



在人工智能领域,多模态技术正迅速崛起,成为推动下一次重大进步的关键力量。回顾 2024 年生成式人工智能的发展趋势,我大胆预测:多模态模型将在年末前走向主流,甚至成为行业新常态。
传统的人工智能系统往往局限于单一数据类型的处理,例如仅能解析文本。然而,环顾我们的日常生活,世界是多维度的。人类通过多种感官(视觉、听觉、触觉等)感知和理解周围环境,而多模态人工智能的目标正是模仿这种复杂的感知方式。
理想情况下,多模态 AI 应该能够接受多种数据类型的组合——文本、图像、视频、音频等,并在一个统一的模型中加以处理。这种能力将显著提升生成式 AI 的适应性和应用场景的广度,让人与机器的交互更加自然高效。

大型语言模型(LLMs)虽然功能强大,但也存在一定局限性,例如有限的上下文窗口和知识更新的截止日期。为了克服这些不足,可以借助一种名为检索增强生成(Retrieval-Augmented Generation, RAG)的方法。这一过程由两个核心步骤组成:检索和生成。
首先,RAG 在响应用户查询时,会从相关数据源中检索最匹配的信息。随后,这些数据被用来支持 LLM 为用户生成更加精准和上下文相关的回答。
在此过程中,矢量数据库发挥了关键作用。它通过存储文本、图像、音频和视频等多种数据类型的嵌入,支持高效的多模态数据检索。这种方式确保 LLM 不仅能够理解用户查询,还能动态访问最相关的多模态数据,从而生成更丰富、更全面的响应。
在本文中,我们将详细探讨多模态 RAG 的两个关键阶段:检索和生成。首先,我们将介绍两种基于矢量数据库的多模态检索方法,阐释如何高效存储和检索文本与图像数据。接着,在生成阶段,我们将展示如何利用大型语言模型(LLMs),结合用户查询和检索到的数据,生成精准且上下文相关的响应。
通过这两个环节的解析,您将全面了解多模态 RAG 如何发挥其独特优势,为复杂任务提供创新解决方案。
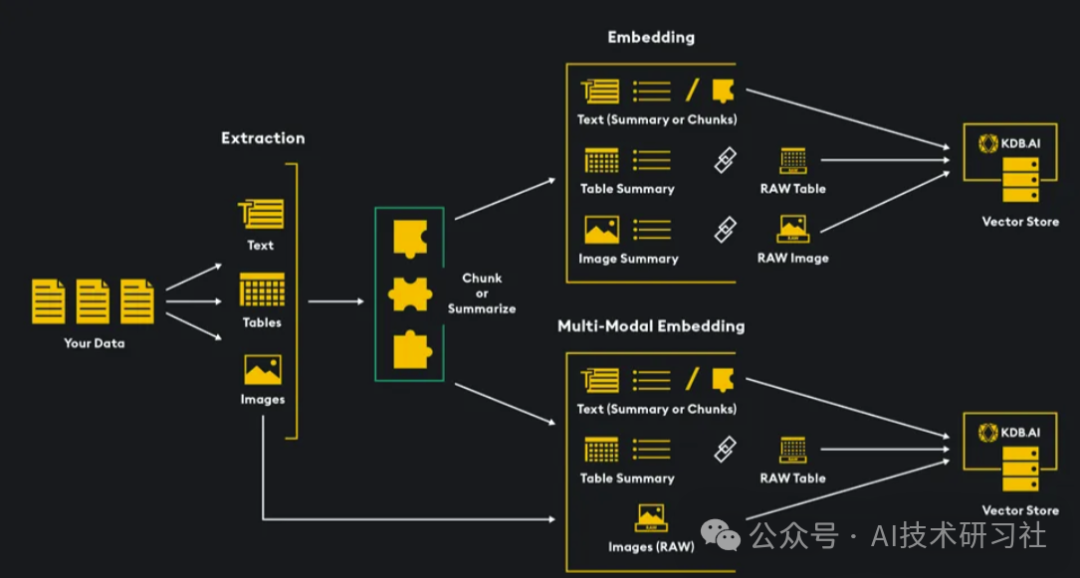
我们的目标是将图像和文本嵌入到统一的向量空间中,从而实现跨两种媒体类型的同时向量搜索。为此,我们通过对数据进行嵌入(将数据转换为数字向量表示)并将其存储在 KDB.AI 向量数据库中来完成。这一过程有多种实现方式,今天我们将探讨两种主要方法:
- 使用多模态嵌入模型同时嵌入文本和图像。
- 使用多模态 LLM 对图像进行摘要处理,然后将摘要和文本数据传递给文本嵌入模型(如 OpenAI 的“text-embedding-3-small”)。
在本文的结尾,我们将结合理论与代码,基于动物图像及描述的数据集,详细介绍如何实现上述两种多模态检索方法。最终,该系统将能够处理用户查询,返回相关图像和文本数据,为多模态检索增强生成(RAG)应用程序提供强大的检索机制。
方法 1:使用多模态嵌入模型嵌入文本和图像
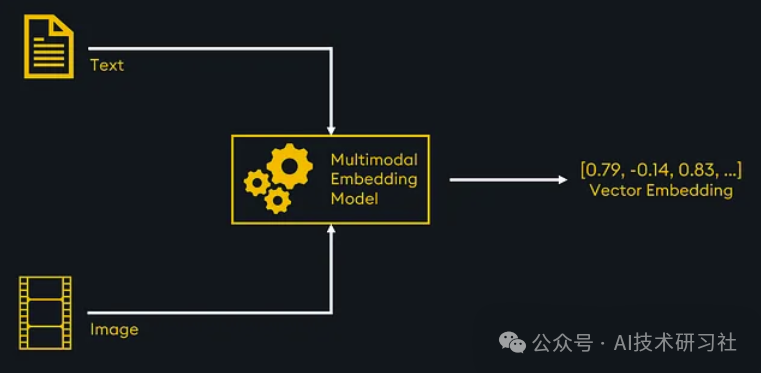
多模态嵌入模型能够将文本、图像以及其他多种数据类型统一映射到一个共享的向量空间中,从而实现跨模态的向量相似性搜索。这一能力极大地增强了 KDB.AI 矢量数据库在处理多模态数据时的灵活性与效率。
通过检索到的嵌入,系统可以进一步支持多模态大型语言模型(LLM),帮助其生成更精准、上下文相关的响应,完整实现检索增强生成(RAG)管道的闭环。
我们将探索的多模态嵌入模型称为“ ImageBind ”,由 Meta 开发。 ImageBind 可以嵌入多种数据模式,包括文本、图像、视频、音频、深度、热量和惯性测量单元 (IMU),其中包括陀螺仪和加速计数据。
ImageBind GitHub Repository: https://github.com/facebookresearch/ImageBindImageBind GitHub 存储库: https://github.com/facebookresearch/ImageBind
让我们通过几个代码片段来概述 ImageBind 的使用。请在此处查看完整的笔记本。
首先,我们克隆 ImageBind,导入必要的包,并实例化 ImageBind 模型,以便稍后在代码中使用它:
git clone https://github.com/facebookresearch/ImageBind
import pandas as pd
import os
import PIL
from PIL import Image
import torch
from imagebind import data
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
os.chdir('./ImageBind')
!pip install .
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate the ImageBind model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
