




AugmenTest: Enhancing Tests with LLM-Driven Oracles
摘要
自动化测试生成对于确保软件应用程序的可靠性和健壮性至关重要,同时减少所需的工作量。尽管在测试生成研究方面取得了重大进展,但生成有效的测试预言仍然是一个悬而未决的问题。
为了应对这一挑战,我们提出了AugmenTest,这是一种利用大型语言模型(LLM)根据被测软件的可用文档推断正确测试预言的方法。与大多数依赖于代码的现有方法不同,AugmenTest利用LLM的语义能力从文档和开发人员注释中推断出方法的预期行为,而无需查看代码。AugmenTest包括四种变体:简单提示、扩展提示、具有通用提示的RAG(没有被测类或方法的上下文)和具有简单提示的RAG,每种变体都为LLM提供不同级别的上下文信息。
为了评估我们的工作,我们选择了142个Java类,并为每个类生成了多个变种。然后,我们从这些突变体中生成测试,只关注通过突变体但在原始类上失败的测试,以确保测试有效地捕获了错误。这导致了203个具有不同错误的独特测试,然后用于评估AugmenTest。结果表明,在最保守的情况下,AugmenTest的扩展提示始终优于简单提示,生成正确断言的成功率为30%。相比之下,最先进的TOGA方法达到了8.2%。
与我们的预期相反,基于RAG的方法并没有带来改善,在最保守的情况下,成功率为18.2%。
我们的研究展示了LLM在提高自动化测试生成工具可靠性方面的潜力,同时也突出了未来需要增强的领域。
贡献
•突变体的实证研究和基准测试:我们在142个Java类的测试用例中对AugmenTest进行了全面评估,分析了其利用大型语言模型生成准确测试预言的性能。这项研究对AugmenTest通过使用突变体(类的有缺陷的版本)推断正确断言的能力进行了独特的基准测试,确保推断出的预言传递给原始类,并在有缺陷的类上失败。这一实证评估为评估LLM驱动的oracle生成的准确性和有效性提供了一个稳健的框架。
•提示变体的比较:我们探索了多种提示变体,包括简单提示、扩展提示和检索增强生成,以研究上下文丰富的提示对断言推理的影响。我们的结果表明,虽然提供扩展上下文可以改善oracle生成,但使用基于RAG的方法并不能提高预期的性能。
•LLM Oracle推理的灵活框架:与之前的研究不同,如TOGA,它训练模型来推断测试预言,AugmenTest提供了一个更灵活、与模型无关的框架。我们的方法可以应用于任何LLM,使其适应不断发展的模型和人工智能的新发展。
•数据集:我们正在公开我们的数据集,以支持未来基于LLM的测试预言机生成的研究。该数据集包括来自142个Java类的203个测试用例,每个类每个方法至少有30个字符的开发人员注释,确保了基于LLM的推理有足够的上下文。我们还包括生成的突变体(类的错误版本),这些突变体用于在推断正确断言时对AugmenTest的性能进行基准测试。
概念
1.Oracle 生成
Gabriel Ryan等人介绍了TOGA,这是一个基于transformer的测试Oracle生成框架。TOGA集成了EvoSuite,并利用了oracle分类器和断言排序器,显著提高了断言和异常行为的推理能力。与其他工具相比,它具有更高的错误查找精度。然而,Liu等人[7]强调了TOGA评估方法的局限性,提出TEval+作为一种更现实的指标,揭示了在现实条件下评估TOGA检测错误的精度要低得多。
Tufano等人[8]利用预训练变换器生成断言语句,比ATLAS有了实质性的改进,包括前1名的准确性提高了80%。Nie等人[9]介绍了TECO,它将代码语义应用于oracle生成,在精确匹配精度方面比TOGA高出82%。他们还强调了执行重新排名对提高预测准确性的影响。
其他方法,如Yu等人[10]的基于信息检索(IR)的方法,表明在断言生成任务中,将IR和深度学习技术相结合优于纯粹的基于深度学习的解决方案,如ATLAS。基于深度学习的方法,如Shin等人[11]分析的方法,对神经Oracle生成(NOG)模型进行了广泛的分析,强调了文本相似性度量(如BLEU、ROUGE)和测试充分性度量(例如代码覆盖率、变异分数)之间缺乏相关性,强调了在Oracle生成中需要更有效的评估方法
