



作者 | 我要吃鸡腿 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1965839552158623077
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
在自动驾驶这个飞速迭代的领域,技术范式的更迭快得令人目不暇接。前年,行业言必称BEV(鸟瞰图视角);去年,“端到端”(End-to-End)又成了新的技术高地。然而,每一种范式在解决旧问题的同时,似乎都在催生新的挑战。
传统的“端到端”自动驾驶,即VA(Vision-Action,视觉-行动)模型,就暴露出一个深刻的矛盾:它就像一个车技高超但沉默寡言的“老司机”。它能凭借海量数据训练出的“直觉”,在复杂的路况中做出令人惊叹的丝滑操作。但当您坐在副驾,心脏漏跳一拍后问它:“刚才为什么突然减速?”——它答不上来。
这就是“黑箱”问题:系统能“做对”,但我们不知道它“为何做对”。这种无法解释、无法沟通的特性,带来了巨大的信任危机。
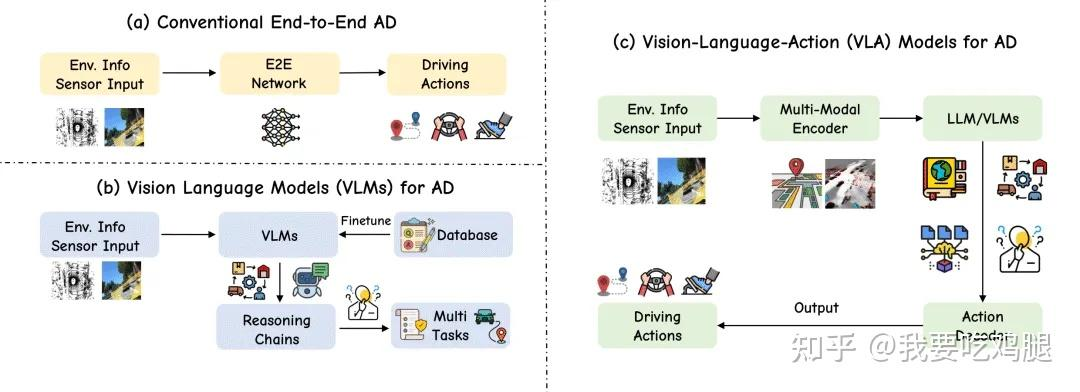
为了撬开这个“黑箱”,行业转向了VLM(Vision-Language Models,视觉语言模型)。VLM就像一个坐在副驾、懂车的“评论员”。它能看懂摄像头拍到的一切,能精准地告诉你“前方有施工”或者“那个指示牌是可变车道”(见图(b))。但问题是,它只会说,不会开。VLM的产出停留在语言和理解层面,与车辆的实际控制之间存在一条难以逾越的“行动鸿沟”(Action Gap)。
更多关于自驾VLA的技术进展、方案解析,欢迎加入「自动驾驶之心知识星球」,4400人的专业社区,我们准备了少量优惠券......

显然,我们需要的不是一个“直觉型老司机”和一个“评论员”的生硬组合,而是一位既能掌勺、又能著书立说的“教练型司机”——他不仅能做出完美的驾驶动作,更能用语言解释他为何这么做。
这就是2025年的技术焦点——VLA(Vision-Language-Action,视觉-语言-行动)模型。
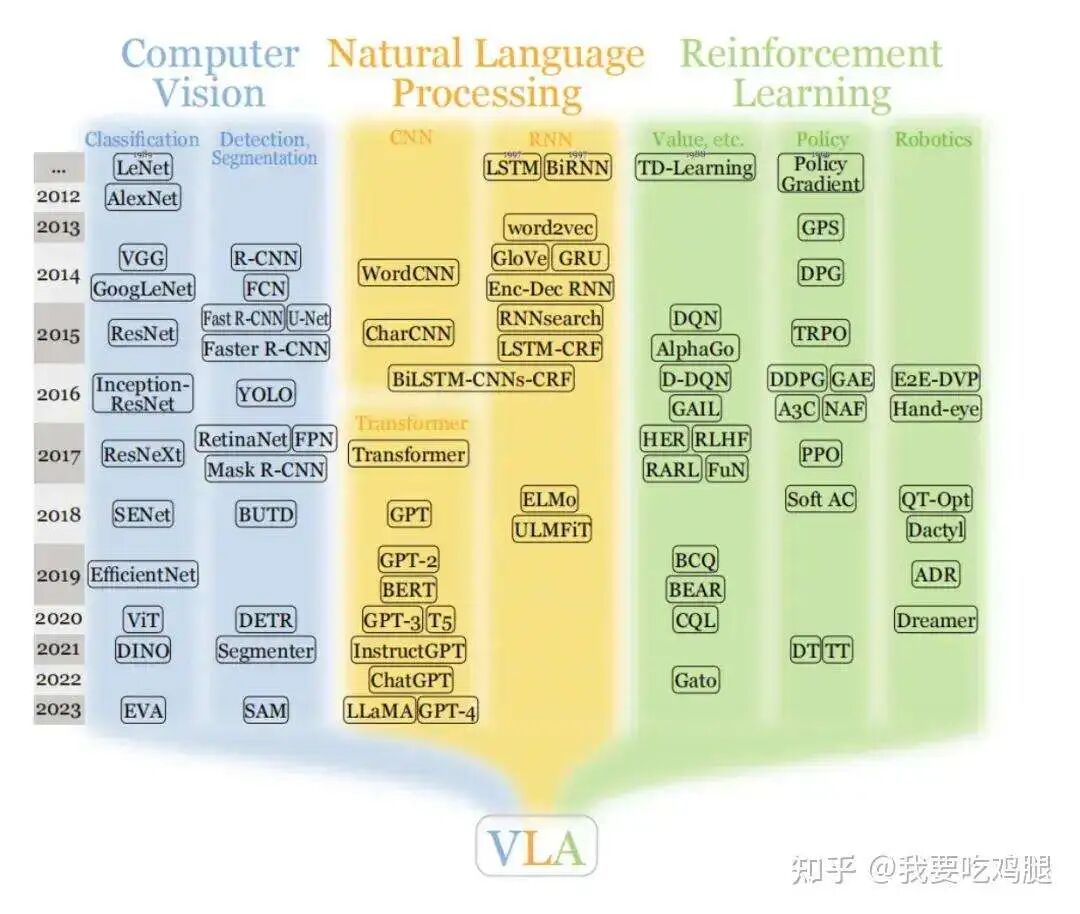
VLA不再是VA或VLM的简单修补,而是一场彻底的范式革命(见图 (c))。它的目标是打造一个“可解释的大脑”,将计算机视觉(Computer Vision)、自然语言处理(Natural Language Processing)和强化学习(Reinforcement Learning)这三大AI领域的顶尖技术最终融合在一起,试图创造一个既能感知世界、又能理解规则、更能执行动作的统一智能体。
一、“真假”E2E之辨:VLA为何是自动驾驶的“真”端到端?
在自动驾驶的讨论中,“端到端”(End-to-End, E2E)是一个被频繁使用,但定义却常常模糊的术语。要理解VLA为何被视为一场革命,我们必须首先严格地辨析:在驾驶场景下,到底什么才是“真”端到端?