接下来,我们需要定义函数来帮助我们在数据上使用 ImageBind、提取多模式嵌入并从文本文件中读取文本:
#Helper functions to create embeddings
def getEmbeddingVector(inputs):
with torch.no_grad():
embedding = model(inputs)
for key, value in embedding.items():
vec = value.reshape(-1)
vec = vec.numpy()
return(vec)
def dataToEmbedding(dataIn,dtype):
if dtype == 'image':
data_path = [dataIn]
inputs = {
ModalityType.VISION: data.load_and_transform_vision_data(data_path, device)
}
elif dtype == 'text':
txt = [dataIn]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(txt, device)
}
vec = getEmbeddingVector(inputs)
return(vec)
# Helper function to read the text from a file
def read_text_from_file(filename):
try:
# Open the file in read mode ('r')
with open(filename, 'r') as file:
# Read the contents of the file into a string
text = file.read()
return text
except IOError as e:
# Handle any I/O errors
print(f"An error occurred: {e}")
return None
现在让我们设置一个空数据框来存储文件路径、数据类型和嵌入。我们还将获得将存储在矢量数据库中的图像和文本的路径列表:
#Define a dataframe to put our embeddings and metadata into
#this will later be used to load our vector database
columns = ['path','media_type','embeddings']
df = pd.DataFrame(columns=columns)
#Get a list of paths for images, text
images = os.listdir("./data/images")
texts = os.listdir("./data/text")
是时候循环遍历我们的图像和文本,并通过我们的辅助函数发送它们,该函数将使用 ImageBind 嵌入数据:
#loop through images, append a row in the dataframe containing each
# image's path, media_type (image), and embeddings
for image in images:
path = "./data/images/" + image
media_type = "image"
embedding = dataToEmbedding(path,media_type)
new_row = {'path': path,
'media_type':media_type,
'embeddings':embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
#loop through texts, append a row in the dataframe containing each
# text's path, media_type (text), and embeddings
for text in texts:
path = "../data/text/" + text
media_type = "text"
txt_file = read_text_from_file(path)
embedding = dataToEmbedding(txt_file,media_type)
new_row = {'path': path,
'media_type':media_type,
'embeddings':embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
我们现在有了一个数据框,其中包含所有数据的路径、媒体类型和多模式嵌入!
