




点击卡片“大数据实战演练”,选择“设为星标”或“置顶”
回复“资料”可领取独家整理的大数据学习资料!
回复“Ambari知识库”可领取独家整理的Ambari学习资料!

大家好,我是EDP团队成员,今天给大家分享下 Ambari Metrics 监控无数据的排查过程,最终监视数据已正常显示,希望我接下来的分享给大家带来一些帮助和启发🤔
一、前言
本文主要分享如何排查 ambari 监控无数据的相关问题,其他监控都可以参考,本次分享以 kafka 监控数据不显示为例,提供一种排查思路。
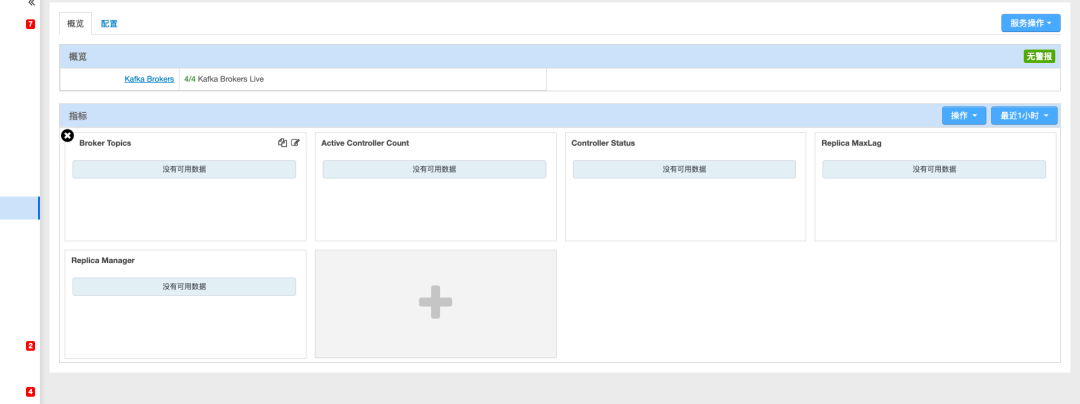
二、排查思路
1、抓取前端请求看是否有数据,判断问题是前端还是在后端
浏览器 F12 看下请求的接口:
http://10.201.60.183:8080/api/v1/clusters/clusterTest/services/KAFKA/components/KAFKA_BROKER?fields=metrics/kafka/server/BrokerTopicMetrics/AllTopicsBytesInPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/BrokerTopicMetrics/AllTopicsBytesOutPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/BrokerTopicMetrics/AllTopicsMessagesInPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/controller/KafkaController/ActiveControllerCount._sum[1654673428,1654677028,15],metrics/kafka/controller/ControllerStats/LeaderElectionRateAndTimeMs/1MinuteRate[1654673428,1654677028,15],metrics/kafka/controller/ControllerStats/UncleanLeaderElectionsPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/ReplicaFetcherManager/Replica-MaxLag[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/PartitionCount._sum[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/UnderReplicatedPartitions[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/LeaderCount._sum[1654673428,1654677028,15]&format=null_padding&_=1654677025364Response 没有返回监控数据:
