




工作原因目前对yolov8的依赖比较紧密,乘着周末,来回顾一下yolov8目标检测模型关于损失函数的一些旧识以及之前没有关注过的细节。
一、相关旧识基础
1.1 模型输出层
Yolo系列模型整体都是采用 backbone+neck+head 的架构完成视觉任务的,这个在网上也可以搜索到大量的资料,且也不是今天分享的重点,这里一笔带过;这里简单提一下基于目标检测模型的输出head的结构;
对于官方提供的预训练模型,模型会将图片的输入通过不同尺度的特征提取,将其进行三个倍率的缩放,输出80*80、40*40、20*20的特征图,共计8400个特征点。
1.2 训练集样式
不管是txt类型的标注文档还是json的标注文档,一个待识别物体的标注内容都会包含 1+4 的结构,1代表分类编号,4代表box框的坐标。
1.3 模型最终输出张量
既然标签包含类别和box框两个元素,那这两个元素最终是要在模型输出中体现出来的,以便于后面进行loss计算或者NMS后输出;
以官方的80个类别预测为例,模型的最终输出有两个张量尺寸分别为【batchsize,8400,80】【batchsize,8400,64】,前面的batchsize和8400不需要过多解释,80代表该物体是80类别的概率分布,64=4*16代表该物体的box框的四边相较于某一个特征点中心在原图(anchor)的偏移量;
二、损失函数相关
2.1 子损失函数
上面说了模型的输出分为两个部分,一部分是对模型分类的预测输出,一部分是对box框偏移量回归的预测输出,那自然会有计算分类的loss和计算box回归的loss;但是如下图所示,在训练模型的过程中会出现三个loss的阶段性结果,那两个分支怎么会出现三个loss呢?下面对这三个loss分别介绍。
2.2 损失函数源码
在ultralytics库的utils/loss.py可以找到v8损失函数的源码,里面不光定义了目标检测的损失函数,实例分割、姿态估计的损失函数也都在里面,如下:
# loss.py
# Ultralytics YOLO 🚀, AGPL-3.0 license
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.metrics import OKS_SIGMA
from ultralytics.utils.ops import crop_mask, xywh2xyxy, xyxy2xywh
from ultralytics.utils.tal import RotatedTaskAlignedAssigner, TaskAlignedAssigner, dist2bbox, dist2rbox, make_anchors
from ultralytics.utils.torch_utils import autocast
from .metrics import bbox_iou, probiou
from .tal import bbox2dist
class VarifocalLoss(nn.Module):
"""
Varifocal loss by Zhang et al.
https://arxiv.org/abs/2008.13367.
"""
def __init__(self):
"""Initialize the VarifocalLoss class."""
super().__init__()
@staticmethod
def forward(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
"""Computes varfocal loss."""
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with autocast(enabled=False):
loss = (
(F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction="none") * weight)
.mean(1)
.sum()
)
return loss
class FocalLoss(nn.Module):
"""Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)."""
def __init__(self):
"""Initializer for FocalLoss class with no parameters."""
super().__init__()
@staticmethod
def forward(pred, label, gamma=1.5, alpha=0.25):
"""Calculates and updates confusion matrix for object detection/classification tasks."""
loss = F.binary_cross_entropy_with_logits(pred, label, reduction="none")
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = pred.sigmoid() # prob from logits
p_t = label * pred_prob + (1 - label) * (1 - pred_prob)
modulating_factor = (1.0 - p_t) ** gamma
loss *= modulating_factor
if alpha > 0:
alpha_factor = label * alpha + (1 - label) * (1 - alpha)
loss *= alpha_factor
return loss.mean(1).sum()
class DFLoss(nn.Module):
"""Criterion class for computing DFL losses during training."""
def __init__(self, reg_max=16) -> None:
"""Initialize the DFL module."""
