




这两天,看到社群里持续分享各种Google Gemini画图的玩法,确实为他们的脑洞感到震惊,原来画图可以有这么多玩法!昨天晚上自己也去体验了一把,确实惊艳,这对于我这种不会P图的人来说,简直是福音,怕是有一大波设计师又要焦虑了!
先给大家看看效果:
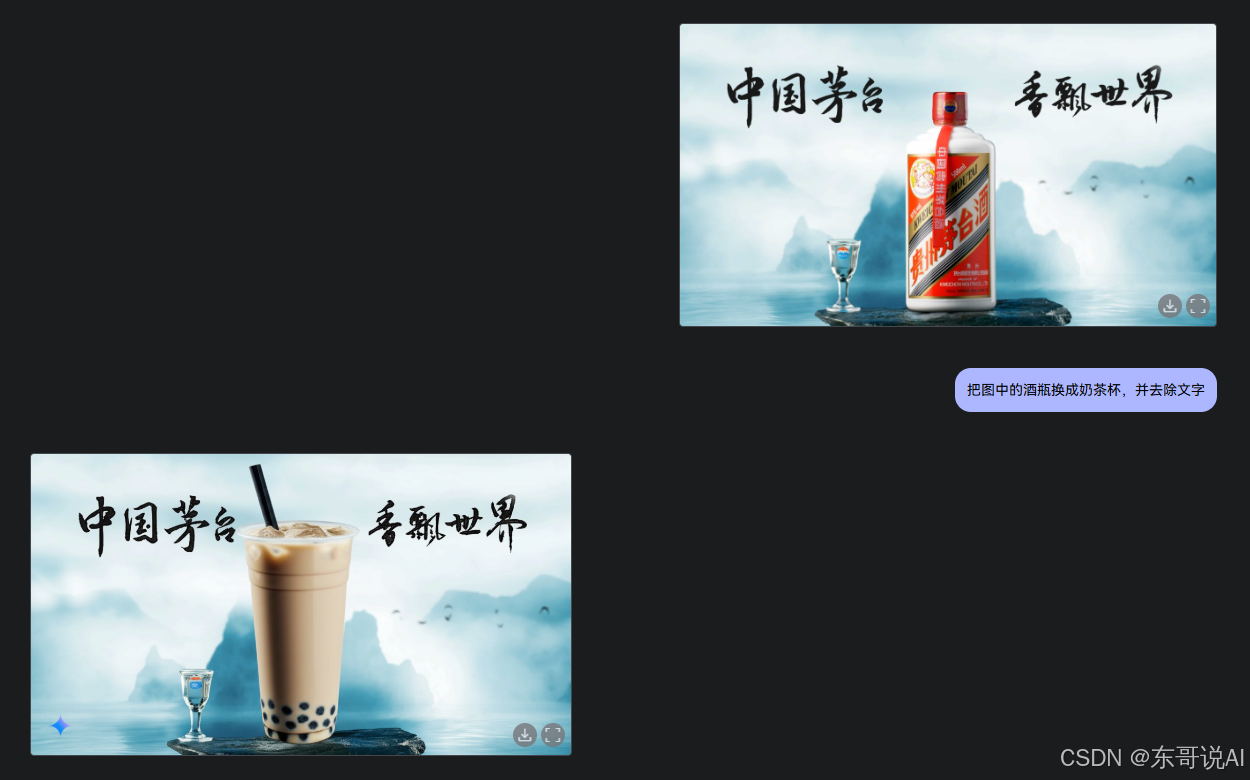
话不多说,先直接给大家上链接:
https://aistudio.google.com/
打开后会看到这个界面(需要魔法):
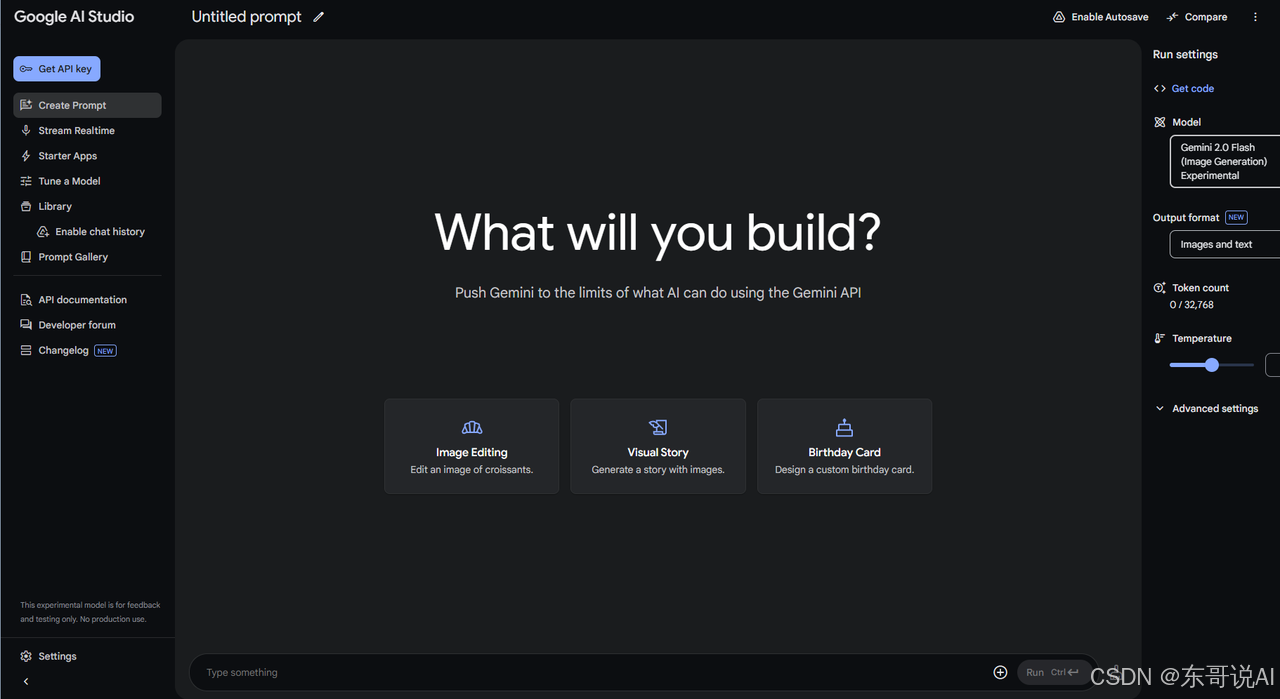
通过简单的设置即可体验用嘴画图:
先选择模型Gemini 2.0 Flash Experimental:
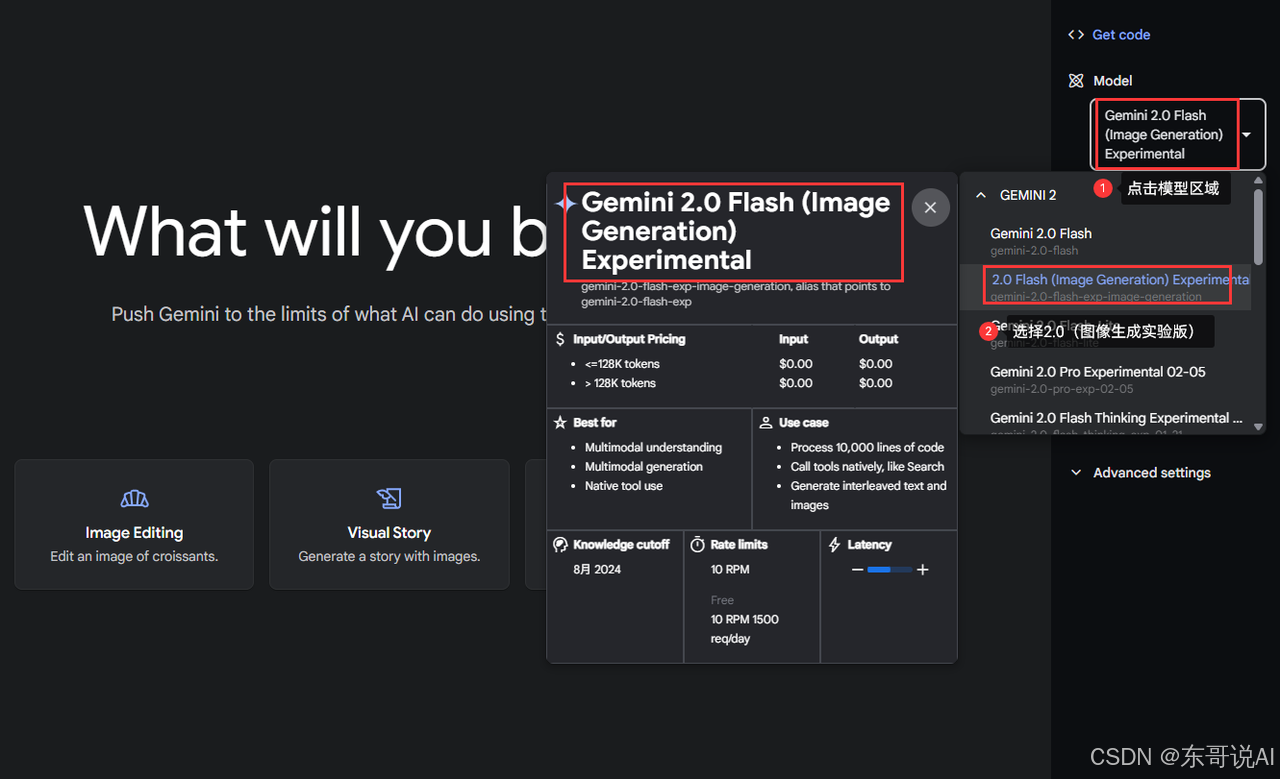
再选择输出格式,必须选择Images and text,这样才能输出图片:

设置好之后就可以愉快地体验画图、修图了。
给大家分享一些有趣的玩法。
1.一句话生成个人专属头像
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3299
3299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