{
"href" : "http://10.201.60.183:8080/api/v1/clusters/clusterTest/services/KAFKA/components/KAFKA_BROKER?fields=metrics/kafka/server/BrokerTopicMetrics/AllTopicsBytesInPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/BrokerTopicMetrics/AllTopicsBytesOutPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/BrokerTopicMetrics/AllTopicsMessagesInPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/controller/KafkaController/ActiveControllerCount._sum[1654673428,1654677028,15],metrics/kafka/controller/ControllerStats/LeaderElectionRateAndTimeMs/1MinuteRate[1654673428,1654677028,15],metrics/kafka/controller/ControllerStats/UncleanLeaderElectionsPerSec/1MinuteRate[1654673428,1654677028,15],metrics/kafka/server/ReplicaFetcherManager/Replica-MaxLag[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/PartitionCount._sum[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/UnderReplicatedPartitions[1654673428,1654677028,15],metrics/kafka/server/ReplicaManager/LeaderCount._sum[1654673428,1654677028,15]&format=null_padding&_=1654677025364",
"ServiceComponentInfo" : {
"cluster_name" : "clusterTest",
"component_name" : "KAFKA_BROKER",
"service_name" : "KAFKA"
}
}总结:经过抓取后发现 ams 后端未返回监控数据。
2、查询底层存储是否有数据,判断是没有数据,还是 ams 自身因为不兼容过滤等逻辑处理的问题
前往 ambari metrics collector 所在的节点,执行以下命令(61181 端口由 hbase.zookeeper.property.clientPort 配置):
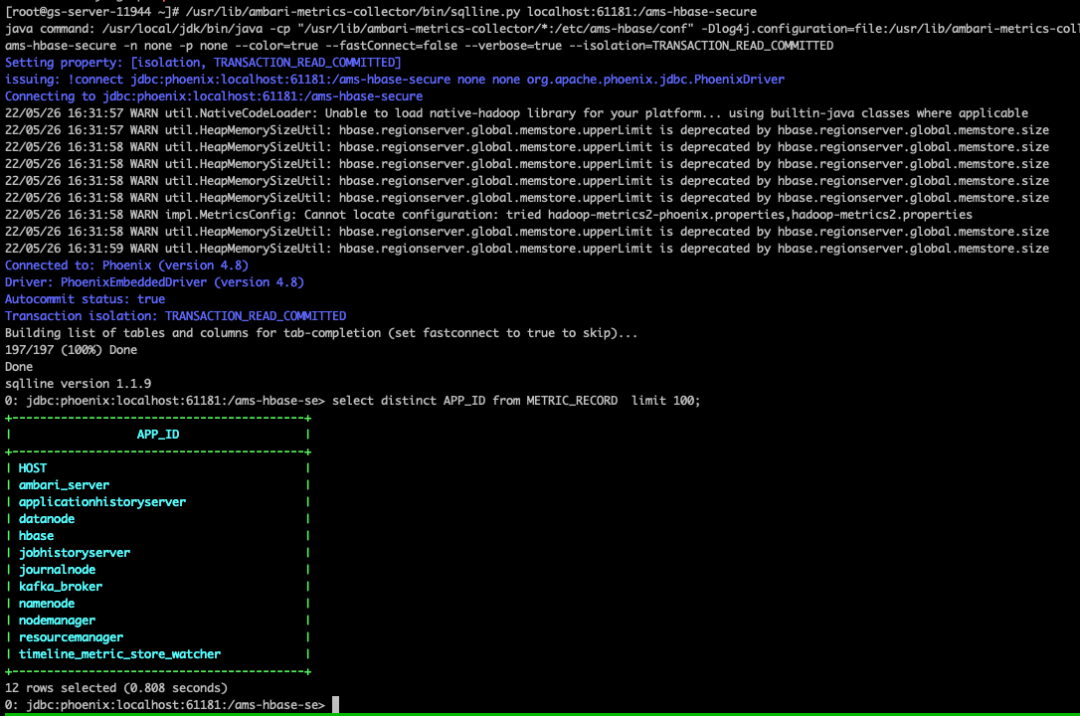
/usr/lib/ambari-metrics-collector/bin/sqlline.py localhost:61181:/ams-hbase-secure执行上述命令后,进入到了 phoenix 交互模式,执行以下命令:
# 查看表
!table
# 查询表记录
select * from METRIC_RECORD where APP_ID = 'kafka_broker' limit 100;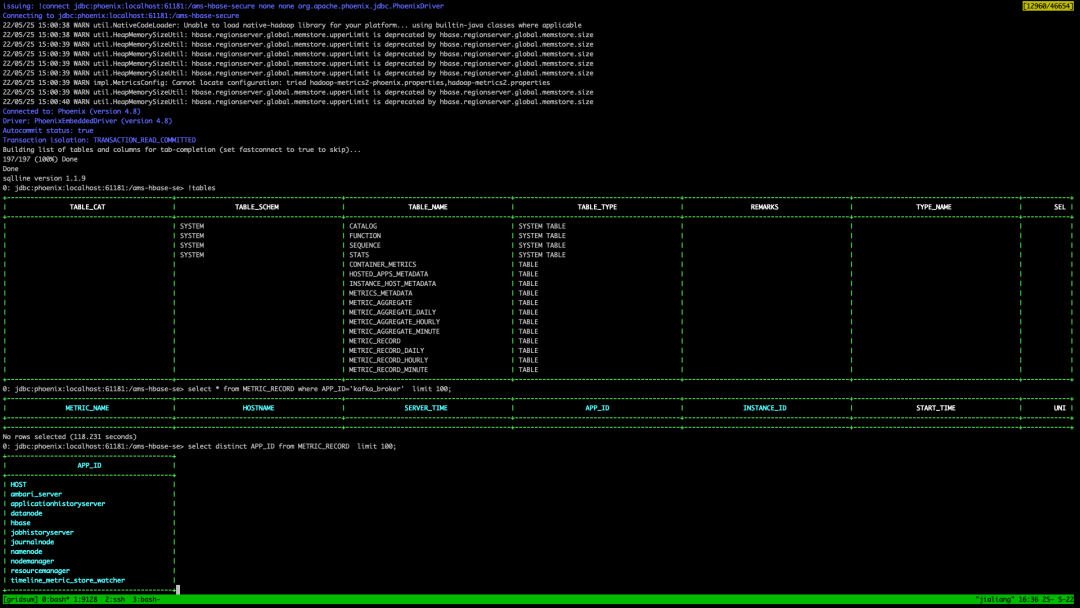 如上图所示,hbase 中确实没有监控数据,那么问题就出在数据源。
如上图所示,hbase 中确实没有监控数据,那么问题就出在数据源。
3、数据源分析
Kafka 的监控数据是 ams 自己提供的 kafka reporter 实现的。
1)这里首先看看 kafka 的 reporter 是否有数据, kafka reporter 作为 plugin 被 kafka 启动时加载
Arthas attach kafka 的线程通过查看 sink.kafka.KafkaTimelineMetricsReporter 源码可知,数据是通过 report 方法上报的,因此查看下 report 方法的返回值,看看是否有数据。
watch org.apache.hadoop.metrics2.sink.kafka.KafkaTimelineMetricsReporter$TimelineScheduledReporter report '{params,returnObj,throwExp}' -n 5 -x 4可以看到没有数据
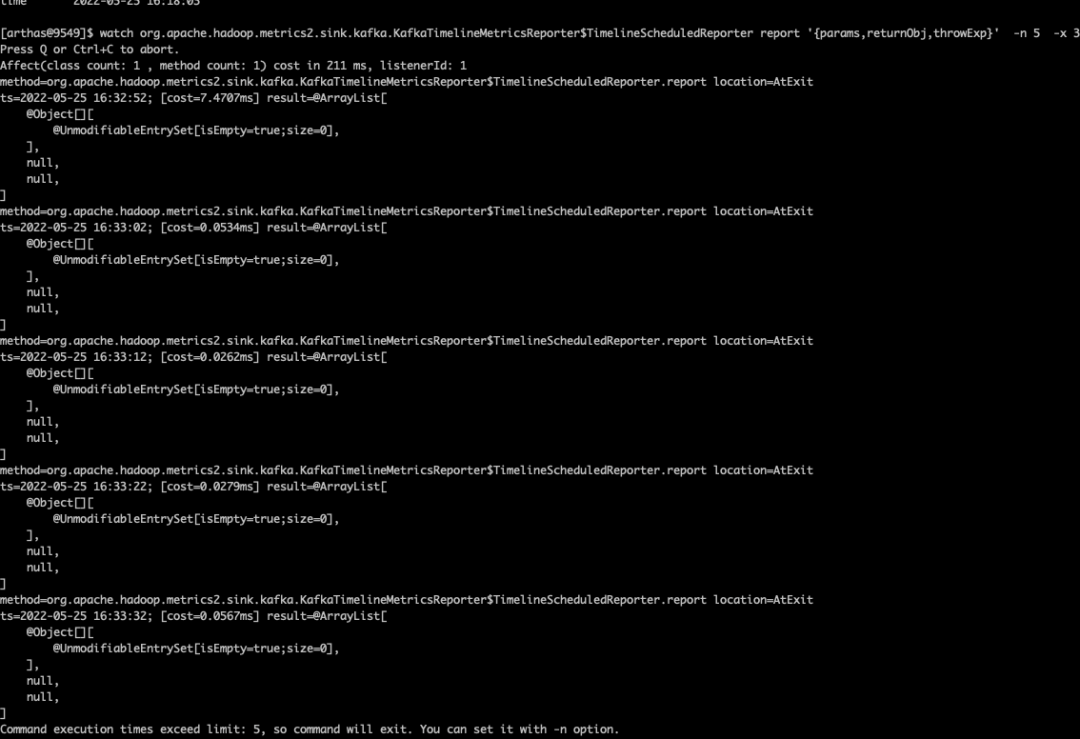
2)kafka reporter 自身确实没有数据上报,这里需要确定数据传递的流程,然后判断是是哪个阶段出了问题
kafka 自身的 metrics 数据源BUG
ams kafka metrics BUG
这里需要知道 kafka 自身如何把数据传递给 reporter,看看 Kafka 自身的 CSV reporter 代码可以看到,数据是从