super().__init__()
self.reg_max = reg_max
def __call__(self, pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
target = target.clamp_(0, self.reg_max - 1 - 0.01)
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max=16):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else None
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.dfl_loss:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1)
loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
class RotatedBboxLoss(BboxLoss):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__(reg_max)
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = probiou(pred_bboxes[fg_mask], target_bboxes[fg_mask])
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.dfl_loss:
target_ltrb = bbox2dist(anchor_points, xywh2xyxy(target_bboxes[..., :4]), self.dfl_loss.reg_max - 1)
loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
class KeypointLoss(nn.Module):
"""Criterion class for computing training losses."""
def __init__(self, sigmas) -> None:
"""Initialize the KeypointLoss class."""
super().__init__()
self.sigmas = sigmas
def forward(self, pred_kpts, gt_kpts, kpt_mask, area):
"""Calculates keypoint loss factor and Euclidean distance loss for predicted and actual keypoints."""
d = (pred_kpts[..., 0] - gt_kpts[..., 0]).pow(2) + (pred_kpts[..., 1] - gt_kpts[..., 1]).pow(2)
kpt_loss_factor = kpt_mask.shape[1] / (torch.sum(kpt_mask != 0, dim=1) + 1e-9)
# e = d / (2 * (area * self.sigmas) ** 2 + 1e-9) # from formula
e = d / ((2 * self.sigmas).pow(2) * (area + 1e-9) * 2) # from cocoeval
return (kpt_loss_factor.view(-1, 1) * ((1 - torch.exp(-e)) * kpt_mask)).mean()
class v8DetectionLoss:
"""Criterion class for computing training losses."""
def __init__(self, model, tal_topk=10): # model must be de-paralleled
"""Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""
device = next(model.parameters()).device # get model device
h = model.args # hyperparameters
m = model.model[-1] # Detect() module
self.bce = nn.BCEWithLogitsLoss(reduction="none")
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.no = m.nc + m.reg_max * 4
self.reg_max = m.reg_max
self.device = device
self.use_dfl = m.reg_max > 1
self.assigner = TaskAlignedAssigner(topk=tal_topk, num_classes=self.nc, alpha=0.5, beta=6.0)
self.bbox_loss = BboxLoss(m.reg_max).to(device)
self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
def preprocess(self, targets, batch_size, scale_tensor):
"""Preprocesses the target counts and matches with the input batch size to output a tensor."""
nl, ne = targets.shape
if nl == 0:
out = torch.zeros(batch_size, 0, ne - 1, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
counts = counts.to(dtype=torch.int32)
out = torch.zeros(batch_size, counts.max(), ne - 1, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
"""Decode predicted object bounding box coordinates from anchor points and distribution."""
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, preds, batch):
"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = preds[1] if isinstance(preds, tuple) else preds
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size = pred_scores.shape[0]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
class v8SegmentationLoss(v8DetectionLoss):
"""Criterion class for computing training losses."""
def __init__(self, model): # model must be de-paralleled
"""Initializes the v8SegmentationLoss class, taking a de-paralleled model as argument."""
super().__init__(model)
self.overlap = model.args.overlap_mask
def __call__(self, preds, batch):
"""Calculate and return the loss for the YOLO model."""
loss = torch.zeros(4, device=self.device) # box, cls, dfl
feats, pred_masks, proto = preds if len(preds) == 3 else preds[1]
batch_size, _, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
# B, grids, ..
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_masks = pred_masks.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
try:
batch_idx = batch["batch_idx"].view(-1, 1)
targets = torch.cat((batch_idx, batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
except RuntimeError as e:
raise TypeError(
"ERROR ❌ segment dataset incorrectly formatted or not a segment dataset.\n"
"This error can occur when incorrectly training a 'segment' model on a 'detect' dataset, "
"i.e. 'yolo train model=yolov8n-seg.pt data=coco8.yaml'.\nVerify your dataset is a "
"correctly formatted 'segment' dataset using 'data=coco8-seg.yaml' "
"as an example.\nSee https://docs.ultralytics.com/datasets/segment/ for help."
