







 超级会员免费看
超级会员免费看
大家好,我是 同学小张,+v: jasper_8017 一起交流,持续学习AI大模型应用实战案例,持续分享,欢迎大家点赞+关注,订阅我的大模型专栏,共同学习和进步。
现在订阅专栏,+微信私信我 返3元,即将涨价!
搜罗了一下目前常用的和比较前沿的RAG方法和研究,20多种。
文章目录
-
- 0. 标准 RAG
- 1. GraphRAG
- 2. Modular RAG
- 3. Advanced RAG
- 4. TRAQ
- 5. ColBERT
- 6. AgenticRAG
- 7. Multimodal RAG
- 8. HyDE(Hypothetical Document Embeddings)
- 9. RARE(Retrieval-Augmented Reasoning Engine)
- 10. RA-DIT
- 11. DSP(Demonstrate-Search-Predict)
- 12. RETRO
- 13. Self-RAG
- 14. KG2RAG
- 15. CoRAG(Collaborative RAG)
- 16. Auto-RAG
- 17. MemoRAG
- 18. HtmlRAG
- 19. FastRAG
- 20. 其他方法(简要列举)
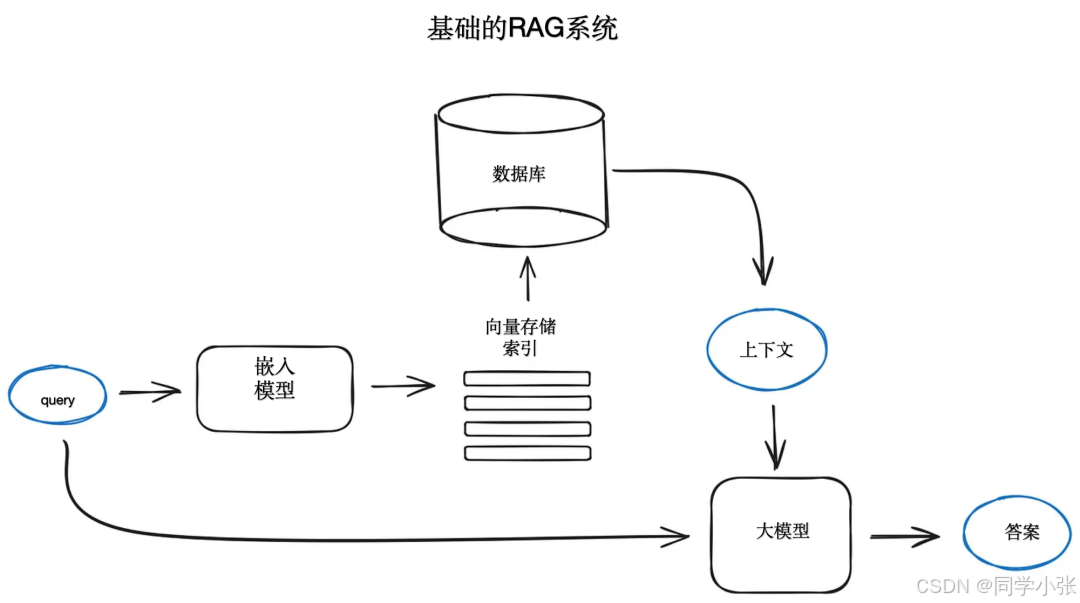
0. 标准 RAG
- 介绍 :一个基本的 RAG 系统由检索模块和生成模块组成。系统会对查询进行编码,检索相关的文档块,然后为基于 transformer 的 LLM 构建丰富的提示。
- 创新点 :将外部知识动态注入生成过程,而无需修改 LLM 本身,就像是给 LLM 戴上了一副能随时获取新知识的 “眼镜”。
- 优点 :简单有效,能够提升 LLM 的生成效果。
- 缺点 :存在检索到很多与 query 无关的片段,增加噪声输入,与 query 关联的信息比较稀疏,需要 LLM 本身去提炼或挖掘利用。
1. GraphRAG
- 创新点:结合知识图谱与RAG,通过实体和关系建模增强语义关联,支持多跳推理和复杂查询。例如,利用图谱的拓扑结构优化检索路径,提升对开放域问题的回答质量。
- 优点:显著提高答案的全面性和逻辑性,适用于知识密集型任务(如医学、法律问答)。
- 缺点:图谱构建成本高,多模态图谱融合难度大。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











