




论文信息
标题: CogMG: Collaborative Augmentation Between Large Language Model and Knowledge Graph
会议: ACL 2024 —— CCF-A
作者: Tong Zhou等
文章链接:https://arxiv.org/abs/2406.17231
代码链接:https://github.com/tongzhou21/CogMG
文章领域: LLM, KG, Hallucination Mitigation
注:论文代码无法复现
研究背景
LLM 的局限性
大语言模型(如ChatGPT)擅长生成流畅的文本,但在回答事实性问题时,容易产生“幻觉”——即生成看似合理但实际错误的内容。例如,若问“爱因斯坦发明了电话吗?”,LLM可能错误地回答“是的”,因为它依赖训练数据中的关联性,而非真实知识。
知识图谱(KG)的作用与不足
知识图谱是一种结构化的数据库,以“实体-关系-实体”的三元组形式存储事实(如“爱因斯坦-职业-物理学家”)。它能帮助LLM减少错误,但面临两大问题:
- 知识覆盖不全: KG无法预存所有可能的答案,尤其是复杂问题。例如,若问“爱因斯坦在哪个大学获得博士学位?”,KG可能缺少这条信息。
- 更新效率低: 传统方法通过自动抽取文本或补全现有关系来更新KG,但这些更新可能不符合用户的实际需求。例如,KG补全了大量“演员-参演-电影”的三元组,但用户更关心“科学家-毕业院校”的信息。
CogMG框架的协作机制
CogMG的核心思想是让LLM和KG互相补足:
- LLM的强项:理解复杂问题、推理和生成答案。
- KG的强项:提供准确的结构化事实。
三步协作流程
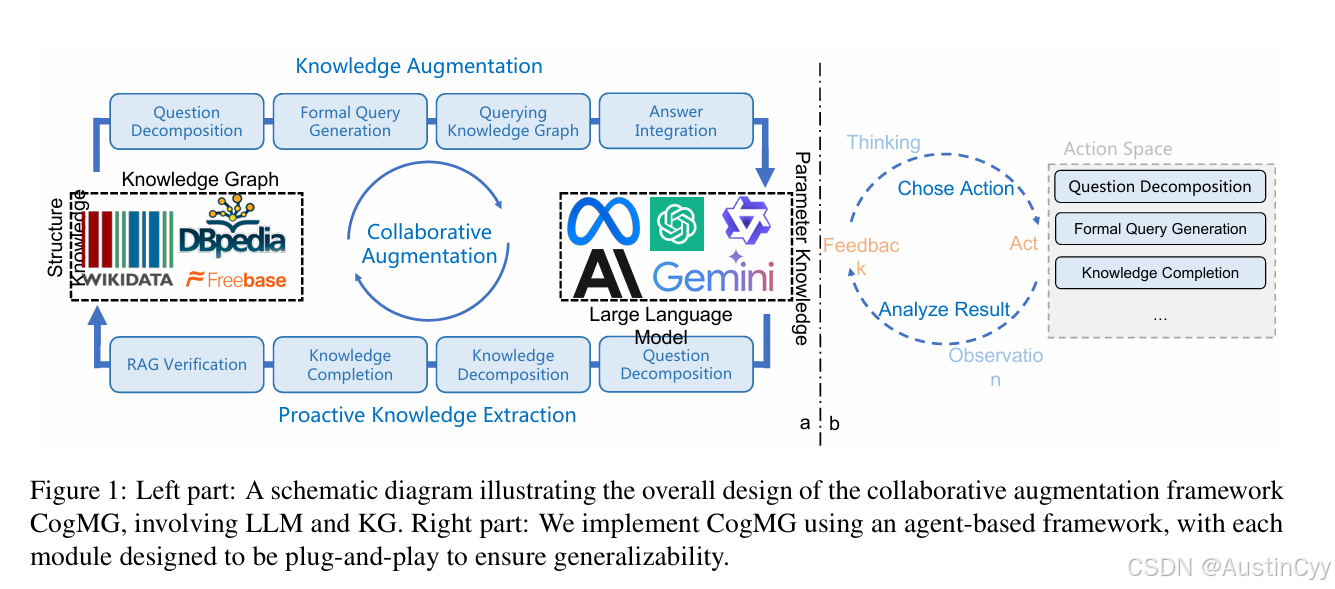
步骤1:查询知识图谱
- 问题分解: LLM将自然语言问题拆解为逻辑步骤。例如,“爱因斯坦的博士导师是谁?” → 分解为“查找爱因斯坦的毕业院校” → “查找该校的导师列表”。
- 生成查询语句: LLM将步骤转换为KG能理解的形式化查询(如KoPL语言)。若查询失败,LLM会标记缺失的三元组(如“(爱因斯坦,博士导师,?)”)。
