




上篇文章我们本地编译运行了 llama.cpp,跑通了本地模型的运行。但是用的是 llama.cpp 自带的调用模型和运行程序,今天,我们不使用 llama.cpp 自带的 main 程序,我们要自己写代码调用 libllama 库。
0. 系列文章
1. 准备工作
(1)直接在 llama.cpp 根目录(你可以自己选择喜欢的目录)下创建一个新目录 HelloAI:
mkdir HelloAI

(2)在 HelloAI 目录下,创建 main.cpp 主程序文件和 CMakeLists.txt 文件。
(3)main.cpp 和 CMakeLists.txt 文件写入最小化代码,先保证可运行。
- main.cpp 代码:
#include <iostream>
int main(int argc, char** argv)
{
std::cout << "Hello World!" << std::endl;
return 0;
}
- CMakeLists.txt 代码:
cmake_minimum_required(VERSION 3.10)
project(HelloAI)
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 添加可执行文件
add_executable(HelloAI main.cpp)
- 测试编译运行
cd HelloAI
mkdir build
cd build
cmake ..
make
./HelloAI
运行结果如下:
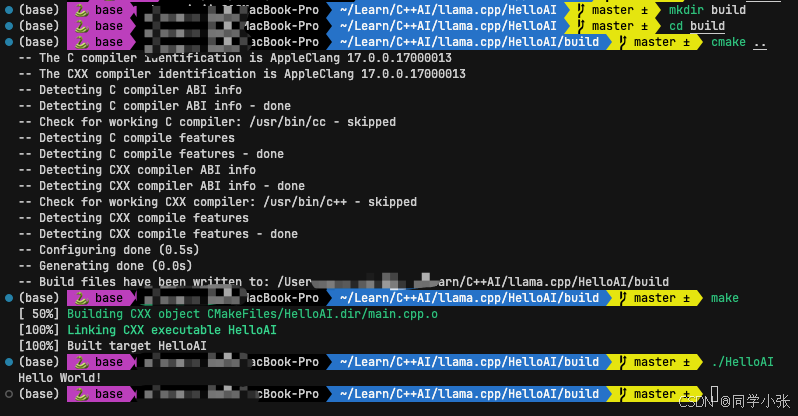
至此,准备工作完成,剩下的任务就是往里面加代码,与 llama.cpp 联通 !
2. 编写 main.cpp
这是一个最小化的推理代码。它做了三件事:
- 加载模型 -> 将文本转为数字(Tokenize) -> 循环预测下一个数字。
2.1 加载模型
把模型文件从硬盘加载到内存中,准备好计算资源。
(1)模型路径(上一篇文章中咱们自己下载的模型)
(2)获取模型默认参数
(3)加载模型文件
std::string model_path = "xxx/models/qwen2.5-0.5b-instruct-q4_k_m.gguf"; // 模型文件绝对路径
llama_model_params model_params = llama_model_default_params(); // 获取默认模型参数
// 从文件加载模型,返回模型指针
llama_model* model = llama_model_load_from_file(model_path.c_str(), model_params);
if (!model) { // 模型加载失败检查
std::cerr << "Failed to load model: " << model_path << std::endl;
return 1;
}
2.2 将文本转化为数字(tokenization)
把你写的中文 Prompt 转换成模型能理解的 Token 序列(整数数组)。
(1)获取模型词汇表: 模型不认识“你好”,它只认识数字。你需要拿到模型的“字典”指针,后面用来把文字转换成数字。
(2)对 Prompt 进行 Token 化
// 获取模型的词汇表(用于tokenization)
const llama_vocab* vocab = llama_model_get_vocab(model);
// 首先获取token数量
const int n_prompt = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), nullptr, 0, true, true);
std::vector<llama_token> prompt_tokens(n_prompt); // 存储token序列的vector
// 执行tokenization
if (llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true) < 0)
{
std::cerr << "Failed to tokenize prompt" << std::endl;
return 1;
}
2.3 准备推理
2.3.1 创建推理上下文: 推理的“工作区”
上下文是模型“思考”时的临时记忆区。
- 设置 ctx_params.n_ctx(比如 2048),决定模型能记多少东西。
- 设置 ctx_params.n_batch,决定一次处理多少 token。
- 使用 llama_init_from_model 创建上下文对象 ctx。
llama_context_params ctx_params = llama_context_default_params(); // 默认上下文参数
ctx_params.n_ctx = 2048; // 上下文窗口大小(最大token数)
ctx_params.n_batch = n_prompt; // 批处理大小(提升推理效率)
ctx_params.no_perf = false; // 启用性能统计
// 从模型创建推理上下文
llama_context* ctx = llama_init_from_model(model, ctx_params);
if (!ctx) { // 上下文创建失败检查
std::cerr << "Failed to create context" << std::endl;
return 1;
}
2.3.2 配置采样器:规定模型“怎么说话”
采样器决定模型如何选择下一个词(是选概率最大的,还是随机一点?)。
代码中使用的是 Greedy (贪婪) 策略:永远只选概率最大的那个词(最稳,但可能缺乏创造力)。
auto sparams = llama_sampler_chain_default_params(); // 默认采样器参数