) from e
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
_, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[2] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
if fg_mask.sum():
# Bbox loss
loss[0], loss[3] = self.bbox_loss(
pred_distri,
pred_bboxes,
anchor_points,
target_bboxes / stride_tensor,
target_scores,
target_scores_sum,
fg_mask,
)
# Masks loss
masks = batch["masks"].to(self.device).float()
if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
masks = F.interpolate(masks[None], (mask_h, mask_w), mode="nearest")[0]
loss[1] = self.calculate_segmentation_loss(
fg_mask, masks, target_gt_idx, target_bboxes, batch_idx, proto, pred_masks, imgsz, self.overlap
)
# WARNING: lines below prevent Multi-GPU DDP 'unused gradient' PyTorch errors, do not remove
else:
loss[1] += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan loss
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.box # seg gain
loss[2] *= self.hyp.cls # cls gain
loss[3] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
@staticmethod
def single_mask_loss(
gt_mask: torch.Tensor, pred: torch.Tensor, proto: torch.Tensor, xyxy: torch.Tensor, area: torch.Tensor
) -> torch.Tensor:
"""
Compute the instance segmentation loss for a single image.
Args:
gt_mask (torch.Tensor): Ground truth mask of shape (n, H, W), where n is the number of objects.
pred (torch.Tensor): Predicted mask coefficients of shape (n, 32).
proto (torch.Tensor): Prototype masks of shape (32, H, W).
xyxy (torch.Tensor): Ground truth bounding boxes in xyxy format, normalized to [0, 1], of shape (n, 4).
area (torch.Tensor): Area of each ground truth bounding box of shape (n,).
Returns:
(torch.Tensor): The calculated mask loss for a single image.
Notes:
The function uses the equation pred_mask = torch.einsum('in,nhw->ihw', pred, proto) to produce the
predicted masks from the prototype masks and predicted mask coefficients.
"""
pred_mask = torch.einsum("in,nhw->ihw", pred, proto) # (n, 32) @ (32, 80, 80) -> (n, 80, 80)
loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction="none")
return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).sum()
def calculate_segmentation_loss(
self,
fg_mask: torch.Tensor,
masks: torch.Tensor,
target_gt_idx: torch.Tensor,
target_bboxes: torch.Tensor,
batch_idx: torch.Tensor,
proto: torch.Tensor,
pred_masks: torch.Tensor,
imgsz: torch.Tensor,
overlap: bool,
) -> torch.Tensor:
"""
Calculate the loss for instance segmentation.
Args:
fg_mask (torch.Tensor): A binary tensor of shape (BS, N_anchors) indicating which anchors are positive.
masks (torch.Tensor): Ground truth masks of shape (BS, H, W) if `overlap` is False, otherwise (BS, ?, H, W).
target_gt_idx (torch.Tensor): Indexes of ground truth objects for each anchor of shape (BS, N_anchors).
target_bboxes (torch.Tensor): Ground truth bounding boxes for each anchor of shape (BS, N_anchors, 4).
batch_idx (torch.Tensor): Batch indices of shape (N_labels_in_batch, 1).
proto (torch.Tensor): Prototype masks of shape (BS, 32, H, W).
pred_masks (torch.Tensor): Predicted masks for each anchor of shape (BS, N_anchors, 32).
imgsz (torch.Tensor): Size of the input image as a tensor of shape (2), i.e., (H, W).
overlap (bool): Whether the masks in `masks` tensor overlap.
Returns:
(torch.Tensor): The calculated loss for instance segmentation.
Notes:
The batch loss can be computed for improved speed at higher memory usage.
