









 本文深入探讨Redis的底层实现,从简单动态字符串(SDS)、链表、跳跃表、压缩列表到字典结构,揭示Redis如何高效地存储和操作数据。通过分析各个数据结构的特性,如SDS的二进制安全、链表的双端无环、跳跃表的快速查找、压缩列表的空间优化,以及对象的编码转换策略,展示了Redis在性能和内存使用上的精妙设计。
本文深入探讨Redis的底层实现,从简单动态字符串(SDS)、链表、跳跃表、压缩列表到字典结构,揭示Redis如何高效地存储和操作数据。通过分析各个数据结构的特性,如SDS的二进制安全、链表的双端无环、跳跃表的快速查找、压缩列表的空间优化,以及对象的编码转换策略,展示了Redis在性能和内存使用上的精妙设计。
说到redis,五大数据结构几乎是人人皆知的东西了,这是redis区别memcached的重要特征,那么redis底层是如何实现这五大数据结构的呢?这里面大有学问,且随博主,一探究竟,绝对值得你收藏慢慢看

万字长文带你吃够底层结构
壹:首先我们先明白几个前置知识
1.redis中所有的底层的主要的数据结构
简单动态字符串SDS、双端链表、字典、压缩列表、整数集合等等
2.redis使用对象存储键值对
我们要明白Redis中无论是key还是value都是使用对象来存储,每当我们在Redis的数据库添加一个键值对时,底层至少会创建两个对象,下面是C语言中对Redis中的对象的定义,熟悉C语言的同学可能会看出这就是基本的结构体
typedef struct redisObject{
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
}robj;
关于什么是type,什么是encoding,先做一个简单的介绍
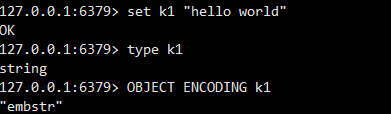
- type获取的是redis的五大基本类型,也就是string,set,zset,list,hash
- encoding获取的是实现五大基本类型的基本结构,这里的embstr就是其中之一,后文会详细介绍到,redis中使用
object encoding指令获取对应encoding
3.五大类型对应的底层结构
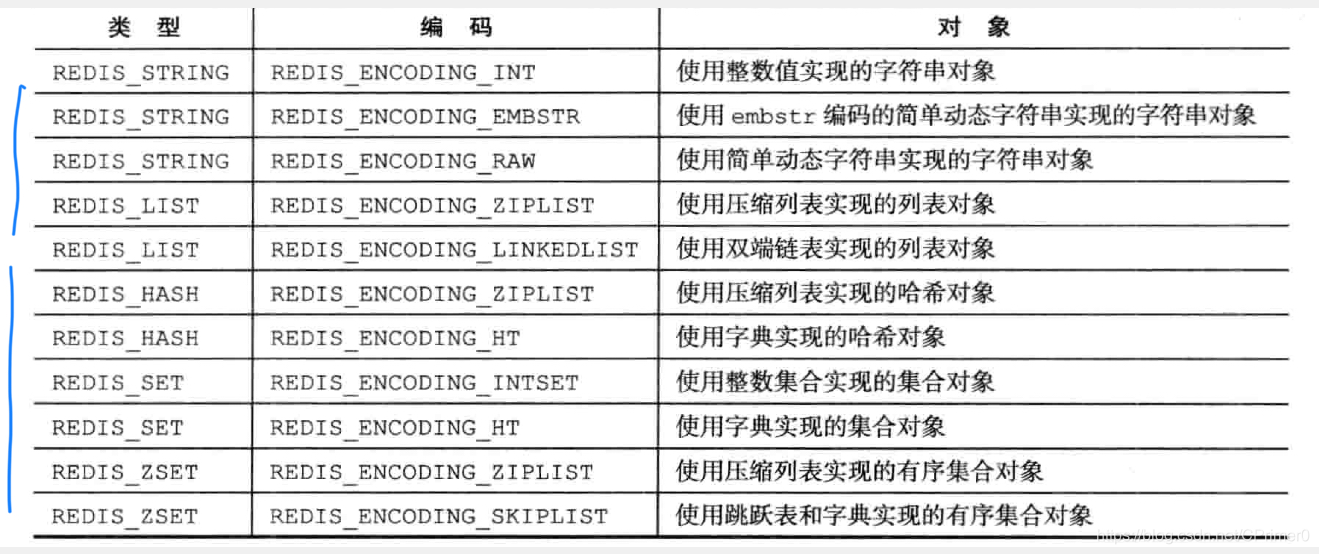 每种类型至少对应两种底层结构,根据数据量的不同以及各种性能的权衡,redis的每种数据结构可能会切换对应的底层结构,也就是所谓的“编码转换”,先简单举个栗子,帮助大伙理解
每种类型至少对应两种底层结构,根据数据量的不同以及各种性能的权衡,redis的每种数据结构可能会切换对应的底层结构,也就是所谓的“编码转换”,先简单举个栗子,帮助大伙理解
- 对于String类型来说,可以用long类型保存的整数编码类型为int
- 可以用long double类型保存的浮点数,编码类型为embstr或者raw
- 字符串值,或者因为长度太长无法用long表示的整数,或者无法用long double表示的浮点数,编码类型为embstr或者raw
贰:走进深水区,正式进入底层结构

1.简单动态字符串(simple dynamic string,SDS)
Redis是用c语言编写的,所以对于字符串的处理,Redis在保留了某些c的特性的情况下,同时进行了包装升级,更适合Redis所追求的性能为王

