




SHAP原理
为了计算一个特定特征(比如“特征 A”)对某个预测的贡献(它的 Shapley 值),SHAP 会考虑:
- 所有可能的特征组合(子集/联盟):从没有特征开始,到包含所有特征。
- 特征 A 的边际贡献:对于每一个特征组合,比较“包含特征 A 的组合的预测值”与“不包含特征 A 但包含其他相同特征的组合的预测值”之间的差异。这个差异就是特征 A 在这个特定组合下的“边际贡献”。
- 加权平均:Shapley 值是该特征在**所有可能**的特征组合中边际贡献的加权平均值。权重确保了分配的公平性。
根据上述原理,SHAP 需要为每个样本的每个特征计算一个贡献值(SHAP 值):
- 解释单个预测:SHAP 的核心是解释单个预测结果。
- 特征贡献:对于这个预测,我们需要知道每个特征是把它往“高”推了,还是往“低”推了(相对于基准值),以及推了多少。
- 数值化:这个“推力”的大小和方向就是该 特征对该样本预测的 SHAP 值。
因此:
对于回归问题:
- 模型只有一个输出。
- 对 n_samples个样本中的每一个,计算 n_features个特征各自的 SHAP 值。
- 这就自然形成了形状为 (n_samples, n_features) 的数组。 shap_values [i, j] 代表第 i 个样本的第 j 个特征对该样本预测值的贡献。
对于分类问题:
- 模型通常为每个类别输出一个分数或概率。
- SHAP 需要解释模型是如何得到每个类别的分数的。
- 因此,对 n_samples 个样本中的每一个,分别为每个类别计算 n_features 个特征的 SHAP 值。
- 最常见的组织方式是返回一个列表,列表长度等于类别数。列表的第 k 个元素是一个 (n_samples, n_features) 的数组,表示所有样本的所有特征对预测类别 k 的贡献。
- shap_values[k][i, j] 代表第 i 个样本的第 j 个特征对该样本预测类别 k 的贡献。
总结
SHAP 通过计算每个特征对单个预测(相对于平均预测)的边际贡献(Shapley 值),提供了一种将模型预测分解到每个特征上的方法。这种分解对于每个样本和每个特征(以及分类问题中的每个类别)都需要进行,因此生成了我们看到的 shap_values 数组结构。
import shap
import matplotlib.pyplot as plt
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)
