



OpenCompass 评测




 本节课程聚焦于大语言模型的评测,在后续的课程中我们将介绍多模态大模型的评测方法。
本节课程聚焦于大语言模型的评测,在后续的课程中我们将介绍多模态大模型的评测方法。
OpenCompass 提供了 API 模式评测和本地直接评测两种方式。其中 API 模式评测针对那些以 API 服务形式部署的模型,而本地直接评测则面向那些可以获取到模型权重文件的情况。
我们首先在训练营提供的开发机上创建用于评测 conda 环境:
conda create -n opencompass python=3.10 conda activate opencompass cd /root git clone -b 0.3.3 https://github.com/open-compass/opencompass cd opencompass pip install -e .#等的比较久,不运行这个的话 后面会一直报错,缺少各种包的错误,这句运行了,就不用一直安装各种包,避免报错(后面自己装也是会出现版本错误) pip install -r requirements.txt pip install huggingface_hub==0.25.2 pip install importlib-metadata
更多使用说明,请参考 OpenCompass 官方文档。
评测 API 模型
如果你想要评测通过 API 访问的大语言模型,整个过程其实很简单。首先你需要获取模型的 API 密钥(API Key)和接口地址。以 OpenAI 的 GPT 模型为例,你只需要在 OpenAI 官网申请一个 API Key,然后在评测配置文件中设置好这个密钥和相应的模型参数就可以开始评测了。评测过程中,评测框架会自动向模型服务发送测试用例,获取模型的回复并进行打分分析。整个过程你不需要准备任何模型文件,也不用担心本地计算资源是否足够,只要确保网络连接正常即可。
考虑到 openai 的 API 服务暂时在国内无法直接使用,我们这里以评测 internlm 模型为例,介绍如何评测 API 模型。
export INTERNLM_API_KEY=xxxxxxxxxxxxxxxxxxxxxxx # 填入你申请的 API Key
- 配置模型: 在终端中运行
cd /root/opencompass/和touch opencompass/configs/models/openai/puyu_api.py, 然后打开文件, 贴入以下代码:
import os
from opencompass.models import OpenAISDK
internlm_url = 'https://internlm-chat.intern-ai.org.cn/puyu/api/v1/' # 你前面获得的 api 服务地址
internlm_api_key = os.getenv('INTERNLM_API_KEY')
models = [
dict(
# abbr='internlm2.5-latest',
type=OpenAISDK,
path='internlm2.5-latest', # 请求服务时的 model name
# 换成自己申请的APIkey
key=internlm_api_key, # API key
openai_api_base=internlm_url, # 服务地址
rpm_verbose=True, # 是否打印请求速率
query_per_second=0.16, # 服务请求速率
max_out_len=1024, # 最大输出长度
max_seq_len=4096, # 最大输入长度
temperature=0.01, # 生成温度
batch_size=1, # 批处理大小
retry=3, # 重试次数
)
]
- 配置数据集: 在终端中运行
cd /root/opencompass/和touch opencompass/configs/datasets/demo/demo_cmmlu_chat_gen.py, 然后打开文件, 贴入以下代码:#python /root/opencompass/run.py --models puyu_api.py --datasets demo_cmmlu_chat_gen.py --debug我是用这个运行的,上面这个会报找不到文件 所以我就加了相对地址
from mmengine import read_base
with read_base():
from ..cmmlu.cmmlu_gen_c13365 import cmmlu_datasets
# 每个数据集只取前2个样本进行评测
for d in cmmlu_datasets:
d['abbr'] = 'demo_' + d['abbr']
d['reader_cfg']['test_range'] = '[0:1]' # 这里每个数据集只取1个样本, 方便快速评测.
这样我们使用了 CMMLU Benchmark 的每个子数据集的 1 个样本进行评测.
完成配置后, 在终端中运行: python run.py --models puyu_api.py --datasets demo_cmmlu_chat_gen.py --debug. 预计运行10分钟后, 得到结果:
注意:我做的时候有可能是版本升级了会有huggingface-hub和transformers版本不匹配的问题,可能是因为opencompass更新的原因,pip install update huggingface-hub就可以解决;之后还会出现缺少包的情况,比如:

pip install --upgrade sentence-transformers就可以解决

不是这个pip install rouge,也不是pip install rouge-score,而是pip install py-rouge。
-
python run.py: 这一部分是告诉操作系统使用Python解释器来执行名为run.py的脚本。 -
--models puyu_api.py: 这个参数指定了run.py脚本需要使用的模型文件或配置为puyu_api.py。在许多情况下,这可能意味着run.py支持通过指定不同的模型文件来执行不同的任务或者使用不同的算法。 -
--datasets demo_cmmlu_chat_gen.py: 类似地,这个参数指定了run.py脚本需要使用的数据集文件为demo_cmmlu_chat_gen.py。这可能是用来定义输入数据、数据处理逻辑或者测试用例的脚本。 -
--debug: 这个标志通常用于启用调试模式。当此标志被设置时,run.py脚本可能会输出更多的调试信息,有助于开发人员追踪问题或理解脚本执行的过程。
-
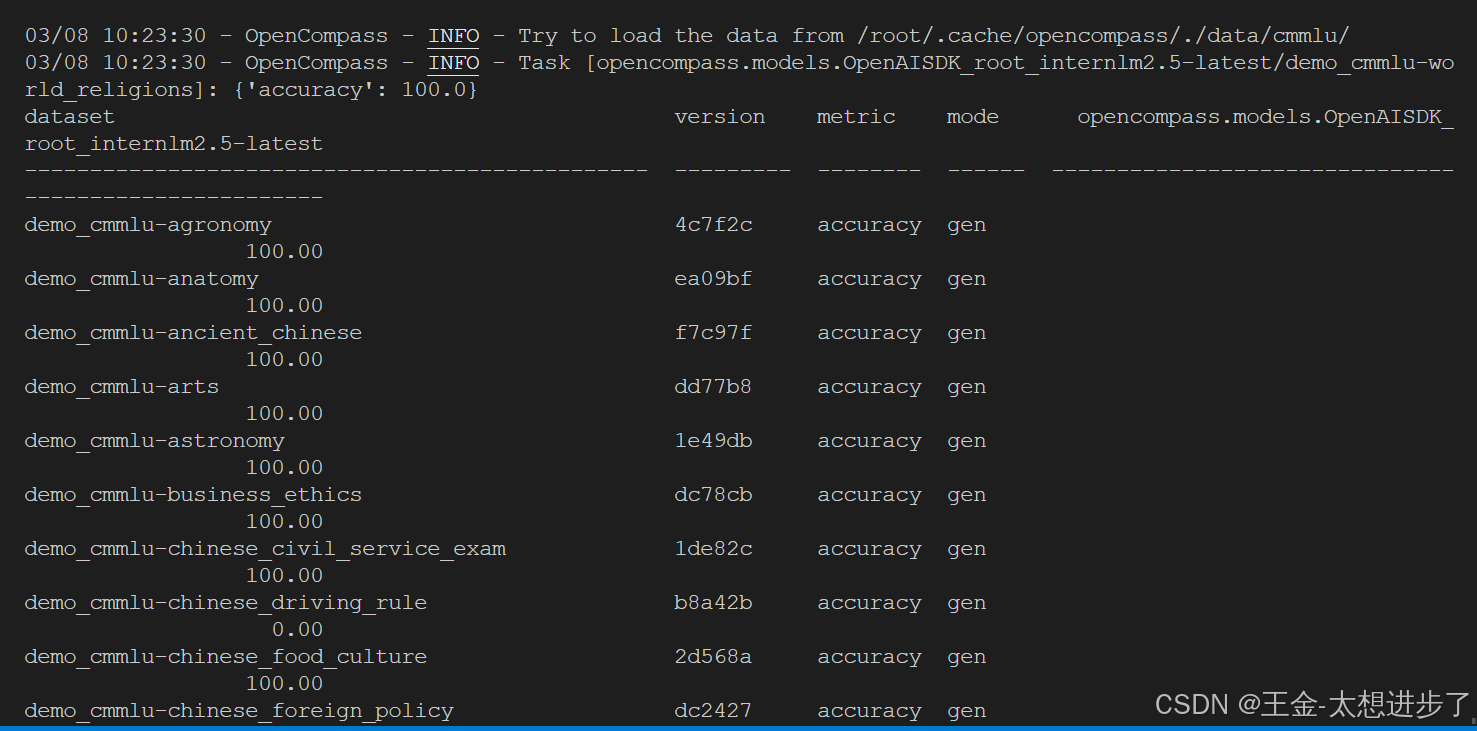

















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