2.单元测试生成
在单元测试生成领域,Schafer等人提出了TESTPILOT[12],这是一种使用LLM进行端到端测试生成的系统,实现了高语句覆盖率和有效的断言生成。Tufano等人提出了一种方法[13],这是一种根据真实世界的开发人员编写的测试用例进行微调的模型,其性能优于GPT-3,测试覆盖率与EvoSuite相当。
Tang等人[14]探索了ChatGPT生成单元测试套件的能力,发现尽管与EvoSuite相比,ChatGPT在覆盖率方面存在困难,但它在可读性和可用性方面表现出色。
Yuan等人[15]通过CHATTESTER进一步研究了这一点,该工具通过减少编译错误和提高断言准确性来改进ChatGPT生成的测试。
Xie等人介绍了ChatUniTest[16],这是另一种基于ChatGPT的工具,在几个关键的测试生成指标上超越了AthenaTest和EvoSuite,强调了基于ChatGPT的修复机制的效率。
这些研究强调了oracle和单元测试生成方面取得的重大进展,展示了LLM在改进自动化测试工作流程方面不断发展的作用。虽然大多数方法都集中在预训练模型上,但我们的工作通过将上下文与代码文档和开发人员注释相结合而脱颖而出,确保了更有针对性和更高效的测试预言机生成。
3.Oracle 分类器的原理(测试Oracle生成主要集中在提高oracle分类器准确率上)
Oracle 分类器利用测试用例中的信息来分析和学习断言的行为模式。通过对大量测试用例的训练,Oracle 分类器能够识别出断言在不同情况下的正确和错误行为。
Oracle 分类器的原理是基于机器学习算法,通过对大量已知正确和错误的测试用例进行训练,学习到不同测试用例的特征和模式,从而能够对新的测试用例进行分类和预测。以下是 Oracle 分类器的详细介绍:
- 特征提取
- Oracle 分类器首先需要从测试用例中提取特征。这些特征可以包括测试用例的输入数据、执行路径、断言类型、异常信息等。例如,在一个测试用例中,输入数据可能是函数的参数值,执行路径可能是函数内部执行的代码分支,断言类型可能是相等性断言、边界条件断言等。
- 特征提取的目的是将测试用例转换为机器学习算法可以处理的数值或向量形式。例如,可以将输入数据的数值范围、断言的类型等编码为特征向量。
- 机器学习算法应用
- Oracle 分类器通常使用监督学习算法,如支持向量机(SVM)、决策树、随机森林或神经网络等。这些算法通过学习训练数据中的特征与标签之间的关系,构建分类模型。
- 训练数据包括已知正确和错误的测试用例。每个测试用例都有一个标签,表示该测试用例的断言是否正确。例如,标签可以是 1(表示正确)或 0(表示错误)。
- 模型训练
- 在模型训练过程中,机器学习算法会根据训练数据的特征和标签,调整模型的参数,以最小化预测误差。例如,在支持向量机中,算法会寻找一个超平面,将正确和错误的测试用例尽可能分开。
- 训练过程可能包括交叉验证等技术,以提高模型的泛化能力。交叉验证通过将训练数据分成多个子集,轮流使用其中一个子集作为验证集,其他子集作为训练集,从而评估模型的性能。
- 预测与分类
- 当新的测试用例出现时,Oracle 分类器会提取其特征,并将其输入到训练好的模型中。模型会根据学习到的特征与标签之间的关系,预测该测试用例的断言是否正确。
- 例如,如果模型预测一个测试用例的断言为正确(标签为 1),则该测试用例会通过;如果预测为错误(标签为 0),则该测试用例会被标记为失败。
- 模型优化
- Oracle 分类器可以通过不断收集新的测试用例数据,对模型进行优化和更新。例如,当发现模型的预测结果与实际结果不一致时,可以将这些数据加入训练集,重新训练模型,以提高其准确性。
实验
我们在评估中涉及以下研究问题:
- RQ1: AugmenTest能否推断出正确的测试预言?