# 计算 SHAP 值(基于测试集),这个shap_values是一个numpy数组,表示每个特征对每个样本的贡献值
# 这里大家先知道这是个numpy数组即可,我们后面学习完numpy在来回头解读这个值
shap_values = explainer.shap_values(X_test) # 这个计算耗时SHAP的维度要求
分类问题和回归问题输出的shap_values的形状不同。
- 分类问题:shap_values.shape =(n_samples, n_features, n_classes)
- 回归问题:shap_values.shape = (n_samples, n_features)
数据维度的要求将是未来学习神经网络最重要的东西之一。
shap_values # 每一行代表一个样本,每一列代表一个特征,值表示该特征对该样本的预测结果的影响程度。正值表示该特征对预测结果有正向影响,负值表示负向影响。shap_values 是一个矩阵(二维数组),其中:
- 行 :对应数据集中的每个样本
- 列 :对应数据集中的每个特征
- 值 :表示该特征对对应样本预测结果的影响程度和方向
- 正值 :特征对预测结果有 正向影响 (增加预测值)
- 负值 :特征对预测结果有 负向影响 (降低预测值)
示例理解
假设在一个心脏病预测模型中:
- shap_values[0, 2] = 0.8 表示第1个样本中,第3个特征(如年龄)对预测结果有0.8的正向贡献
- shap_values[1, 5] = -0.3 表示第2个样本中,第6个特征(如胆固醇水平)对预测结果有-0.3的负向贡献
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数SHAP类别
SHAP 特征重要性条形图 (Summary Plot - Bar)
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()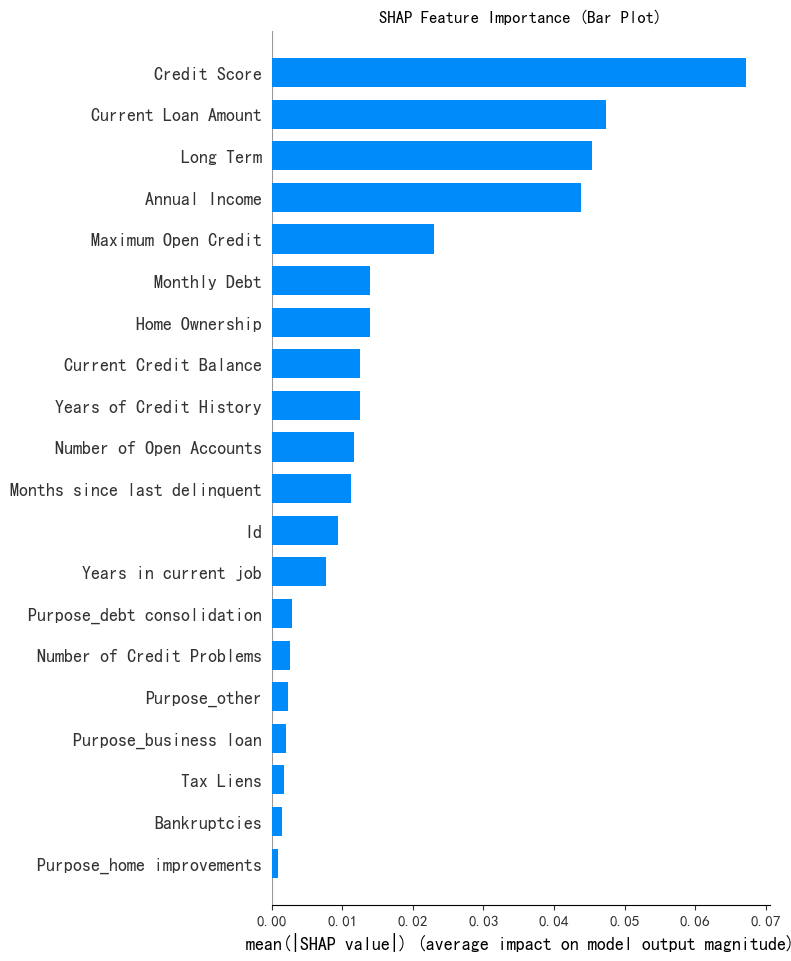
SHAP 特征重要性蜂巢图 (Summary Plot - Violin)
# --- 2. SHAP 特征重要性蜂巢图 (Summary Plot - Violin) ---
print("--- 2. SHAP 特征重要性蜂巢图 ---")
shap.summary_plot(shap_values[:, :, 0], X_test,plot_type="violin",show=False,max_display=10) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()