sparams.no_perf = false; // 启用性能统计
llama_sampler* smpl = llama_sampler_chain_init(sparams); // 初始化采样器链
// 添加贪婪采样策略(每次选择概率最高的token)
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
2.4 正式推理
这是最核心的部分。输入 -> 模型计算 -> 吐出一个词 -> 再把这个词输进去 -> 循环。
2.4.1 准备第一批数据 (Batch)
使用 llama_batch_get_one 把刚才转换好的 prompt_tokens 打包成一个批次。
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
2.4.2 处理编码器模型 (可选,本文案例可以不要)
注:大部分聊天模型(如 Llama, Qwen)不需要这一步,只有 T5 等架构需要。
如果模型有 Encoder,先跑 llama_encode,然后准备 Decoder 的起始 Token。
// 如果是编码器-解码器架构的模型
if (llama_model_has_encoder(model))
{
// 先编码prompt
if (llama_encode(ctx, batch))
{
std::cerr << "llama_encode failed" << std::endl;
return 1;
}
// 获取解码起始token
llama_token decoder_start_token_id = llama_model_decoder_start_token(model);
if (decoder_start_token_id == LLAMA_TOKEN_NULL)
{
// 如果模型没有指定,使用BOS(begin of sequence) token
decoder_start_token_id = llama_vocab_bos(vocab);
}
// 准备解码阶段的batch
batch = llama_batch_get_one(&decoder_start_token_id, 1);
}
2.3.4 主推理循环 - 生成文本
直到达到生成的长度限制 n_predict。
// 循环直到生成足够token或遇到结束标记
for (int n_pos = 0; n_pos + batch.n_tokens < n_prompt + n_predict; )
{
n_pos += batch.n_tokens; // 更新已处理token位置
}
具体步骤:
2.3.4.1 解码 (Decode)
if (llama_decode(ctx, batch))
{
std::cerr << "llama_decode failed" << std::endl;
return 1;
}
2.3.4.2 采样 (Sample)
调用 llama_sampler_sample 挑出下一个 Token (new_token_id)。
new_token_id = llama_sampler_sample(smpl, ctx, -1);
2.3.4.3 检查结束 (Check End)
如果生成的 Token 是“结束符”(EOG),就跳出循环。
if (llama_vocab_is_eog(vocab, new_token_id)) {
break; // 遇到结束标记则终止生成
}
2.3.4.4 更新Batch
把这个新生成的 Token 放入 batch,作为下一次推理的输入。
batch = llama_batch_get_one(&new_token_id, 1);
然后进入下一次循环。
3. 完整代码与运行结果
3.1 CMakeLists.txt 文件加入 llama.cpp 相关内容
这里就不细讲了,不是本文重点。
文件中重点关注:
- llama.cpp 目录路径
- 之前你编译的 llama 库的路径
- 如果你跟我一样是mac电脑,库的后缀名是
.dylib
cmake_minimum_required(VERSION 3.10)
project(HelloAI)
set(CMAKE_CXX_STANDARD 17)
# 设置 llama.cpp 的路径
set(LLAMA_DIR "${CMAKE_SOURCE_DIR}/../../llama.cpp")
# 头文件路径
include_directories(${LLAMA_DIR}/include)
include_directories(${LLAMA_DIR}/ggml/include)
# 库文件路径 (根据你的编译结果,可能会变)
link_directories(${LLAMA_DIR}/build/src)
link_directories(${LLAMA_DIR}/build/ggml/src)
link_directories(${LLAMA_DIR}/build/common) # 有时候需要 common
add_executable(HelloAI main.cpp)
# 链接库
# 这里使用 glob 暴力链接所有 ggml 相关的静态库,防止漏掉
file(GLOB GGML_LIBS "${LLAMA_DIR}/build/bin/*dylib")
target_link_libraries(HelloAI
${LLAMA_DIR}/build/bin/libllama.dylib
${GGML_LIBS}
)
if (APPLE)
target_link_libraries(HelloAI "-framework Foundation -framework Metal -framework MetalKit")
endif()
3.2 main.cpp 完整代码 & 详细注释
// 标准库头文件引入
