







 本文探讨了深度学习中遇到的梯度消失问题,分析了其原因,包括网络过深、激活函数饱和及权重初始化不当。提出了通过选择合适激活函数如ReLU,以及使用Xavier或He初始化来缓解这一问题。此外,还详细解释了批归一化的作用,它能稳定激活值分布,避免梯度消失,加速网络训练并提高收敛速度。
本文探讨了深度学习中遇到的梯度消失问题,分析了其原因,包括网络过深、激活函数饱和及权重初始化不当。提出了通过选择合适激活函数如ReLU,以及使用Xavier或He初始化来缓解这一问题。此外,还详细解释了批归一化的作用,它能稳定激活值分布,避免梯度消失,加速网络训练并提高收敛速度。
如下图所示,以3个隐藏层的神经网络为例,每层网络只有一个神经元:

其中H表示激活函数,这里选择sigmoid函数为激活函数。损失函数为
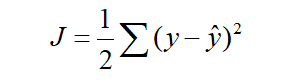
根据梯度下降法和反向传播算法来更新w1、w2、w3、w4:
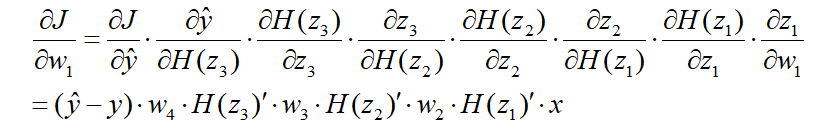
其中H函数表示sigmoid激活函数。
若wi的初始化值小于1;当x位于sigmoid函数两侧时,其dH(x)/dx的导数接近于0。因此经过多层的反向传播,导致损失函数J对w1的倒数接近于0。这就是梯度消失或梯度弥散。
因此,层数越靠前的网络越容易出现梯度消失,如下图所示。
如下图所示,以3个隐藏层的神经网络为例,每层网络只有一个神经元:
其中H表示激活函数,这里选择sigmoid函数为激活函数。损失函数为
根据梯度下降法和反向传播算法来更新w1、w2、w3、w4:
其中H函数表示sigmoid激活函数。
若wi的初始化值小于1;当x位于sigmoid函数两侧时,其dH(x)/dx的导数接近于0。因此经过多层的反向传播,导致损失函数J对w1的倒数接近于0。这就是梯度消失或梯度弥散。
因此,层数越靠前的网络越容易出现梯度消失,如下图所示。
 454
5542
454
5542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















