




 本文深入解析PyTorch中的LSTM模块,详细介绍其参数意义、输入输出维度要求及使用方法。通过实例演示如何构建LSTM网络,处理序列数据。
本文深入解析PyTorch中的LSTM模块,详细介绍其参数意义、输入输出维度要求及使用方法。通过实例演示如何构建LSTM网络,处理序列数据。
通过源代码中可以看到nn.LSTM继承自nn.RNNBase,其初始化函数定义如下
class RNNBase(Module):
...
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False):
我们需要关注的参数以及其含义解释如下:
input_size – 输入数据的大小,也就是前面例子中每个单词向量的长度
hidden_size – 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数
num_layers – recurrent layer的数量,默认等于1。
bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
batch_first – 默认为False,也就是说官方不推荐我们把batch放在第一维,这个CNN有点不同,
此时输入输出的各个维度含义为 (seq_length,batch,feature)。当然如果你想和CNN一样把batch
放在第一维,可将该参数设置为True。
dropout – 如果非0,就在除了最后一层的其它层都插入Dropout层,默认为0。
bidirectional – If True, becomes a bidirectional LSTM. Default: False
下面介绍一下输入数据的维度要求(batch_first=False):
输入数据需要按如下形式传入 input, (h_0,c_0)
input: 输入数据,即上面例子中的一个句子(或者一个batch的句子),
其维度形状为 (seq_len, batch, input_size)
seq_len: 句子长度,即单词数量,这个是需要固定的。当然假如你的一个句子中只有2个单词,
但是要求输入10个单词,这个时候可以用torch.nn.utils.rnn.pack_padded_sequence()
或者torch.nn.utils.rnn.pack_sequence()来对句子进行填充或者截断。
batch:就是你一次传入的句子的数量
input_size: 每个单词向量的长度,这个必须和你前面定义的网络结构保持一致
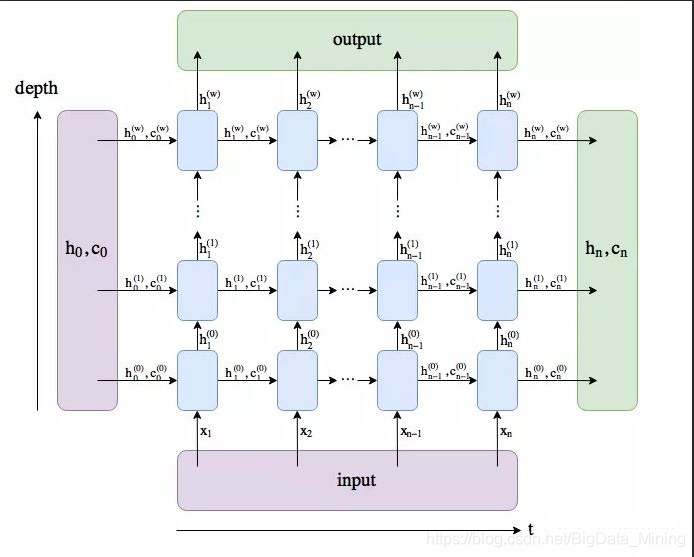
h_0:维度形状为 (num_layers * num_directions, batch, hidden_size):
结合下图应该比较好理解第一个参数的含义num_layers * num_directions,
即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的bidirectional决定,
如果为False,则等于1;反之等于2。
batch:同上
hidden_size: 隐藏层节点数
c_0: 维度形状为 (num_layers * num_directions, batch, hidden_size),各参数含义和h_0类似。
当然,如果你没有传入(h_0, c_0),那么这两个参数会默认设置为0。
output: 维度和输入数据类似,只不过最后的feature部分会有点不同,
即 (seq_len, batch, num_directions * hidden_size)
这个输出tensor包含了LSTM模型最后一层每个time step的输出特征,
比如说LSTM有两层,那么最后输出的是[h10,h11,...,h1l] ,
表示第二层LSTM每个time step对应的输出.另外如果前面你对输入数据
使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence。
对于unpacked情况,我们可以对输出做如下处理来对方向作分离
output.view(seq_len, batch, num_directions, hidden_size),
其中前向和后向分别用0和1表示Similarly, the directions can be separated in the packed case.
h_n:(num_layers * num_directions, batch, hidden_size), 只会输出最后一个time step的隐状态结果(如下图所示)。
Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size) and similarly for c_n.
c_n :(num_layers * num_directions, batch, hidden_size),只会输出最后个time step的cell状态结果(如下图所示)。
代码:
rnn = nn.LSTM(10, 20, 2) # 一个单词向量长度为10,隐藏层节点数为20,LSTM有2层
input = torch.randn(5, 3, 10) # 输入数据由3个句子组成,每个句子由5个单词组成,单词向量长度为10
h0 = torch.randn(2, 3, 20) # 2:LSTM层数*方向 3:batch 20: 隐藏层节点数
c0 = torch.randn(2, 3, 20) # 同上
output, (hn, cn) = rnn(input, (h0, c0))
print(output.shape, hn.shape, cn.shape)
>>> torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