接下来,我们将建立 KDB.AI 矢量数据库。您可以在KDB.AI免费注册,并获取端点和 API 密钥。
# vector DB imports
import os
from getpass import getpass
import kdbai_client as kdbai
import time
#Set up KDB.AI endpoing and API key
#Go to kdb.ai to sign up for free if you don't already have an account!
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
#connect to KDB.AI
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
要将数据提取到 KDB.AI 矢量数据库中,我们需要设置表模式。在我们的例子中,我们将有一个文件路径、media_type 和嵌入的列。我们还定义了一个将应用于架构中嵌入列的索引。
嵌入将具有 1024 维,因为这是 ImageBind 输出的维数。相似度搜索方法被定义为“cs”或余弦相似度,索引只是简单的平面索引。这些参数中的每一个都可以根据您的用例进行自定义。
# Connect to the default database in KDB.AI
db = session.database('default')
#Set up a table with three columns, path, media_type, and embeddings
table_schema = [
{"name": "path", "type": "str"},
{"name": "media_type", "type": "str"},
{
"name": "embeddings",
"type": "float64s",
},
]
# Define the index
indexes = [
{
'type': 'flat',
'name': 'flat_index',
'column': 'embeddings',
'params': {'dims': 1024, 'metric': "CS"},
},
]
确保不存在同名表,然后创建一个名为“multi_modal_demo”的表:
# First ensure the table does not already exist
try:
db.table("multi_modal_ImageBind").drop()
except kdbai.KDBAIException:
pass
#Create the table called "multi_modal_demo"
table = db.create_table(table="multi_modal_ImageBind", schema=table_schema, indexes=indexes)
将我们的数据加载到 KDB.AI 表中!
#Insert the data into the table, split into 2000 row batches
from tqdm import tqdm
n = 2000 # chunk row size
for i in tqdm(range(0, df.shape[0], n)):
table.insert(df[i:i+n].reset_index(drop=True))
我们已将多模式数据加载到矢量数据库中。这意味着文本和图像嵌入都存储在同一向量空间内。现在我们可以执行多模式相似性搜索。
我们将定义三个辅助函数。一种将自然语言查询转换为嵌入式查询向量。另一个是从文件中读取文本。最后,帮助我们清楚地查看相似性搜索的结果。
# Helper function to create a query vector from a natural language query
def QuerytoEmbedding(text):
text = [text]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text, device)
}
vec = getEmbeddingVector(inputs)
return(vec)
# Helper function to view the results of our similarity search
def viewResults(results):
for index, row in results[0].iterrows():
if row[1] == 'image':
image = Image.open(row[0])
display(image)
elif row[1] == 'text':
text = read_text_from_file(row[0])
print(text)
# Multimodal search function, identifies most relevant images and text within the vector database
def mm_search(query):
image_results = table.search(vectors={"flat_index":query}, n=2, filter=[("like", "media_type", "image")])
text_results = table.search(vectors={"flat_index":query}, n=1, filter=[("like", "media_type", "text")])
results = [pd.concat([image_results[0], text_results[0]], ignore_index=True)]
viewResults(results)
return(results)
让我们进行相似性搜索来检索与查询最相关的数据:
#Create a query vector to do similarity search against
query_vector = [QuerytoEmbedding("brown animal with antlers").tolist()]
#Execute a multimodal similarity search
results = mm_search(query_vector)