一条简单的指令中,键值对的键是一个字符串对象,对象的底层实现保存了字符串“k1”的SDS,键值对的值同理
A.SDS的定义
底层c语言的代码
struct sdshdr{
// 记录buf数组中已经使用的子节的数量
int len;
// buf数组中未使用的子节数量
int free;
// 子节数组,用于保存字符串
char buf[]
}
假设存储一个“Redis"的SDS对象,底层结构的示意图如下
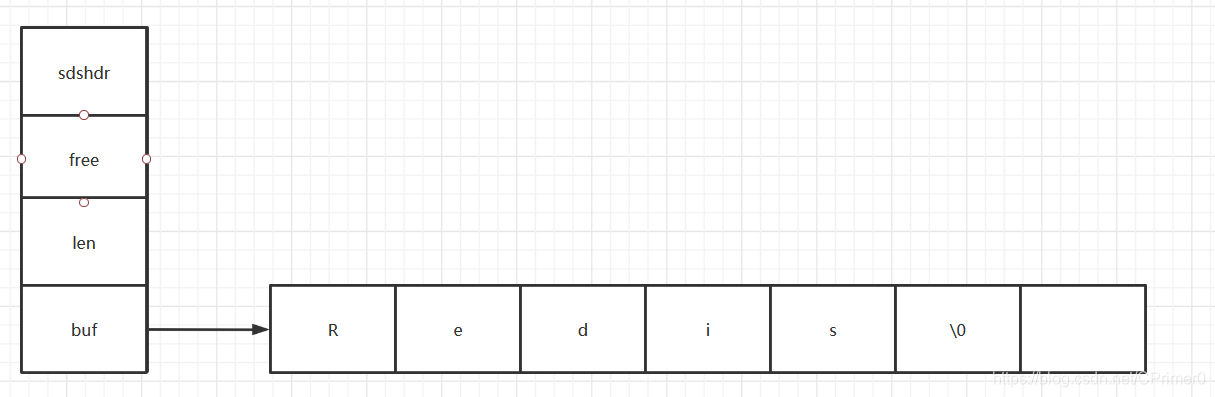
- len的值为5,不包括结束字符’\0’
- free的值为1. '\0’占用一个子节
- 保存’\0’是为了调用c语言底层类似于printf等库函数,不用反复造轮子
A.SDS相比于c字符串的优点
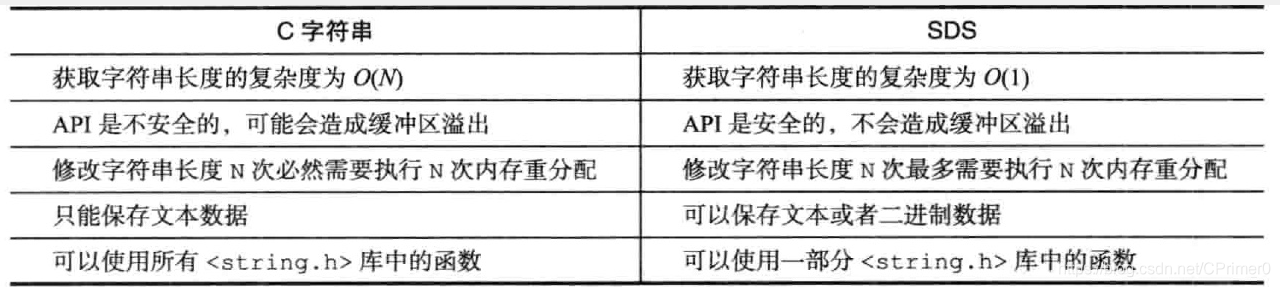
- 由于SDS中保存了len的字段,所以可以在o(1)的复杂度内获取长度,但原生的c字符串中必须遍历在o(n)的复杂度内得到长度,确保了获取字符串的长度的操作不会影响性能,即使是获取一个很长的字符串的长度,以空间换事件
- 杜绝缓冲区溢出,熟悉c语言的小伙伴一定明白,
strcat(char *dest,char *src)等对于字符串的操作函数,需要自己确保dest能够存储拼接后的字符串,稍不注意可能会出现缓冲区溢出的错误,但是SDS会先检查空间是否足够进行动态调整 - 减少字符串改变时带来的内存重分配的次数,对于c语言来说如果进行类似于append拼接操作超过了缓存区长度,需要再次申请内存空间,而进行缩短字符串类似trim的操作还要释放不使用的空间,SDS通过上文的free字段优化策略
- ①.空间预分配,如果要扩展空间时,SDS不仅会分配必要的空间,还会分配未使用空间,free用来记录未使用空间的长度,如果进行修改后的SDS的长度小于1M,会分配和len相同的未使用空间,如果修改后大于1M,会分配1M的未使用空间
- ②.惰性空间释放,如果对SDS进行了缩短操作,多出来的子节不会立即回收,而是用free记录回收的空间,便于下一次的使用,譬如在进行增长操作可能会在派上用场
B.支持二进制安全
对于c语言来说,字符串中间不能出现’\0’字符,否则会被误认为字符串结尾,所以导致c字符串只能存储文本文件,不能存储图片等,但是Redis的buf数组存储的不是字符而是一系列的二进制数据,这也是buf为什么被叫做子节数组,所以SDS存储特殊的数据完全没有问题,也就是锁胃的二进制安全
C.一张图对比SDS和C的字符串
2.链表
Redis底层的链表和我们平常中使用的链表并不太大的差异,这里只说一些Redis中的特性即可
- Redis底层链表时双端无环的链表
- 由于链表未设置特定的类型,所以Redis的链表可以存储各种不同的类型
- 链表被广泛用于实现Redis的各种功能,比如列表键,发布与订阅,慢查询,监视器等
3.跳跃表
跳跃表是一种有序的数据结构,是Zset的底层结构之一,跳跃表的节点查找平均复杂度为o(logn),最坏为o(N),目的就是为了加快有序集合的增删改查,为了不使文章篇幅过长,可以看博主的一篇文章详解跳跃表,一文包你看懂
4.压缩列表
