




摘要
AAA模式,即安排、操作和断言,为单元测试用例提供了一个统一的结构,这有利于理解和维护。然而,对于现实生活中的开发人员是否以及如何在实践中遵循AAA构建单元测试用例,人们知之甚少。特别是,是否存在偏离AAA结构并值得重构的反复出现的反模式?并且,如果测试用例遵循AAA结构,它们是否会在A块(arrange块)中包含设计缺陷?如果我们建议重构来修复AAA测试用例的设计,开发人员如何接收这些建议?他们支持重构吗?如果没有,他们的考虑是什么?
本研究对从四个开源项目中随机选择的435个实际单元测试用例进行了实证研究。总的来说,大多数(71.5%)的测试用例遵循AAA结构。并且,我们观察到偏离AAA结构的三个反复出现的反模式,以及可能存在于A块中的四个设计缺陷。每种问题类型都有其缺点和相应的重构解决方案的优点。为了解决这些问题,我们总共发送了18个重构建议。我们收到了78%的积极反馈,支持重构。从这些拒绝中,我们了解到投资回报率是开发者的一个关键考虑因素。这些发现为实践者提供了在头脑中构建AAA单元测试用例的见解,并为研究人员开发在测试用例中执行AAA的相关技术提供了见解。
目标是为在头脑中使用AAA创建测试用例的实践者和开发便利技术的研究人员提供见解。
注:
与测试气味研究不同处:
这项工作与测试气味的研究高度相关,测试气味专注于测试代码中深层问题的表面迹象。然而,我们的工作以两种方式区分自己:
1)它通过利用测试用例中的整体AAA上下文来关注揭示设计缺陷和反模式的根本原因。相比之下,测试气味通常停留在问题迹象的表面。
2)它揭示了测试用例中的四个新的设计问题,这些问题在以前的工作中没有报告过。与测试气味的详细比较见第六节。
贡献
•首先进行了此类实证研究,以调查AAA模式是否被实践以及多久被实践一次。
•基于测试用例中AAA的整体上下文,在测试用例中推断出新的设计缺陷和反模式,这可以揭示设计的根本原因,从而揭示问题迹象。
•现实生活中的开发者对于他们是否支持在AAA环境下解决设计问题的观点和考虑。
概念
AAA 模式将单元测试分为三个明确的阶段:
- 安排 (Arrange): 在这个阶段,我们需要设置必要的条件和环境,以便测试能够顺利进行。这包括初始化任何必需的对象、变量或数据。
- 执行 (Act): 这一阶段涉及执行我们想要测试的功能或行为。通常这意味着调用某个函数或方法。
- 断言 (Assert): 最后,我们需要验证执行的结果是否符合预期。这通常涉及到使用断言语句来检查结果的状态或值。
#include <gtest/gtest.h>
#include "stack.h" // 假设我们有一个名为 stack.h 的头文件
TEST(StackTest, PushOnEmptyStackIncrementsCount) {
// Arrange
Stack<bool> stack; // 使用 Stack 类型代替 stack<bool>
// Act
stack.push(false);
// Assert
ASSERT_EQ(stack.count(), 1);
}PR (Pull Request)
Pull Request 是一种代码审查和合并的机制,通常用于版本控制系统(如 Git)中。它允许开发者在将代码更改合并到主分支之前,发起一个请求,以便其他开发者可以审查和批准这些更改。
IT (Issue Ticket)
Issue Ticket 是一种用于记录和跟踪问题或任务的机制,通常用于项目管理工具(如 Jira、GitHub Issues、GitLab Issues 等)。它允许团队成员报告问题、分配任务、跟踪进度和管理项目。
实验
RQ1:实际测试用例遵循AAA模式的频率是多少?AAA测试用例和反AAA测试用例如何相互比较?
RQ2:测试用例偏离AAA模式的常见方式是什么?这种偏差可能产生哪些反模式?另外,AAA测试用例是否包含值得改进的设计缺陷?
RQ3:现实生活中的开发人员如何接受重构建议,以改进反AAA测试用例和带有设计缺陷的AAA用例?
