




 本文介绍02号爬虫,在01爬虫基础上,进入文章链接解析详细内容。先分析页面,得到解析规则,接着自定义解析函数,重写相关函数以控制跳转。完成爬虫后给出运行结果和源码,还简单介绍了爬虫中Python的super()和yield特色用法。
本文介绍02号爬虫,在01爬虫基础上,进入文章链接解析详细内容。先分析页面,得到解析规则,接着自定义解析函数,重写相关函数以控制跳转。完成爬虫后给出运行结果和源码,还简单介绍了爬虫中Python的super()和yield特色用法。
在知道了01爬虫的运行原理之后,现在能让其去做更多的事情,在上一节中已经拿到了页面上所有文章的链接,现在可以进入每一条链接,可以拿到文章的详细内容,对其进行一一解析,这就是本文的内容,02号爬虫。
-
分析页面
首先访问优快云博客主页:https://blog.youkuaiyun.com/,
按照01号爬虫的解析规则,解析出每一篇文章的详细链接。然后依次访问链接,进入文章的详情页面,解析内容为:标题,时间,阅读数。
想要解析文章的内容,当然是可以的,只不过文章的内容太多,不方便显示,所以此处不解析文章的内容,感兴趣的朋友可以自行去测试。下图为例子:
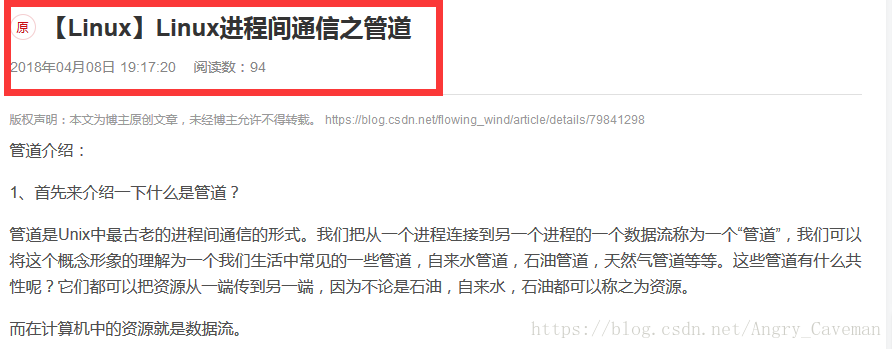
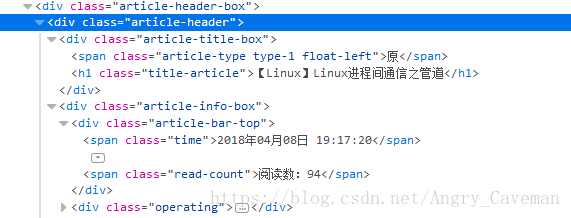
查看页面元素,依照xpath的原理,得到如下解析规则:
‘title’://div[@class=’article-header’]//div//h1/text()
‘time’://span[@class=‘time’]/text()
‘readcount’://span[@class=’read-count’]/text()至此,得到了页面内容的解析规则。
-
解析函数
我们需要优先解析博客首页的那些文章链接。可以自定义一个解析函数_url_parse(self,response),response用于接收返回的response对象。
这个函数需要做两件事情,1,从页面中解析文章链接;2,对解析出来的链接发送请求。解析链接没有什么问题,问题在于如何对解析得到的链接发送新请求。在上一篇文章中提到了Request函数。可以直接用Request发送请求。
Request方法当然是没有问题的,但是,事实上爬虫所继承的scarpy.Spider中有一个函数,之前也提到过,那就是make_requests_from_url(self, url),本质上它就是在调用Request函数,所以,重写它即可,还有一个原因就是,爬虫启动,访问self.start_urls的起始链接列表时,调用的也是这个函数,我们需要“控制”它跳转到_url_parse(self,response),而不是跳转到默认的parse(self,response)函数
先将make_requests_from_url(self, url)函数重写,让它访问博客首页时,回调到我们自定义的_url_parse(self,response)。
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url,dont_filter=True,callback=self. _url_parse)只需要将request的callback属性指定成我们的自定义函数即可。直接给callback赋定值似乎不够灵活,我们后续可能会继续调用make_requests_from_url(self, url),让它回调到别的函数。因此需要一个自定义变量self. custom_way,在初始化函数中给它赋初始值
重写初始化函数:
def __init__(self,name=None, **kwargs):
self.custom_way = self._url_parse
super(myspider02,self).__init__()重写make_requests_from_url(self, url):
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url,dont_filter=True,callback=self.custom_way)这时可以完成_url_parse(self,response)函数,让它解析出新的链接,访问新的链接,并且回调到另一个函数_content_parse(self,response)(这个函数用于解析页面中想要的数据)。