#include <iostream> // 用于标准输入输出流操作
#include <vector> // 使用动态数组容器存储token序列
#include <string> // 字符串处理
#include <cstring> // C风格字符串处理
#include "llama.h" // llama.cpp核心库,提供LLM推理功能
// -------------------------------------------------------------------------
// 主函数 - 程序入口
// -------------------------------------------------------------------------
int main(int argc, char** argv) {
// 1. 模型路径和推理参数配置
std::string model_path = "xxxx/models/qwen2.5-0.5b-instruct-q4_k_m.gguf"; // 模型文件绝对路径
std::string prompt = "你是谁?"; // 初始提示词(prompt)
int n_predict = 32; // 最大生成token数量限制
// 2. 初始化GGML后端计算资源
ggml_backend_load_all(); // 加载所有可用的后端计算设备(CPU/GPU等)
// 3. 加载LLM模型
llama_model_params model_params = llama_model_default_params(); // 获取默认模型参数
// model_params.n_gpu_layers = 99; // 开启Metal GPU加速(适用于macOS)
// 从文件加载模型,返回模型指针
llama_model* model = llama_model_load_from_file(model_path.c_str(), model_params);
if (!model) { // 模型加载失败检查
std::cerr << "Failed to load model: " << model_path << std::endl;
return 1;
}
// 获取模型的词汇表(用于tokenization)
const llama_vocab* vocab = llama_model_get_vocab(model);
// 4. 将提示词(prompt)转换为token序列
// 4.1 首先获取token数量
const int n_prompt = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), nullptr, 0, true, true);
// 4.2 分配空间并执行tokenization
std::vector<llama_token> prompt_tokens(n_prompt); // 存储token序列的vector
if (llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true) < 0)
{
std::cerr << "Failed to tokenize prompt" << std::endl;
return 1;
}
// 5. 创建推理上下文(context)
llama_context_params ctx_params = llama_context_default_params(); // 默认上下文参数
ctx_params.n_ctx = 2048; // 上下文窗口大小(最大token数)
ctx_params.n_batch = n_prompt; // 批处理大小(提升推理效率)
ctx_params.no_perf = false; // 启用性能统计
// 从模型创建推理上下文
llama_context* ctx = llama_init_from_model(model, ctx_params);
if (!ctx) { // 上下文创建失败检查
std::cerr << "Failed to create context" << std::endl;
return 1;
}
// 6. 初始化采样器(sampler) - 控制文本生成策略
auto sparams = llama_sampler_chain_default_params(); // 默认采样器参数
sparams.no_perf = false; // 启用性能统计
llama_sampler* smpl = llama_sampler_chain_init(sparams); // 初始化采样器链
// 添加贪婪采样策略(每次选择概率最高的token)
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
// 打印原始prompt(用于调试)
for (auto id : prompt_tokens) {
char buf[128];
// 将token转换为可读文本
int n = llama_token_to_piece(vocab, id, buf, sizeof(buf), 0, true);
if (n < 0) {
fprintf(stderr, "%s: error: failed to convert token to piece\n", __func__);
return 1;
}
std::string s(buf, n);
printf("%s", s.c_str()); // 打印token对应的文本
}
// 7. 准备批处理(batch)数据
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
// 如果是编码器-解码器架构的模型
