







 本文深入解析Redis字典的数据结构,介绍Hash表底层结构、Entry组成,重点讲解渐进式rehash过程及其优点。通过实例揭示如何在Redis中高效管理键值对并保持负载均衡。
本文深入解析Redis字典的数据结构,介绍Hash表底层结构、Entry组成,重点讲解渐进式rehash过程及其优点。通过实例揭示如何在Redis中高效管理键值对并保持负载均衡。
如果对跳跃表感兴趣可以看博主的另一篇文章:传送门,看不懂来捶我~
剖析字典结构
对于面试常问的Redis五种数据结构类型,相信每个java程序员都刻入到DNA中了,但大厂面试官问必底层,问到把你裤衩子给看穿,所以作为五大数据结构的底层实现结构之一:字典更是重中之重,接下来随博主用最简洁,图文并茂的讲给你听

壹:宏观理解字典
字典就可以理解为我们生活使用的字典,就是存放key-value的大集合,key相当于想要查的汉字,value:相当于汉字的详细解释,字典存放了一个个的key-value,并且每个key都是唯一的
Redis本身就是基于key-value的键值对的存储结构,所以Redis的数据库就是使用字典来实现的,同时对于五大数据结构中Hash,Set,Zset底层也是使用的字典结构
贰:字典的实现
1.字典的底层实现:Hash表的结构
Redis的字典使用Hash表作为底层实现,对于Hash表也叫散列表相信大家都不陌生,在Redis中Hash表=数组+链表,我们来看看底层C语言中对于哈希表的定义
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
其中table存储的便是一个个Entry(一个key-value键值对为一个Entry),我们再来看看Entry的底层实现
Hash表中Entry的结构
typedef struct dictEntry {
// 键
void *key;
// 值
union {
// value值可能是指针
void *val;
// 或者是一个uint64_t整数
uint64_t u64;
// 或者int64_t整数
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
我们来分析一个Entry中各个属性含义
- union是c语言中的一种结构,它与struct的区别在于:在union 中所有的数据成员共用一个空间,同一时间只能储存其中一个数据成员,所有的数据成员具有相同的起始地址,所以Redis会根据程序员set的value值在三者中选择一个
- next属性用于解决hash冲突,当索引值相同时使用拉链法解决哈希冲突,将冲突的Entry以链表的结构连接在一起
一张图解释Hash表的底层结构
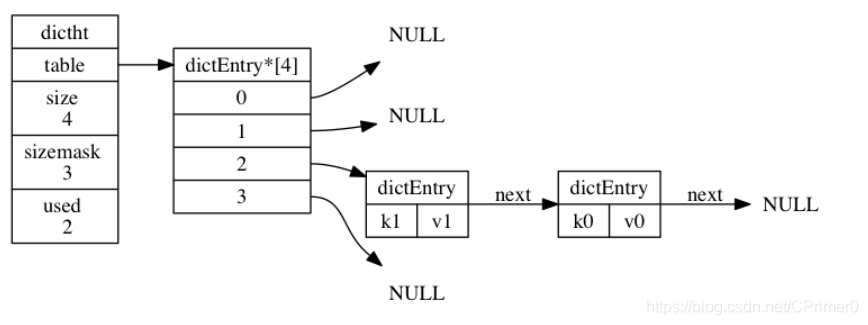
整合Hash和Entry的字典结构
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
我们重点来看两个属性
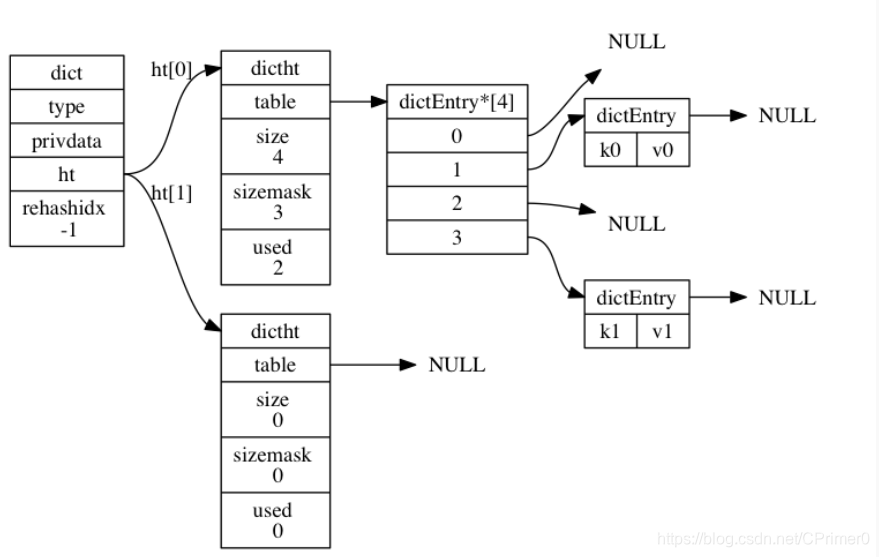
- ht[2]两个哈希表用于rehash时方便使用,后文详细介绍,也是字典结构的重点
- threhashidx表示rehash是否在进行,跟渐进式hash息息相关,也由后文细致讲述
一张图解释普通状态下即没有rehash的字典结构
叁:重点渐进式rehash过程
