




深度学习常见问题——归一化
归一化
BN原理
BN的操作相当于在大梯度和非线性之间找到一个平衡点,使其能够在较快的收敛速度下保持网络的表达能力
训练阶段:
BN的初衷在于解决内部数据分布的偏移问题,也就是a+1层数据要不断适应a层数据的分布变化问题,这样会导致网络参数进入饱和区,导致梯度较小或者弥散。
所以BN通过将每层输出的数据归一化到均值0,方差1的分布上,消除各个层输出数据的偏移,但是这样做又会使数据停留在线性区域,限制网络的表达能力,所以在归一化后又加了一个可学习参数的线性变换,恢复其表达能力。而归一化的均值和方法是通过mini-batch的数据进行计算的。
具体的实现方法如下:

测试阶段:
训练阶段是对单个目标进行推理,所以均值和方差是采用训练阶段记录的结果进行BN的。将训练阶段的每个mini-batch的均值和方差记录下来,最后求期望,作为推理时用的均值和方差。
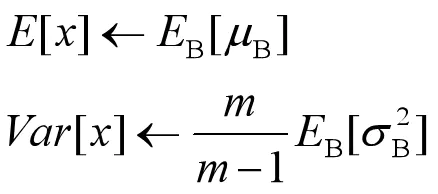
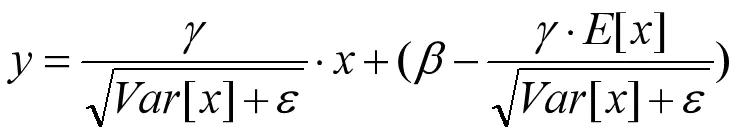
BN优点
- 加速模型的训练速度
- 对于饱和性激活函数,能够防止训练过程中梯度消失
- 具有正则化效果:mini-batch的均值、方差相当于引入了一定量的噪声
BN缺点
- 如果Batch size比较小,效果不好,引入噪声太大
- 推理时均值方差依赖的是训练集的结果,如果测试集分布和训练集不同,将影响效果
BN, GN, LN, IN之间的异同?
相同点:
这四种方法的归一化计算流程都是一样的,都为:
计算均值——>计算方差——>归一化成均值0方差1的分布——>用可学习参数 γ \gamma γ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3127
3127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









