







 本文深入浅出地介绍了跳跃表这一高效的数据结构,它是Redis中Zset的底层实现之一。跳跃表通过多层链表实现快速查找,平均时间复杂度为O(logn)。文章通过公交线路的比喻解释了跳跃表的工作原理,并详细阐述了查找、插入、删除和更新节点的过程。此外,还介绍了Redis中跳跃表的节点结构和随机造层策略,帮助读者全面掌握跳跃表的精髓。
本文深入浅出地介绍了跳跃表这一高效的数据结构,它是Redis中Zset的底层实现之一。跳跃表通过多层链表实现快速查找,平均时间复杂度为O(logn)。文章通过公交线路的比喻解释了跳跃表的工作原理,并详细阐述了查找、插入、删除和更新节点的过程。此外,还介绍了Redis中跳跃表的节点结构和随机造层策略,帮助读者全面掌握跳跃表的精髓。
写在前面:
关于跳跃表网上的博客抄来抄去大差不差,博主用最通俗的语言给你讲懂
跳跃表是一种有序的数据结构,说到有序,我们很快能想到Redis的五大基本类型之一——Zset的底层数据结构之一,跳跃表的出现就是为了解决在有序表中增删改查的效率问题,跳跃表支持平均o(logn)最坏o(n)的查找复杂度,大部分情况下和红黑树的效率几乎可以媲美,那为什么不用红黑树呢?
有段子说作者不会红黑树,哈哈哈哈,maybe