结果!!我们检索了三个最相关的嵌入。事实证明它效果很好,返回了鹿的文字描述和两张鹿角的图片:

方法 2:使用多模态LLM来总结图像并嵌入文本摘要
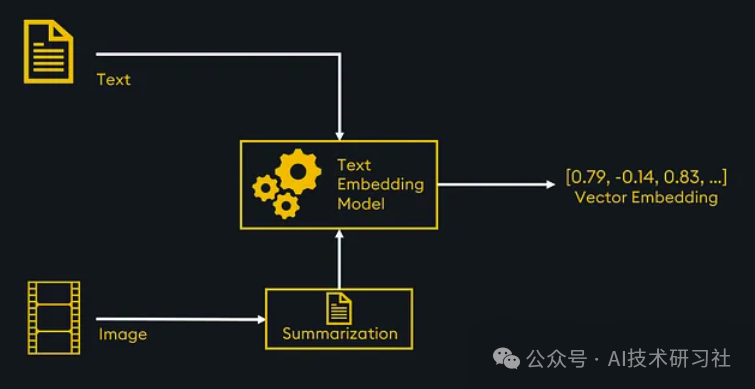
实现多模式检索和 RAG 的另一种方法是将所有数据转换为单一模式:文本。这意味着您只需使用文本嵌入模型即可将所有数据存储在同一向量空间中。这会带来额外的成本,即手动或通过LLM初步汇总其他类型的数据(例如图像、视频或音频)。
通过嵌入并存储在矢量数据库中的文本和图像摘要,可以实现多模式相似性搜索。当检索到最相关的嵌入时,我们可以将它们传递给 RAG 的LLM 。
首先,我们需要一种总结图像的方法。解决此问题的一种方法是以“base64”编码对图像进行编码,然后将该编码发送到LLM例如“gpt-4-vision-preview”。
import base64
# Helper function to convert a file to base64 representation
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Takes in a base64 encoded image and prompt (requesting an image summary)
# Returns a response from the LLM (image summary)
def image_summarize(img_base64,prompt):
''' Image summary '''
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img_base64}",
},
},
],
}
],
max_tokens=150,
)
content = response.choices[0].message.content
return content
要嵌入文本,无论是来自文件还是来自LLM生成的摘要,都可以使用“text-embedding-3-small”等嵌入模型:
def TexttoEmbedding(text):
embeddings = openai.Embedding.create(
input=text,
model="text-embedding-3-small"
)
embedding = embeddings["data"][0]["embedding"]
return(embedding)
现在让我们设置一个空数据框来存储文件路径、数据类型、原始文本和嵌入内容。我们还将获得将存储在矢量数据库中的图像和文本的路径列表:
#Define a dataframe to put our embeddings and metadata into
#this will later be used to load our vector database
columns = ['path','media_type','text','embeddings']
df = pd.DataFrame(columns=columns)
#Get a list of paths for images, text
images = os.listdir("./data/images")
texts = os.listdir("./data/text")
循环遍历文本和图像文件,通过我们的辅助函数发送它们以进行嵌入。为每个文本和图像文件添加一个新行到数据框,并包含相应的路径、media_type、文本(或摘要)和嵌入:
# Embed texts, store relevant info in data frame
for text in texts:
path = "./data/text/" + text
media_type = "text"
text1 = read_text_from_file(path)
embedding = TexttoEmbedding(text1)
new_row = {'path': path,
'media_type':'text',
'text' : text1,
'embeddings': embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
# Encode images with base64 encoding,
# Get text summary for encoded images,
# Embed summary, store relevant info in data frame
for image in images:
path = "./data/images/" + image
media_type = "images"
base64_image = encode_image(path)
prompt = "Describe the image in detail."
summarization = image_summarize(base64_image,prompt)
embedding = TexttoEmbedding(summarization)
new_row = {'path': path,
'media_type':'image',
'text' : summarization,
'embeddings': embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
我们现在有了一个数据框,其中包含所有数据的路径、媒体类型、文本和嵌入!现在,我们将设置矢量数据库(请参阅方法 1)并创建一个具有以下架构的表:
database = session.database("default")
# Define table schema for our table with columns for path, media_type, text, and embeddings
table_schema = [
{"name": "path", "type": "str"},
{"name": "media_type", "type": "str"},
{"name": "text", "type": "str"},
{"name": "embeddings", "type": "float64s"}
]
# Define the index that will be applied to the embeddings column defined above
indexes = [