步骤2:处理查询结果
- 直接回答: 若KG返回结果(如“(爱因斯坦,毕业院校,苏黎世大学)”),LLM生成详细答案。
- 补全缺失知识: 若查询失败,LLM基于自身知识补全三元组(如“(爱因斯坦,博士导师,阿尔弗雷德·克莱纳)”),并通过检索外部文档(如维基百科)验证补全结果。
步骤3:更新知识图谱
- 补全的三元组经过人工审核或自动化验证后加入KG。例如,管理员确认“爱因斯坦的博士导师”信息正确后,KG永久存储该数据,供后续查询使用。
类比: CogMG像一个“医生团队”,KG是病历库,LLM是主治医生。当遇到未知病例(缺失知识)时,医生(LLM)通过查阅文献(检索外部文档)提出治疗方案(补全三元组),经专家(人工审核)确认后更新病历库(KG)。
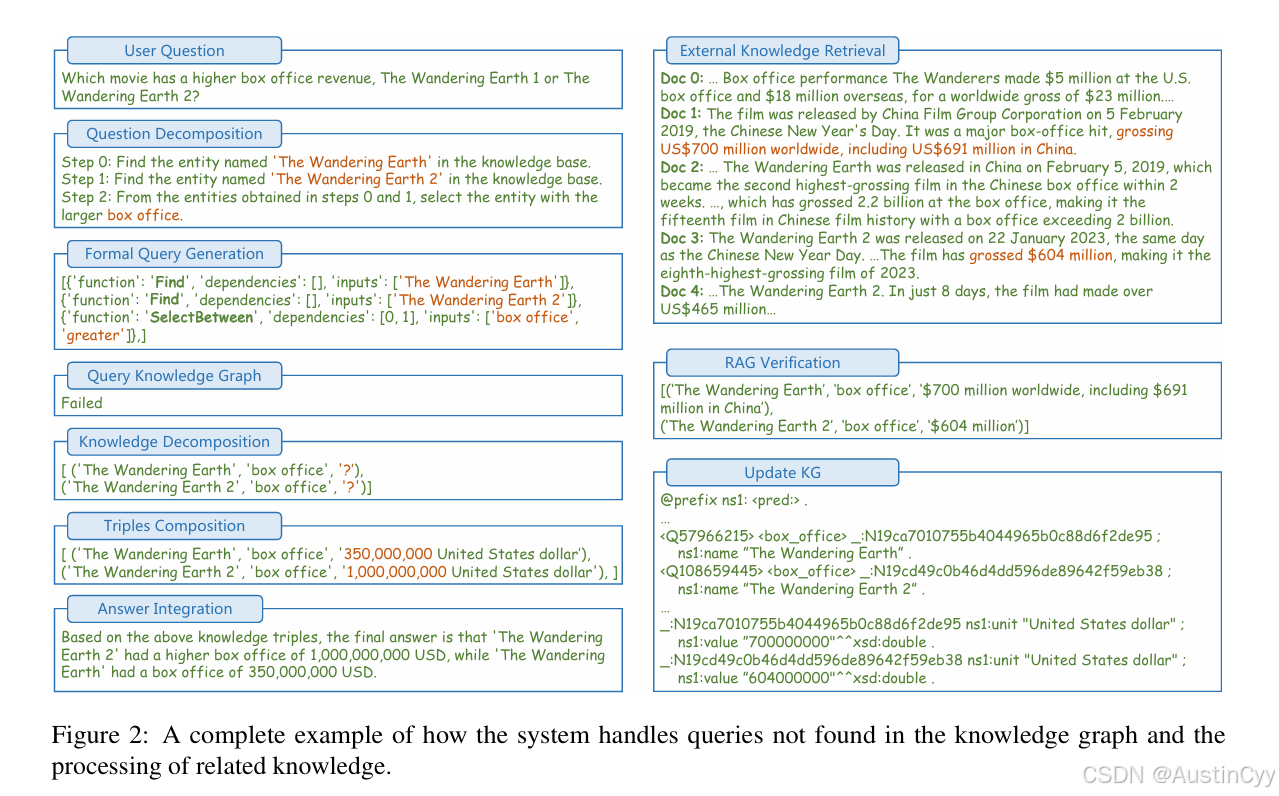
实现细节与技术工具
-
ReAct代理框架:
- 定义:一种模块化框架,支持LLM自主规划步骤(Thought)、调用工具(Action)、接收反馈(Observation)。
- 应用:
- Thought:LLM规划查询步骤(如“先查实体,再查关系”)。
- Action:调用KoPL查询引擎或RAG模块。
- Observation:接收KG结果或检索内容,决定下一步操作。
-
模型与数据:
- LLM主干:Qwen-14B-Chat(开源中文模型),用于问题分解、知识补全和答案生成。
- 知识图谱:基于Wikidata子集(开源KG,含数千万条三元组)。
- 训练数据:50k人工标注的“问题-分解步骤”样本,覆盖复杂逻辑查询。
-
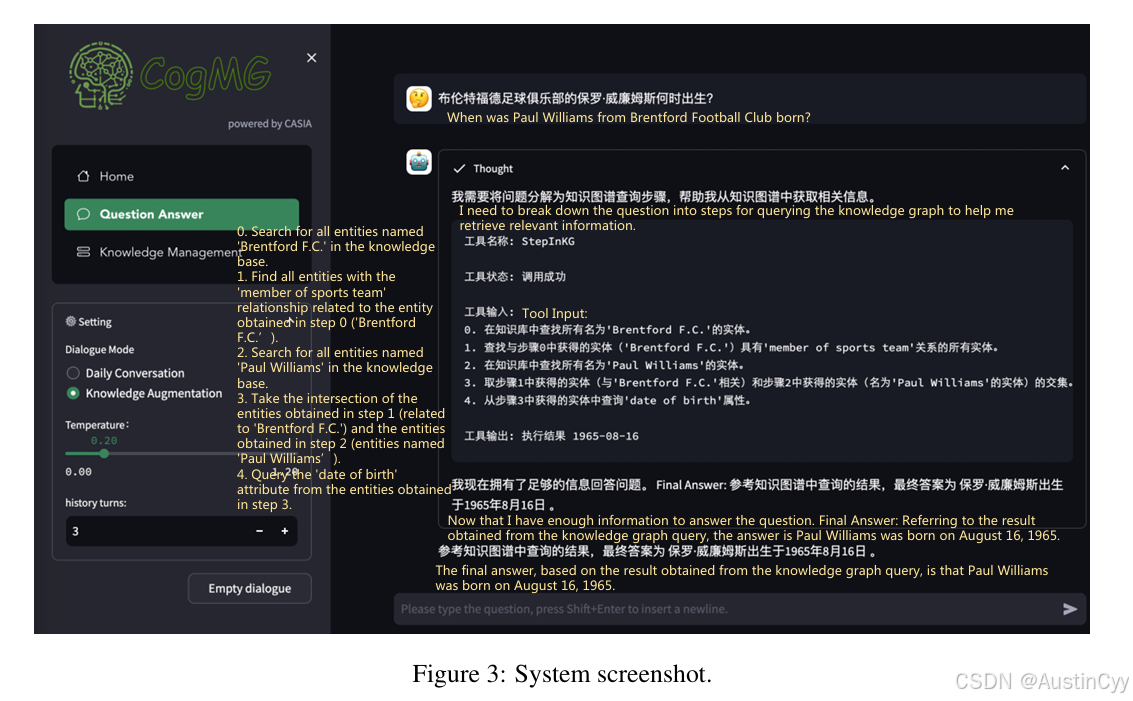
系统架构:
- 用户界面:实时展示LLM的推理路径(如“思考→行动→观察”)。
- 知识管理后台:管理员审核待添加的三元组,支持直接更新、手动修正或RAG验证。
实验结果:效果如何?
在KQA-Pro数据集(包含复杂知识问题的基准测试)中,CogMG的表现如下:
| 方法 | 准确率 | 解释 |
|---|---|---|
| 直接使用LLM | 40% | LLM单独回答,错误率高(如混淆“爱因斯坦发明电话”)。 |
