








知识图谱(KG)或任何图都包括节点和边,其中每个节点表示一个概念,每个边表示一对概念之间的关系。本文介绍一种将任何文本语料库转换为知识图谱的技术,本文演示的知识图谱可以替换其他专业知识图谱。
一、知识图谱
知识图谱表示了任意两个实体之间的关系,在这个结构中,节点表示着诸如人、地点或事件之类的实体,而边表示这些实体之间的连接。知识图谱还包含了第三个元素,通常被称为谓词或边缘标签,它阐明了关系的性质。
知识图谱就像智能网络一样,显示了现实世界中的事物是如何连接的。它存储在图形数据库中,并可视化为图形结构,形成我们所说的“知识图”。用户可以像实时聊天机器人对话一样使用graph数据进行聊天。
知识图谱有多种用途。通过应用图算法,我们可以计算任何节点的中心度,从而深入了解一个概念在一系列工作中的重要性。分析连接和断开的概念集,或确定概念群落,可以提供对主题的全面理解。知识图谱使我们能够揭示看似不相关的概念之间的联系。
此外,知识图谱可以用于图检索增强生成(GRAG或GAG),并促进与文档的对话交互。与具有固有局限性的传统版本的RAG相比,这种方法通常产生优越的结果。例如,依赖简单的语义相似性搜索进行上下文检索可能并不总是有效的,尤其是当查询缺乏足够的上下文时,或者当相关信息分散在庞大的文本语料库中时。
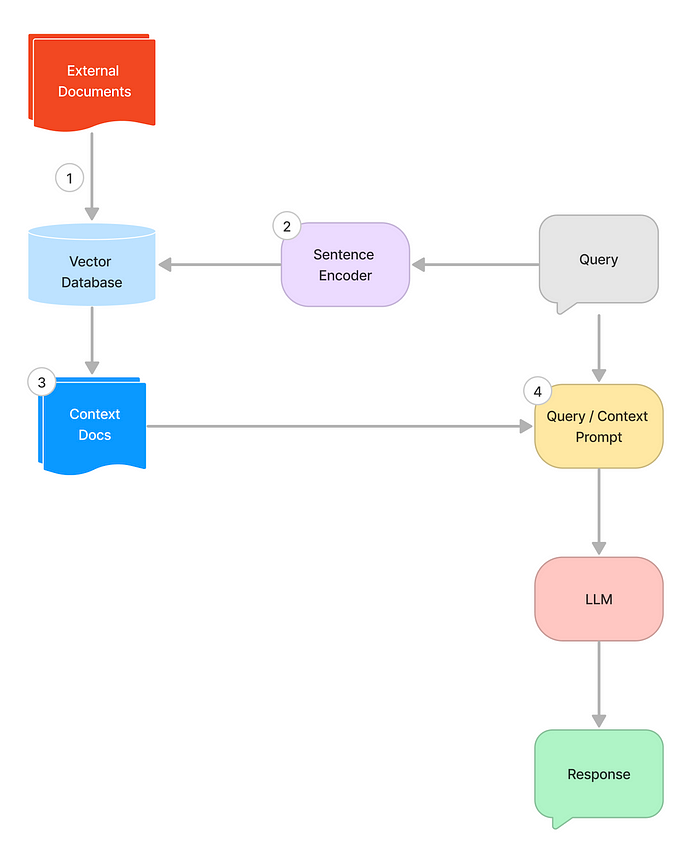
二、高级RAG体系结构
-
使用矢量数据库编码文档;
-
使用sentence transformer将查询转换为向量;
-
基于输入的查询从矢量数据库中检索相关上下文;
-
利用查询和检索到的上下文来激发LLM。
三、RAG的局限性
RAG的一个主要缺点是它很难对复杂而细微差别的查询提供精确的响应。这种限制源于几个因素:
理解用户意图:RAG系统可能很难完全掌握用户查询背后的确切意图,这是向LLM提供准确信息的关键方面。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