For example, pred_mask can be computed as follows:
pred_mask = torch.einsum('in,nhw->ihw', pred, proto) # (i, 32) @ (32, 160, 160) -> (i, 160, 160)
"""
_, _, mask_h, mask_w = proto.shape
loss = 0
# Normalize to 0-1
target_bboxes_normalized = target_bboxes / imgsz[[1, 0, 1, 0]]
# Areas of target bboxes
marea = xyxy2xywh(target_bboxes_normalized)[..., 2:].prod(2)
# Normalize to mask size
mxyxy = target_bboxes_normalized * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=proto.device)
for i, single_i in enumerate(zip(fg_mask, target_gt_idx, pred_masks, proto, mxyxy, marea, masks)):
fg_mask_i, target_gt_idx_i, pred_masks_i, proto_i, mxyxy_i, marea_i, masks_i = single_i
if fg_mask_i.any():
mask_idx = target_gt_idx_i[fg_mask_i]
if overlap:
gt_mask = masks_i == (mask_idx + 1).view(-1, 1, 1)
gt_mask = gt_mask.float()
else:
gt_mask = masks[batch_idx.view(-1) == i][mask_idx]
loss += self.single_mask_loss(
gt_mask, pred_masks_i[fg_mask_i], proto_i, mxyxy_i[fg_mask_i], marea_i[fg_mask_i]
)
# WARNING: lines below prevents Multi-GPU DDP 'unused gradient' PyTorch errors, do not remove
else:
loss += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan loss
return loss / fg_mask.sum()
class v8PoseLoss(v8DetectionLoss):
"""Criterion class for computing training losses."""
def __init__(self, model): # model must be de-paralleled
"""Initializes v8PoseLoss with model, sets keypoint variables and declares a keypoint loss instance."""
super().__init__(model)
self.kpt_shape = model.model[-1].kpt_shape
self.bce_pose = nn.BCEWithLogitsLoss()
is_pose = self.kpt_shape == [17, 3]
nkpt = self.kpt_shape[0] # number of keypoints
sigmas = torch.from_numpy(OKS_SIGMA).to(self.device) if is_pose else torch.ones(nkpt, device=self.device) / nkpt
self.keypoint_loss = KeypointLoss(sigmas=sigmas)
def __call__(self, preds, batch):
"""Calculate the total loss and detach it."""
loss = torch.zeros(5, device=self.device) # box, cls, dfl, kpt_location, kpt_visibility
feats, pred_kpts = preds if isinstance(preds[0], list) else preds[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
# B, grids, ..
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_kpts = pred_kpts.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
batch_size = pred_scores.shape[0]
batch_idx = batch["batch_idx"].view(-1, 1)
targets = torch.cat((batch_idx, batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_kpts = self.kpts_decode(anchor_points, pred_kpts.view(batch_size, -1, *self.kpt_shape)) # (b, h*w, 17, 3)
_, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[3] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor
loss[0], loss[4] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
keypoints = batch["keypoints"].to(self.device).float().clone()
keypoints[..., 0] *= imgsz[1]
keypoints[..., 1] *= imgsz[0]
loss[1], loss[2] = self.calculate_keypoints_loss(
fg_mask, target_gt_idx, keypoints, batch_idx, stride_tensor, target_bboxes, pred_kpts
)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.pose # pose gain
loss[2] *= self.hyp.kobj # kobj gain
loss[3] *= self.hyp.cls # cls gain
loss[4] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
@staticmethod
def kpts_decode(anchor_points, pred_kpts):
"""Decodes predicted keypoints to image coordinates."""
y = pred_kpts.clone()
y[..., :2] *= 2.0
y[..., 0] += anchor_points[:, [0]] - 0.5
y[..., 1] += anchor_points[:, [1]] - 0.5
return y
def calculate_keypoints_loss(
self, masks, target_gt_idx, keypoints, batch_idx, stride_tensor, target_bboxes, pred_kpts
):
"""
Calculate the keypoints loss for the model.
This function calculates the keypoints loss and keypoints object loss for a given batch. The keypoints loss is
based on the difference between the predicted keypoints and ground truth keypoints. The keypoints object loss is
a binary classification loss that classifies whether a keypoint is present or not.
Args:
masks (torch.Tensor): Binary mask tensor indicating object presence, shape (BS, N_anchors).
target_gt_idx (torch.Tensor): Index tensor mapping anchors to ground truth objects, shape (BS, N_anchors).
keypoints (torch.Tensor): Ground truth keypoints, shape (N_kpts_in_batch, N_kpts_per_object, kpts_dim).
batch_idx (torch.Tensor): Batch index tensor for keypoints, shape (N_kpts_in_batch, 1).
stride_tensor (torch.Tensor): Stride tensor for anchors, shape (N_anchors, 1).
target_bboxes (torch.Tensor): Ground truth boxes in (x1, y1, x2, y2) format, shape (BS, N_anchors, 4).
pred_kpts (torch.Tensor): Predicted keypoints, shape (BS, N_anchors, N_kpts_per_object, kpts_dim).