| CogMG(不更新KG) | 44% | 通过KG查询部分解决问题,但未更新KG,后续同类问题仍需依赖LLM补全。 |
| CogMG(更新KG后) | 86% | 动态更新KG后,后续同类问题可直接从KG获取正确答案,准确率大幅提升。 |
关键结论
- KG的动态更新是提升准确率的核心。
- 人工审核虽必要,但通过自动化验证(如RAG)可减少工作量。
创新点与意义
- 双向增强机制: LLM补全KG的缺失知识,KG反哺LLM的事实性支持,形成良性循环。
- 用户需求驱动的更新: 传统KG更新是“盲目”的(如批量添加数据),而CogMG根据用户的实际问题定向补全,更高效。
- 模块化设计: 系统可适配不同的LLM和KG,例如替换为GPT-4或专用领域KG。
局限与未来方向
局限性
- 复杂推理支持有限: 例如多跳问题(如“爱因斯坦的导师的母校是哪所?”)仍需改进。
- 长尾知识依赖人工: 冷门知识(如小众历史事件)的补全仍需人工干预。
未来工作
- 强化学习: 让系统自动优化知识更新策略,减少人工审核。
- 全自动化流程: 结合多模态数据(如图片、表格)进一步验证知识。
总结
CogMG通过LLM与KG的协作,既减少了LLM的“幻觉”,又解决了KG的知识覆盖问题。其动态更新机制使系统越用越聪明,类似于“学习型助手”。未来,这种框架可应用于医疗咨询、法律问答等需要高准确性的领域。
示例场景
- 用户提问:“特斯拉的创始人还创办了哪些公司?”
- LLM补全“(特斯拉,创始人,埃隆·马斯克)”,并检索外部文档验证。
- 更新KG后,后续用户再问“马斯克的公司”,系统可直接从KG返回“特斯拉、SpaceX”。
通过这种协作,CogMG让AI不仅“能回答”,还能“自我完善”。
补充:KoPL查询示例
# 自然语言问题:爱因斯坦的博士导师是谁?
Query(entity="爱因斯坦", relation="毕业院校") → "苏黎世大学"
Query(entity="苏黎世大学", relation="导师列表") → ["阿尔弗雷德·克莱纳"]

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