完成_url_parse(self,response)函数:
def _url_parse(self,response):
print('正在解析url')
hrefs=response.selector.xpath('//div[@class="title"]//h2//a/@href').extract()
print(hrefs)
self.custom_way = self._content_parse
for href in hrefs:
yield self.make_requests_from_url(href)更改回调函数的方式就是,更改self. custom_way的值。现在去完成页面解析函数_content_parse(self,response)即可,比较简单,不需要单独贴出来,请在下面的完整源码中查看。
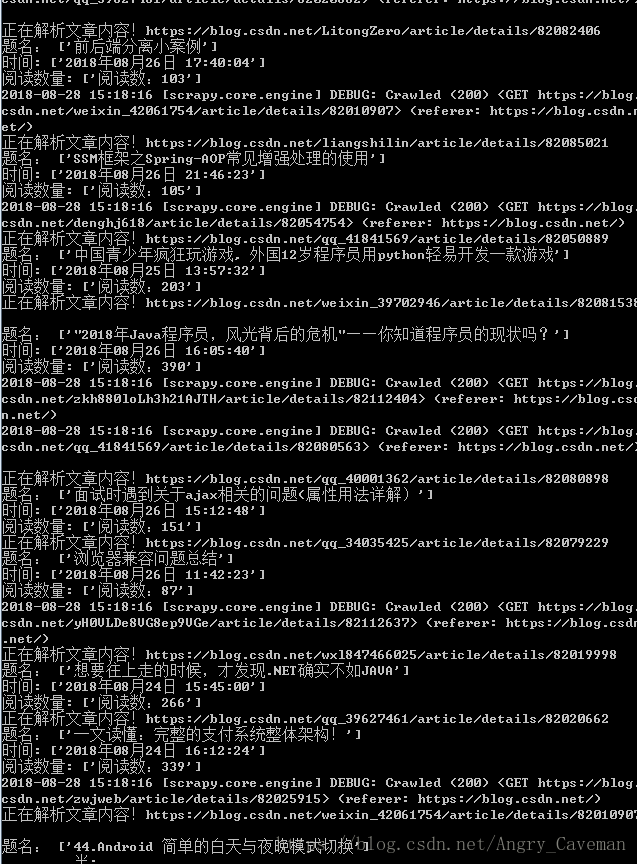
这样,整个爬虫也就完成了。以下是运行结果和完整的源码。
运行结果:
02号爬虫源码如下,windows记事本的话记得另存文件为utf-8:
#coding=utf-8
import scrapy
from scrapy.http import Request
class myspider02(scrapy.Spider):
name='02'
start_urls=['https://blog.youkuaiyun.com/']
def __init__(self,name=None, **kwargs):
self.custom_way = self._url_parse
super(myspider02,self).__init__()
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url,dont_filter=True,callback=self.custom_way)
def _content_parse(self,response):
print('正在解析文章内容!'+response.url)
title=response.selector.xpath('//div[@class="article-header"]//div//h1/text()').extract()
time=response.selector.xpath('//span[@class="time"]/text()').extract()
readcount=response.selector.xpath('//span[@class="read-count"]/text()').extract()
print('题名:',title)
print('时间:',time)
print('阅读数量:',readcount)
def _url_parse(self,response):
print('正在解析url')
hrefs=response.selector.xpath('//div[@class="title"]//h2//a/@href').extract()
print(hrefs)
self.custom_way = self._content_parse
for href in hrefs:
yield self.make_requests_from_url(href)-
关于python
在这个爬虫中用到了两个python语言比较有特色的用法。
一个是,super()函数的使用。
一个是,yield的用法。
如果要解释清楚,需要一定的篇幅,因为与scrapy无关,这里只简单介绍一下。
Super()用于调用超类的方法,所传递的参数为,类名和对象,此处为myspider02和self。我们通过它调用了scrapy.Spider的初始函数,所以scrapy.Spider中没有被重写的方法,依旧可以正常使用。
Yield用于生成器,拥有yield的函数,就是一个生成器,它和return有很大的区别,生成器一次只返回一个结果。例如return返回一个列表,那么yield只是逐个返回列表里的内容,在很多程序中,这样占用资源少(但是人们普遍还是用return),在scrapy中发起请求时,会要求你返回一个request,item或者其他等等,此时最好用yield。

















 8798
8798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