Returns:
(tuple): Returns a tuple containing:
- kpts_loss (torch.Tensor): The keypoints loss.
- kpts_obj_loss (torch.Tensor): The keypoints object loss.
"""
batch_idx = batch_idx.flatten()
batch_size = len(masks)
# Find the maximum number of keypoints in a single image
max_kpts = torch.unique(batch_idx, return_counts=True)[1].max()
# Create a tensor to hold batched keypoints
batched_keypoints = torch.zeros(
(batch_size, max_kpts, keypoints.shape[1], keypoints.shape[2]), device=keypoints.device
)
# TODO: any idea how to vectorize this?
# Fill batched_keypoints with keypoints based on batch_idx
for i in range(batch_size):
keypoints_i = keypoints[batch_idx == i]
batched_keypoints[i, : keypoints_i.shape[0]] = keypoints_i
# Expand dimensions of target_gt_idx to match the shape of batched_keypoints
target_gt_idx_expanded = target_gt_idx.unsqueeze(-1).unsqueeze(-1)
# Use target_gt_idx_expanded to select keypoints from batched_keypoints
selected_keypoints = batched_keypoints.gather(
1, target_gt_idx_expanded.expand(-1, -1, keypoints.shape[1], keypoints.shape[2])
)
# Divide coordinates by stride
selected_keypoints /= stride_tensor.view(1, -1, 1, 1)
kpts_loss = 0
kpts_obj_loss = 0
if masks.any():
gt_kpt = selected_keypoints[masks]
area = xyxy2xywh(target_bboxes[masks])[:, 2:].prod(1, keepdim=True)
pred_kpt = pred_kpts[masks]
kpt_mask = gt_kpt[..., 2] != 0 if gt_kpt.shape[-1] == 3 else torch.full_like(gt_kpt[..., 0], True)
kpts_loss = self.keypoint_loss(pred_kpt, gt_kpt, kpt_mask, area) # pose loss
if pred_kpt.shape[-1] == 3:
kpts_obj_loss = self.bce_pose(pred_kpt[..., 2], kpt_mask.float()) # keypoint obj loss
return kpts_loss, kpts_obj_loss
class v8ClassificationLoss:
"""Criterion class for computing training losses."""
def __call__(self, preds, batch):
"""Compute the classification loss between predictions and true labels."""
loss = F.cross_entropy(preds, batch["cls"], reduction="mean")
loss_items = loss.detach()
return loss, loss_items
class v8OBBLoss(v8DetectionLoss):
"""Calculates losses for object detection, classification, and box distribution in rotated YOLO models."""
def __init__(self, model):
"""Initializes v8OBBLoss with model, assigner, and rotated bbox loss; note model must be de-paralleled."""
super().__init__(model)
self.assigner = RotatedTaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
self.bbox_loss = RotatedBboxLoss(self.reg_max).to(self.device)
def preprocess(self, targets, batch_size, scale_tensor):
"""Preprocesses the target counts and matches with the input batch size to output a tensor."""
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 6, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
counts = counts.to(dtype=torch.int32)
out = torch.zeros(batch_size, counts.max(), 6, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
bboxes = targets[matches, 2:]
bboxes[..., :4].mul_(scale_tensor)
out[j, :n] = torch.cat([targets[matches, 1:2], bboxes], dim=-1)
return out
def __call__(self, preds, batch):
"""Calculate and return the loss for the YOLO model."""