壹:先通俗地了解什么是跳跃表
这里,结合生活中的栗子给你来通俗地讲解什么是跳跃表:
在我生活的城市,有那么一条公交线,站间隔短,站总数过多,导致每次坐这班车至少一个半小时,心想太慢了
 当然公交公司也注意到了这个问题,为了缓解交通压力,在原本的线路上出了特快专业,加大了站间隔,减少了站总数,大大缩短了通行时间
当然公交公司也注意到了这个问题,为了缓解交通压力,在原本的线路上出了特快专业,加大了站间隔,减少了站总数,大大缩短了通行时间
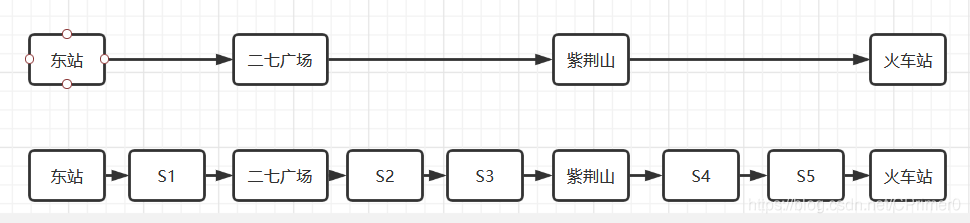 现在来看,假如我想到S5站,先做快车到紫荆山,然后做慢车到S5站,所以灵感来自于生活,跳跃表就是这么个原理,只是跳跃表相对更加复杂,可以有多层线路,下面让我们深入跳跃表
现在来看,假如我想到S5站,先做快车到紫荆山,然后做慢车到S5站,所以灵感来自于生活,跳跃表就是这么个原理,只是跳跃表相对更加复杂,可以有多层线路,下面让我们深入跳跃表
贰:跳跃表两大结构定义
- zskiplist:一个是用于统计跳跃表整体信息的节点,存储了最底层链表的头节点,尾节点,整个跳跃表的最大层数,以及最底层链表节点的个数
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
- zskiplistNode:用于存储节点信息,高层是单向链表,所以高层包括前进指针和跨度,由于底层是双向链表所以还有后指针,以及分值,存储的成员对象
typedef struct zskiplistNode {
robj ele;
double score;
// 后退指针
struct zskiplistNode *backward;
// 层,最多32层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
/**
* 跨度实际上是用来计算元素排名(rank)的,
* 在查找某个节点的过程中,将沿途访过的所有层的跨度累积起来,
* 得到的结果就是目标节点在跳跃表中的排位
*/
unsigned long span;
} level[];
} zskiplistNode;
- 一张图带你了解两个结构的具体含义
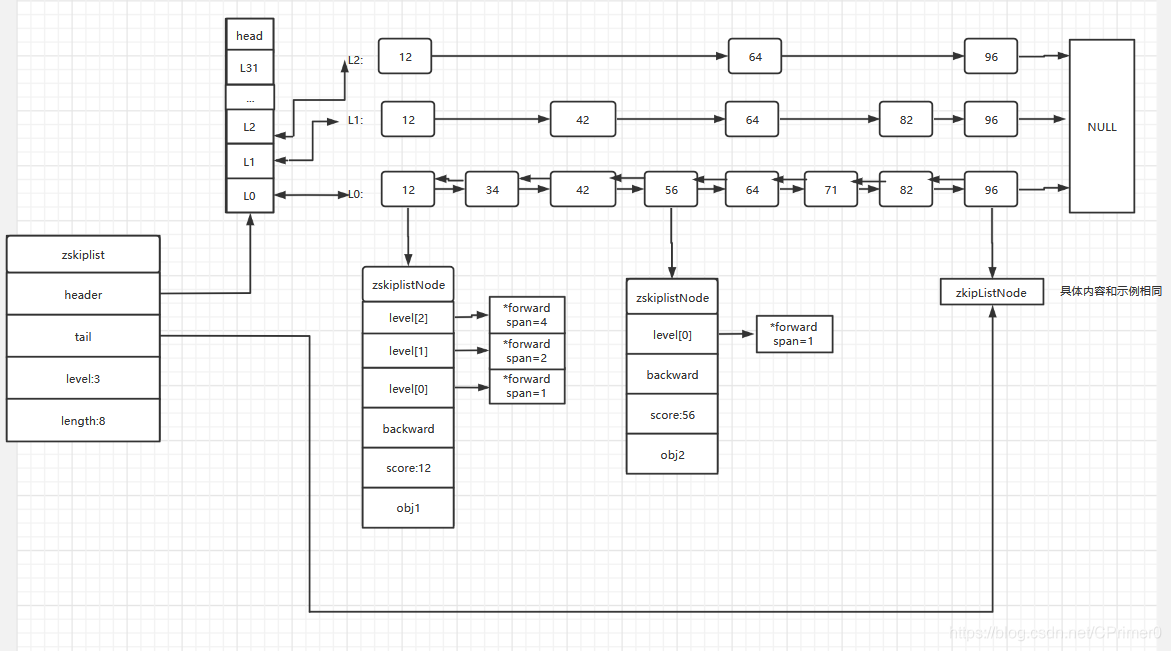
如图所示,头节点是哨兵节点只存储层级信息,不存储具体的信息,最底层是双向链表,上层是单向链表,我相信这张图清晰明了,你绝对能看明白
叁:查找节点流程
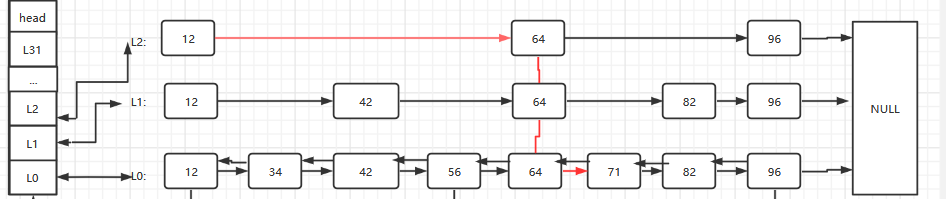 假如我们想要查找分支为71的节点
假如我们想要查找分支为71的节点
- 从最顶层开始比较,发现71>12,向后比较发现71>64,继续向后发现71<96
- 此时向下层寻找,发现71<82
- 继续向下层寻找,最终找到71
肆:插入流程
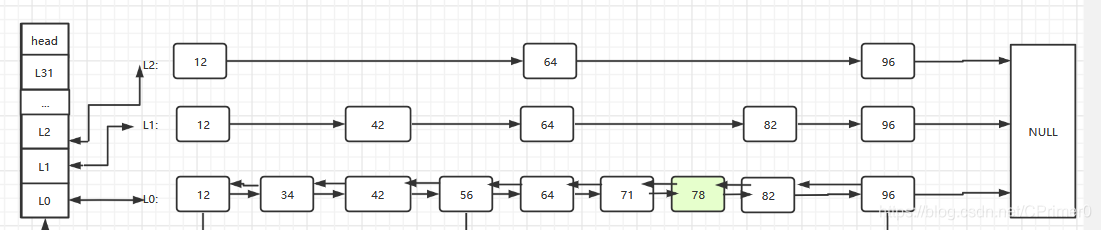
假设我们想插入78
- 首先找到插入位置,和上述步骤相同,然后插入节点,连接前后指针
- 随机造层:如果我们在底层插入了大量的节点,查找效率就会逐渐降低,所以为新插入的节点我们要进行造层,怎么造呢?完全随机,层高都是1至32的随机数
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
这里面有一个宏定义ZSKIPLIST_P ,在源码中定义为了0.25,生成一个随机数,两者同时和16进制数0xFFFF相与后比较,所以每生成一层的概率是0.25,越高的层数越难出现
伍:删除和更新流程
如果你对查找和添加熟悉之后,删除和更新的流程几乎雷同,删除无非就是找到位置,修改指针,更新的流程先找到原位置,删除后插入新的节点,在此就不再重复描述
陆:重点回顾
- 跳跃表是有序结合的底层实现之一
- Redis的跳跃表由zskiplist和zskiplistNode两个结构构成,前者存储跳跃表整体信息,后者存储节点信息
- 每个跳跃节点的曾高都是1-32的随机数
- 跳跃表最终按照分值score排序,分值相同分局成员对象的大小进行排序
以上就是跳跃表的全部内容了,相信用我最通俗的语言和生动形象的图解,你一定明白了其中的奥秘,觉得不错,三连一下,作者最近在更新Redis的全部底层结构,敬请期待

















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