getMetricsRegistry.allMetrics().entrySet();
KafkaYammerMetrics.defaultRegistry().allMetrics().entrySet();首先看下
vmtool -x 3 --action getInstances --className org.apache.hadoop.metrics2.sink.kafka.ScheduledReporter --express 'instances[0].registry'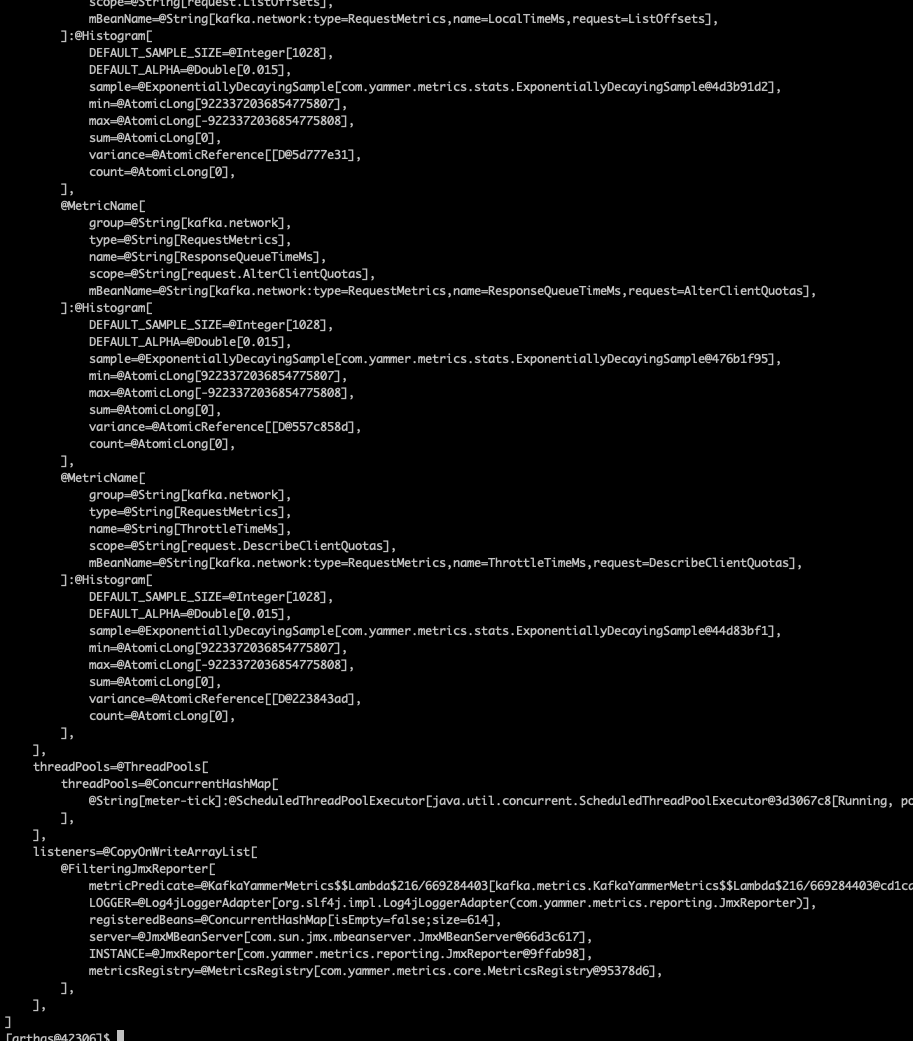 Arthas 查看是否有数据
Arthas 查看是否有数据
KafkaYammerMetrics.defaultRegistry().allMetrics().entrySet();
命令如下:
ognl -x 3 '@kafka.metrics.KafkaYammerMetrics@defaultRegistry()'
# 数据量太多,查看下总条数
ognl -x 3 '@kafka.metrics.KafkaYammerMetrics@defaultRegistry().allMetrics().size()'可以看到有数据
 看下 kafka.metrics.KafkaYammerMetrics 监控数据容器是否有监控数据,如图是有的:
看下 kafka.metrics.KafkaYammerMetrics 监控数据容器是否有监控数据,如图是有的:
ognl -x 3 '@kafka.metrics.KafkaYammerMetrics@defaultRegistry().allMetrics()'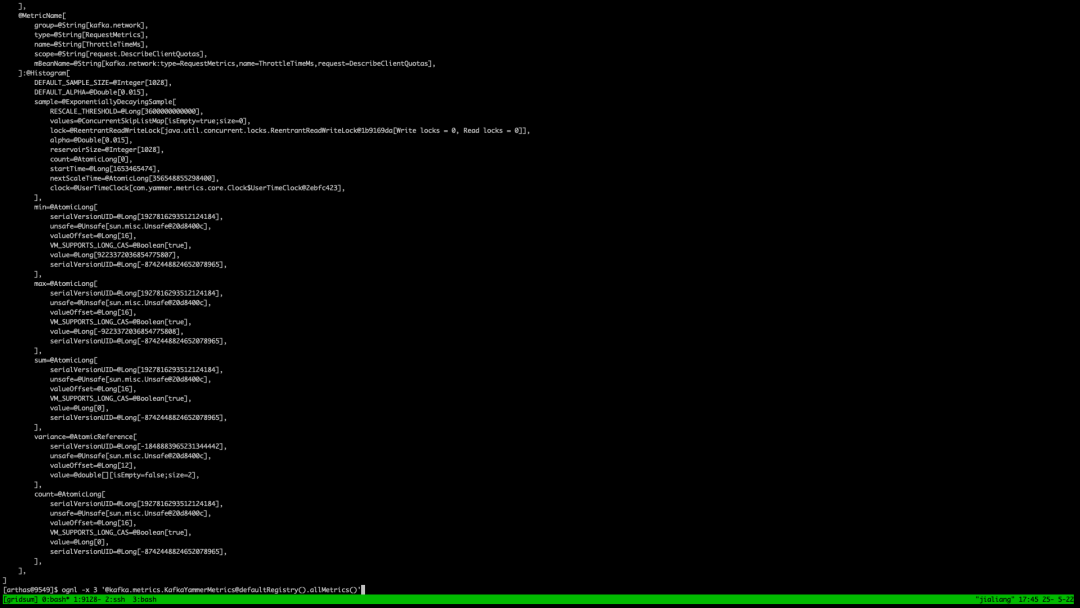 好,问题出在 ams 自己实现的 kafka reporter 上,查看了代码,发现其使用的 registry 和 kafka 使用的不同,这里两个情况,分别是:
好,问题出在 ams 自己实现的 kafka reporter 上,查看了代码,发现其使用的 registry 和 kafka 使用的不同,这里两个情况,分别是:
ams 使用的对的,只不过数据处理过程有问题不兼容
ams 使用的 kafka metrics 数据源不正确
使用 arthas 直接查看 ams kafka reporter 的 metrics 数据源:
ognl -x 3 '@com.yammer.metrics.Metrics@defaultRegistry().allMetrics()'Metrics.defaultRegistry()可以看到没有数据, 去 kafka 中搜索下 该调用,说明 ams 使用了过时的配置:
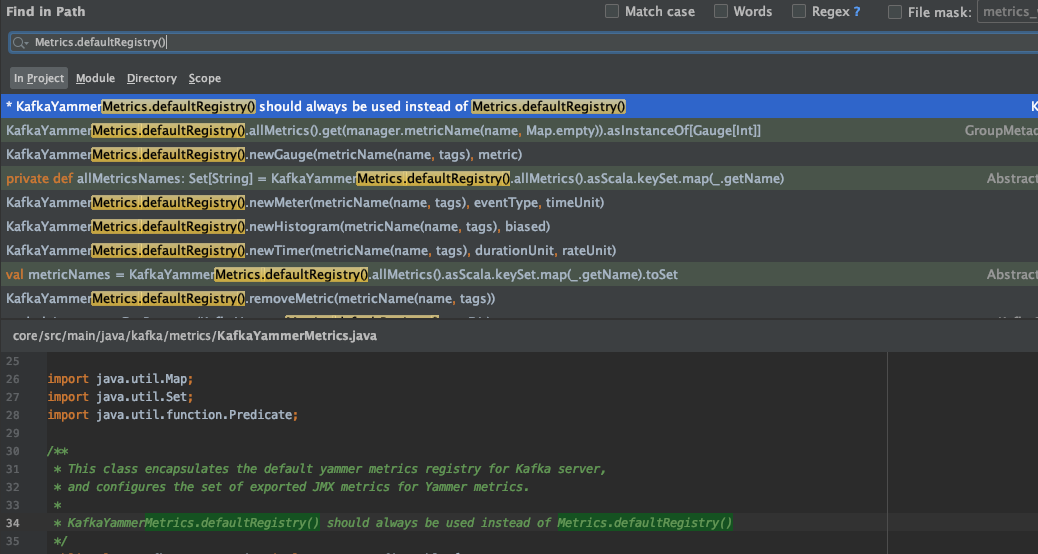 OK,搜索下代码,发现 kafka 标记了这个方法 deprecated 了,无法获取数据了,
换成新的实现 KafkaYammerMetrics.defaultRegistry()
,然后编译后替换包,发现 panel 还是没有监控数据。
OK,搜索下代码,发现 kafka 标记了这个方法 deprecated 了,无法获取数据了,
换成新的实现 KafkaYammerMetrics.defaultRegistry()
,然后编译后替换包,发现 panel 还是没有监控数据。
这里用 arthas 查看下 ams kafka reporter 中的数据容器是否有数据:
vmtool -x 3 --action getInstances --className org.apache.hadoop.metrics2.sink.kafka.ScheduledReporter --express 'instances[0].registry'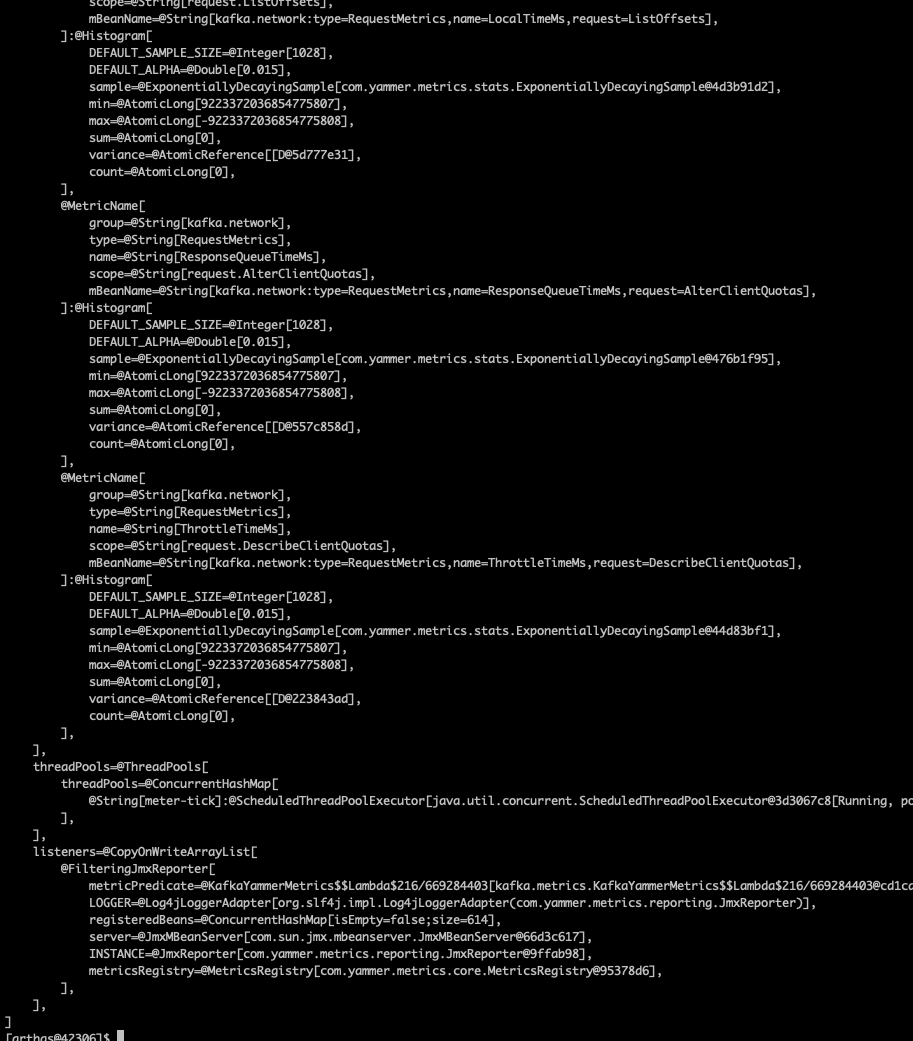 好,说明我们之前的改动是正确的,那么再看看 ams kafka report 方法是否有正确上报 kafka 数据:
好,说明我们之前的改动是正确的,那么再看看 ams kafka report 方法是否有正确上报 kafka 数据:
watch org.apache.hadoop.metrics2.sink.kafka.KafkaTimelineMetricsReporter$TimelineScheduledReporter report '{params,returnObj,throwExp}' -n 5 -x 3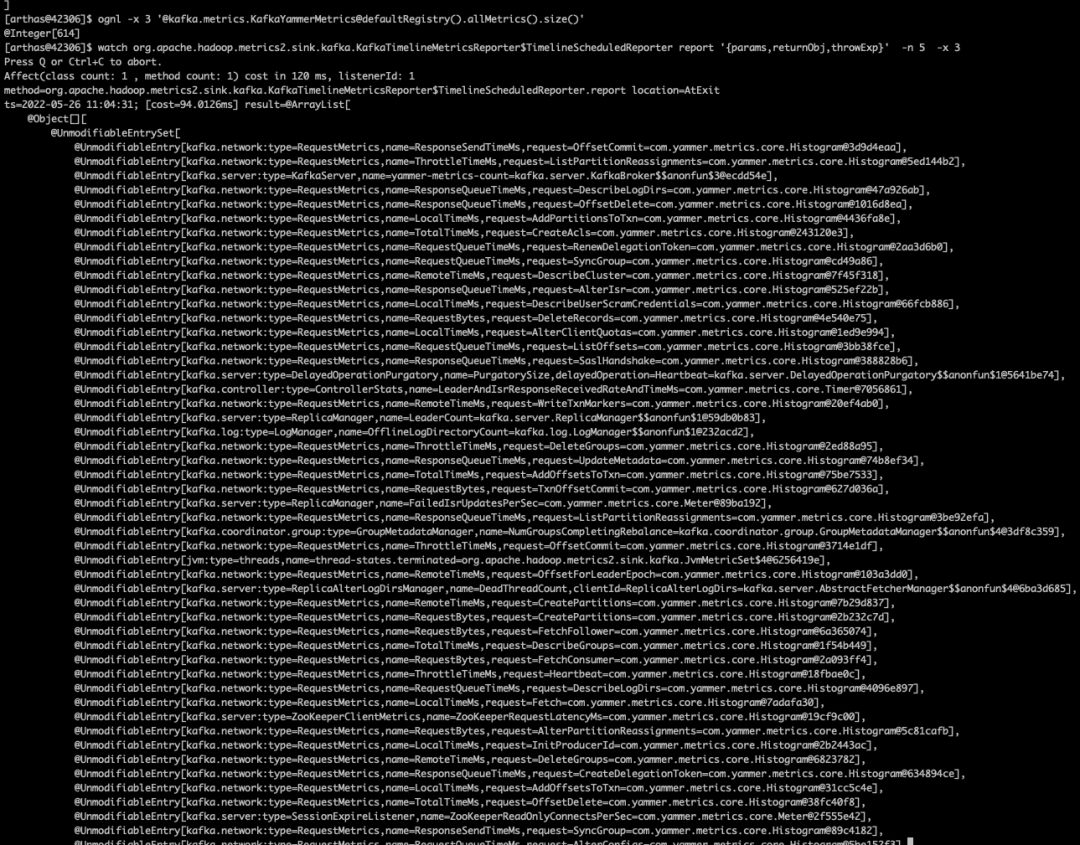 有!说明数据上报了ams,那么看下数据是否正确存入了 hbase
有!说明数据上报了ams,那么看下数据是否正确存入了 hbase
之前这个表没有,现在有了,如下图所示:
 查看下监控数据,发现有很多 kafka 数据:
查看下监控数据,发现有很多 kafka 数据:
select * from METRIC_RECORD where APP_ID = 'kafka_broker' limit 100;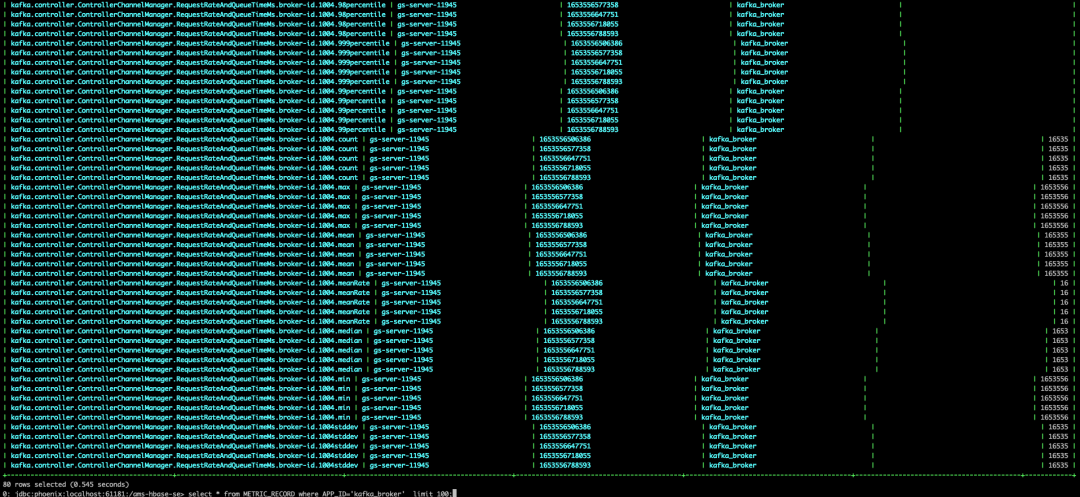 但是,查不到页面上展示的那些数据,也就是说,此时 ambari 的 kafka 监视数据还是空的。
但是,查不到页面上展示的那些数据,也就是说,此时 ambari 的 kafka 监视数据还是空的。
select * from METRIC_RECORD where APP_ID='kafka_broker' and METRIC_NAME like 'jvm%' limit 1000; 所以,之前的修复有效,但是还不够!!