实验流程:
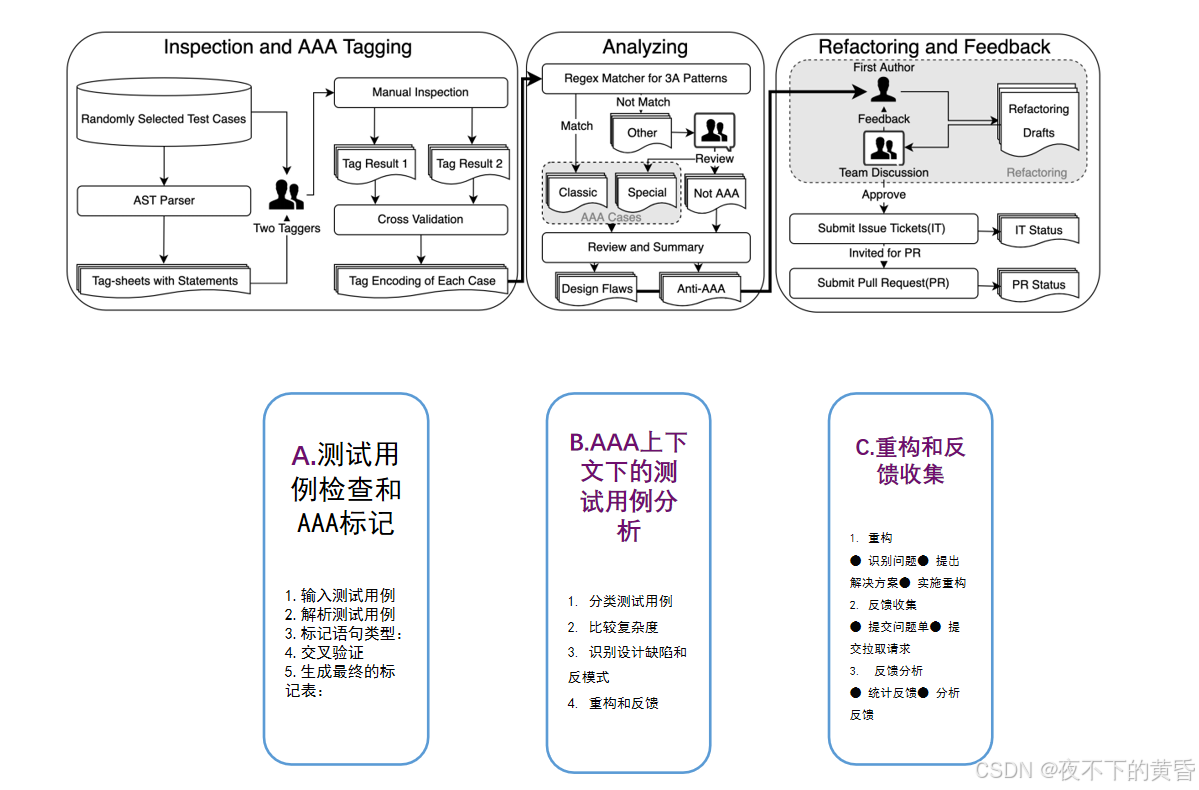
A.测试用例检查和AAA标记
- 输入测试用例:将测试用例作为输入。
- 解析测试用例:使用解析器生成调用语句列表。(不会对生产方法进行深层次调用)
- 标记语句类型:标记器(人工)根据测试用例的意图,将每个语句标记为Arrange、Act或Assert。
-
- 深入了解测试用例的内部逻辑
- 检查调用方法的内部
- 交叉验证:两个标记器比较结果,确保标记的一致性。
- 生成最终的标记表:生成包含每个语句及其标记类型的列表。
B.AAA上下文下的测试用例分析
- 分类测试用例:
-
- 使用正则表达式匹配经典AAA模式。
- 手动检查特殊设计的测试用例,确定是否为特殊AAA模式。
- 识别反AAA模式的测试用例。
- 比较复杂度:
-
- 比较遵循AAA模式和不遵循AAA模式的测试用例的LOC和圈复杂度。
- 分析测试用例中标记为Arrange、Act和Assert的语句数量。
- 识别设计缺陷和反模式:
-
- 通过审查测试用例的编码和源代码,识别设计缺陷和反模式。
- 记录每个问题的缺点和可能的解决方案。
- 重构和反馈:
-
- 对有问题的测试用例进行重构。
- 提交问题单和拉取请求,收集开发人员的反馈
C.重构和反馈收集
- 重构
- 识别问题:首先,研究者通过手动检查和标记测试用例,识别出不符合AAA模式的反模式和设计缺陷。
- 提出解决方案:针对每个问题,研究者提出具体的重构方案。这些方案旨在简化测试用例的结构,使其更清晰、更易于理解和维护。
- 实施重构:研究者手动对测试用例进行重构,确保重构后的测试用例仍然能够正确执行,并且符合AAA模式。
- 反馈收集(Feedback Collection)