当你向redis添加的列表项数据量比较小,或者每个列表项要么是小整数值,要么是长度比较短的字符串,这时为了节约空间,会使存储更加紧凑,Redis就会使用压缩列表,List,Zset,Hash底层都用到了压缩列表
A.压缩列表的组成部分解析
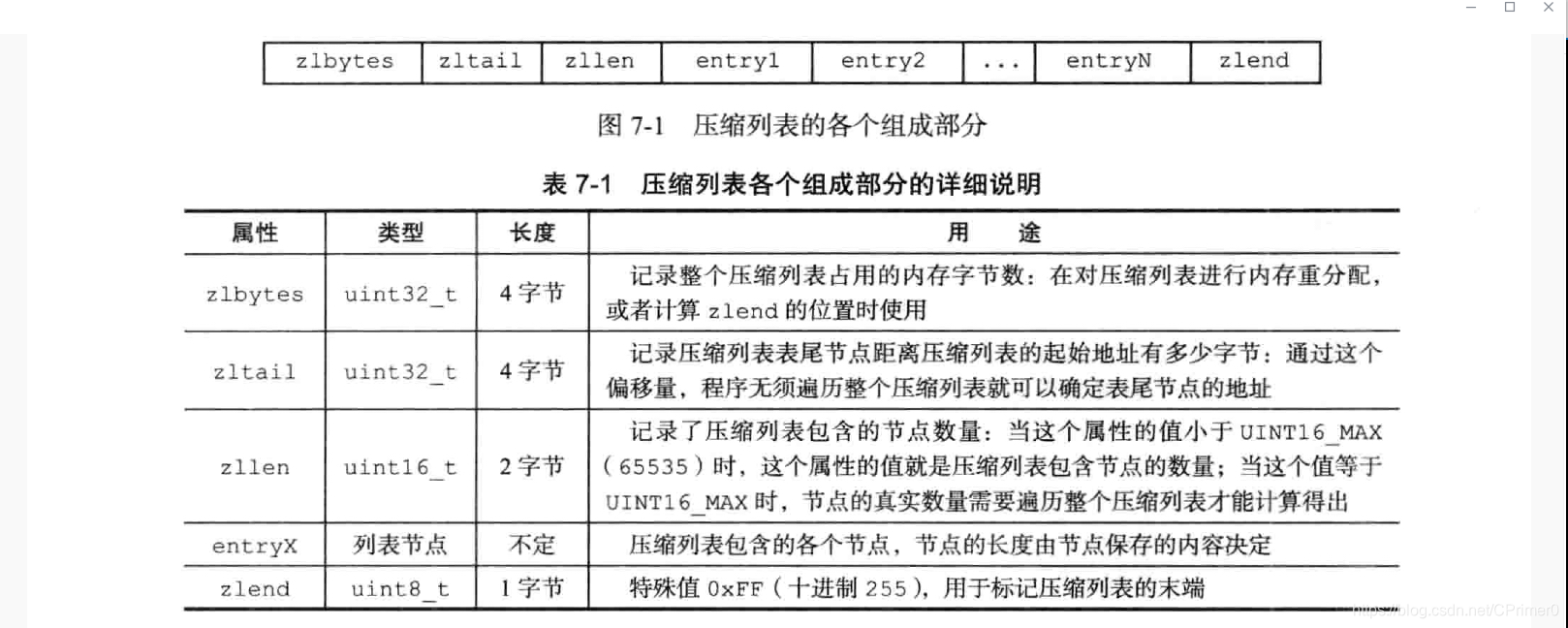 所以整个压缩列表来说,存储空间很紧凑,没有空间浪费,并且由zltail,zllen等属性使得获取压缩列表节点个数,长度的复杂度都控制在o(1)内
所以整个压缩列表来说,存储空间很紧凑,没有空间浪费,并且由zltail,zllen等属性使得获取压缩列表节点个数,长度的复杂度都控制在o(1)内
B.每个entry的组成结构
struct entry{
prev_entry_length;
encoding;
contents;
}
- prev_entry_length:由于底层是子节存储,用来编码前置节点的长度,用于从后往前遍历
- 如果前置节点的长度小于254字节,那么采用1个字节来保存这个长度值
- 如果前置节点的长度大于254字节,则采用5个字节来保存这个长度值,其中,第一个字节被设置为0xFE(254),用于表示该长度大于254字节,后面四个字节则用来存储前置节点的长度值
- encoding:编码属性,这里指的不是五大基本类型,而是底层实现类型,ziplist的节点可以保存字符串值和整数值,二者的编码属性下面一一道来。
- (一)、保存字符串的值:本质上是字节数组,如果节点保存的是字符串值,那么该编码大小可能为1字节,2字节或5字节,这与字符串的长度有关。编码部分前两位为00,01或者10,分别对应上述的三种大小,后面的位表示长度大小值。
- (二)、节点保存整数值:如果节点保存的是整数值,那么其编码长度固定为1个字节,该字节的前两位固定为11,用于表示节点保存的是整数值。这里也用一个表来说明。
- contents:负责保存节点的值
C:关于压缩表的基本操作
由于Redis是纯C语言实现的,所以具体方法的实现都是基于C语言,我们来看看插入操作
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen; // 当前长度和插入节点后需要的长度
unsigned int prevlensize, prevlen = 0; // 前置节点长度和编码该长度值所需的长度
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; // 为了避免警告,初始化其值
zlentry tail;
// 找出待插入节点的前置节点长度
// 如果p[0]不指向列表末端,说明列表非空,并且p指向其中一个节点
if (p[0] != ZIP_END) {
// 解码前置节点p的长度和编码该长度需要的字节
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
// 如果p指向列表末端,表示列表为空
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
// 计算尾节点的长度
prevlen = zipRawEntryLength(ptail);
}
}
// 判断是否能够编码为整数
if (zipTryEncoding(s,slen,&value,&encoding)) {