所以,之前的修复有效,但是还不够!!
3)继续排查
这里有可能 ams 处理数据的过程把数据整没了,也许是 filter 之类的机制,或者干脆是 BUG。
打开 ams 的 debug 日志, 再去看 ams 日志中是否数据没有存进去。
vi /var/log/ambari-metrics-collector/ambari-metrics-collector.log日志中搜索 jvm.heap_usage 发现 Kafka push 过来的监控数据中确实没有该监控项:
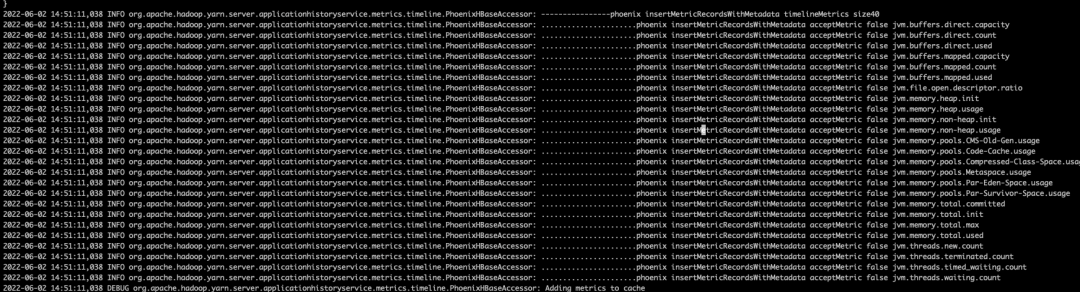 直接搜到 Kafka broker 的 reporter 提交的监控数据,查看是否有 JVM 相关数据,如下图所示确实有 JVM 数据,只不过监控数据名字不同。
直接搜到 Kafka broker 的 reporter 提交的监控数据,查看是否有 JVM 相关数据,如下图所示确实有 JVM 数据,只不过监控数据名字不同。
 这里到底是谁搞的鬼,是 kafka 更新后 还是 reporter 改动了 metrics 的名?
这里到底是谁搞的鬼,是 kafka 更新后 还是 reporter 改动了 metrics 的名?
于是用 arthas 查看运行时的Kafka 中 metrics 的数据
 根据 ams 的拼写规则,metrics 名字确实是 jvm.memory.heapusage
根据 ams 的拼写规则,metrics 名字确实是 jvm.memory.heapusage
这里怀疑 ambari 版本太老,用了旧的名字,
然后查看 ambari metrics.json 和 widget.json 确实发现名字为 jvm.heap_usage。
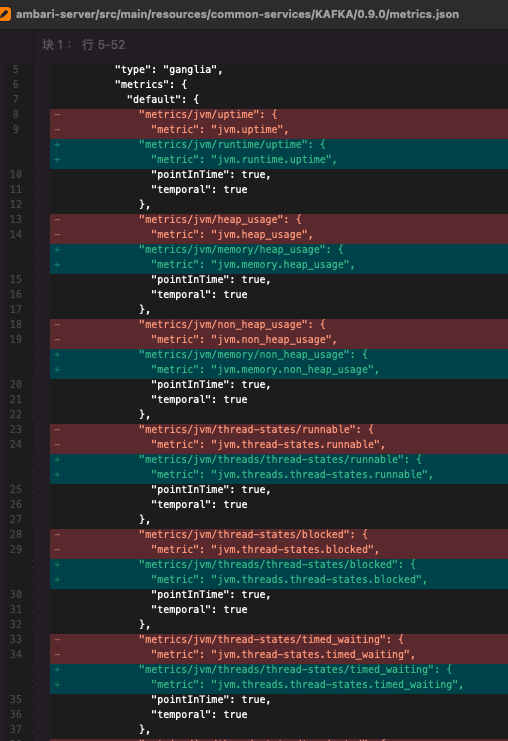
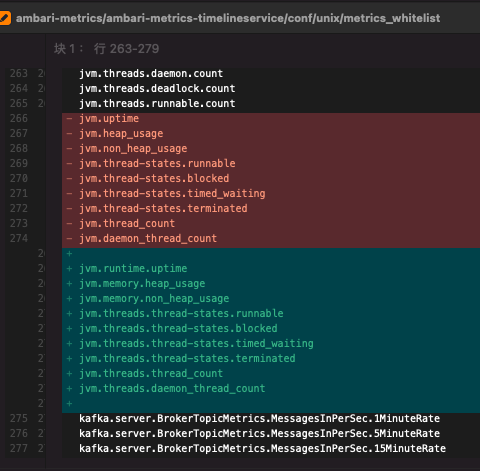