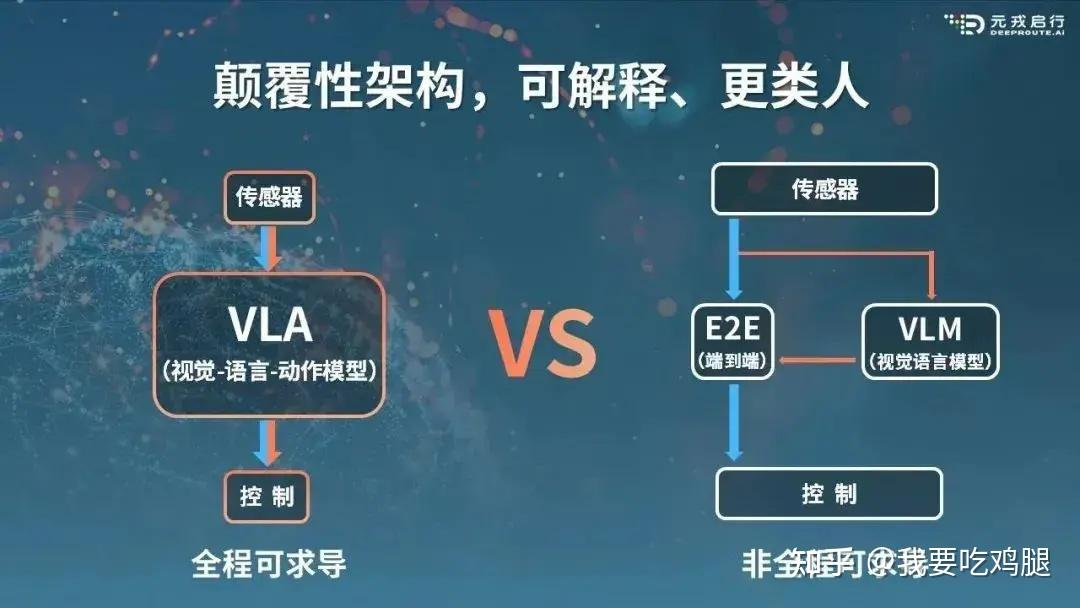
一个“真”的端到端驾驶系统,必须是一个统一的、完整的神经网络。它接收最原始的传感器输入(如摄像头图像 - Vision),并直接输出最终可执行的控制信号(如转向和加减速 - Action)。
这个架构最关键的特性,在于它是“全程可求导”的(Fully Differentiable)。这意味着,当车辆在现实中犯了一个错误(比如刹车晚了),这个“错误”的信号可以像电流一样,从最终的动作输出端,一路反向传播(Backpropagation)回溯到最开始的视觉输入端,从而修正和优化网络中的每一个参数。
只有这样,系统才能通过驾驶本身“学会”驾驶。
1.1 VLM的“非”端到端本质
基于上述严格的定义,我们再来看行业早期为了让E2E模型“变聪明”而引入的VLM(视觉语言模型),会发现一个根本性的问题。
VLM的引入,非但没有实现“真”端到端,反而从架构上“打断”了端到端的闭环。
其核心问题在于:VLM的输出端是文本(Text),而非轨迹(Trajectory)。
正如上图(b)所示,VLM(视觉语言模型)在自动驾驶中扮演的角色,是我们序言中提到的“评论员”。它接收图像输入(Image),然后输出它对场景的“理解”,即文本(Text)。例如,它会输出:“前方有行人,应减速”或“这是一个可变车道,当前可通行”。
这个“文本”输出,与车辆最终执行的物理动作——即一系列精确的转向、油门、刹车数值(例如 [x, y, yaw, velocity, ...])——之间,存在着一条巨大的“语义鸿沟”和“行动鸿沟”。
这种架构上的断裂,带来了一个灾难性的后果:VLM模型无法受益于自动化的数据闭环(Data Loop)驱动。
试想一下:当车辆因为“刹车晚了”而产生了一个错误,这个“刹车”的错误信号是一个物理数值。我们如何用这个物理数值,去反向训练一个只输出“文本”的VLM,让它下次生成“更正确”的句子呢?答案是几乎不可能。
由于VLM并不直接输出轨迹,它的学习和优化(即反向传播)与车辆的最终驾驶行为是“解耦”的。因此,VLM本质上“并非端到端神经网络”(在驾驶的语境下)。它是一个强大的“外挂”大脑,但它不是“驾驶员”本身。
1.2 “快慢双核”的“半”端到端
既然VLM本身无法成为端到端的“驾驶员”,一个看似聪明的“折中”方案便应运而生:将VLM(“评论员”)与传统的VA(“老司机”)组合在一起,形成一个“L+VA”的拼凑架构。
这就是行业早期的“快慢双核”系统。
“快系统”(System 1): 传统的VA端到端模型,负责处理95%的常规驾驶场景。它就像大脑的“直觉与本能”,运行速度快、自动化。
“慢系统”(System 2): VLM大模型,负责处理5%的复杂长尾场景(如理解异形路标、处理复杂博弈)。它就像大脑的“理性思考”,费力、缓慢但逻辑性强。

以理想汽车早期的IM系统为例,这套“快慢双核”架构的运行机制非常典型:
它的“快系统”(System 1)运行在一块Orin X芯片上,可能以15-20Hz的频率高速处理本能驾驶。而它的“慢系统”(System 2,基于阿里的千问大模型)则运行在另一块芯片上,受限于算力和VLM的复杂性,可能仅以5Hz的频率缓慢地进行“理性思考”。
这种“半”端到端的拼凑架构,虽然在一定程度上解决了VA“老司机”不认识字的问题,但也带来了三个致命的缺陷:
异步与冲突: 两个系统、两块芯片、两种频率(15-20Hz vs 5Hz),这本身就是一场灾难。当“快系统”凭直觉要超车时,“慢系统”在200毫秒后才反应过来并发出指令:“不要超车,那是可变车道”。此时,两个系统的决策发生冲突,车辆到底该听谁的?
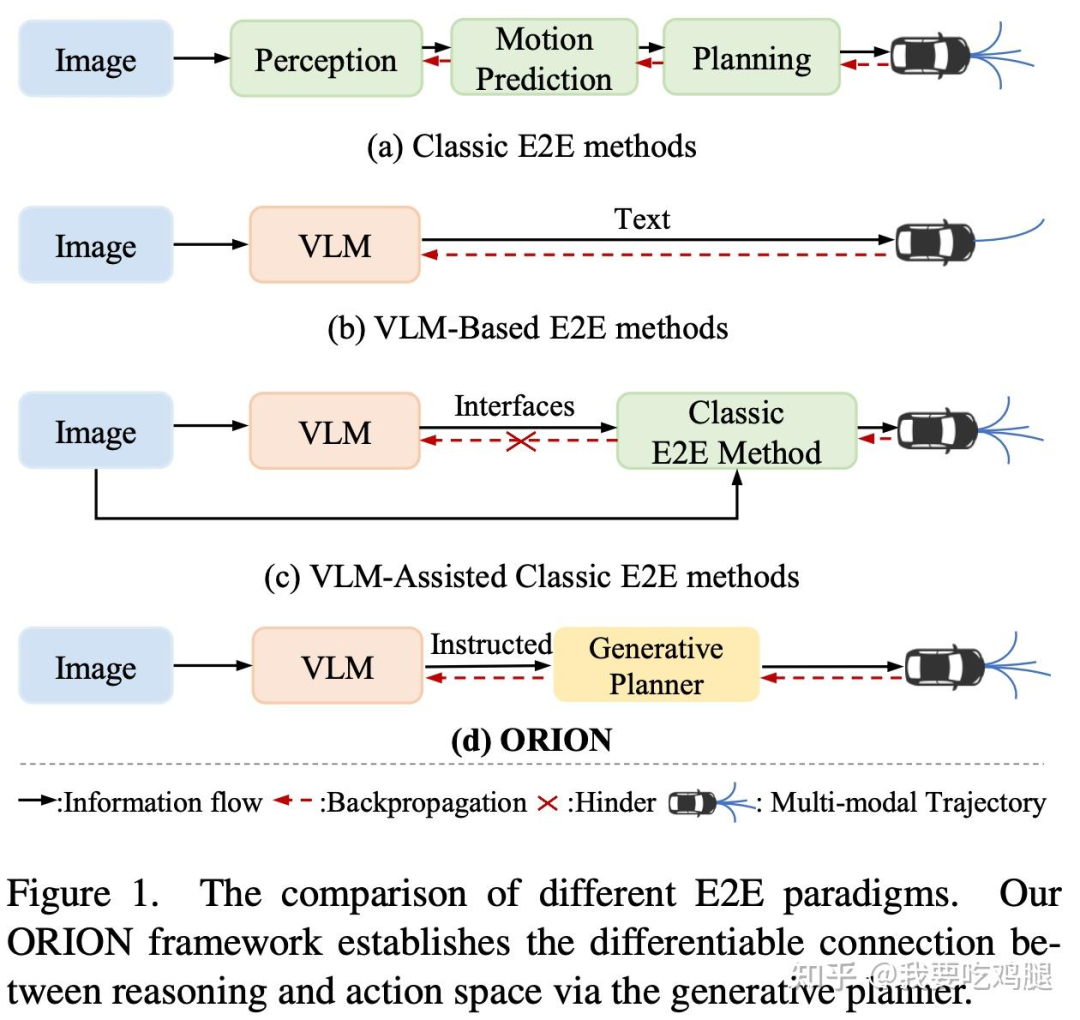
臃肿与信息损失: “慢系统”VLM如何“指导”“快系统”E2E?它无法直接传递“直觉”,只能通过低效的“符号”。比如,VLM输出一段文本,或者输出一条粗糙的“参考轨迹”,然后“快系统”再进行所谓的“轨迹优化”(Trajectory Refinement)。这就像一个“翻译”过程(见图1.2 (c)),不仅架构臃肿,而且在“翻译”过程中会丢失大量有价值的原始信息。
优化困难: 这两个系统是独立训练的。你无法将一个“慢系统”的VLM和一个“快系统”的E2E放在一起进行端到端的联合优化。如图1.1所示,这是一个“非全程可求导”的架构。驾驶失误的信号无法同时回传给两个系统,导致整个架构的迭代效率低下。
我们看一下图1.2 :(c) VLM-Assisted Classic E2E methods。这张图清晰地展示了“快慢双核”的拼凑架构,VLM通过一个低效的接口(Interfaces)与经典的E2E方法相连,反向传播(红色虚线)被阻断(X)。
因此,这种“快慢双核”系统,本质上只是一个“半”端到端的过渡形态。它虽然短暂地解决了有无问题,但其架构上的根本性缺陷,决定了它必然会被“真”端到端所取代。
1.3 VLA的“真”端到端
“快慢双核”的拼凑暴露了根本性的架构缺陷,而VLA(视觉-语言-行动)模型,正是为了彻底解决这些问题而生的。它不是对旧架构的修补,而是一次彻底的“颠覆性”重构。
VLA的“真”,首先体现在它在算法形式上,回归并坚守了从(传感输入)到(轨迹输出)的端到端神经网络形式。
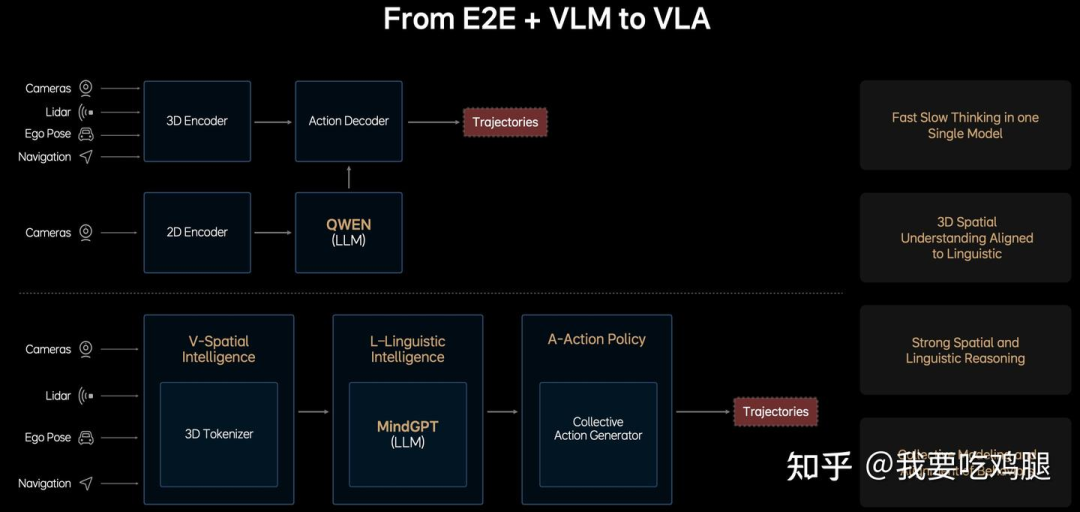
如上图所示,VLA不再是两个分裂的系统,而是一个统一的、单一的大模型。在这个模型中,视觉感知(V)、语言推理(L)和动作执行(A)被“融合”在了一起。
这种架构上的统一,带来了一个至关重要的特性,也是“真”端到端的核心标志:“全程可求导”(Fully Differentiable)。