// 该节点已经编码为整数,通过encoding来获取编码长度
reqlen = zipIntSize(encoding);
} else {
// 采用字符串来编码该节点
reqlen = slen;
}
// 获取前置节点的编码长度
reqlen += zipPrevEncodeLength(NULL,prevlen);
// 获取当前节点的编码长度
reqlen += zipEncodeLength(NULL,encoding,slen);
// 只要不是插入到列表的末端,都需要判断当前p所指向的节点header是否能存放新节点的长度编码
// nextdiff保存新旧编码之间的字节大小差,如果这个值大于0
// 那就说明当前p指向的节点的header进行扩展
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
// 存储p相对于列表zl的偏移地址
offset = p-zl;
// 重新分配空间,curlen当前列表的长度
// reqlen 新节点的全部长度
// nextdiff 新节点的后继节点扩展header的长度
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
// 重新获取p的值
p = zl+offset;
// 非表尾插入,需要重新计算表尾的偏移量
if (p[0] != ZIP_END) {
// 移动现有元素,为新元素的插入提供空间
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
// p+reqlen为新节点前置节点移动后的位置,将新节点的长度编码至前置节点
zipPrevEncodeLength(p+reqlen,reqlen);
// 更新列表尾相对于表头的偏移量,将新节点的长度算上
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
// 如果新节点后面有多个节点,那么表尾的偏移量需要算上nextdiff的值
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
// 表尾插入,直接计算偏移量
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
// 当nextdiff不为0时,表示需要新节点的后继节点对头部进行扩展
if (nextdiff != 0) {
offset = p-zl;
// 需要对p所指向的机电header进行扩展更新
// 有可能会引起连锁更新
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
// 将新节点前置节点的长度写入新节点的header
p += zipPrevEncodeLength(p,prevlen);
// 将新节点的值长度写入新节点的header
p += zipEncodeLength(p,encoding,slen);
// 写入节点值
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// 更新列表节点计数
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