所以破案了,ambari 中定义的 jvm 部分的 metrics 名字过时了,我又用这个文件中的 metrics 名字添加到了白名单中,所以导致 jvm 正确的数据被拉黑,没有存储进去。
在服务器上可以直接修改
/var/lib/ambari-server/resources/common-services/KAFKA/0.9.0/metrics.json
修改 metrics_whitelist、metrics.json 文件,并重启 ams panel-server 即可解决,但是由于 jvm 相关的 metrics 并没有默认丢进 widget.json,所以不用改 widget.json。
改动记录如下图所示:
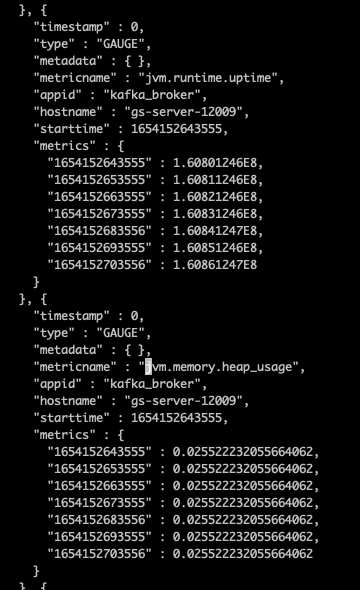
4)修复成功
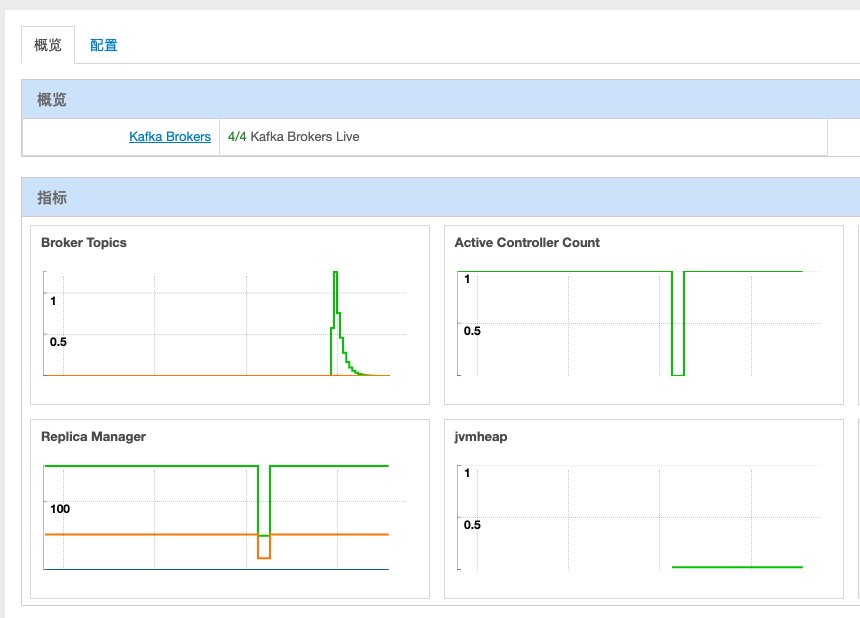
修复后正常显示的 jvm heap 如图所示:
三、总结
小结一下,改动如下:
1、换成了新的实现 KafkaYammerMetrics.defaultRegistry()
2、ambari 中定义的 jvm 部分的 metrics 名字过时了,修改 metrics_whitelist、metrics.json 文件。
排查过程中主要使用了 Arthas 工具,确实好用。
四、EDP 监控开发进展
我们这次给 Ambari 的监控系统进行了大刀阔斧的改造!终于把那个又老又难用的 Ambari Metrics 代替了,拥抱了 Prometheus 生态。
说真的,原来那套用 Phoenix + 单机 HBase 存数据的方案真是让人头大:
运维起来特别折腾
想跟 Prometheus 生态玩不到一块去
查问题全靠蒙,加个监控指标都费劲
所以我们决定大刀阔斧地重构一把,现在是这么个情况:
完美接入了 Prometheus 全家桶。
想用啥时序数据库都行,随你挑!
内置了一堆常用的监控大盘,拿来就能用
想加新监控?随便找个 Prometheus 的 exporter,分分钟搞定!