- 提交问题单(Issue Ticket):研究者通过问题单详细描述发现的问题和提出的重构方案,邀请开发人员进行讨论和评估。
- 提交拉取请求(Pull Request):在开发人员同意重构方案后,研究者通过拉取请求提交重构后的代码,供开发人员审查和合并。
- 反馈分析
- 统计反馈:记录每个问题单和拉取请求的反馈情况,包括接受、拒绝和修改意见。
- 分析反馈:分析开发人员的反馈,了解他们对重构建议的看法和意见,评估重构的实际效果。
结果
RQ1:总体而言,71.5%的测试用例遵循AAA结构,64.4%明确遵循以及7.1%遵循一些特殊设计。遵循AAA模式对测试用例的LOC或圈复杂度没有明显影响,其关键的区别在于act的次数。遵循AAA结构可能是促进测试用例设计中单一责任原则的一种方式——只关注一个功能单元和一个场景。
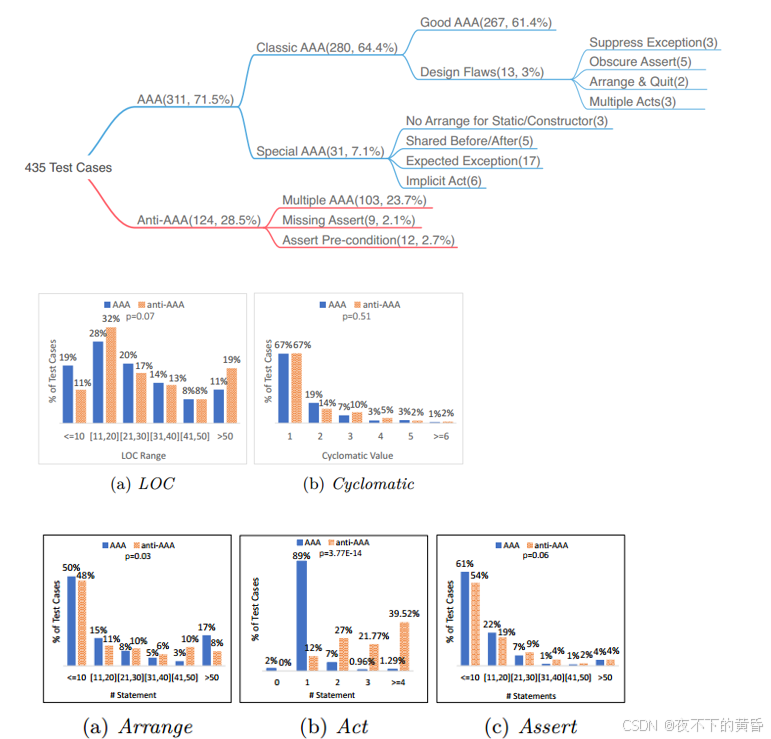
1.
四种特殊AAA模式:
1.无静态/构造函数安排:测试用例的目标是静态函数或构造函数,因此测试用例不需要任何arrange。
2.Shared Before/After:arrange或assert部分被封装在带有特殊注释的方法中,例如@Before或@After。
3.预期异常:测试用例使用@test注释的预期属性声明它预期会抛出异常。(隐式断言)
4.隐含行为:测试用例没有明确的行为;而JUnit断言函数通过动态绑定执行act函数。这些情况都与测试用户定义函数覆盖的等式有关。
2.
反AAA模式的LOC往往略高于AAA模式,但差异并不显著——p值0.07(>0.05)。
反AAA和AAA模式的圈形指标没有区别——p值为0.5,这表明AAA模式对测试用例的复杂性没有明显影响。
3.
