 逃逸测试覆盖高原
逃逸测试覆盖高原





该文献提出算法CODAMOSA执行SBST,直到其覆盖率改进停滞,然后要求Codex为未覆盖的功能提供示例测试用例。这些示例帮助SBST将其搜索重定向到搜索空间中更有用的区域。
贡献
• 提出了CODAMOSA,它将代码的大型语言模型(LLMs)与基于搜索的软件测试(SBST)相结合。它包括将任意来源的Python测试用例集成到SBST中的技术。
• 对CODAMOSA及其设计决策和基线在486个基准测试上进行了大规模评估。
• 发布了CODAMOSA的开源实现以及用于帮助复现本文实验的数据。
概念
焦点方法:被单元测试的方法
PUT:被测程序
基于搜索的软件测试:利用搜索算法来生成和选择测试用例的方法。它首先随机生成一组测试用例,然后探索新的测试时用例,并保留覆盖率最高的测试用例。
-
- 初始化:生成初始的测试用例集合,这些测试用例可以是随机生成的,也可以是基于某种策略选择的。
- 搜索:利用搜索算法(如遗传算法、模拟退火算法、粒子群优化算法等)在测试空间中搜索新的测试用例。搜索过程会考虑测试用例的覆盖率、执行成本等因素,以找到最优或次优的测试用例。
- 更新:根据搜索结果更新当前的测试用例集合,保留优秀的测试用例,淘汰低效的测试用例。同时,根据新的测试用例继续搜索,以发现更多的软件行为。
反序列化:SBST框架通常有一套预定义的规则和限制,用于确定哪些语句或代码片段可以包含在测试用例中。这些限制有助于保持搜索过程的可行性和效率。然而,Codex生成的代码可能是任意的Python代码,它可能包含SBST原本不支持的函数调用、语法结构或数据类型。
反序列化过程就是解决这个问题的关键步骤。它负责将Codex生成的原始字符序列(即代码)转换为SBST内部表示形式(如抽象语法树、中间表示或SBST特定的测试用例格式)。在这个过程中,反序列化程序会检查Codex生成的代码,并根据SBST的规则和限制进行必要的修改或调整。
通过反序列化过程,SBST能够利用Codex生成的测试用例中的新元素(如新的函数调用、新的语法结构等),这些新元素可能有助于覆盖更多的代码路径或发现新的软件缺陷。因此,反序列化过程有效地扩展了SBST的搜索空间,使其能够探索原本无法触及的代码区域。
MOSA算法:

输入:一是被测程序的模块,二是种群大小:即测试用例数量,三是规定时间的开销。
算法:1:提取可以覆盖的语句 2:调用的方法 3:随机生成的测试用例 4:维护一个归档即最大覆盖率的最少测试用例
问题
变异后的测试用例不太可能增加覆盖率是相当常见的一种情况。因此,会导致SBST搜索的停滞不前。或者可以说,SBST难以以预期的方式测试被测程序,即如何生成这些预期的测试用例是一大难点。
idea:源于bump_version方法。其功能是输入一个版本号,输出一个版本号。所以初始测试用例生成需要满足特定的格式,而对于SBST其随机生成测试用例可能会导致覆盖率停滞。因此,通过LLM生成测试用例(可满足测试用例的规则),之后使用SBST框架应运而生。
实验
算法参数:在实现过程中,在小型测试基准上观察CODAMOSA的运行后,我们选择了25次迭代的最大停滞长度,对Codex的最大查询次数为10次。我们使用这些值进行评估,以防止过度拟合我们的基准。对于人口规模,我们使用pypyn默认值50。
实验参数:每项技术在每个测试模块上运行16次,每次10分钟(T = 10分钟)。我们选择10分钟作为搜索时间,因为这是评价pyngin所使用的时间,比评价MOSA所用的5-8分钟的搜索时间要长。对于CODAMOSA及其变体,10分钟的时间包括通过OpenAI的API查询Codex的时间。
结果
RQ1
CODAMOSA与我们的基准集上的基线相比如何?
基准:codex,mosa
先判断codex,codemosa和mosa之间是否存在显著性差异,之后在判断差异是多少。
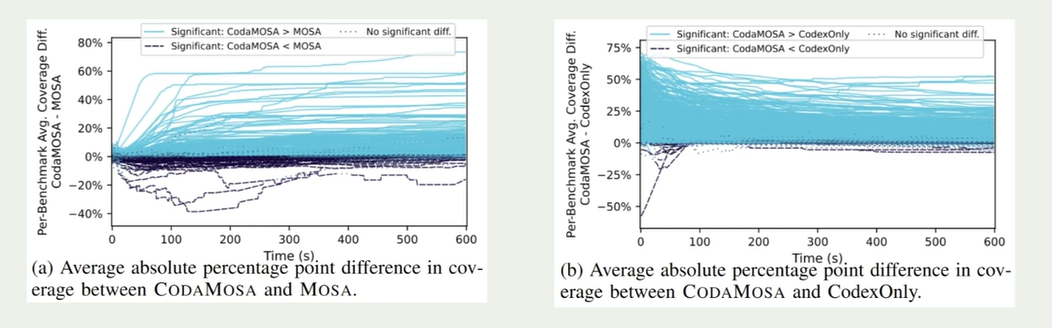
最初使用随机测试生成比查询Codex更快地生成测试用例。但随着时间推移,codex逐渐下降
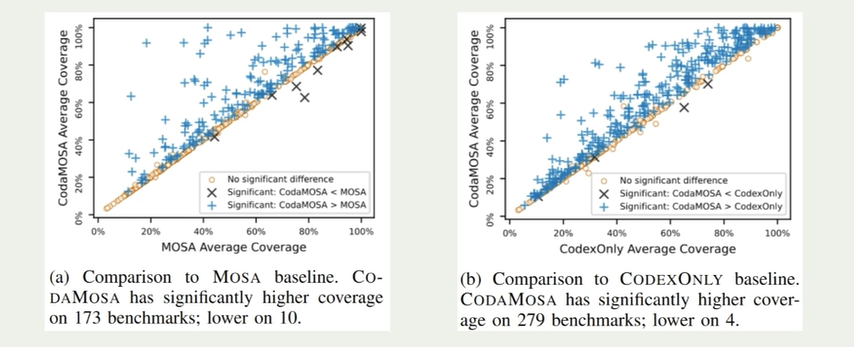
codemosa高于mosa原因:特殊的字符串;备份可调用的方法/函数;未解释的语句
少部分codemosa低于mosa原因:codemosa请求调用codex大模型花费时间;codex构造函数错误;无法被解析的结构
Q2
消融实验(未解释的语句、Codex超参数、低覆盖率目标、提示)
未解释语句较为重要
RQ3
为什么CODAMOSA在质量上与MOSA获得不同的覆盖结果?
RQ4
判断codemosa方法是否存在过拟合现象?答案显然是不存在
CHATTESTER
CODEMOSA算法:

输入:一是被测程序的模块,二是种群大小:即测试用例数量,三是规定时间的开销。
算法:1:提取可以覆盖的语句 2:调用的方法 3:随机生成的测试用例 4:维护一个归档即最大覆盖率的最少测试用例 5:最大停滞长度,多少次后仍无覆盖率提升,之后就调用codex模型
7,8:之前的测试覆盖率
到了第9行后,就开始判断当前停滞长度和最大停止长度的大小关系。
如果大于,将target置为true。然后调用TARGETEDGEN方法(该方法返回一租新的测试用例并扩大测试用例集合)
如果小于,执行和MOSA算法相同的部分,对测试用例进行变异更新
之后到21行,如果调用模型了但有效测试用例集合和之前一样,将最大停滞长度设为2倍

输入:归档archive,可调用对象,测试方法,调用模型,交互次数
输出:低覆盖率的测试用例的调用对象,新的测试用例
大模型生成的测试代码不可以在SBST中直接使用,因此需要进行反序列化。生成的测试用例反序列化为搜索算法的内部表示。这种表示简化了专门化操作,例如类型感知的突变或测试用例缩减。
反序列化
重写codex生成结果:可能生成嵌套结构,将该结构拆开
局部解析:丢弃无法解析的语句
可调用对象拓展
未解释的语句
总结
提出了一个算法CODEMOSA,当传统的基于搜索的测试生成遇到覆盖率瓶颈的时候,可以求助于LLM,让LLM 生成更加合理的测试用例,从而逃离覆盖率的停滞。



















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