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats, pred_angle = preds if isinstance(preds[0], list) else preds[1]
batch_size = pred_angle.shape[0] # batch size, number of masks, mask height, mask width
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
# b, grids, ..
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_angle = pred_angle.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
try:
batch_idx = batch["batch_idx"].view(-1, 1)
targets = torch.cat((batch_idx, batch["cls"].view(-1, 1), batch["bboxes"].view(-1, 5)), 1)
rw, rh = targets[:, 4] * imgsz[0].item(), targets[:, 5] * imgsz[1].item()
targets = targets[(rw >= 2) & (rh >= 2)] # filter rboxes of tiny size to stabilize training
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 5), 2) # cls, xywhr
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
except RuntimeError as e:
raise TypeError(
"ERROR ❌ OBB dataset incorrectly formatted or not a OBB dataset.\n"
"This error can occur when incorrectly training a 'OBB' model on a 'detect' dataset, "
"i.e. 'yolo train model=yolov8n-obb.pt data=dota8.yaml'.\nVerify your dataset is a "
"correctly formatted 'OBB' dataset using 'data=dota8.yaml' "
"as an example.\nSee https://docs.ultralytics.com/datasets/obb/ for help."
) from e
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri, pred_angle) # xyxy, (b, h*w, 4)
bboxes_for_assigner = pred_bboxes.clone().detach()
# Only the first four elements need to be scaled
bboxes_for_assigner[..., :4] *= stride_tensor
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(),
bboxes_for_assigner.type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes[..., :4] /= stride_tensor
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
else:
loss[0] += (pred_angle * 0).sum()
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
def bbox_decode(self, anchor_points, pred_dist, pred_angle):
"""
Decode predicted object bounding box coordinates from anchor points and distribution.
Args:
anchor_points (torch.Tensor): Anchor points, (h*w, 2).
pred_dist (torch.Tensor): Predicted rotated distance, (bs, h*w, 4).
pred_angle (torch.Tensor): Predicted angle, (bs, h*w, 1).
Returns:
(torch.Tensor): Predicted rotated bounding boxes with angles, (bs, h*w, 5).
"""
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
return torch.cat((dist2rbox(pred_dist, pred_angle, anchor_points), pred_angle), dim=-1)
class E2EDetectLoss:
"""Criterion class for computing training losses."""
def __init__(self, model):
"""Initialize E2EDetectLoss with one-to-many and one-to-one detection losses using the provided model."""
self.one2many = v8DetectionLoss(model, tal_topk=10)
self.one2one = v8DetectionLoss(model, tal_topk=1)
def __call__(self, preds, batch):
"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""
preds = preds[1] if isinstance(preds, tuple) else preds
one2many = preds["one2many"]
loss_one2many = self.one2many(one2many, batch)
one2one = preds["one2one"]
loss_one2one = self.one2one(one2one, batch)
return loss_one2many[0] + loss_one2one[0], loss_one2many[1] + loss_one2one[1]
2.3 目标检测loss
在该源码中我们找到 class v8DetectionLoss 就是目标检测的loss,如下:
class v8DetectionLoss:
"""Criterion class for computing training losses."""
def __init__(self, model, tal_topk=10): # model must be de-paralleled
"""Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""
device = next(model.parameters()).device # get model device
h = model.args # hyperparameters
m = model.model[-1] # Detect() module
self.bce = nn.BCEWithLogitsLoss(reduction="none")
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.no = m.nc + m.reg_max * 4
self.reg_max = m.reg_max
self.device = device
self.use_dfl = m.reg_max > 1
self.assigner = TaskAlignedAssigner(topk=tal_topk, num_classes=self.nc, alpha=0.5, beta=6.0)
self.bbox_loss = BboxLoss(m.reg_max).to(device)
self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
def preprocess(self, targets, batch_size, scale_tensor):
"""Preprocesses the target counts and matches with the input batch size to output a tensor."""
nl, ne = targets.shape
if nl == 0:
out = torch.zeros(batch_size, 0, ne - 1, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
counts = counts.to(dtype=torch.int32)
out = torch.zeros(batch_size, counts.max(), ne - 1, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
"""Decode predicted object bounding box coordinates from anchor points and distribution."""