读过Java中HashMap的同学都知道其中一个变量load factory负载因子,负载因子的作用就是调节Hash表的长度在一个合理范围内,当键值对太多时,此时Hash冲突的概率也会增高,就需要将table表进行扩展操作,当删除了很多键值对后,为了节省空间又需要进行收缩操作,所以rehash(重新散列)就是用于扩展和收缩哈希表的,接下来我们来看看具体的步骤
-
1.前文说到两个哈希表就是用于rehash过程中数据的迁移,就是将ht[0]中的数据保存到ht[1]中,那么rehash的第一步就是分配ht[1]的空间大小
- 如果是拓展操作,ht[1]的大小为第一个大于等于ht[0].userd*2的2^n,举个栗子,假设ht[0]有10个元素,即used = 10,那么ht[1]的空间大小为32
- 如果是收缩操作,ht[1]的大小为第一个大于等于ht[0].userd的2^n,栗子同上
-
2.将 rehash 索引计数器变量 rehashidx 的值设置为0,表示 rehash 正式开始。
-
3.在 rehash 进行期间,每次对字典执行添加、删除、査找、更新操作时,程序除了执行指定的操作以外,还会触发额外的 rehash 操作,也就是渐进式rehash的思想,并不是一次性集中的完成
-
4.随着操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],此时 rehash 流程完成,会执行最后的清理工作:释放 ht[0] 的空间、将 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值为 -1。
你可能会有疑问
将 rehash 分摊到每个操作上确实是非常妙的方式,但是万一此时服务器比较空闲,一直没有什么操作,难道 redis 要一直持有两个哈希表吗?
答案当然不是的。我们知道,redis 除了文件事件外,还有时间事件,redis 会定期触发时间事件,这些时间事件用于执行一些后台操作,其中就包含 rehash 操作:当 redis 发现有字典正在进行 rehash 操作时,会花费1毫秒的时间,一起帮忙进行 rehash。
肆:rehash的优点
- 渐进式 rehash 的好处在于它采取分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 而带来的庞大计算量。
- 在进行渐进式 rehash 的过程中,字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间,字典的删除、査找、更新等操作会在两个哈希表上进行。例如,要在字典里面査找一个键的话,程序会先在 ht[0] 里面进行査找,如果没找到的话,就会继续到 ht[1] 里面进行査找,诸如此类。
- 另外,在渐进式 rehash 执行期间,新增的键值对会被直接保存到 ht[1], ht[0] 不再进行任何添加操作,这样就保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
总结:
- 字典用于Redis数据库的底层结构,也是哈希键的底层实现结构
- 每个字典有两个哈希表,一个平常使用,一个rehash时使用
- 哈希表使用链地址法解决哈希冲突
- Redis采取渐进式rehash,并不是一次集中的更新到新的hash表中,而是将操作均摊到每一此增删改查中

















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