“全程可求导”意味着,当车辆在现实中犯了一个错误(比如刹车晚了),这个“错误”的信号可以从最终的“轨迹”(Trajectories)输出端,一路无阻碍地反向传播(Backpropagation),穿过“行动策略”(A模块)、穿过“语言智能”(L模块),一直回溯到最开始的“空间智能”(V模块)。
这解决了“快慢双核”最大的痛点。它意味着VLA终于可以像最初的VA“老司机”模型一样,高效率、低成本地通过自动化的数据闭环(Data Loop)来实现驾驶数据的自我驱动和迭代。
那么,VLA是如何解决“快慢双核”之间低效的“符号”交流问题的呢?
答案是,VLA通过一个统一的内部表征,取代了L和V+A之间低效的“外部翻译”。在“快慢双核”系统中,语言模型(L)和行动模型(VA)是通过“符号”(如文本指令)来交流的,这个过程效率极低且损失了大量信息。
而在VLA这个统一模型中,V、L、A模块之间传递的不再是人类能理解的“文本符号”,而是一种模型内部的“软符号系统”(soft-symbol system)。大语言模型(LLM)在VLA中的工作方式,也不是真正进行人类意义上的“符号逻辑推理”,而是如GPT自己所说,它在底层是token prediction(令牌预测),但能“涌现”出“合理的思维链条”,这是一种“类推理能力”。
换言之,VLA内部的“思考”和“行动”是同一种“语言”(即Token)。L模块(语言智能)的输出——即“思考”的结果,直接就是A模块(行动策略)的输入——即“行动”的指令。这种内部的“类推理”token预测,远比“快慢双核”之间通过文本符号来回“翻译”要高效和保真得多。
这就是VLA的真正强大之处。它不是简单地把V、L、A三个积木粘在一起,而是把它们熔铸成了一个全新的合金。它既拥有了传统E2E模型的“全程可求导”的数据驱动能力,又在模型内部融合了大语言模型的“思维链”和“类推理能力”。
VLA=端到端的神经网络形式 + 大语言模型的推理能力
它终于成为了我们想要的那个,既能开、又能(在内部)“思考”的“真”端到端驾驶员。
二、VLA要解决的“VLM顽疾”:从“长尾场景”到“语义鸿沟”
VLA的出现,并不仅仅是为了追求更优雅的“全程可求导”架构。它的诞生,更是出于一种迫切的“必要性”——即为了解决上一代“快慢双核”(L+VA)架构暴露出的四大核心痛点。这些痛点,是VLM和E2E模型“强行拼凑”时必然产生的顽疾。
2.1 长尾场景的挑战:当“老司机”不认识字
自动驾驶面临的最大挑战,并非日常的直行和转弯,而是那些“出乎意料”的“长尾场景”(Corner Cases)。
对于传统的VA“老司机”模型(即基于找规律的数据驱动系统)而言,学习“左转右转”或“绕开一个坑”是容易的,因为这些驾驶行为在全世界的规律都相似。但当它面对一个写着“前方施工,请绕行”的临时手写木板时,它就束手无策了。
这就是“长尾场景”的核心:它们是高度语义化、非标准化、且极其多样化的。

上图仅仅揭开了冰山一角。中国的实际路况远比这更复杂:
复杂的龙门架: 一块指示牌上可能挤满了十几个箭头和地名。
可变车道: 需要根据不同时段的LED灯或指示牌来判断能否通行。
临时指示: 各种临时的、不规则摆放的锥桶和手写指示牌。
动态LED文本: 如“在安全原则下,红灯允许直行” 或“ETC故障,请走人工通道”。
对于VA“老司机”来说,这些充满了“文字”和“逻辑”的场景是它的知识盲区。它无法通过“找规律”的方式去学习这上百万种“如果”。
正是为了解决这个“老司机不认识字”的根本性问题,VLM(语言模型)才被引入到自动驾驶系统中。VLM的核心任务,就是去“阅读”和“理解”这些VA模型无法处理的复杂语义信息。然而,VLM的引入,虽然解决了“长尾”问题,却也带来了下面三个更为棘手的架构顽疾。
2.2 语义鸿沟(The Gap):当“大脑”的语言,“车轮”听不懂
VLM的引入虽然解决了“长尾场景”的“看懂”问题,但它也立即催生了一个更棘手的架构难题:“语义鸿沟”(Semantic Gap)。
VLM(无论是理想IM 还是其他VLM-Assisted方法)本质上是生活在一个“语义推理空间”(Semantic Reasoning Space)。它的输出是文本(Text),是逻辑和描述。例如,它会输出:“前方有行人,应减速”。
图1.2 中的 (b) VLM-Based E2E 和 (c) VLM-Assisted E2E 揭示了“鸿沟”所在。VLM的输出是“Text”(文本)或“Interfaces”(接口),而不是车辆能直接执行的动作,反向传播(红色虚线)因此被阻断。
然而,车辆的控制器(如方向盘、油门、刹车)并不生活在“语义空间”,而是生活在一个纯粹的、冷冰冰的“轨迹行动空间”(Action Space)。它需要的是一系列精确的、可执行的纯数值,例如:[转向角: -5.2°, 加速度: -2.1m/s², ...]。
“应减速”(一个文本字符串)和 [加速度: -2.1m/s²](一个物理数值向量)之间,存在着一条几乎无法跨越的“语义鸿沟”。
“快慢双核”系统 试图用一种笨拙的方式来“翻译”:让VLM(慢系统)输出一个粗略的指令(如文本或一条大致的轨迹),然后让E2E(快系统)去执行所谓的“轨迹优化”(Trajectory Refinement)。这就像一个“评论员”在电话里告诉“老司机”该如何打方向盘,这个过程不仅效率低下,而且充满了信息的损失和误解。这就是VLM架构下难以弥补的“行动鸿沟”。
2.3 空间精度不高:当“评论员”被强行要求“画图”
一个自然的想法是:既然“翻译”这么麻烦,我们能不能强行“教会”VLM,让它不输出文本,而是直接输出那串[x, y, z, ...]的轨迹数值呢?
