






EDA二手车数据分析
1、基础科学函数库
基础工具
##基础工具
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
2、载入基础数据库
## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库)
Train_data = pd.read_csv('D:/天池竞赛/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('D:/天池竞赛/used_car_testA_20200313.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
显示结果如下(赛事统一数据)数据来源:阿里云

这里需要注意在
Train_data = pd.read_csv(‘D:/天池竞赛/used_car_train_20200313.csv’, sep=’ ‘)
TestA_data = pd.read_csv(‘D:/天池竞赛/used_car_testA_20200313.csv’, sep=’ ')中
D盘文件下的\应该改为/,避免被坑
3、总体数据预览
.describe()查看统计数值特征
// An highlighted block
var foo = 'bar';
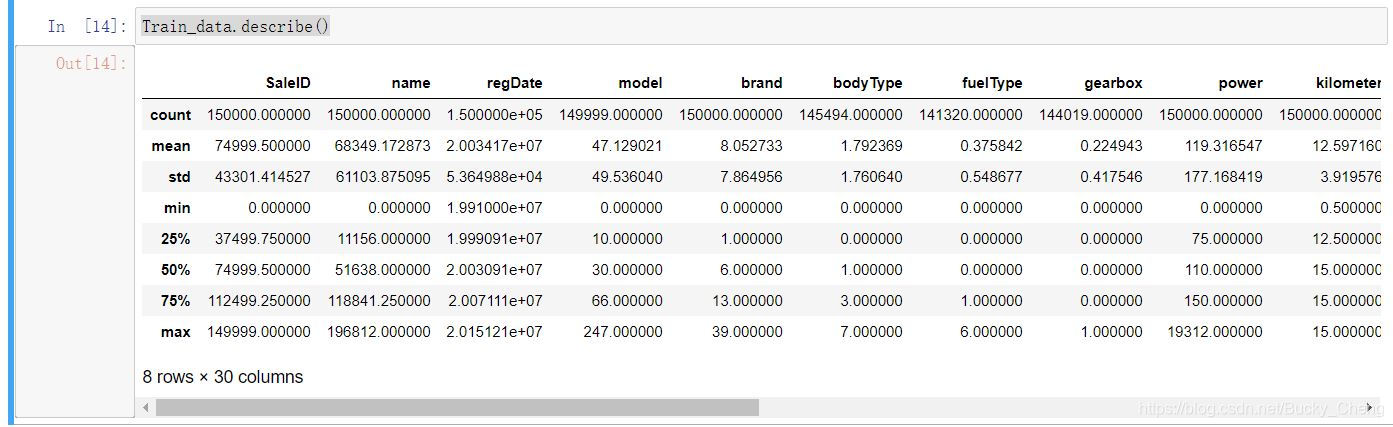
在这里可以看到数据的
count(数量),
mean(均值),
std(标准差),
min(最小值),
max(最大值),
25%,50%,75%(排序),
特征存在缺失(count<150000)。
.info()查看数据的数据结构
Train_data.info()
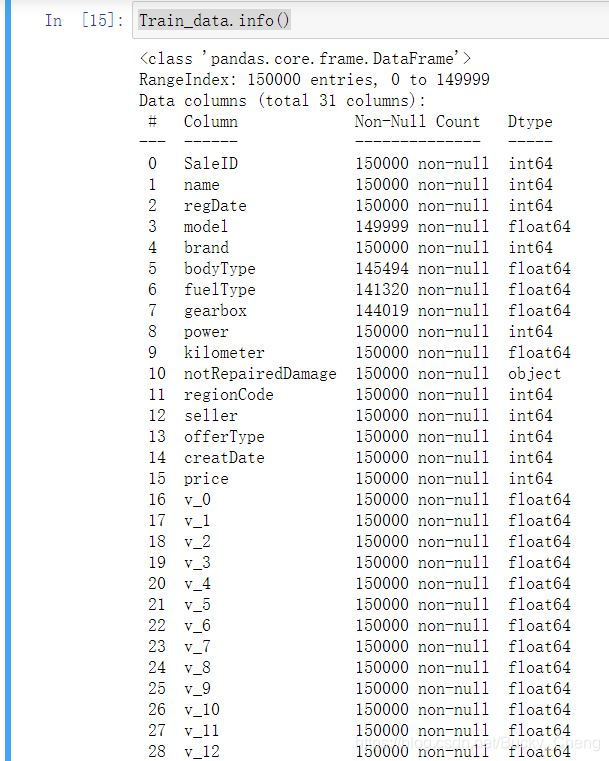
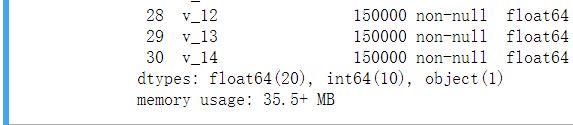
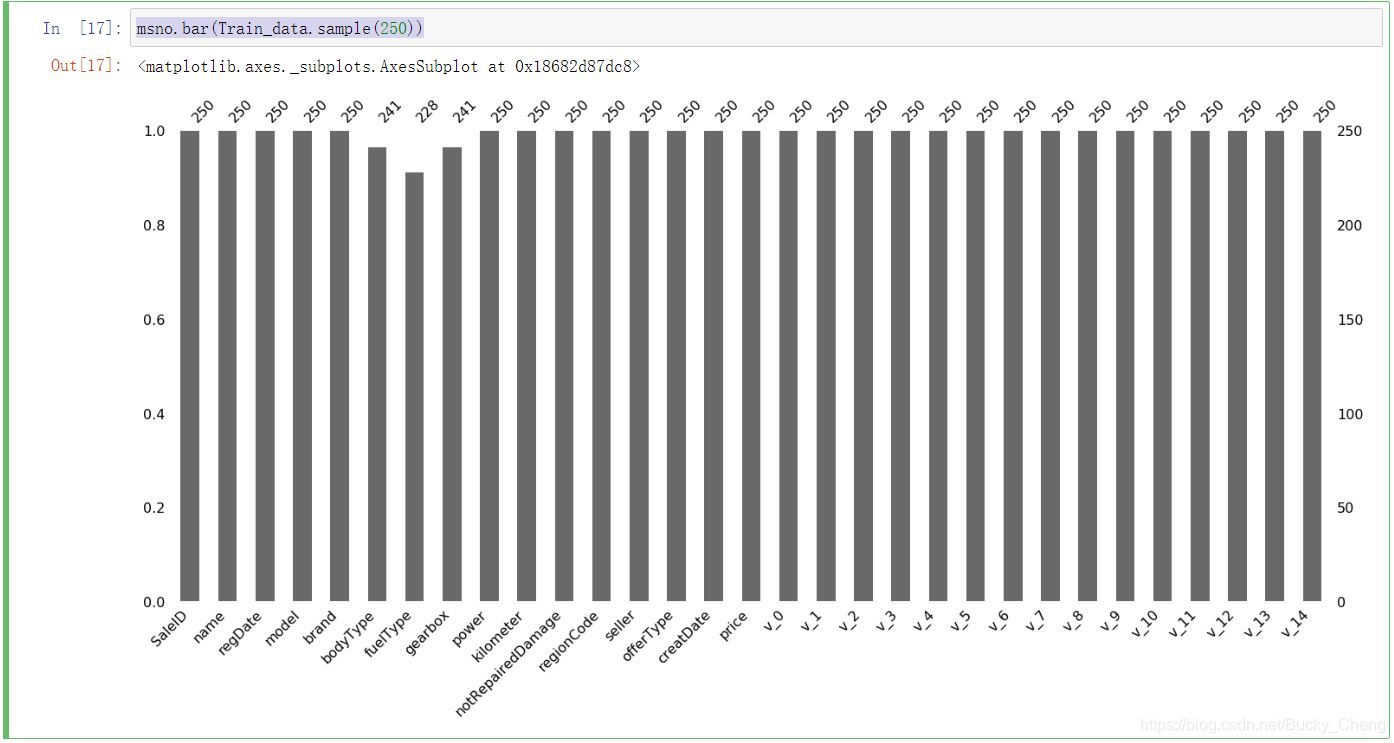
4,查看数据分布与缺失情况
msno.matrix(Train_data.sample(1000))
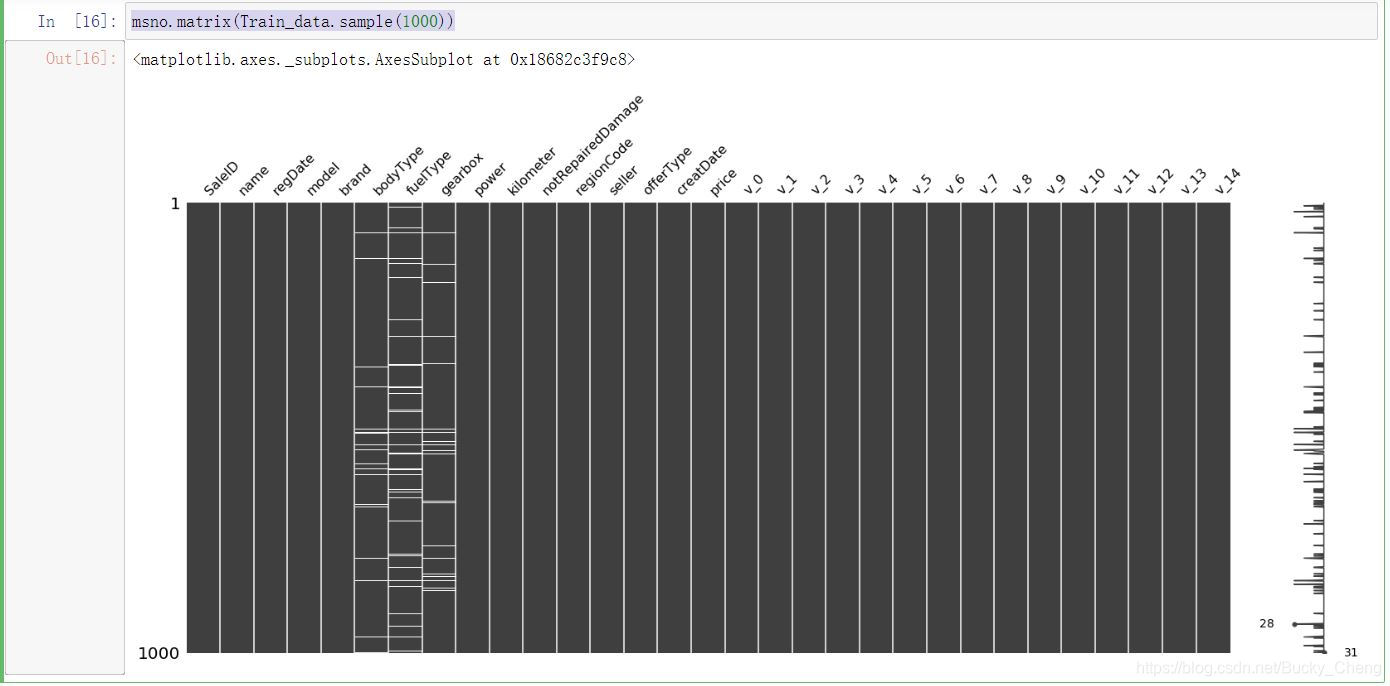
msno.bar(Train_data.sample(250))
5,总结与收获
第一次参与数据挖掘和数据结构的探索,对于也是刚入门python的我感到非常头疼,好在有队友的帮助。
数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示三个步骤。数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集;规律寻找是用某种方法将数据集所含的规律找出来;规律表示是尽可能以用户可理解的方式(如可视化)将找出的规律表示出来。数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等。(引自百度词条)
数据挖掘对于人工智能和神经网络以及机器深度学习等领域来说是一项基础工作,对于前沿开发、经济预测、科学管理等行业来讲也是一个必不可少的环节和工具。
第一次的数据挖掘,对于数据和模型的整合分析还有很大的不足,不能非常全面地分析数据和预测模型,还在学习中所以也就没必要把一些参考内容生搬硬套在这里了。
希望能和众多大佬一起学习,我还是个小白,也希望通过这次学习能提高丰富自己,我是学自动化的,软件硬件都要有基础,在学校的硬件学的偏多,所以还希望大家多多指点,为我的学习道路指点迷津。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