- RQ2:提供额外的上下文是否会改善断言生成?
评估LLM生成的可变性实验方法:
为了解释LLM产生的响应的固有可变性,我们对每个测试用例重复断言生成10次。这会导致一些断言是正确的,而另一些则不是。因此,我们采用了一种基于阈值的评估机制来衡量在多次运行中生成的测试预言的一致性和可靠性。具体来说,我们对每个实验进行了10次复制,并考虑了三个阈值:60%、80%和100%,它们代表了复制之间不同程度的一致性。阈值表示必须为给定的测试用例生成相同断言才能被视为成功的最小复制百分比。例如,100%阈值是最保守的,这意味着只有当所有10个复制都生成了正确的断言时,测试用例才被认为是有效的,而60%阈值则更宽松,只要求10次运行中有6次正确。
AugmentTest方法:
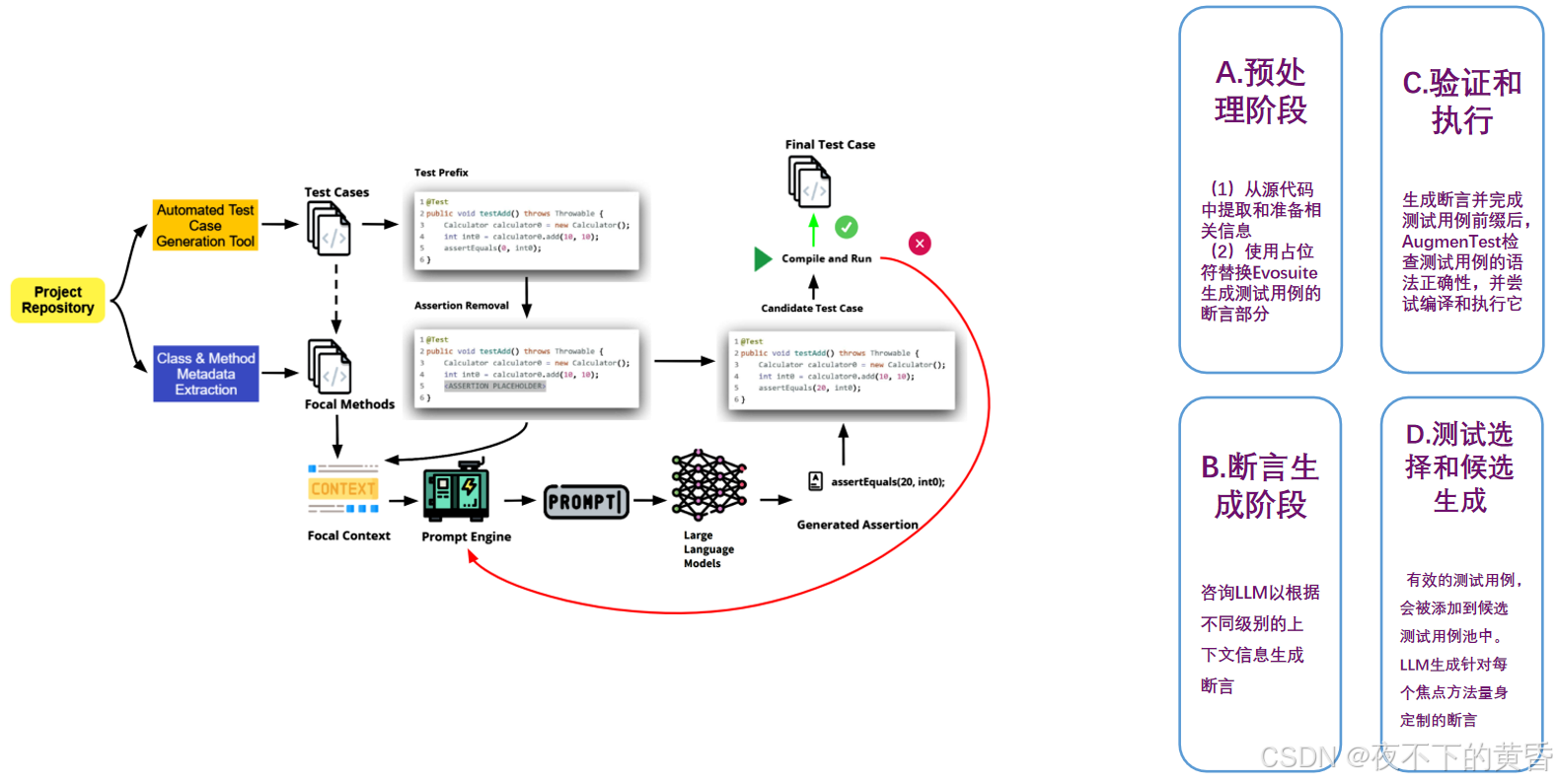
1.测试用例预处理
对于每个测试用例,AugmenTest首先确定测试用例中的焦点方法,并剥离断言,留下测试前缀。测试前缀是通过在测试用例中仅保留非断言语句并为要生成的最终断言留下占位符来准备的。请注意,这里我们假设测试生成工具(例如EvoSuite)与测试用例一起生成一个或多个断言,在这种情况下,AugmenTest会删除它们并用占位符替换它们,占位符将被使用LLM的断言替换。然而,预处理过程同样适用于测试生成工具不生成断言的场景。
2.上下文提示生成
我们的快速设计优先考虑专门为生成JUnit断言而定制的简洁和确定性输出。与更适合开放式任务的传统快速工程技术(如角色扮演或结构化示例)不同,我们的方法侧重于提供清晰且与任务相关的上下文(如方法细节、开发人员评论),同时最大限度地减少响应噪声。显式格式说明(例如,“您的语句应以分号结尾”)确保与自动后处理和下游验证步骤的兼容性。这种设计选择优化了效率并减少了歧义,特别是对于过程性任务,同时适应了闭源API和局部量化模型的令牌和计算约束。
一旦使用占位符对测试用例进行预处理,以便插入最终的断言,下一步就是制定一个适当的提示,发送给LLM,请求替换先前插入的占位符的断言。此阶段的关键方面是用于构建提示上下文的信息级别,这些信息分为四种变体。
(1)简单提示(SP):从存储的结构化数据中提取并替换有关类的基本信息,如类名、字段和测试中的方法。详细信息,如焦点方法名称、签名、参数、依赖关系、返回类型、开发人员注释