答案是:可以,但效果很差。
VLM(尤其是那些基于LLM的VLM)的核心是“语言”和“逻辑”。它的整个世界是由“Token”(令牌)构建的。让一个以“Token”为基础的模型去生成高精度的、物理上连续的、空间几何上正确的驾驶轨迹,就像是强迫一个诗人去绘制一张CAD工程蓝图。
结果就是“空间精度不高”,“输出轨迹点是基于语言生成的,易产生偏差”。VLM或许能“理解”它应该向左转,但它“画”出来的这条左转轨迹可能是歪歪扭扭的、会切到马路牙子的、或者在加减速上是反物理的。
这种与生俱来的“偏差”意味着VLM(慢系统)永远无法被信任去直接操控车辆。它最多只能提供一个“大概的参考意见”,最后还是需要“快系统”E2E模型来收拾残局,进行实时的、高精度的轨迹生成。这进一步证明了“快慢双核”架构的臃肿和低效。
2.4 时序建模的瓶颈:当“大脑”只有三秒钟记忆
最后一个顽疾,是VLM在处理“时间”上的瓶颈。
驾驶决策不是一个静态的“看图说话”,而是一个动态的“时序分析”。你不仅要看到“现在”有一辆车,你还要知道它“5秒前”在哪里,“3秒前”是否在加速,以此来“预测”它“2秒后”会做什么。
传统的VLM(如LLaVA)在处理视频或时序任务时,采用的是一种简单粗暴的方法:叠加多帧的图像信息(Stacking Frames)。
这种方法在自动驾驶的复杂场景下,会立即导致两个灾难性的后果:
1. Token长度限制(Context Window Limit):
VLM“通过叠加多帧的图像信息完成时序建模,会受到 VLM 的 Token 长度限制”。一个LLM的上下文窗口(Context Window)是有限的。如果一帧图像需要消耗500个Token,那么一个8K的上下文窗口最多也就能装下16帧。如果以10Hz的频率计算,这连2秒钟的驾驶历史都存不下。这种“短暂的记忆”让VLM无法进行任何长时程的规划和博弈。
2. 巨大的计算开销(Computational Cost):
VLM(慢系统)本就运行缓慢。如果每一次“思考”都需要它去处理这叠加的十几帧图像,无疑是雪上加霜。这“会增加额外的计算开N销”,并进一步拉大了它与“快系统”(E2E)之间的频率差距,使得“快慢双核”的同步几乎成为不可能的任务。
综上所述,VLM的引入虽然解决了VA“老司机”不认识字的“长尾”问题,但它带来的“语义鸿沟”、“空间精度低”和“时序瓶颈”这三大顽疾,使得“快慢双核”的拼凑架构注定只是一个过渡。
自动驾驶需要一场彻底的革命,一个能同时解决这所有问题的“统一大脑”。这就是VLA诞生的使命。
三、VLA的通用技术栈:积木是如何搭建的?
VLA的“统一大脑”并非凭空产生的魔法,它更像是将过去十年中AI领域最顶尖的“乐高积木”——即那些在各自领域被验证为最强(SOTA)的模型组件以一种全新的方式拼装在了一起。
要真正理解VLA,我们就必须拆解它的“积木”。一个VLA模型(无论是用于自动驾驶还是机器人) 通常由三个核心技术组件构成:视觉编码器(V)、语言编码器(L)和动作解码器(A)。
本章,我们就来详细拆解这三大组件的“黄金标准”。
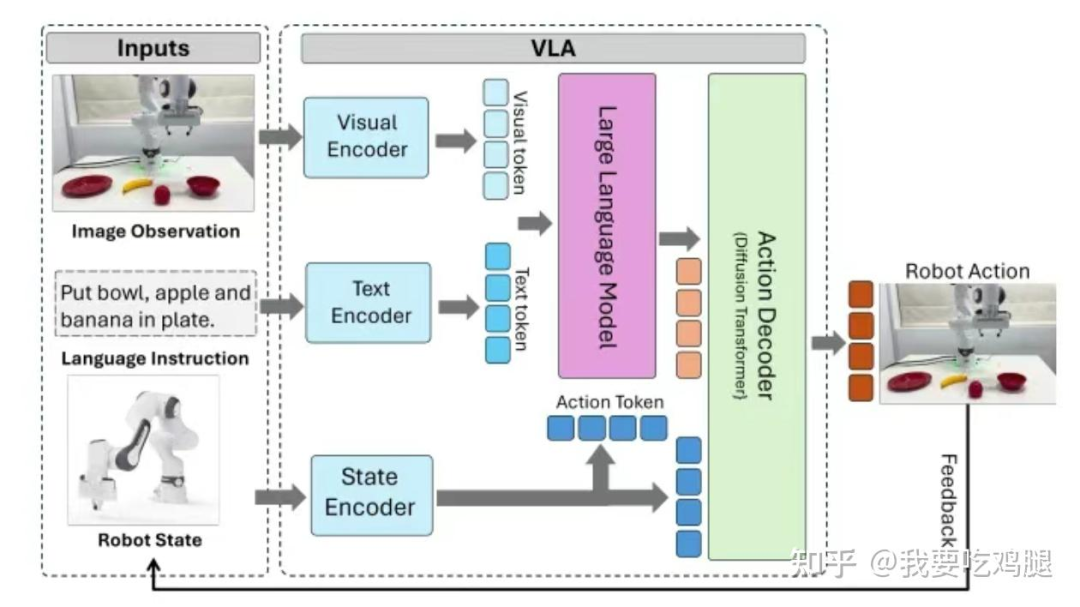
3.1 视觉编码器 (V):VLA的“眼睛”
VLA的“眼睛”,即视觉编码器(Visual Encoder),是整个系统的感知基石。它的核心任务是接收最原始的传感器输入(如摄像头图像),并将其“翻译”成“大脑”(L模块,即LLM)能够理解的“视觉令牌”(Visual Token) 或特征。
在当今的技术栈中,这个角色的最佳选择,几乎被ViT(Vision Transformer)及其变体所垄断。而ViT的强大,又来自于其特定的“预训练”方式。
目前,VLA领域最受青睐的ViT主要有两种:CLIP/SigLIP 和 DINOv2。它们各自为VLA提供了不可或缺的独特能力。
1. CLIP / SigLIP:提供“内容识别”能力 (“What is it?”)
核心功能:
CLIP(及其优化版SigLIP)的核心是 强大的视觉-文本对齐(visual-text alignment)能力。它擅长将图像中的像素与描述这些像素的自然语言单词联系起来。训练方式: 它们通过海量的“图像-文本”配对数据进行“对比学习”(Contrastive Learning)。简单来说,它们学习到了“这段文字描述的就是这张图片”。
SigLIP的优势:SigLIP是CLIP的直接升级版。它用更简单、扩展性更好的Sigmoid损失函数,取代了CLIP复杂的Softmax损失函数,训练过程更高效,且在更大规模数据集上表现更好,从而实现了“更简单,效果更好”。VLA中的角色:
SigLIP主要为VLA提供了“识别和描述图像内容” 的能力。它负责告诉“大脑”:“我看到了一个红色的瓶子”或“这是一条狗,脖子上有牵引绳”。
2. DINOv2:提供“空间理解”能力 (“Where is it? How is it positioned?”)
核心功能:DINOv2 的核心是强大的空间理解和高级视觉语义能力。训练方式: 它是一种自监督学习(Self-Supervised Learning)模型。它不需要文本标签,而是通过一种名为“自蒸馏”(self-distillation) 的方式进行训练。这种方式强迫模型去理解图像的内在空间结构(例如,一张猫的左耳和右耳在空间上的关系,即使没有任何文字告诉它这是“猫”或“耳朵”)。VLA中的角色:DINOv2主要为VLA提供了“空间推理能力”。它负责告诉“大脑”:“那个红色的瓶子在碗的左边,并且是竖立着的”,或者“那只狗正坐着,它的牵引绳延伸到了草地上”。
3. 顶尖方案:SigLIP + DINOv2 双编码器
既然SigLIP擅长“识别内容”(What),而DINOv2擅长“理解空间”(Where/How),那么最强大的VLA视觉系统,自然是将两者互补的优势结合起来。
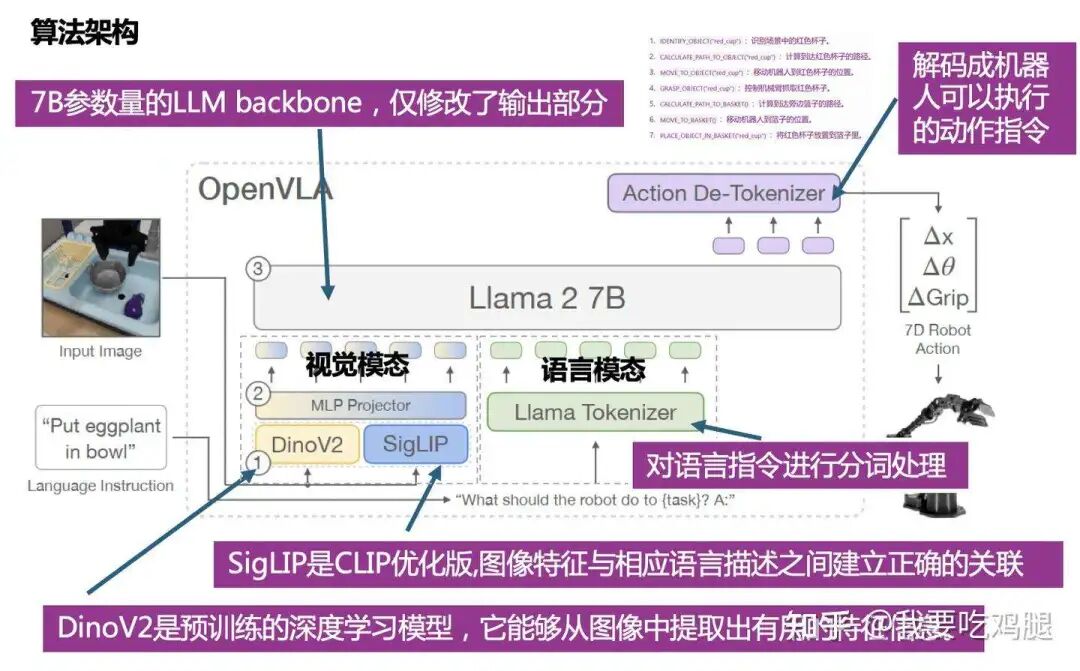
这正是OpenVLA、Prismatic-7B 等顶尖VLA模型所采用的“双编码器”策略:
并行编码: 原始图像被同时输入到SigLIP和DinoV2两个独立的视觉编码器中。
特征提取:SigLIP输出包含丰富“内容”信息的特征向量,DinoV2输出包含精确“空间”信息的特征向量。
特征融合: 这两种不同类型的特征向量在通道维度上被“连接”(Concatenated)在一起,形成一个同时包含“是什么”和“在哪里/怎么样”的“综合性的视觉表示”(comprehensive visual representation)。
模态对齐-关键步骤: 最后,这个“综合视觉特征”必须被“翻译”成“大脑”(L模块,即LLM)能够理解的“语言”。这个关键的“翻译”步骤由一个MLP Projector(多层感知机投影器) 完成。该投影器负责将高维的视觉特征向量,投影(映射)到与LLM处理文本时使用的相同的“令牌”(Token)嵌入空间中。
通过这种“双编码器 + MLP投影器” 的精密设计,VLA的“眼睛”就为“大脑”提供了最完美的输入:一个既知道“是什么”(来自SigLIP),也知道“在哪里/怎么样”(来自DinoV2)的、且“大脑”能够直接理解的视觉信息流。
理想汽车MindVLA的实现方式:拥抱3D高斯建模 (3DGS)
值得注意的是,SigLIP + DINOv2 虽然是通用VLA中的顶尖方案,但并非唯一选择。
理想汽车的MindVLA在其V-Spatial Intelligence(空间智能)模块 上,采取了另一条更侧重于高保真3D重建的技术路线。
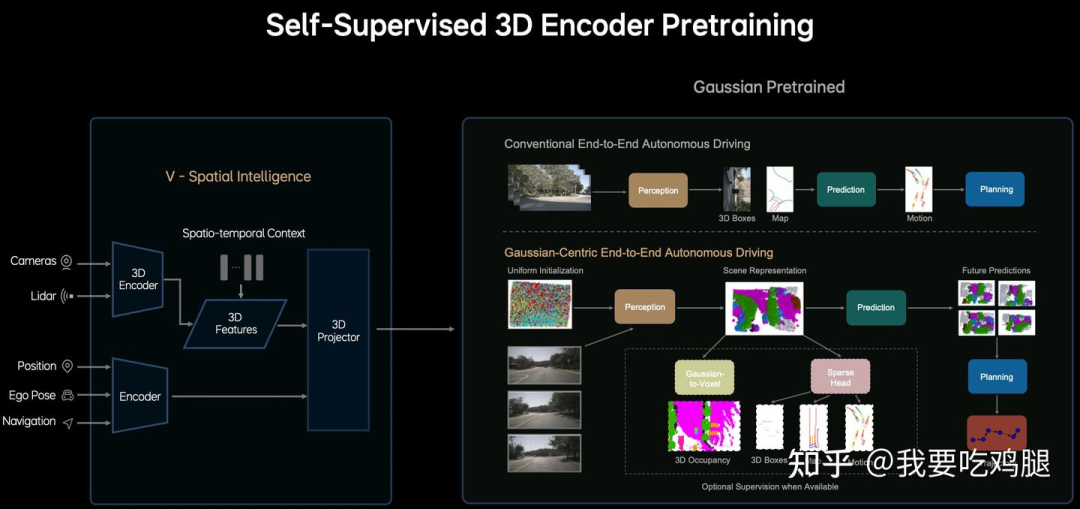
MindVLA的V模块核心是:
3D高斯建模-3D Gaussian Splatting, 3DGS:它没有使用SigLIP或DINOv2,而是直接采用了基于3D高斯球的场景表示方法。这种方法旨在从多视图2D图像中,重建出更精细、更连续的3D场景。
自监督3D编码器预训练-Self-Supervised 3D Encoder Pretraining:其V模块通过自监督的方式,直接从传感器数据(包括摄像头Cameras, 激光雷达Lidar等)通过3D Encoder 生成统一的Scene Representation(场景表示)。
3D Tokenizer / 3D Projector:最终,这个基于3DGS的场景表示,通过3D Projector(3D投影器) 或3D Tokenizer 被转换为MindGPT(L模块) 可以理解的Token。
对比总结:
通用方案-SigLIP + DINOv2: 更侧重于从2D图像中提取内容和空间语义,并通过MLP投影器与LLM对齐。
MindVLA方案-3DGS: 更侧重于直接进行高保真的3D场景重建,为“从零预训练”的L模块提供更原生、更丰富的3D空间输入。
这两种不同的V模块实现路径,也反映了VLA架构仍在快速发展,不同的团队在根据自身的技术积累和目标进行着不同的探索。
3.2 语言编码器 (L):VLA的“大脑”
如果说V模块(视觉编码器)是VLA的“眼睛”,那么L模块(语言编码器,即LLM)就是VLA的“大脑”。
这个“大脑”是整个系统的“决策中枢”。它的核心任务不再是像ChatGPT一样“聊天”,而是接收来自“眼睛”(V模块)的视觉令牌(Visual Token) 和来自用户的文本令牌(Text Token),在模型内部将这两者“融合”(Fuse),并进行复杂的跨模态推理(Cross-modal Reasoning)。
3.2.1 “大脑”的主流选择:LLaMA家族与Qwen等
正如V模块被ViT及其变体所统治,L模块(语言领域)目前的主流选择也相对集中。
LLaMA家族(核心主导): 这是目前VLA领域的绝对主流。
LLaMA-2:被广泛认为是开源VLA模型的“标配”。例如,OpenVLA 和 Prismatic-7B 都明确使用了Llama 2 7B 作为其语言主干(backbone)。
Vicuna:作为LLaMA最著名的微调变体之一,Vicuna因其强大的对话和推理能力而被广泛采用。ORION 架构的LLM就是Vicuna v1.5。
Qwen系列(重要力量): 阿里巴巴的Qwen系列也在VLA领域扮演着重要角色。
OpenDriveVLA使用了Qwen-2.5。
SimLingo使用了Qwen-2。
Impromptu VLA和AutoVLA则都采用了Qwen-2.5VL。理想汽车早期IM系统也使用了基于Qwen(千问)的VLM。
其他家族(展现多样性): 当然,GPT系列和Gemma等也在VLA模型中占有一席之地,验证了VLA架构的灵活性。
EMMA使用了Gemini。
LangCoop使用了GPT-4o。
VaVIM使用了GPT-2。
Pi-0和FAST模型使用了Gemma-2B。
3.2.2 “大脑”是如何工作的?—— 融合与推理
L模块的工作流程(以OpenVLA 和 ORION 为例)非常精妙:
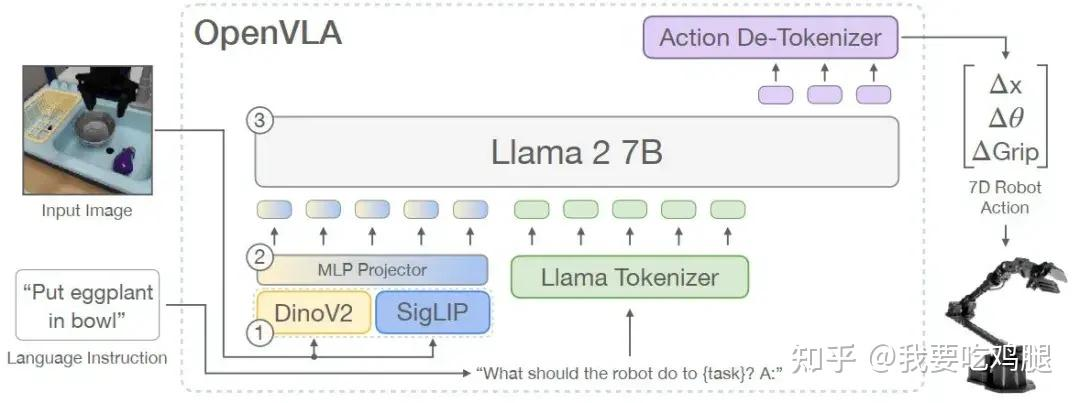
图注:OpenVLA的L模块(Llama 2 7B) 接收两路输入:一路是来自Llama Tokenizer的“文本指令”,另一路是来自MLP Projector的“视觉特征”。