1)AAA模式的arrange数量似乎略高,p值为0.03(<0.5)。解释是开发人员在遵循AAA模式时,往往会为测试目标函数准备更复杂的安排。
2)反AAA模式的act数量明显是AAA案例的四倍,p值为3.7E-14。
3)AAA和反AAA模式的断言数量没有明显差异,p值为0.06(>0.5)。
因此,主要结论是act数量是反AAA和AAA案例之间的关键区别——这与单一责任原则(single responsibility principle)是否得到遵循有关。
RQ2:我们观察到三种反复出现的反AAA模式——多重AAA、缺失断言和断言前提条件,以及存在于A块内的四种设计缺陷类型——抑制异常、模糊断言、安排和退出以及多重行为。每种问题类型都有自己的缺点和相应的重构解决方案。
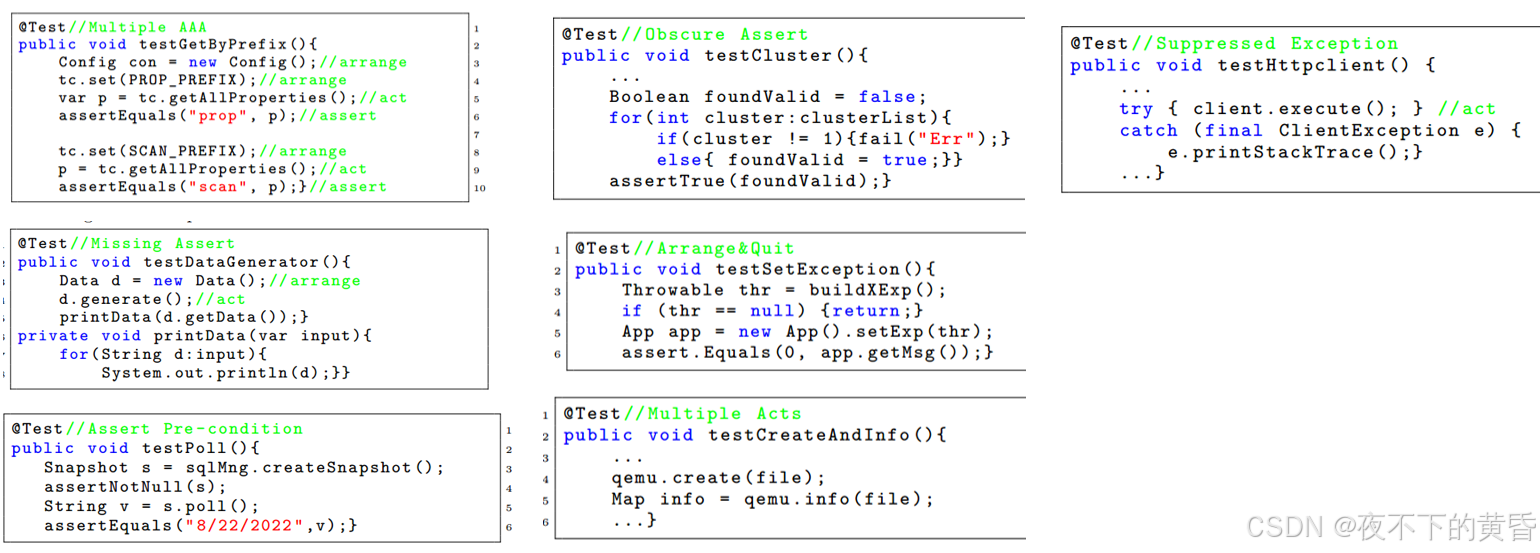
反AAA模式:
1.
多个AAA:测试用例由多个AAA块组成。
缺点:首先,如果将多个AAA块组合在一起,测试用例可能会变得非常大,从而影响对测试用例的理解和维护。其次,测试用例失败的原因不止一个,因为AAA的每个块都可能触发测试失败。这导致调试的复杂性增加。此反模式违反了软件设计中的单一责任原则
重构:将其拆分为多个测试用例,每个测试用例包含一个来自原始用例的AAA块。因此,每个测试用例都遵循经典的AAA模式,专注于一个测试场景,并且应该只因一个原因而失败。
2.
缺少断言:测试用例不包含任何JUnit断言函数,也没有指定任何预期的行为(例如,使用我们前面描述的预期属性)。换句话说,无论测试下的函数是否正确,测试用例都不会引发失败。测试用例可能使用打印功能,该功能将结果检查委托给人工。
缺点:如果测试用例从未失败,它就失去了捕获被测函数缺陷的目的。使用打印/日志方法进行手动检查,成本过高,特别是在现代软件开发的CD/CI环境中。
重构:添加断言函数。
3.
断言前提条件:测试用例在执行被测功能之前,断言排列对象的某些前提条件。如下图所示,assertNull确保从数据库获取快照(即不为空)。
缺点:测试用例可能因两个原因而失败:1)不满足先决条件;2) 被测函数包含错误。这将增加调试的复杂性。重构:用Junit假设替换断言前提条件。假设是自JUnit4以来引入的一组方法,用于陈述关于测试有意义的条件的假设。假设失败并不意味着代码被破坏,而是测试提供的信息不那么有用
AAA模式缺陷
1.
模糊断言:断言块包含不必要的控制流,模糊了断言的逻辑。如下所示,for循环加上if-else块断言集合中的元素满足某些条件。
缺点:顾名思义,这个设计缺陷给断言逻辑增加了不必要的复杂性,模糊了断言的意图,增加了理解和维护的难度
重构:消除不必要的控制流,简化断言逻辑。通过使用下面显示的7hamcrest API,可以将上面的示例简化为一个断言语句。请注意,并非所有此类情况都需要使用hemcrest。
2.