(2)扩展提示(EP):除了在简单提示中添加的信息外,有关被测类中所有方法的详细信息也被添加到上下文中,以在扩展提示模板中替换,如清单2所示。
(3) 带通用提示的RAG(RAG):提示中没有添加有关被测类或方法的上下文。相反,检索增强生成用于从结构化数据存储中检索类的相关信息,以生成断言,如清单3所示。
(4) RAG with Simple Prompt(RAG SP):将Simple Prompt和RAG与类/方法信息数据库相结合,有关类的基本信息存在提示词中间,相关的方法信息需要进行检索。
AugmenTest 方法的 RAG(Retrieval-Augmented Generation)变体类型通过结合检索和生成技术来增强测试断言的生成。以下是 RAG 变体类型的实现过程:
(1)数据预处理和元数据提取
- 解析源代码 :AugmenTest 首先分析源代码,提取有关类和方法的基本信息,如方法签名、返回类型、类变量、依赖关系、开发人员注释等。这些信息构成了后续检索和生成的基础。
- 存储元数据 :将提取的元数据存储在结构化或半结构化的格式中,例如 JSON 文件。每个 Java 类对应一个 JSON 条目,包含类级和方法级的详细信息,如类名、文件路径、签名、超类、实现的接口、包、导入的库、方法名、方法签名、返回类型、参数(名称和类型)以及开发人员注释。
(2)向量化存储
- 转换为向量嵌入 :对于使用 RAG 的变体(即 RAG 和 RAG SP),将提取的元数据转换为向量嵌入。这使用了合适的嵌入模型, OpenAI 的 File Search Assistant 工具中的 text-embedding-3-large 模型,该模型具有 256 个维度。
- 存储向量嵌入 :将转换后的向量嵌入存储在结构化的数据存储中,以便在断言生成阶段进行高效的检索。
(3)检索过程
- 检索相关信息 :在生成测试断言时,RAG 变体使用检索增强生成技术,从结构化的数据存储中检索与当前测试用例相关的类和方法信息。这些信息是基于向量嵌入的相似度进行检索的,可以有效地找到与当前测试用例最相关的上下文信息。
(4)断言生成
- 结合检索信息 :检索到的相关信息被结合到生成测试断言的提示(prompt)中。对于 RAG 与通用提示(RAG)变体,提示中不包含特定的类或方法上下文信息,而是依赖检索到的信息来生成断言。对于 RAG 与简单提示(RAG SP)变体,将简单提示中的信息与检索到的向量嵌入相结合,以生成更准确的断言。