{
"name": "flat_index",
"column": "embeddings",
"type": "flat",
"params": {"dims": 1536, "metric": "CS"}
}
]
# First ensure the table does not already exist
try:
database.table("multi_modal_demo").drop()
except kdbai.KDBAIException:
pass
# Create the table called "multi_modal_demo"
table = database.create_table("multi_modal_demo", schema=table_schema, indexes=indexes)
让我们填充我们的表:
#Insert the data into the table, split into 2000 row batches
from tqdm import tqdm
n = 2000 # chunk row size
for i in tqdm(range(0, df.shape[0], n)):
table.insert(df[i:i+n].reset_index(drop=True))
我们的矢量数据库已经加载了所有数据,我们可以尝试相似性搜索:
query_vector = [TexttoEmbedding("animals with antlers")]
results = table.search({index_name: query_vector}, n=3)
viewResults(results)

这些方法中的每一种都可以充当多模式 RAG 管道中的检索阶段。最相关的数据(文本或图像)可以从矢量搜索中返回,然后注入到提示中发送给您选择的LLM 。如果使用多模式LLM ,文本和图像都可以用来增强提示。如果使用基于文本的LLM ,只需按原样传递文本和图像的文本描述即可。
下面的架构显示了 RAG 的高级流程:
-
数据预处理
-
摄取数据,将其分块或汇总后生成嵌入向量。
-
嵌入存储
-
将生成的嵌入向量存储在向量数据库中,供后续检索使用。
-
语义搜索
-
用户查询被嵌入为向量,并与向量数据库中的数据进行语义相似性搜索。
-
数据检索
-
从数据库中检索与查询最相关的数据。在多模态 RAG 场景下,这些数据可能包含文本和图像。
-
数据传递
-
检索到的相关数据与用户查询一并传递给大型语言模型(LLM)。
-
生成响应
-
LLM 利用检索到的数据作为上下文,为用户生成针对性且精准的回答。
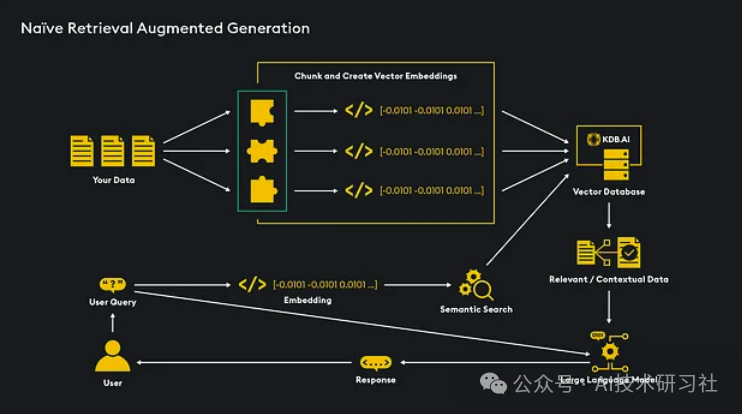
使用本文描述的检索方法后,您可以将检索到的数据以文本或图像的形式传递给LLM进行生成,以完成RAG过程。在下面的示例中,我们传入检索到的文本数据列表和用户提示 - 该函数构建一个查询并将其发送到LLM ,然后返回生成的响应。
对于接受文本和图像作为输入的多模式LLM生成,请参阅下面使用 Google 的 Gemini Vision Pro 模型的代码片段:
import google.generativeai as genai
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
# Use Gemini Pro Vision model to handle multimodal inputs
vision_model = genai.GenerativeModel('gemini-1.5-flash')
# Generate a response by passing in a list containing:
# the user prompt and retieved text & image data
response = vision_model.generate_content(retrieved_data_for_RAG)
print(response.text)
对于基于文本的LLM生成,我们将图像摘要和文本直接传递到LLM中,请参阅下面使用“OpenAI 的 gpt-4-turbo-preview”模型的代码片段:
# Helper function to execute RAG, we pass in a list of retrieved data, and the prompt
# The function returns the LLM's response
def RAG(retrieved_data,prompt):
messages = ""
messages += prompt + "\n"
if retrieved_data:
for data in retrieved_data:
messages += data + "\n"
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": messages},
],
}
],
max_tokens=300,
)
content = response.choices[0].message.content
return content
将多种数据类型(如文本和图像)集成到 LLMs 中,显著提升了其生成全面响应的能力。这种集成使人工智能能够更好地理解复杂查询,并提供更符合上下文的答案。本文着重探讨了 KDB.AI 等矢量数据库在多模态检索系统中的核心作用,通过耦合相关多模态数据与 RAG 应用程序中的 LLMs,实现了更强大的生成能力。
尽管我们今天的重点是图像和文本,但未来可以整合更多数据类型(如音频和视频),进一步扩展人工智能的适用场景,为新型 AI 应用开辟更广阔的可能性。
多模态 RAG 的理念不仅是技术进步的体现,更是在人工智能领域中模仿类人感知的重要尝试。那么,您如何看待多模态 RAG 的未来发展?有哪些应用场景是您特别期待的?欢迎一起讨论!
参考:https://medium.com/kx-systems/guide-to-multimodal-rag-for-images-and-text-10dab36e3117
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】



















 4848
4848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