简单来说和普通的插入操作相差无几,大致上都是找到插入位置,修改节点信息,无非就是细节上的实现,对于源码的学习我们不应死究细节,我们只需要有一个宏观的把控
D:连锁更新
什么是连锁更新,上文说到每个节点都有一个prev_entry_length属性用来存储上一个节点的长度,长度是1子节或者5子节用来存储上一个节点的长度
现在假设这么一种情况
如果有多个连续的,长度解于250子节到253子节的节点,也就是说这些节点的prev_entry_length只需要一个子节用来存储,如果此时要在这些节点的头部插入长度大于254子节的节点,那么prev_entry_length就需要扩展到5个子节,加上5个子节后就大于254子节,所以后一个节点也需要扩展prev_entry_length导致一系列的扩展操作
同理如果删除节点也可能存在连续压缩的情况,这就是级联更新
但不用担心,实际上,压缩列表中有多个的满足连锁更新的节点的情况并不常见,即使出现只要节点数量不多,就不会对性能有什么本质上的影响,所以不必担心连锁更新会影响压缩列表的性能
E:总结
- 压缩列表是用来节约内存开发的顺序性数据结构
- 压缩列表作为列表键和哈希键的底层实现之一
- 压缩列表可以包含多个值,每个节点可以用来存储子节数组或者整数值
- 添加或者删除可能会引起连锁更新,但不用担心对性能的影响
5.字典结构
字典结构复杂, 是redis整个key-value数据库的底层结构,同时也是set,Zset,Hash的底层结构,主要涉及到rehash的过程和字典底层结构Hash的实现机制,由于篇幅原因,可以跳转到博主专门写的博客:传送门,绝对通俗易懂
6.对象的编码转换
前文说到在Redis中一切的结构都是对象,所以五种数据结构可以分为五大对象:字符串对象,列表对象,哈希对象,集合对象,有序集合对象,每种对象对应的结构上文图中也已做详细解释
每种对象的底层至少对应着两种encoding,Redis根据空间和性能多方面抉择底层到底使用那种数据结构,也就是编码转换,接下来对每种对象的编码转换做一个大总结
A:String对象
- 对于String类型来说,可以用long类型保存的整数编码类型为int
- 可以用long double类型保存的浮点数,编码类型为embstr或者raw
- 字符串值,或者因为长度太长无法用long表示的整数,或者无法用long double表示的浮点数,编码类型为embstr或者raw
B:列表对象
- 列表对象保存的所以字符串长度都小于64子节,或者保存的元素小于512个,列表对象使用zipList编码
- 如果不能满足上述两个条件,使用linkedList编码
C:哈希对象
使用zipList的条件同上, 如果不能满足上述两个条件,使用hashtable编码
D:集合对象
- 当集合对象保存的所有元素都是整数值并且保存元素个数不超过512个,使用intset编码
- 否则使用hashtable编码
E:有序集合
- 有序集合保存的元素个数少于128个,并且所有元素的长度小于64子节,底层使用zipList
- 否则使用skiplist编码
以上就是全部内容了,创作不易,觉得不错,你的三联就是对博主最大的鼓励!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