最爽的是,我们不但把原来监控的功能都给保住了,还全面升级加强了一波。现在的监控更全面、更好用、想怎么扩展就怎么扩展。
总之就是:更强!更快!更好用!目前初见成效,附几张图给大家看看:
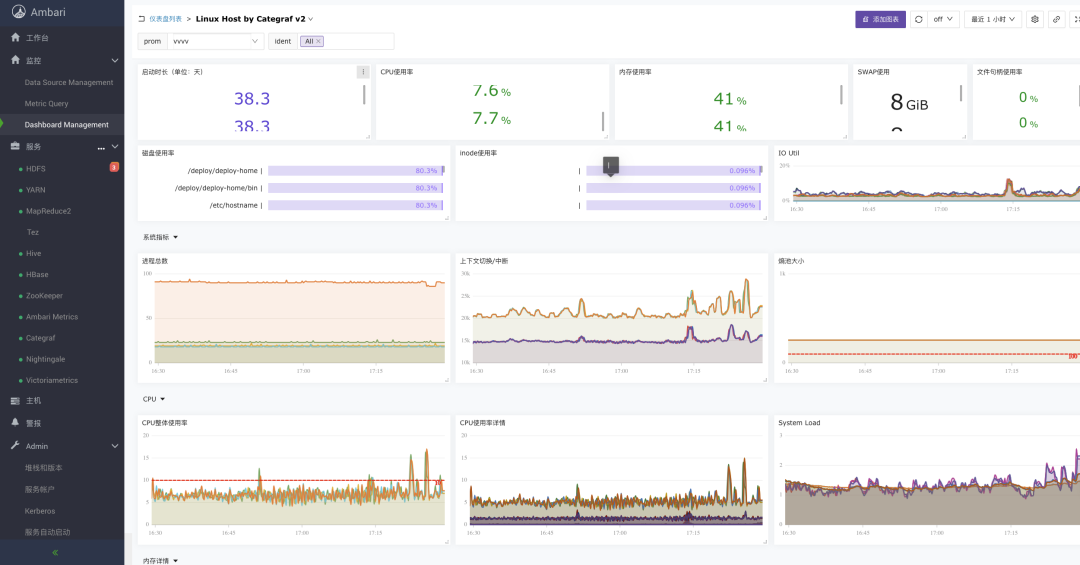
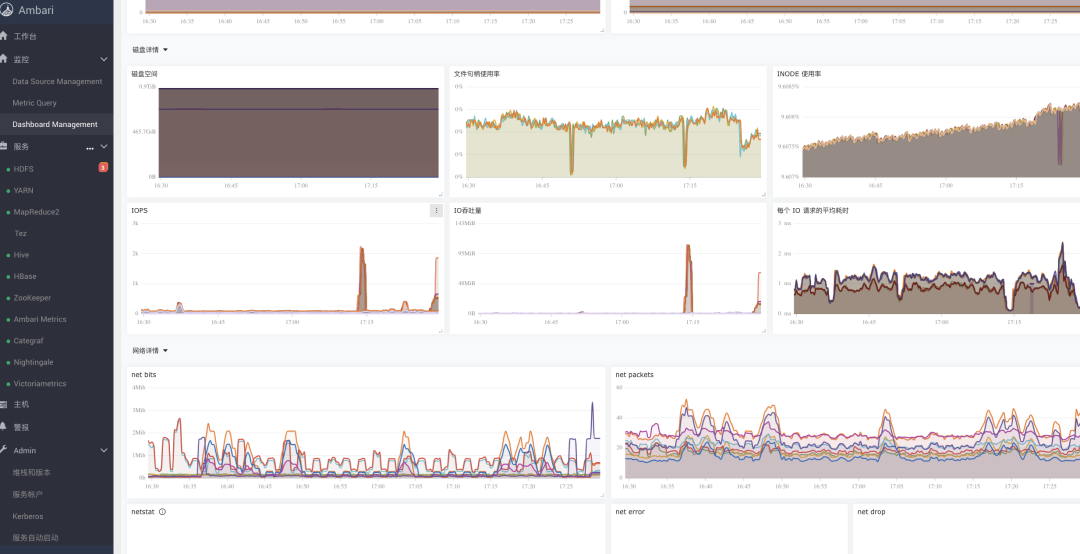
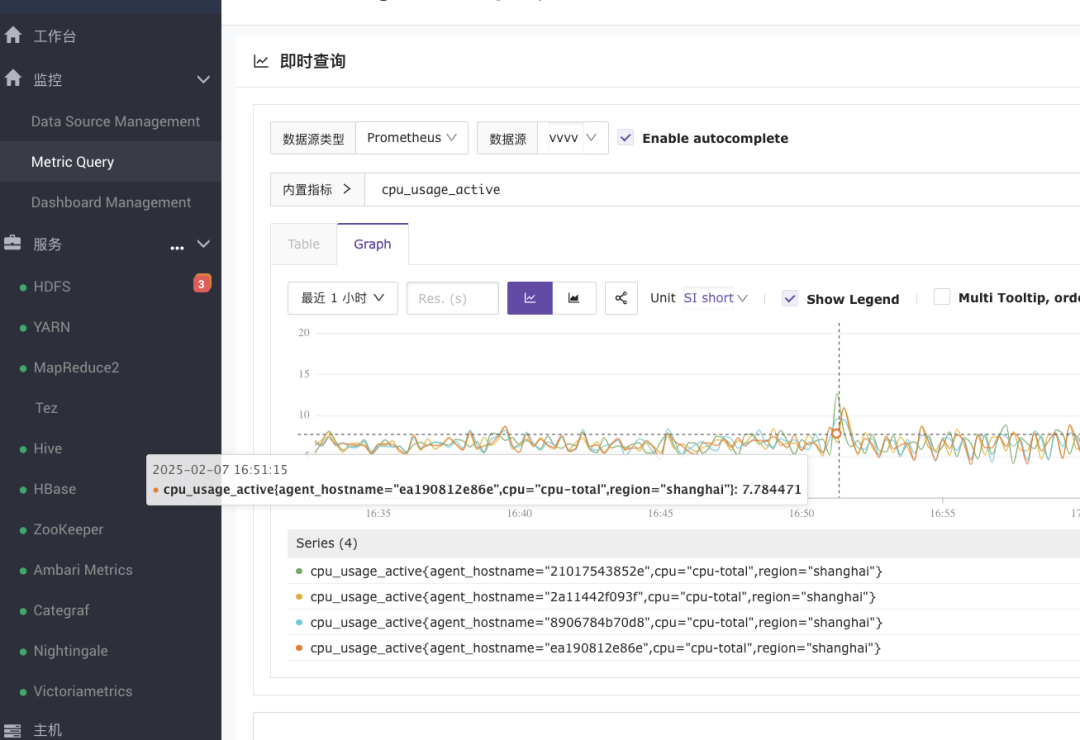 后续再详细给大家汇报开发进展,我们下期见~
后续再详细给大家汇报开发进展,我们下期见~
ending


一个人可以走得很快,但一群人才能走得更远。我的Ambari课程累计学员已经有 400+。感谢信任的同时,如果你需要一个良好的Ambari学习与交流环境,就请加入我们吧。这是一个学习Ambari的付费私密圈子,里面的人都是Ambari的活跃二次开发者,报名后,你可以享有知识星球 + 学员微信群 + 课程资料(笔记、视频等)+ 导师学习陪伴答疑服务,认识更多大佬,和大家一起成长。也欢迎大家点击左下角阅读原文了解我,希望我能提供的服务可以帮助到你。

最后,把我的座右铭送给大家:执行是消除焦虑的有效办法,明确并拆解自己的目标,一直行动,剩下的交给时间。共勉 💪。
戳“阅读原文”,查看最新内容


















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











