



作者 | EatElephant 编辑 | 汽车人
原文链接:https://www.zhihu.com/question/598088657/answer/30059767
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
其实学术界和产业界都有这种方面的尝试,总的来说就是端到端的自动驾驶技术,产业界比较有名的是Comma.ai 的OpenDrive,已经可以实现不依赖高精地图的高速导航驾驶和正在实验的红绿灯起停功能,以及来自英国的Wayve公司主要目标是使用端到端实现L4级自动驾驶功能。


自动驾驶其实有很多流派,其中一种分类是端到端的自动驾驶和模块化的自动驾驶。关于更多自动驾驶流派和现状的讨论我以前发过一篇回答,有兴趣可以参考下各大厂都下场造车,自动驾驶这一块今年各路神仙登场,你看好哪一派?。
目前无论是L4自动驾驶公司还是量产车企,绝大多数自动驾驶公司都走的是模块化的路线,模块化的路线总的来说就是将驾驶这个工作拆分成感知,定位,预测,决策,控制等可以各个击破的模块,各自做到最好再将各个模块功能组合到一起完成驾驶工作。这个方案的好处在于可解释性强,各模块符合人类对驾驶认知,一旦出现问题可以快速定位问题解决问题。缺点则在于无法进行端到端的训练,各模块间接口由人类定义,另外各模块输入输出之间可以理解成为一种信息抽象,输入到输出不可避免造成信息损失,因此越下游模块的输入信息越受上游限制。
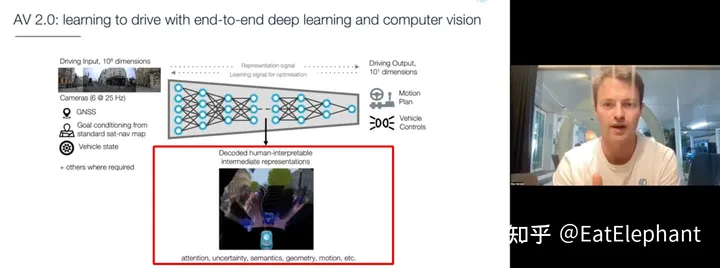
另外一种端到端的自动驾驶就是问题中所说的由各种传感器如相机,GPS,IMU,轮速,Lidar,毫米波雷达以及导航地图等作为输入给入一个大模型直接输出对车的控制信号如油门刹车,方向盘转向,信号灯开关等等。这样的方案好处在于不必划分模块,整个系统可以由数据驱动的端到端训练完成。而且驾驶信号入油门刹车方向盘等很容易获得,直接提取驾驶员动作就可以,相比图像标注,Lidar点云标注等节省大量人工作业成本。另外由于去掉了人工定义的模块间接口,消除了人为设计的不足,避免了模块间信息的逐层流失。
虽然端到端自动驾驶有着这些优势,然而业界普遍认为端到端自动驾驶优点并非必须,但缺点有点致命。端到端自动驾驶的主要缺点在于不可解释性,一旦端到端给出了错误的输出,由于端到端整个系统是个黑盒,其中的问题很难定位排查和修复。目前GPT等为代表的大语言模型展现出了令人激动的能力,我本人也是非常关注,但是目前GPT中最广为诟病的问题依旧是会胡编乱造一些不真实信息,这对于一个大语言模型是尚可容忍的瑕疵,然而对于自动驾驶就比变成了难以接受的致命问题,因为自动驾驶与大语言模型不同,是一个对安全问题近乎零容忍的AI系统。端到端的训练虽然在GPT等大语言模型上展现出让人难以置信的“智能”,但是无论功能多么强大,如果无法极大的减少交通事故的发生,那么使用端到端大模型直接完成全部自动驾驶功能就还无法实现。

最后目前的端到端系统为了提高可解释性,一般添加中间层的人类可解读的语义信息的可视化输出,其本质上仍旧是通过中间层去训练出一些符合人类对驾驶中间过程认知来保证模型具有一定的可解释性,这其实和人脑的工作原理类似,人脑在接收传感器输入后并非直接映射成驾驶动作,其中也会有对周围事物语义的解读,例如前车要加塞,这里有个坑,车子开过去会可能造成损坏等非驾驶动作的中间信息,那这些有益的端到端实践其实给后续的很多大模型研发提供了值得借鉴的经验。
另外分享一点个人理解,未必正确,欢迎讨论。虽然人类驾驶本质上是一个大的神经网络直接把输入信号映射成驾驶操作,但是人脑的构造和人工神经网络模型并不相同,目前神经网络模型的设计趋势是趋向于更容易进行梯度反向传播,更易训练,更高效推理而并不是更加强调仿生,所以大规模神经网络究竟能多大程度上实现人脑智能目前还没有定论,因此端到端的进行自动驾驶是值得尝试的,但不一定就能实现。因为虽说驾驶对人类来讲不算困难的任务,大多数人可以通过训练掌握这个技能,但是即使不说神经网络模型和大脑模型的差异,就算是与我们人类大脑十分接近的猩猩,其大脑构造和人类大脑的差异大概率远小于现阶段神经网络大模型和人脑的差异,但是人们似乎目前还无法训练猩猩成为合格的司机。所以如果端到端的训练无法让猩猩掌握驾驶,那么端到端的神经网络模型能力上限在哪,是人类智能,超过人类智能,还是只有猴子猩猩,甚至更低水平的智能,是否可以端到端的实现自动驾驶,这些问题的答案都还是没有定论的。因此现阶段用人类智慧对驾驶工作进行拆分,模块化,以补充人工神经网络模型能力的不足,这样的技术架构目前看来仍旧是更合理,更靠谱的。

视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









