



知识点:
1.独热编码和缺失值填补的顺序关系
2.部分代码不能跳步执行的原因
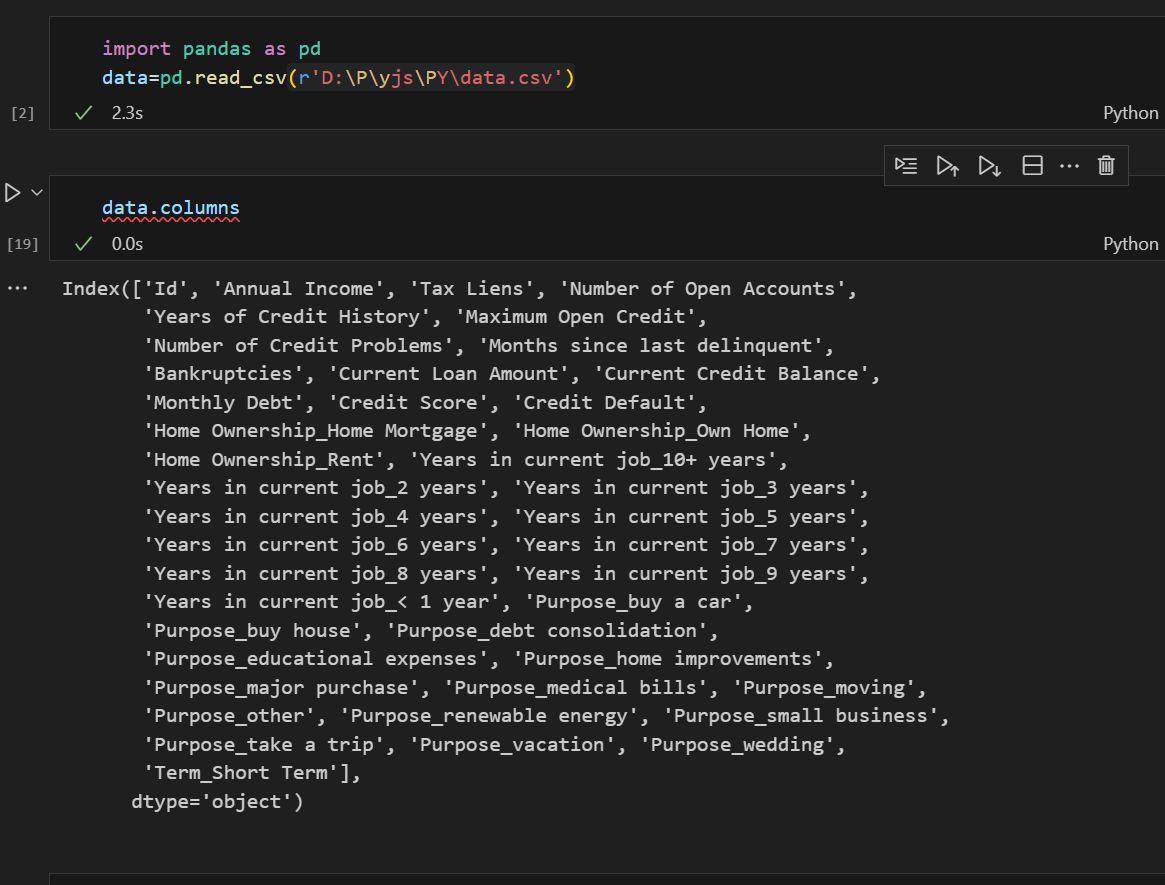
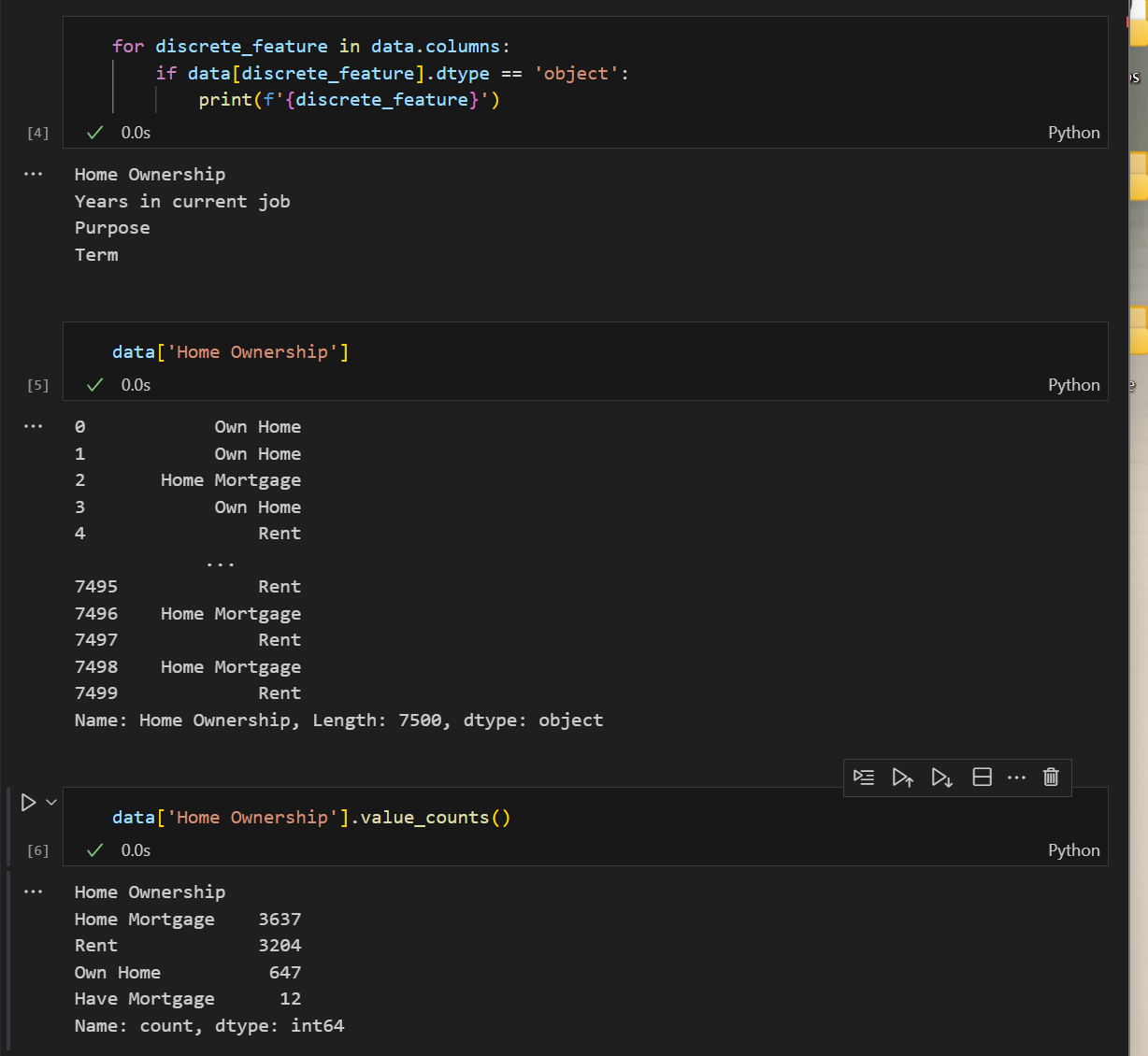
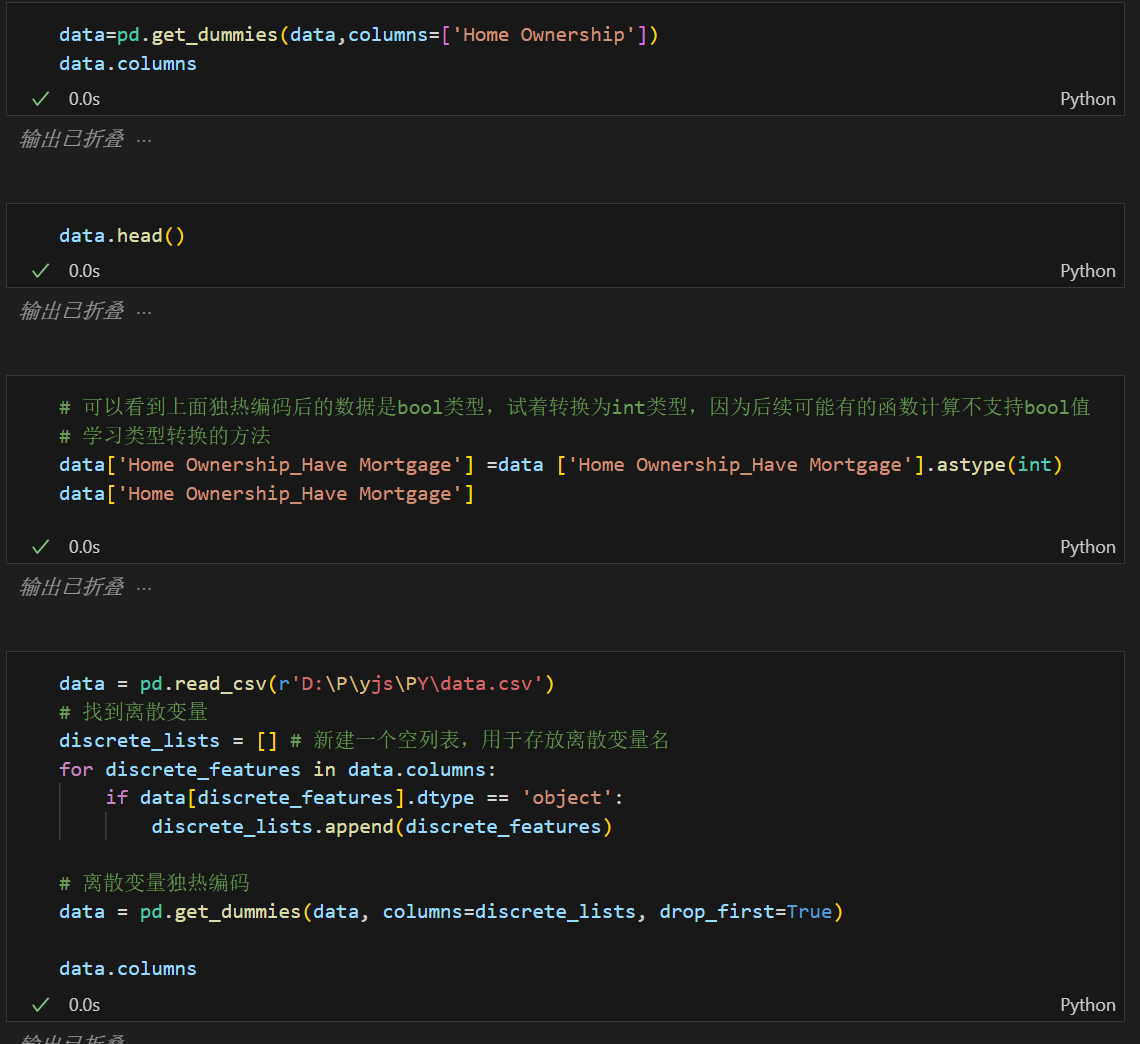