- 生成断言 :使用大型语言模型(LLM)根据结合了检索信息的提示生成测试断言。LLM 会根据提供的上下文信息和检索到的相关信息,生成合适的断言语句。
(5)验证和执行
- 验证测试用例 :生成断言后,AugmenTest 检查测试用例的语法正确性,并尝试编译和执行测试用例。如果测试用例编译成功且执行无误(无论通过还是失败),则认为该测试用例是有效的候选者。
- 处理失败情况 :如果测试用例编译失败或执行出错,AugmenTest 会在预定义的预算范围内重新尝试生成断言,直到找到有效的候选者或耗尽预算。
3.使用LLM接口生成断言
一旦准备好上下文提示,AugmenTest就会使用LLM界面,与LLM交互以生成断言。
4.验证和执行
生成断言并完成测试用例前缀后,AugmenTest检查测试用例的语法正确性,并尝试编译和执行它。如果测试用例成功编译并执行无任何错误,则该测试被视为有效的候选。
5.测试选择和候选生成
一旦生成了有效的测试用例,它就会被添加到候选测试用例池中。对项目中的每个测试用例重复此过程,LLM生成针对每个焦点方法量身定制的断言。
结果
RQ1:结果表明,AugmenTest确实可以推断出正确的断言,GPT-4模型在总体成功率方面明显优于LLAMA和HERMES。使用扩展提示(EP)的成功率高于简单提示(SP),这表明提供更多信息可以提高断言推理。
我们在这里注意到,在我们的数据集中,有许多测试用例(由EvoSuite生成)涉及异常处理断言。在这些情况下,实验的变体都无法推断出正确的断言。因此,这里给出的结果仅适用于涉及非异常断言的测试用例。
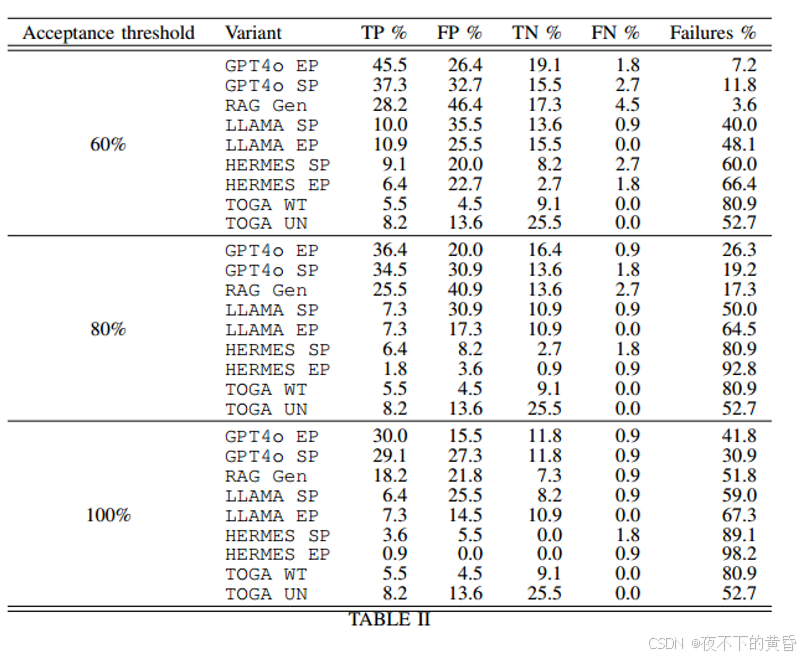
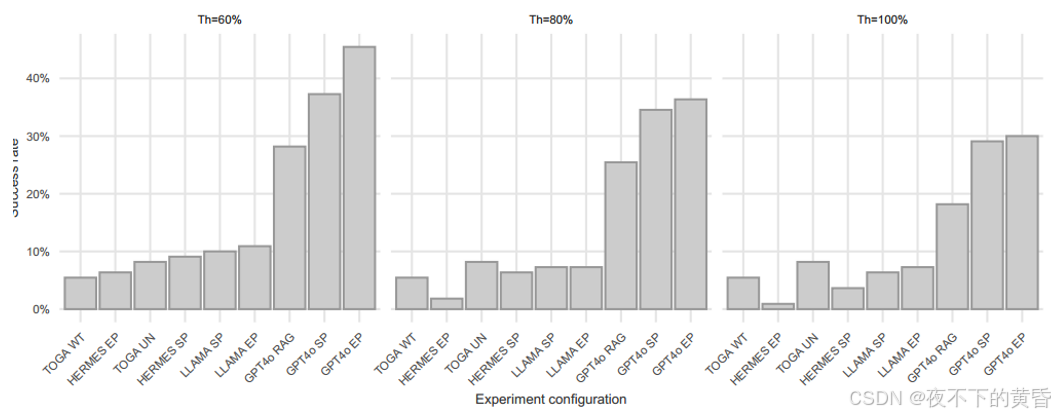
RQ2:在60%的阈值下,AugmenTest的扩展提示(EP)实现了45.5%的最高成功率,而简单提示(SP)的成功率为37.3%。当我们将阈值提高到80%时,EP的表现仍然优于其他变体,为36.4%,而SP的表现为34.5%。在最保守的情况下,所有复制都需要100%的一致性,成功率下降,但EP继续以30%领先,SP为29.1%。有趣的是,基于RAG的方法在所有阈值上的表现一直不佳,这表明,虽然用额外的结构化数据丰富LLM具有潜力,但需要进一步改进才能实现其全部好处。