融合(Fusion): L模块(LLM)的输入是一个组合序列。这个序列的前半部分是来自“眼睛”(V模块)的视觉Token(即被MLP Projector“翻译”过的视觉特征),后半部分是来自“用户”的文本Token(例如“Put eggplant in bowl”,即“把茄子放进碗里”)。
推理(Reasoning): 一旦输入融合,LLM就会像处理普通文本一样,在“视觉”和“文本”Token之间进行复杂的“自注意力”(Self-Attention)计算。
在ORION 这样的高级架构中,L模块的输入甚至还包括了来自QT-Former 的“历史Token”。
此时,LLM会执行后续的高级推理任务,如“场景分析”(Scene Analysis)、“动作推理”(Action Reasoning)和“历史回顾”(History Review)。
3.2.3 “大脑”的输出:从“思考”到“指令”
VLA“大脑”的革命性在于它的输出。
它输出的不是用于聊天的文本,而是一个(或一系列)高度浓缩的、机器可读的“动作令牌”(Action Token) 或“规划令牌”(Planning Token)。
这个“Token”就是L模块(大脑)“思考”的最终结晶。它代表了一个明确的“意图”或“决策”(例如“抓取红色物体”或“执行减速让行策略”)。这个“意图”将被传递给A模块(“手脚”),由A模块去解码和执行。
3.2.4 “大脑”的优化:LoRA与MoE
在车端或机器人上部署一个70亿(7B)参数的LLM 是一个巨大的工程挑战。为了让“大脑”既聪明又高效,业界采用了两种主流的优化策略:
LoRA-Low-Rank Adaptation: 这是ORION(小米的实现) 采取的策略 。即冻结(Frozen) 庞大的Vicuna 主体参数,只在旁边“外挂”一个极小的、可训练的LoRA适配器。这使得VLA的微调成本和部署灵活性大大降低,是一种“轻量化”的改装方案 。
这里面理想汽车MindVLA的与ORION 等模型采用开源LLM(如Vicuna )+ LoRA 轻量化微调的“改装”路线不同,理想汽车的MindVLA 选择了更彻底的“从零开始打造LLM” 的“自研”路线,其L模块被称为MindGPT。
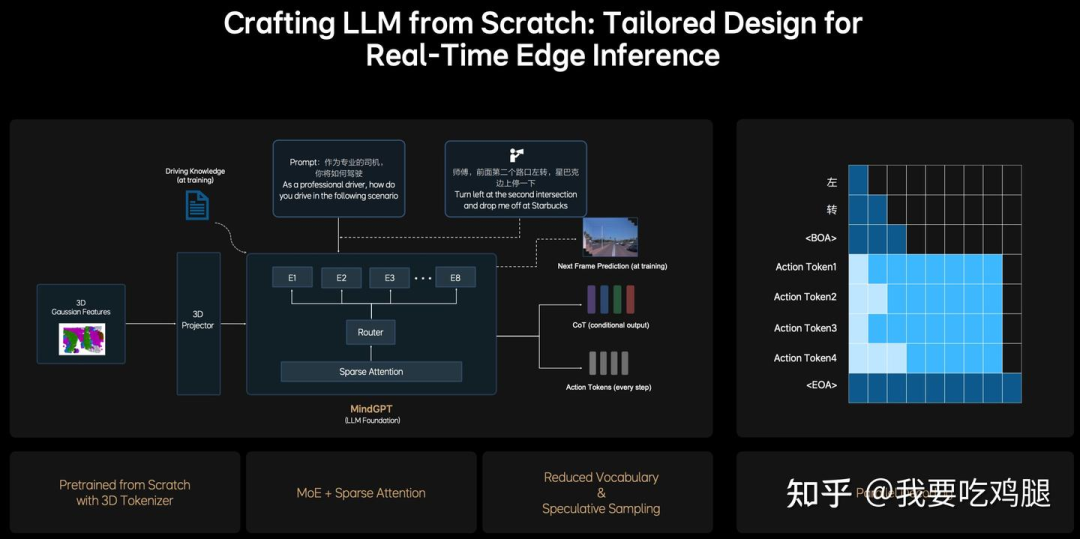
MindGPT 的核心特点在于其针对3D驾驶场景的原生设计:
原生3D输入:MindGPT的输入不是经过MLP Projector “翻译”的2D图像特征,而是来自V模块 的、通过3D Projector 或3D Tokenizer 处理的“3D高斯特征”(3D Gaussian Features)。它的“母语”就是3D空间。
面向驾驶的预训练:MindGPT在预训练阶段就学习驾驶相关的物理因果律,例如通过“未来帧预测”(Next Frame Prediction) 和“CoT(条件输出)” 等任务进行训练。
为车端优化的架构: 为了在车端芯片上实现实时推理,MindGPT内部采用了MoE(混合专家)+ 稀疏注意力(Sparse Attention) 架构,通过Router(路由器) 实现稀疏激活,大幅降低了计算量。
高效动作输出: 在输出“Action Tokens”(动作令牌) 时,MindGPT采用了“并行解码”(Parallel Decoding) 技术,在一个步骤内同时生成所有动作指令(如转向、油门等),满足了实时性要求。
对比总结:
通用方案-如ORION: 通常采用开源LLM + LoRA微调。优点是开发速度快,可利用社区成果;缺点是LLM底层可能缺乏对3D物理世界的原生理解。
MindVLA方案-MindGPT: 采用从零预训练。优点是模型天生为3D驾驶设计,与V模块(3DGS) 结合更紧密,性能潜力可能更高;缺点是研发投入巨大。
3.3 动作解码器 (A):VLA的“手脚”
当“眼睛”(V模块)完成了高保真的3D感知,“大脑”(L模块)也完成了复杂的跨模态推理 并输出了一个抽象的“指令”——即“动作令牌”(Action Token)或“规划令牌”(Planning Token)之后,VLA就进入了最后,也是最关键的一步:执行。
“动作解码器”(Action Decoder, A模块) 就是VLA的“手脚”。
它的核心任务,就是接收来自“大脑”(L模块)的那个高度浓缩的“意图”Token,并将其“解码”(Decode) 成一系列真实、物理、可执行的控制信号,例如机器人的[Δx, Δθ, ΔGrip](7D动作) 或自动驾驶的“Trajectories”(轨迹)。
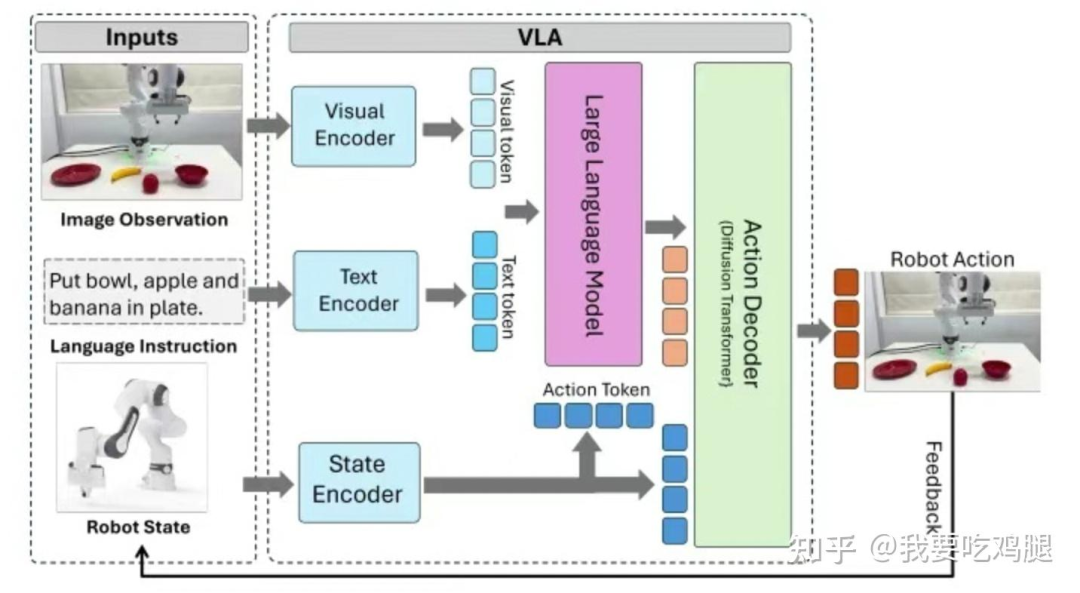
在VLA的技术栈中,实现这个“解码器”有多种路径,但其中一种因其卓越的性能而成为当今的“黄金标准”。
3.3.1 “黄金标准”:基于扩散的Transformer(Diffusion Transformer)
在所有技术中,“基于扩散的Transformer”(Diffusion-based Transformer)是目前VLA模型中“最受青睐”(most favored)的动作解码器方案。
代表模型:Octo、理想汽车的MindVLA(其A-Action Policy核心就是一个“Diffusion Decoder”) 以及小米/华科的ORION(它也将Diffusion作为一个核心的“Generative Planner”选项) 都采用了这一思路。
为何是它? 因为Diffusion模型(AIGC绘画的核心技术)极其擅长“建模复杂多模态动作分布”。
解释: 驾驶或机器人操作往往不是一个“唯一解”。面对一个障碍物,你可以“向左绕一点”、“向左绕很多”或者“减速等待”。Diffusion模型天生就能理解并生成这种“多模态”的概率分布,而不是只给出一个僵硬的单一答案。
如何工作? 它通过一种名为“迭代去噪”(Iterative Denoising) 的方式工作。
流程: 从一堆随机的“噪声”(Noise) 出发,在“大脑”(L模块)输出的“Action Token”或“Planning Token”的约束和引导下,逐步将噪声“还原”成一条(或多条)符合意图的、最优的轨迹。
核心优势: 这种“生成式”的轨迹,具有无与伦比的“细粒度”和“平滑控制”(fine-grained, smooth control)能力。
“拟人化”轨迹: 这完美地呼应了MindVLA的目标——生成“拟人化”的、“如丝般顺滑”的“黄金轨迹”。正如理想工程师所比喻的“旋轮线”,Diffusion寻找的是物理上最优、最舒适的“变分函数”解,而不是简单的代数曲线。