// if (llama_model_has_encoder(model))
// {
// // 先编码prompt
// if (llama_encode(ctx, batch))
// {
// std::cerr << "llama_encode failed" << std::endl;
// return 1;
// }
// // 获取解码起始token
// llama_token decoder_start_token_id = llama_model_decoder_start_token(model);
// if (decoder_start_token_id == LLAMA_TOKEN_NULL)
// {
// // 如果模型没有指定,使用BOS(begin of sequence) token
// decoder_start_token_id = llama_vocab_bos(vocab);
// }
// // 准备解码阶段的batch
// batch = llama_batch_get_one(&decoder_start_token_id, 1);
// }
// 8. 主推理循环 - 生成文本
const auto t_main_start = ggml_time_us(); // 记录开始时间(微秒)
int n_decode = 0; // 解码token计数器
llama_token new_token_id; // 存储新生成的token
// 循环直到生成足够token或遇到结束标记
for (int n_pos = 0; n_pos + batch.n_tokens < n_prompt + n_predict; )
{
// 执行解码推理
if (llama_decode(ctx, batch))
{
std::cerr << "llama_decode failed" << std::endl;
return 1;
}
n_pos += batch.n_tokens; // 更新已处理token位置
// 选择下一个token
{
// 使用采样器选择最可能的下一个token
new_token_id = llama_sampler_sample(smpl, ctx, -1);
// 检查是否是结束标记(End of Generation)
if (llama_vocab_is_eog(vocab, new_token_id)) {
break; // 遇到结束标记则终止生成
}
// 将token转换为可读文本
char buf[128];
int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true);
if (n < 0) {
std::cerr << "Failed to convert token to piece" << std::endl;
return 1;
}
std::string s(buf, n);
std::cout << s; // 输出生成的文本
// 准备下一轮推理的batch(单token)
batch = llama_batch_get_one(&new_token_id, 1);
n_decode += 1; // 增加解码计数
}
}
// 生成结束提示
std::cout << "\n\nDone!" << std::endl;
// 9. 性能统计
const auto t_main_end = ggml_time_us(); // 记录结束时间
// 计算并输出生成速度(tokens/秒)
std::cout << "decoded: " << n_decode << " tokens in "
<< (t_main_end - t_main_start) / 1000000.0f << " s, speed: "
<< n_decode / ((t_main_end - t_main_start) / 1000000.0f) << " tok/s"
<< std::endl;
// 打印采样器和上下文的性能数据
llama_perf_sampler_print(smpl);
llama_perf_context_print(ctx);
// 10. 资源清理
llama_sampler_free(smpl); // 释放采样器
llama_free(ctx); // 释放上下文
llama_model_free(model); // 释放模型
return 0; // 程序正常退出
}
3.3 编译运行
mkdir build
cd build
cmake ..
make
./HelloAI
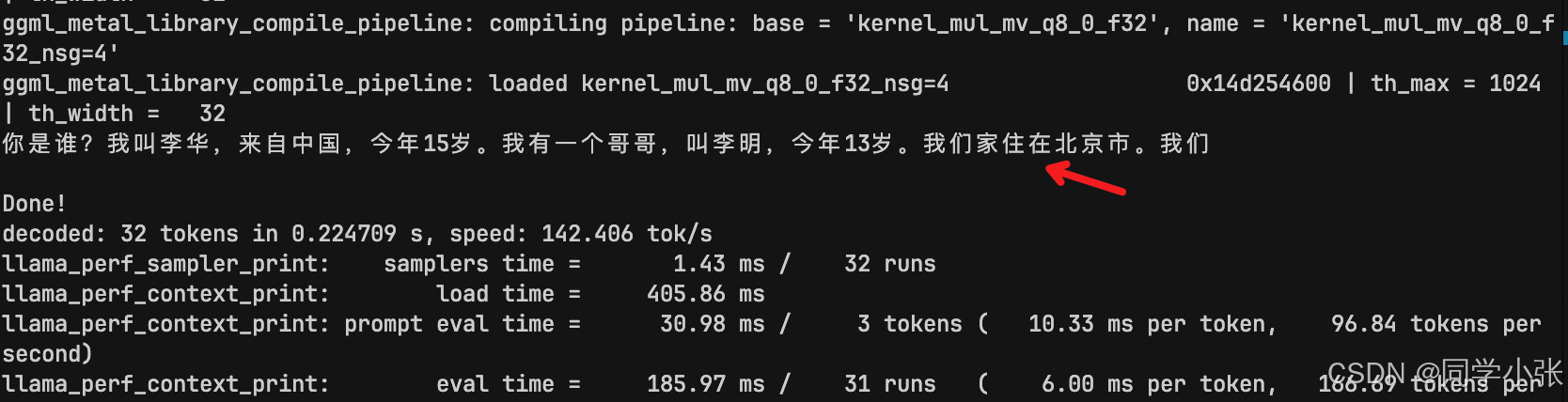
3.4 运行结果
可以看到正常回复了我的提问,当然,被截断了,因为到达了 n_predict 数量。
4. 总结
总结一下主要步骤:
(1)指路:定好模型路径字符串。
(2)载入:Load Backend -> Load Model -> Get Vocab。
(3)预处理:Tokenize (把字符串变数字)。
(4)配置:Create Context (申请内存) -> Init Sampler (设定规则)。
(5)跑圈:Batch (填入Prompt) -> Decode (计算) -> Sample (选词) -> Print -> Next Batch (填入新词) -> Repeat。
(6)关灯:Free 所有指针。
本文结束,至此,我们大体知道了手动调用一个模型文件的总过程。下篇文章,我们在这个 main.cpp 文件上,深入看一下 llama.cpp 接口的定义,以及一些编码过程中可能有的疑问,例如: 为什么调用模型文件是这么一个过程?Batch是什么?等。




















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