这些结果表明,虽然AugmenTest可以推断出正确的断言,但RAG的引入并没有带来预期的改进。事实上,RAG Gen变体的表现不如简单提示和扩展提示。GPT4o EP的成功率虽然略高于GPT4o SP,但表明额外的背景确实有所帮助,但并不重要。
我们还从表II的结果中注意到,在几种失败的情况下(Failures列),断言生成没有产生候选,主要是因为生成的断言没有成功编译/运行。这也表明了使用LLM的固有问题,至少在其当前状态下,这不一定能保证有效的响应。
讨论
值得注意的是,这些变体都没有成功推断出任何异常预言机,这是一个意想不到的结果。虽然TOGA通常能够对断言和异常预言机进行分类,但在这种情况下,它未能推断出异常是令人惊讶的,特别是考虑到它在异常预言机上的训练。这表明TOGA在实际场景中泛化超出其训练数据的能力存在潜在局限性。这一发现还表明,在未来处理涉及异常的预言机的工作中,AugmenTest方法需要进一步改进。
一个关键发现是,通过RAG提供更详细和结构化的信息并没有带来更好的预言推理。与更简单的提示相比,RAG变体的表现不佳,这与我们的期望相矛盾,即更多的上下文会导致更准确的断言。这可能表明,在这种情况下,LLM在有效整合复杂结构化数据方面存在局限性。
它还表明,虽然像GPT-4o这样的LLM受益于更丰富的自然语言环境(从SP到EP的改进中可以看出),但除非以更直观或更专业的方式集成,否则它们可能无法从结构化数据中获益。
总结
AugmentTest对Evousite生成的测试用例进行处理,将其断言部分注释掉并替换为占位符,调用LLM对断言部分重新进行生成。AugmentTest有四种类型,分别是简单提示词+LLM,扩展提示词+LLM,简单提示RAG+LLM,简单提示词+RAG+LLM。实证研究后,扩展提示词+LLM类型表现最佳。LLM对结构化信息理解能力不强,结合RAG类型的AugmentTest表现不佳。
文献来源:[2501.17461] AugmenTest: Enhancing Tests with LLM-Driven Oracles



















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