工程挑战: Diffusion虽然强大,但“迭代去噪”天生就很慢。为了解决这个问题,MindVLA等架构采用了ODE Sampler(常微分方程采样器) 等技术,将“去噪”步骤从几百步压缩到“2到3步”,从而满足了实时控制的需求。
解决方案 (以MindVLA为例): 为了解决这个速度瓶颈,MindVLA等架构采用了ODE Sampler(常微分方程采样器) 等先进的采样技术。
效果: 这些技术极大地加速了Diffusion的生成过程。它们不再需要“成百上千步”,而是可以将轨迹的“收敛”压缩到“大概2到3步内完成”。这个工程上的突破,才使得Diffusion这个强大的生成模型,终于得以被应用于需要实时控制的自动驾驶和机器人领域。
3.3.2 其他主流方案
虽然Diffusion是“顶配”,但在不同的VLA模型中,也存在其他更简洁、更高效的解码器方案:
自回归Transformer头(Autoregressive Transformer Head):
代表模型:Gato。
工作方式:这种解码器就像LLM“写作文”一样,一个Token一个Token地“逐步生成动作序列”。例如,它会先生成“转向Token”,再生成“油门Token”……
核心优势:这种方式非常适合“优化实时响应”。
MLP预测器头(MLP Predictor Head):
代表模型:OpenVLA。
工作方式:这是最简单直接的方案。L模块输出的“Action Token”,被直接送入一个简单的MLP(多层感知机,即Action De-Tokenizer),由这个MLP直接“映射”出最终的[Δx, Δθ, ΔGrip] 等控制数值。
核心优势:“实现高效低级控制”。它极其轻量,计算速度飞快。ORION的消融实验也将“MLP with Planning Token”作为了一个重要的对比基线。
嵌入式MPC/规划头(Embedded MPC / Planning Head):
代表模型:VoxPoser。
工作方式: VLA的L模块(大脑)不输出具体动作,而是输出一个“目标状态”,然后由一个经典的“模型预测控制”(MPC)或“规划头”来解算这个目标。
核心优势:“支持动态决策”,能很好地与传统的、经过安全验证的控制理论相结合。
从简单的MLP,到实时的自回归,再到最强大、最受青睐的Diffusion Transformer,“动作解码器”(A模块)是VLA的最终执行者,负责将“大脑”的意图转化为物理世界的精确动作。理想汽车MindVLA 通过采用先进的Diffusion Transformer 并结合ODE Sampler 加速技术,力求在生成质量和实时性之间达到最佳平衡。
至此,VLA的“积木”已全部分解完毕:它用强大的视觉编码器(如3DGS 或SigLIP+DINOv2)作为“眼睛”,用LLaMA 或自研模型(如MindGPT)作为“大脑”,用先进的动作解码器(如Diffusion Transformer)作为“手脚”。这些最强组件的融合,构建出了这个革命性的“统一大脑”。
四、VLA的四个进化阶段:从“驾驶解释器”到“决策核心”
VLA架构的演进并非一蹴而就,而是经历了一个清晰的、逐步“赋权”的过程。语言(Language)在自动驾驶系统中的角色,经历了从一个被动的“旁观者”,到主动的“规划者”,最终演变为具备推理能力的“决策核心”。
根据麦吉尔大学和清华大学等机构的权威综述,我们可以将VLA的发展划分为四个清晰的阶段。
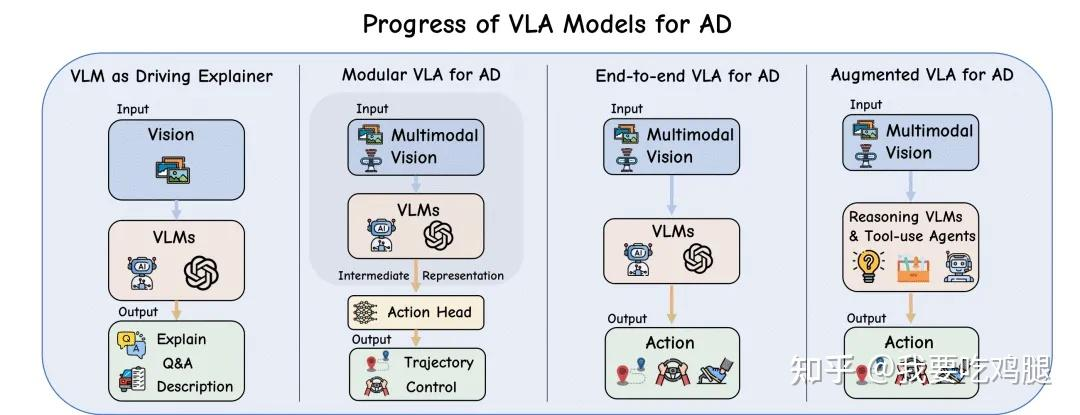
阶段一:语言模型作为“解释器” (Pre-VLA: Language Model as Explainer)
在最初的探索阶段(Pre-VLA),语言模型被用作一个被动的、用于描述的工具,其核心目标只有一个:增强自动驾驶系统的可解释性。
这一阶段的系统,就是我们前文提到的“评论员”。
典型架构: 这一阶段的系统通常采用一个冻结的视觉模型(如 CLIP)和一个LLM解码器(如 LLaMA-2)。
工作流程: 如图4.1中的第一副图所示,系统感知到驾驶场景(Vision)后,将图像特征喂给视觉语言模型(VLMs),模型并不参与任何车辆控制。
核心输出: 其输出是纯粹的文本,如“解释”(Explain)、“问答”(Q&A)或“场景描述”(Description)。
DriveGPT-4 是这个阶段的典型代表。它可以接收来自前置摄像头的单张图像,然后生成一个高阶的操纵标签(如“减速”、“左转”)或一段场景描述。
这些文本输出,极大地帮助了人类工程师去理解感知系统“看到”了什么,或者E2E“黑箱”模型“打算”做什么,从而提升了系统的透明度。
然而,这个阶段的局限性也是显而易见的:一个根本性的“语义鸿沟”(或者说“行动鸿沟”)依然存在。正如之前所说的:“描述场景不等于生成精确的驾驶指令”。这个“评论员”的角色,使其在驾驶任务上更像是一个“局外人”,对解决实际的驾驶问题帮助有限。
阶段二:模块化VLA模型 (Modular VLA Models for AD)
随着研究的深入,语言的角色开始发生关键转变。它不再仅仅是一个被动的场景“评论员”,而是演变为模块化架构中一个主动的规划组件。
在这一阶段,语言的输入和输出开始直接为规划决策提供信息。其核心思想是,语言成为了连接“高级指令”与“车辆执行”之间的一个可解释的中间环节。
典型架构: 如图4.1中的第二幅图所示,系统接收多模态视觉输入(Multimodal Vision),VLM(视觉语言模型)不再只是对外输出文本,而是生成一个“中间表示”(Intermediate Representation)。这个中间表示随后被送入一个独立的“动作头”(Action Head),最终由动作头输出“轨迹”(Trajectory)或“控制”(Control)信号。
工作流程: 感知 -> 语言规划 -> 动作执行。
这一阶段涌现了许多创新的代表作:
OpenDriveVLA:它能融合摄像头、激光雷达和文本路径指令(例如“在教堂右转”),然后VLM会生成人类可读的中间路径点(例如“20米后右转,然后直行”),这些路径点最后被下游的控制器转换为连续的轨迹。
DriveMoE:它采用混合专家(Mixture-of-Experts)架构。VLM会利用语言线索(例如分析场景是“高速超车”还是“拥堵跟车”),来动态地选择最合适的子规划器(例如“超车专家”或“启停专家”)。
RAG-Driver:它提出了一种检索增强(RAG)的规划机制。当遇到模糊或长尾场景时,系统会从记忆库中“检索”相似的历史驾驶案例,用以指导当前的决策。
尽管这些模块化方法显著缩小了语言指令和车辆动作之间的“语义差距”,但它们的根本缺陷也暴露无遗:它们严重依赖于多阶段的处理流程。
