过程中花费大量时间。Lift Splat Shoot是一种经典的view transformation方法。尽管已经针对高级GPU设备(例如,NVIDIA Tesla A100、V100)提出了一些加速技术,但优化无法轻易转移到边缘芯片等其他设备。
另一类view transformation是,它假设深度分布沿着光线是均匀的。优点是,一旦获得了相机的内参/外参,就可以很容易地知道2D到3D的投影。由于这里没有使用可学习的参数,可以很容易地计算2D特征图和BEV特征图中的点之间的对应矩阵。遵循的投影方法,并从两个角度进一步加速:
预计算投影指数
密集体素特征生成
投影索引是从2D图像空间到3D体素空间的映射索引。因为本文的方法既不依赖于依赖于数据的深度预测,也不依赖于Transformer,所以对于每个输入,投影索引都是相同的。因此,可以预先计算固定的投影索引并将其存储。在推理过程中,可以通过查询查找表来获得投影索引,这在边缘设备上是一种非常便宜的操作。此外,如果从单帧扩展到多帧,也可以很容易地预先计算内参和外参,并将它们预先对准当前帧。
cuda kernel实现如下:
static __global__ void compute_volum_kernel(int num_valid, const half* camera_feature, const float* valid_index, const int64_t* valid_y, const int64_t* valid_x, int num_camera, int feat_height, int feat_width, half* output_feature) {
int tid = cuda_linear_index;
if (tid >= num_valid) return;
for (int icamera = 0; icamera < num_camera; ++icamera) {
int index = icamera * num_valid + tid;
if(valid_index[index] == 1.0){
int64_t x = valid_x[index];
int64_t y = valid_y[index];
for(int c=0; c< 64; c++){
output_feature[c*num_valid+tid] = camera_feature[icamera*64*feat_height*feat_width+c*feat_height*feat_width +feat_width*y+x];
}
}
}
}将为每个相机视图存储一个体素特征,然后将其聚合以生成最终的体素特征(见图5)。因为每个相机只有有限的视角,所以每个体素特征都非常稀疏,例如,只有大约17%的位置是非零的。作者认为这些体素特征的聚集由于其巨大的尺寸而非常昂贵。建议生成密集的体素特征,以避免昂贵的体素聚集。
具体来说,让来自所有相机视图的图像特征投影到相同的体素特征,从而在末端产生一个密集的体素。
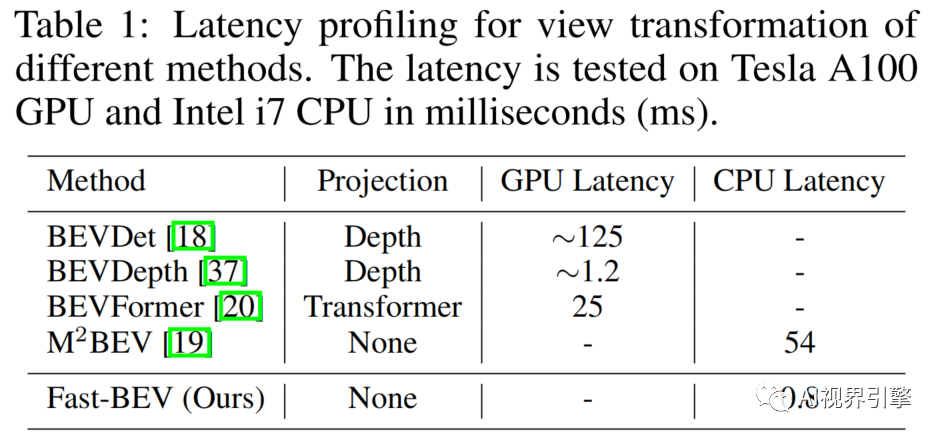
在表1中,分析了4种不同方法的视图转换延迟,发现:
BEVDepth在GPU上实现了最佳延迟,但它需要专用的并行计算支持,因此不适用于CPU。
与 Baseline相比,所提出的快速BEV在CPU上实现了数量级的加速。
3、参考
[1].Fast-BEV: Towards Real-time On-vehicle Bird’s-Eye View Perception.
[2].https://github.com/Mandylove1993/CUDA-FastBEV.

南京大学提出量化特征蒸馏方法QFD | 完美结合量化与蒸馏,让AI落地更进一步!!!
英特尔提出新型卷积 | 让ResNet/MobileNet/ConvNeXt等Backbone一起涨点
华为诺亚实验室提出CFT | 大模型打压下语义分割该何去何从?或许这就是答案!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