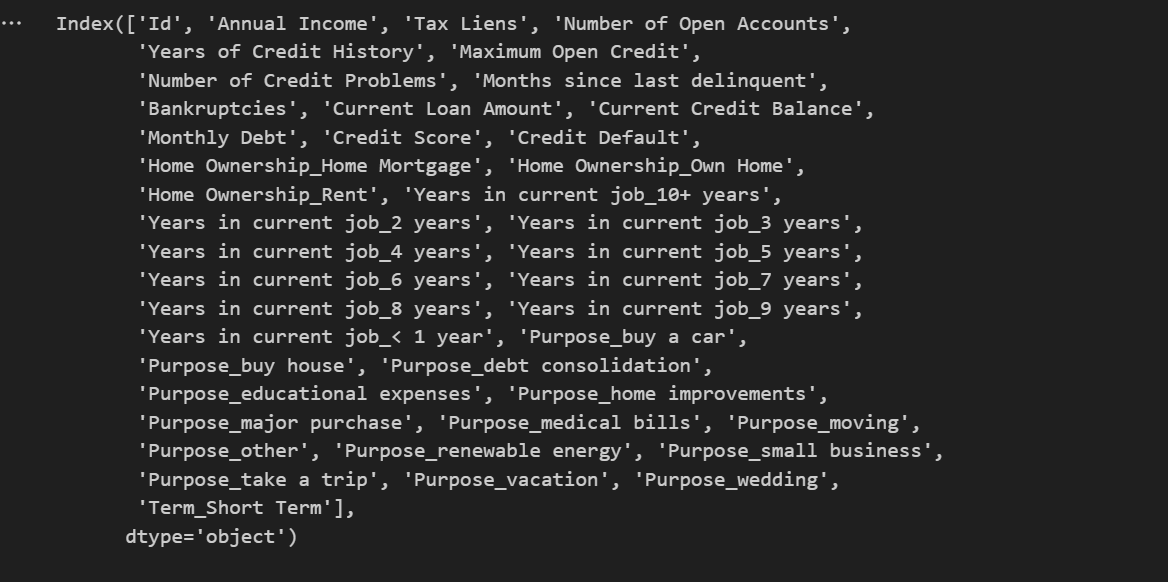
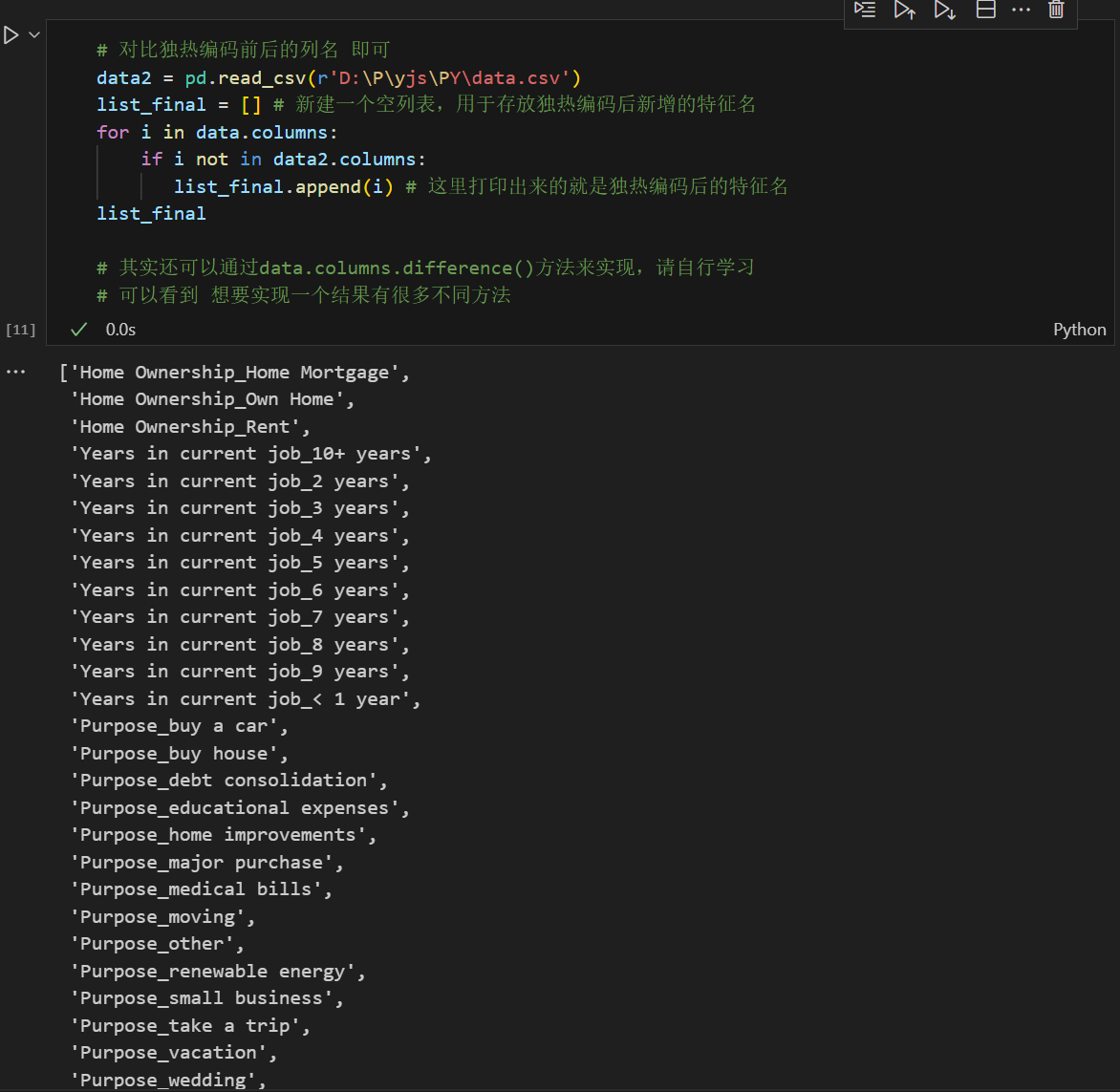
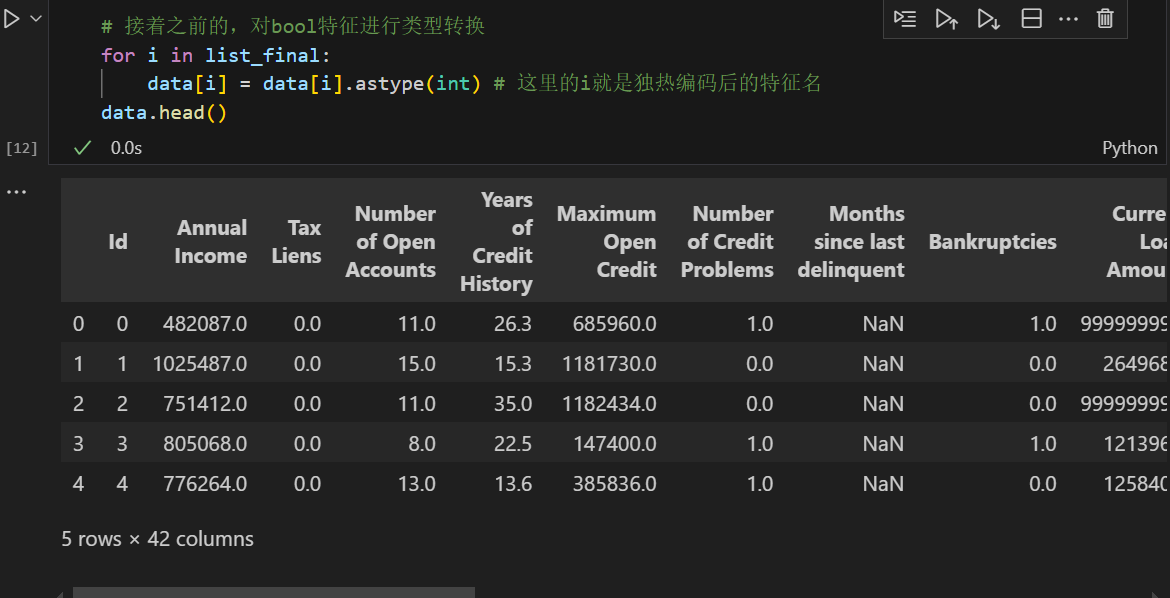
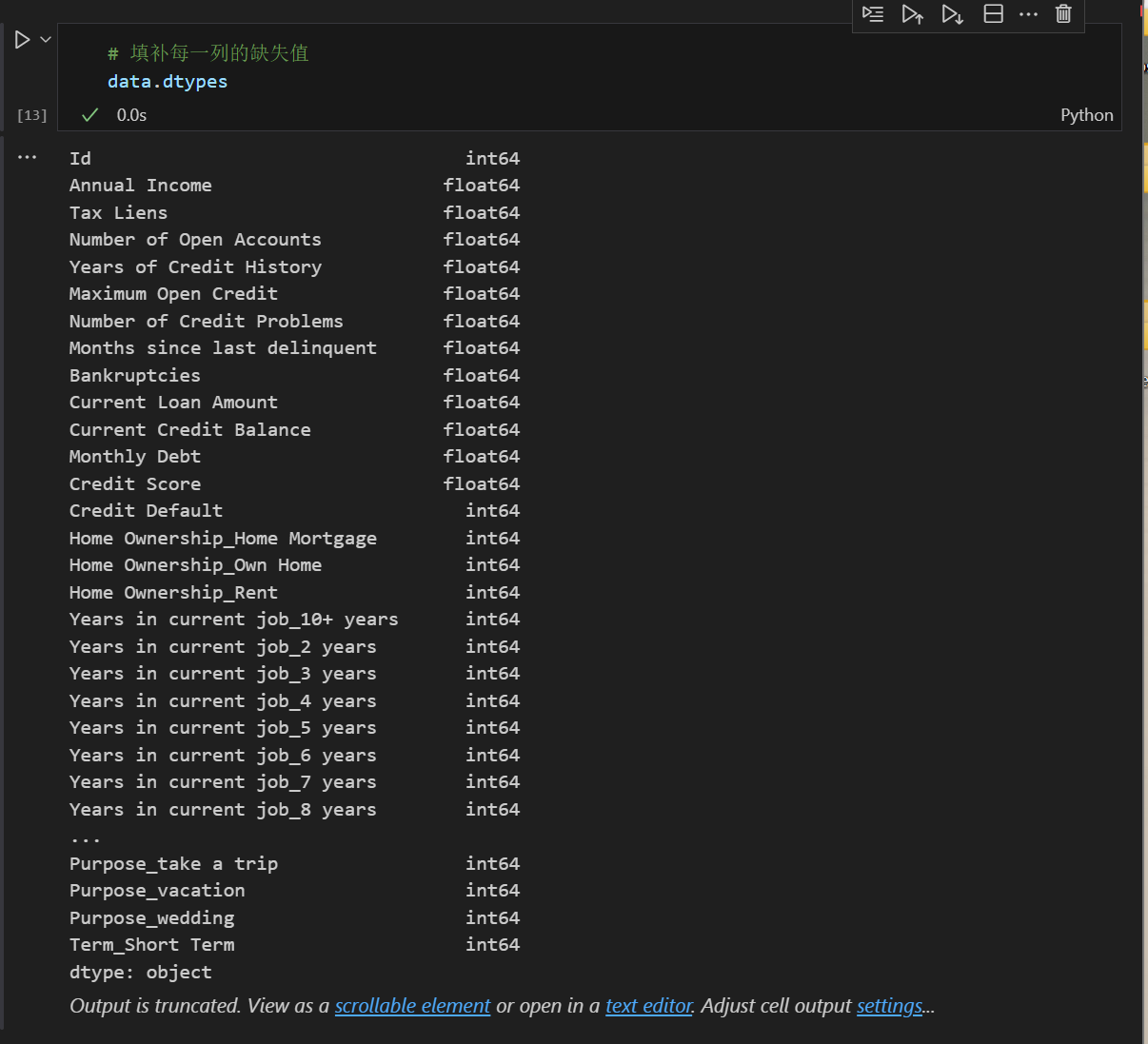