# 注意下上面几个参数,plot_type可以是bar和violin,max_display表示显示前多少个特征,默认是20个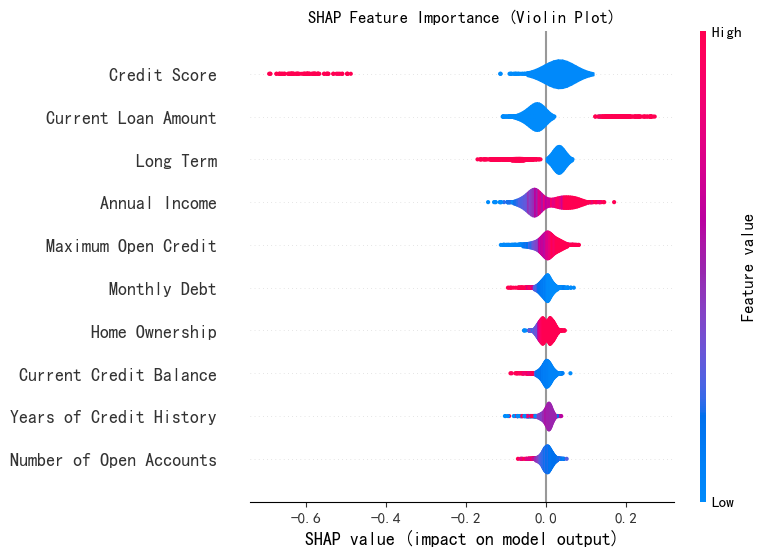
SHAP 特征重要性依赖图
# --- 3. SHAP 特征重要性依赖图 ---
print("--- SHAP 特征重要性依赖图 ---")
shap.dependence_plot('Monthly Debt', shap_values[:, :, 0], X_test,
display_features=X_test,
interaction_index='Credit Score',show=False)
plt.title('Monthly Debt和Credit Score特征依赖图')
plt.show()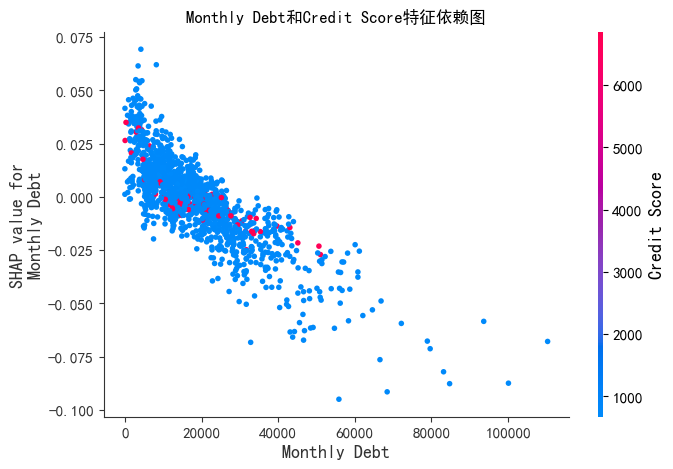
SHAP 特征重要性力图
# --- 4. SHAP 特征重要性力图 ---
print("--- 4. SHAP 特征重要性力图 ---")
shap.force_plot(explainer.expected_value[0],
shap_values[0, :, 0],
X_test.iloc[0],
matplotlib=True,
show=False,
text_rotation=30)
plt.title("SHAP Force Plot for Single Sample")
plt.show()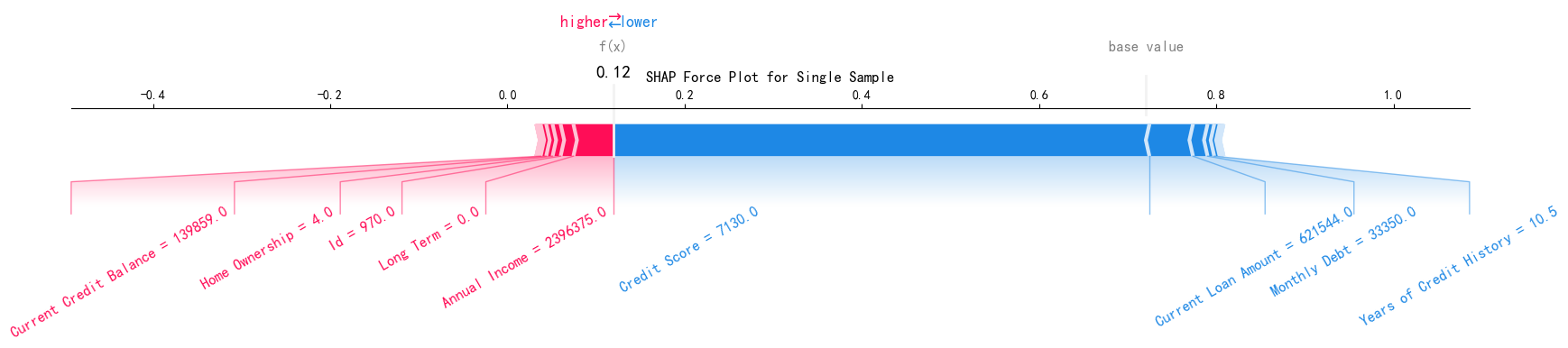
SHAP 特征重要性决策图
# --- 5. SHAP 特征重要性决策图 ---
print("--- 5. SHAP 特征重要性决策图 ---")
shap.decision_plot(explainer.expected_value[0],
shap_values[0,:,0],
X_test.iloc[0],
#feature_order='hclust',
show=False)
plt.title("SHAP Decision Plot")
plt.show()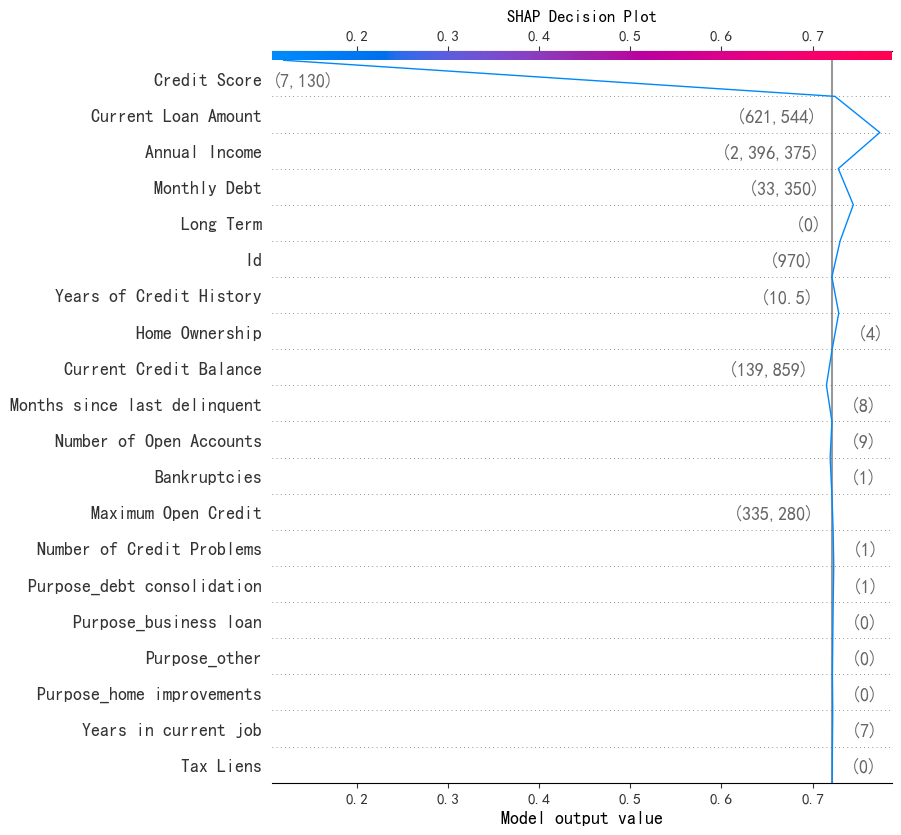

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









