




所有关于 assignment1 的代码已开源在:
https://github.com/ACEEE-1222/Standford-CS336-Assignment-1
如果对你有帮助的话,记得顺手点个star喔!
在之前的内容中,我们完成了字节级 BPE 分词器的训练部分,得到了词汇表(vocab)和合并规则(merges)。而要让分词器能够实际应用,还需要实现编码和解码功能。本文将详细介绍 Stanford CS336 课程第一个作业中分词器(Tokenizer)的实现过程,包括其核心方法和关键细节。
一、作业要求概述
本次作业的核心任务是实现一个 Tokenizer 类,该类基于训练得到的词汇表(vocab)和合并规则(merges),能够将文本编码为整数 ID 序列,以及将整数 ID 序列解码为文本。同时,需要支持用户提供的特殊符号。
具体要求如下:
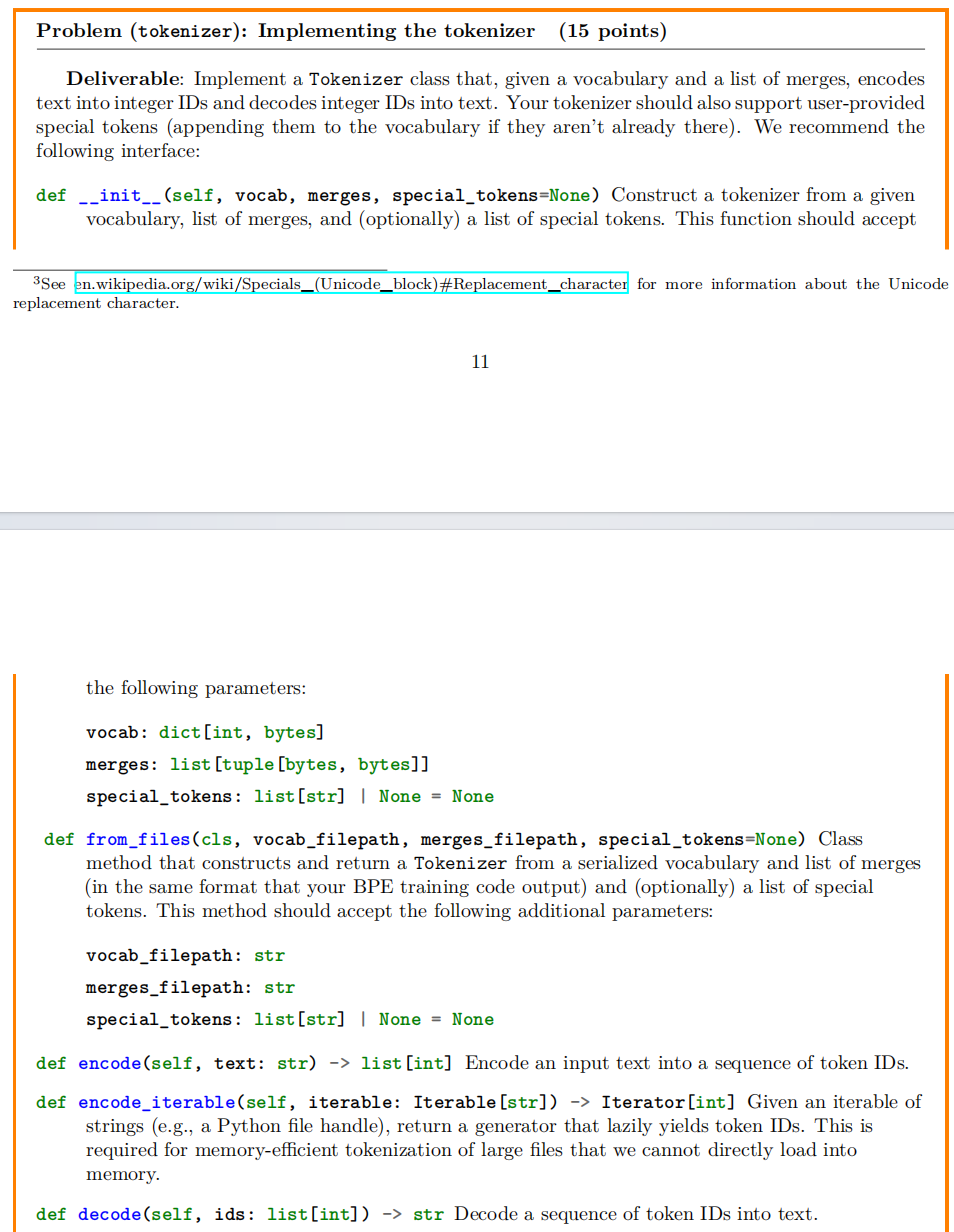
- 编码(encode):将输入的文本字符串转换为 token ID 列表。过程需先进行预分词,再应用 BPE 合并规则。
- 解码(decode):将 token ID 列表转换为文本字符串。对于无效的 token ID,需用 Unicode 替换字符(U+FFFD)处理。
- 支持从文件加载:实现
from_files类方法,从文件加载词汇表和合并规则。 - 支持迭代式编码:实现
encode_iterable方法,支持对大型文件进行内存高效的编码。 - 特殊符号处理:若特殊符号不在词汇表中,需将其添加进去,并在编码中保持独立。
二、Tokenizer 类的实现
1. 类的初始化(__init__ 方法)
def __init__(self, vocab: dict[int, bytes], merges: list[tuple[bytes, bytes]], special_tokens: list[str] | None = None):
self.vocab = vocab
self.vocab_reversed = {
v: k for k, v in self.vocab.items()}
self.merges = merges
self.special_tokens = sorted(special_tokens or [], key=lambda x: -len(x))
初始化方法中我们做了如下工作:
- 存储词汇表、合并规则和特殊符号;
- 构建词汇表的反向映射
vocab_reversed,便于编码时查表; - 对特殊符号按长度降序排序,防止短符号干扰长符号匹配。(在测试样例中有条就是关于这个的)
2. 从文件加载(from_files 类方法)
@classmethod
def from_files(cls, vocab_filepath: str, merges_filepath: str, special_tokens: list[str] | None = None) -> "Tokenizer":
vocab: dict[int, bytes] = {
}
with open(vocab_filepath, "r", encoding="utf-8") as f:
for line in f:
id_str, token_str = line.strip().split("\t")
vocab[int(id_str)] = token_str.encode("utf-8")
merges: list[tuple[bytes, bytes]] = []
with open(merges_filepath, "r", encoding="utf-8") as f:
for line in f:
parts = line.strip().split()
if len(parts)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1505
1505



 到【灌水乐园】发言
到【灌水乐园】发言