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, preds, batch):
"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = preds[1] if isinstance(preds, tuple) else preds
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size = pred_scores.shape[0]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
这里不逐行的去讲解这个代码,不过可以在call函数中看到loss是一个列表,包含box、cls、dfl三部分;
2.3.1 分类损失函数loss
从下面这的注释和代码可以识别loss[1]就是分类函数的loss,可以看到其实它采用的是一个二元交叉熵损失(BEC)来作为分类的损失函数,关于BEC的原理可以自行,它以及它的变种常用于分类任务;
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
这里有一个可以改进的小点分享一下,也是最近遇到的一个问题的有效解决方案;就是当你的训练集样本类别数据不均衡导致对某些类别识别比较差时,但你有因为数据有限不能补充效果差的类别的数据时,可以将BEC损失替换为包含类别权重张量的损失函数,可以有效缓解较少训练集类别的识别效果,修改方式如下:
步骤 1:计算类别权重
首先,你需要根据你的数据集统计每个类别的样本数量,并计算权重。常用的方法有:
- Inverse Frequency Weighting:
class_weights = total_samples / (num_classes * class_counts) - Log-based Weighting(更平滑):
class_weights = 1.0 / np.log(1.02 + class_counts / np.min(class_counts))
你可以使用
ultralytics提供的工具统计类别分布:yolo task=detect mode=val model=yolov8n.pt data=coco.yaml plots=True
步骤 2:修改 YOLOv8 损失函数源码
定位到 v8DetectionLoss 类中的 __call__ 方法,找到分类损失的计算部分:
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
修改为使用带权重的 BCE:
import torch
import torch.nn.functional as F
# 假设你已经计算好 class_weights,形状为 (nc,),nc=80
# 例如:class_weights = torch.tensor([0.8, 1.2, ..., 2.5], device=pred_cls.device)
# 将 class_weights 扩展为 (1, nc) 以便广播
class_weights_tensor = class_weights.unsqueeze(0) # (1, nc)
# 使用带权重的 BCEWithLogitsLoss(推荐,数值更稳定)
# 注意:pred_cls 是未经过 sigmoid 的 logits
loss[1] = F.binary_cross_entropy_with_logits(
pred_cls,
target_cls,
pos_weight=class_weights_tensor # pos_weight 用于正样本加权
)
🔥 关键点:
- 使用
F.binary_cross_entropy_with_logits而不是BCELoss + sigmoid,因为它更稳定。pos_weight参数正是用于对正样本(positive)进行加权。类别样本越少,pos_weight越大,该类正样本的损失贡献越大。
步骤 3:将 class_weights 传入损失函数
你可以在 v8DetectionLoss 初始化时传入 class_weights,例如:
class v8DetectionLoss:
def __init__(self, model, autobalance=False, class_weights=None):
self.class_weights = class_weights if class_weights is not None else torch.ones(nc)
# ... 其他初始化
2.3.2 box回归损失函数loss
对于box回归的损失函数又包含两个子函数iou_loss和dfl_loss,从源码中我们也是可以看到这一点,我们分别讲解其作用;
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
2.3.2.1 iou_loss
其实也很好理解,我们都知道在模型后处理有一个NMS(非极大值抑制)的过程,其核心就是计算预测框之间的交并比(iou)来进行过滤,这里也是一样,通过计算预测框和真实标签框之间的iou作为损失函数来不断迭代模型权重,使得预测框和真实框更加的吻合,代码如下:
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
oss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
2.3.2.2 dfl_loss
这个损失函数的设定就没有那么的显而易见,首先这个损失函数做的事情就是计算锚框(在v8中没有锚框,其实就是每个特征点在原图的中心坐标)中心点到预测框上下左右四个边的距离,然后再计算锚框中心点到真实框上下左右四个边的距离,对比两个距离的差值,将预测框的偏移量向真实框靠拢,代码如下:
class DFLoss(nn.Module):
"""Criterion class for computing DFL losses during training."""
def __init__(self, reg_max=16) -> None:
"""Initialize the DFL module."""