Arrange&Quit:如果排列的对象不符合特定条件,测试用例将静默返回,这是Assert Precondition的对应部分
缺点:首先,if返回使逻辑成为隐式的测试用例。其次,测试用例将悄无声息地退出,没有任何关于测试用例是否成功执行的提示。如果没有,为什么。
重构:将if返回块替换为前提条件的假设
3.
多重行为:测试用例扮演一个类的多个函数。
缺点:如果测试用例失败,很难判断是哪个函数导致了失败。此外,每个单独的函数通常都没有被充分断言,因为断言侧重于最终输出,但忽略了中间输出。
重构:将测试用例分解为单独的用例,每个用例关注一个行为并添加单独的断言
4.
抑制异常:测试用例使用trycatch块抑制应抛出的异常并引发失败。如下所示,try-catch块捕获Exception并打印堆栈跟踪。
缺点:这会抑制异常,不会引发失败。它对开发人员隐藏了错误。
重构:删除catch并保留try。
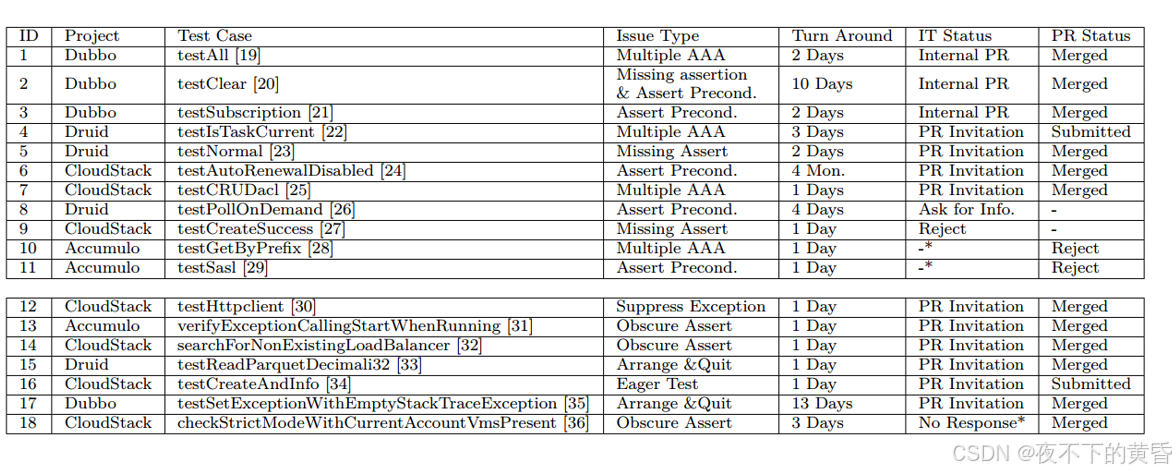
RQ3:18项提案获得了100%的回应率。78%的回复是积极的——我们被邀请提交PR或PR被合并。这表明现实生活中的开发人员关心测试用例的设计,他们有兴趣解决我们发现的问题。
拒绝也指出了宝贵的经验教训——投资回报率是一个关键问题,可以考虑测试用例的变更(如果一个测试用例经常因为业务逻辑的变化而需要修改,开发人员可能会认为,对这个测试用例进行重构的风险较高,因为未来的修改可能会破坏重构后的代码。)和失败倾向(如果一个测试用例在过去几个月中从未失败过,开发人员可能会认为它运行稳定,不需要进行重构。),以及变更的粒度(如果一个测试用例包含多个测试场景,开发人员可能会认为将其拆分为多个独立的测试用例会增加维护的复杂性,因为每个测试用例都需要单独维护。)
总结
本文总结了人工编写测试用例的建议实践——AAA模式。统计了遵循该实践的样本数量,研究了反AAA模式常见的三大类型(多AAA,缺少断言,断言前提条件),特殊的AAA模式(无静态/构造函数,@before@after函数封装,预期异常,封装行为),AAA模式与反AAA模式在LOC和圈复杂度上区别不大,关键区别在于act数量(是否遵循单一原则),AAA模式的四个缺陷(模糊断言,安排退出,多重行为,抑制异常)。最后,针对AAA模式的缺陷和反AAA模型,提出了重构,并提交给开发者。绝大多数接受建议并合并,拒绝建议的是从测试用例变更频率,失败倾向,变更粒度三个方面进行的考虑。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