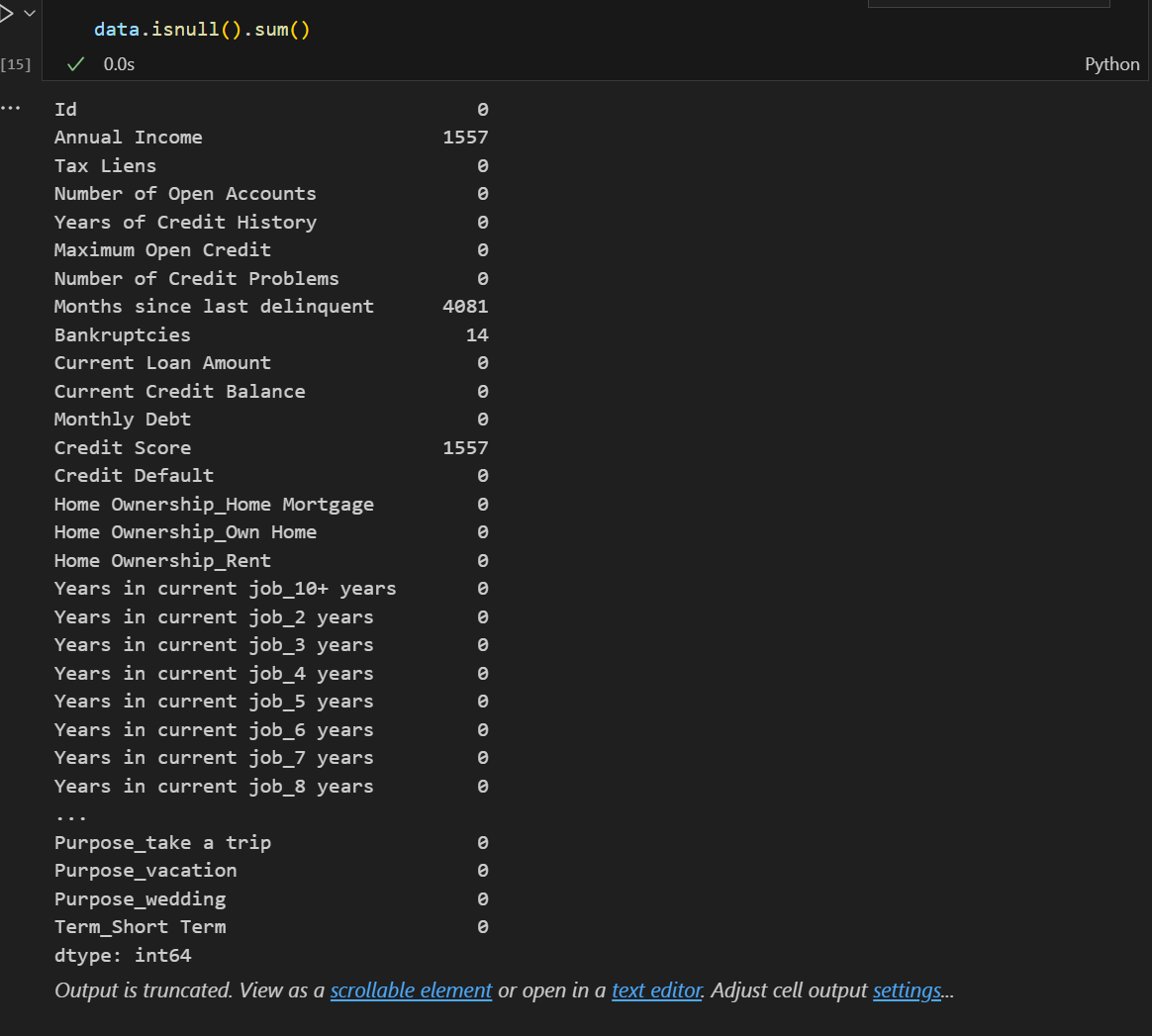
那么对于object对象如何填补缺失值呢?
import pandas as pd
# 1. 读取数据
df = pd.read_csv("your_data.csv") # 替换为你的数据路径
# 2. 前置分析:识别object列 + 查看缺失/取值
object_cols = df.select_dtypes(include="object").columns.tolist()
print("=== 待填充的object列 ===")
print(object_cols)
# 查看每列的缺失值和取值分布(关键!避免盲目填充)
for col in object_cols:
print(f"\n=== 列 {col} 信息 ===")
print(f"缺失值占比:{df[col].isnull().sum() / len(df):.2%}")
print(f"取值分布:\n{df[col].value_counts(dropna=False).head(5)}") # 看前5个高频值
# 3. 基础填充:众数填充(纯分类文字列首选)
for col in object_cols:
# 众数可能有多个,取第一个;若全是缺失,填“未知”
fill_value = df[col].mode()[0] if not df[col].mode().empty else "未知"
df[col] = df[col].fillna(fill_value)
# 4. 验证:检查填充后是否还有缺失值
print("\n=== 填充后缺失值检查 ===")
print(df[object_cols].isnull().sum()) # 所有列应为0
















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