这种“感知 -> 语言规划 -> 动作执行”的串联管道,不仅会引入显著的计算延迟(这在高速驾驶中是致命的),而且在每个模块的交界处都带来了“级联错误”(Cascading Errors)的风险。
换句话说,如果第一阶段的VLM对场景的理解(中间表示)出了哪怕一点小错,这个错误也会被传递并放大到第二阶段的“动作头”,导致最终输出一个灾难性的驾驶轨迹——即使“动作头”本身的功能是完美的。这个“翻译”过程中的信息损失和错误累积,是模块化VLA无法克服的硬伤。
阶段三:统一的端到端VLA模型 (Unified End-to-End VLA Models for AD)
模块化VLA暴露出的“延迟”和“级联错误”问题,促使研究者们寻求一个更彻底的解决方案。受益于(如Gemini)等大型多模态基础模型的出现,自动驾驶的范式演进到了第三阶段——构建完全统一的端到端网络。
这一阶段的核心思想是:在一个单一的、可微分的系统中,无缝整合感知、语言理解和动作生成。
典型架构: 如图4.1中的第三幅图所示,阶段二的“VLM”和“动作头”这两个分离的模块被合并成了一个单一的“VLMs”大模型。
工作流程: 不再有“中间表示”或“多阶段”处理。模型在一个单一的前向传播(single forward pass)中,就能将多模态的传感器输入(以及可选的文本指令)直接映射到最终的轨迹(Trajectory)或控制信号(Action)。
这个架构的代表作包括 EMMA、LMDrive、CarLLaVA 和 SimLingo。
其中,LMDrive 和 CarLLaVA 等模型为了实现这种直接映射,甚至在CARLA模拟器中进行微调,并引入了一种名为“行动构想”(Action Dreaming)的创新训练技术:
在训练时,模型会通过“想象”来学习。例如,在同一个驾驶场景下,研究者会给模型两个相反的指令,如“保持车道”和“向左变道”。模型被要求在这两个不同指令下“构想”出两条截然不同的未来轨迹。
这种“行动构想”技术,强制性地在模型的语言理解(“向左变道”)和其最终的轨迹输出(一条向左的曲线)之间建立了紧密的因果耦合。这使得模型真正学会了“听懂人话”并将其转化为精确的驾驶动作,而不是像阶段二那样仅仅是“翻译”指令。
核心局限性:
统一的端到端VLA模型虽然反应灵敏,在“感觉运动映射”(sensorimotor mapping)——即“所见即所动”的反应能力上表现出色,但一个新的瓶颈也随之出现。
这些模型擅长执行明确的、即时的指令,但它们在长时程规划(例如,需要提前几百米就规划好如何通过一个复杂的施工区)和提供细粒度的决策解释(例如,详细说明为什么它选择等待而不是抢行)方面,仍然存在明显困难。
它们就像是反应很快的“士兵”,但还不是能够深谋远虑的“指挥官”。这一局限性,直接催生了VLA的第四个、也是目前最前沿的进化阶段。
阶段四:推理增强的VLA模型 (Reasoning-Augmented VLA Models for AD)
这是VLA发展至今最新、最前沿的浪潮。它将VLM/LLM从一个“执行组件”彻底提升为整个自动驾驶系统的“决策核心”。
在这一阶段,系统不再仅仅是对传感器输入的“被动反应”,而是被赋予了“思考”的能力。模型在输出任何一个驾驶动作之前,都能够进行解释、预测和长时程的推理。
核心思想: 将“思维链”(Chain-of-Thought, CoT)与“行动”(Action)进行端到端的对齐。VLA必须在行动之前,先用语言(或内部Token)表达其决策路径,即“先想明白,再行动”。
典型架构: 如图4.1中的第四幅图所示,这一阶段的架构演变为“推理VLM与工具使用代理”(Reasoning VLMs & Tool-use Agents)。VLM不再只是一个模型,而是一个可以调用“工具”(如记忆库、规划器)的“智能代理”(Agent)。
这一阶段的代表作,如 ORION、Impromptu VLA 和 AutoVLA,真正展现了“可解释的大脑”是如何工作的:
ORION:它引入了一个名为 QT-Former 的Transformer记忆模块,可以存储并聚合长达数分钟的观察和动作历史。它的LLM核心会负责“总结”这段历史,并同时输出下一段轨迹和一个相应的自然语言解释(例如:“因为我刚才在历史中看到了那辆车一直在变道,所以我现在选择拉开距离”)。
ORION 的关键创新在于,它使用VLM生成一个抽象的“规划Token”来弥合“语义鸿沟”。这个“规划Token”既是VLM推理(CoT)的结果,又是下游生成模型(A模块)生成轨迹的“条件”(Condition),从而将推理和动作完美地对齐。
Impromptu VLA:这个模型将“CoT与行动对齐”做到了极致。它的训练集不再是简单的(视频+动作),而是专门收集了8万个带有“专家驾驶推理步骤”标注的“犄角旮旯”(corner-case)场景。
例如,一份训练数据可能是:“(CoT:前方有救护车在闪灯,虽然是红灯,但交规允许避让)->(Action:缓慢压线绕行)”。
通过学习这种“先思考、后行动”的专家范例,Impromptu VLA 在零样本(Zero-shot)的车辆任务中达到了业界顶尖水平(SOTA)。
AutoVLA:它则在一个单一的自回归Transformer中,天才般地融合了CoT推理和轨迹规划。
AutoVLA 的创新之处在于将连续的路径点“令牌化”(Tokenize),变成了离散的“驾驶令牌”(Driving Tokens)。
这使得LLM可以在同一个输出序列中,既生成“文本令牌”(CoT推理),又生成“驾驶令牌”(轨迹规划)。例如,一个输出序列可能是:“[
CoT: 前方车辆刹车灯亮了,我需要减速][DrivingToken: 加速度-2.5][DrivingToken: 转向0.0] ...”。
第四阶段的VLA系统,预示了未来“可对话的自动驾驶汽车”的到来。你可以实时地质问它“你为什么要变道?”,它会立即用自然语言口头解释自己的行为,然而,这种强大的推理能力也带来了全新的挑战:
我们如何高效地索引和查询城市规模的记忆库(如 ORION 的 QT-Former)?
我们如何将LLM复杂的“思维链”推理(CoT)压缩在30Hz(约33毫秒)的实时控制循环内完成?
以及最关键的:我们如何对这种由“自然语言”调节的驾驶策略进行形式化的安全验证?
这些都是我们后续需要解决的问题,下一篇的会给大家介绍一下理想的VLA的具体实现方式。
自动驾驶之心
端到端与VLA自动驾驶小班课!

添加助理咨询课程!

知识星球交流社区


















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