super().__init__()
self.reg_max = reg_max
def __call__(self, pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
target = target.clamp_(0, self.reg_max - 1 - 0.01)
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
但是我们可以注意到,明明这是一个回归问题,但是却使用了分类才使用的交叉熵函数来计算loss,这里就需要特别说明一下v8的设计;
首先这个问题确实是一个回归问题,目的是预测偏移量,是4个连续的值,但是在v8中,大佬将这个回归问题转换成了一个分类的问题;大佬将最大偏移量划分为n个小段(默认n=16),然后预测这个偏移量落在某一个小段的概率,这样就将一个连续问题离散化为一个分类问题,然后通过下面的函数将其转化为一个标量:
#在 ultralytics/nn/modules.py 或 utils/ops.py 中可以找到类似逻辑:
def bbox_decode(dist, anchors):
"""Decode distribution to bbox coordinates."""
cdf = dist.cumsum(dim=-1)
# 或者使用期望
bins = torch.arange(dist.shape[-1], device=dist.device)
xy = (dist.softmax(dim=-1) * bins).sum(dim=-1)
return xy
注:n的值可以改变,值越大控制偏移量越精细,反之越粗糙;
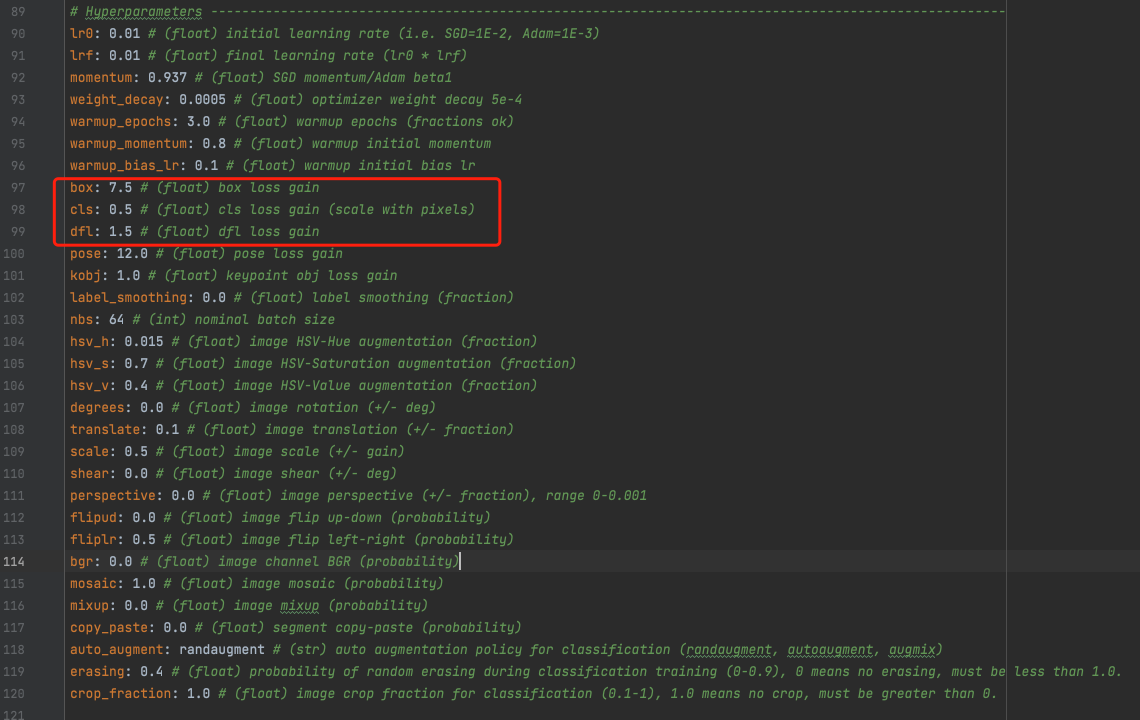
三、总结
将上述三个子损失函数加权相加就组成了目标检测的损失函数,这三个子函数的权重调节可以在模型超参配置文件(ultralytics/cfg/default.yaml)的 Hyperparameters 区域进行设置,如下图:



















 1965
1965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









