



未来,每个产品经理都是 AI 产品经理,而每个 AI 产品经理都必须懂 RAG。
所谓RAG(Retrieval - Augmented Generation),即信息检索(Retrieval)+内容生成(Generation)。
图片来源:百度
通过 RAG,可以让大模型从指定的内部知识库“检索”准确的内容,再根据准确的内容“生成”回答内容,从而有效避免幻觉。
比如,如果直接让大模型进行医疗诊断,由于大模型的本质是概率模型,因此它会提供大量错误或者不相关的信息。
有了RAG,大模型就可以从海量的医学文献、病例库中直接检索与患者病症相关的知识,再生成诊断建议供医生参考,从而提高内容的准确性。
接下来给大家介绍 RAG 的 7 个核心概念,看完以后,你会对 RAG 有更深入的认识。
1、向量数据库
向量数据库是 RAG 最重要的基础设施之一。
传统数据库的内容查询主要依赖“关键词匹配”,对查询的精确度要求很高。
比如,如果你查询“如何提高工作效率”,而数据库只有“时间管理技巧”内容,那么就无法搜索出任何内容。
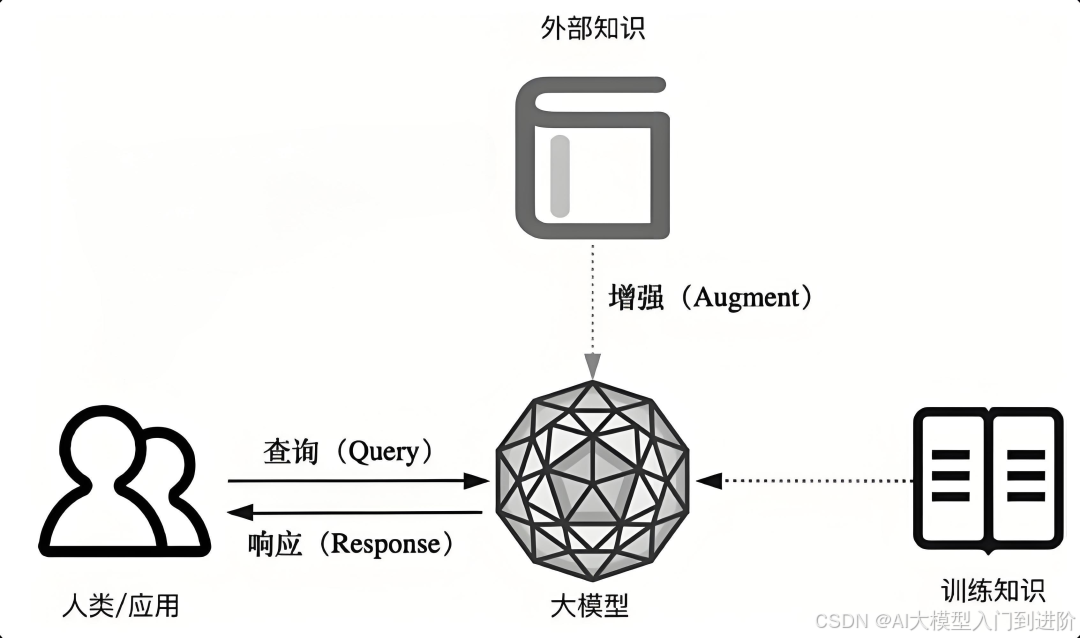
而向量数据库就可以有效解决这个问题,它会把各种知识都转换成一组组数字(向量),这些数字能代表知识的内容和特点,
当你在 RAG 系统中输入查找信息时,它会把输入信息也转换成一组数字(向量),然后在数据库中找出最相关的知识,从而实现“语义检索”。
图片来源:百度
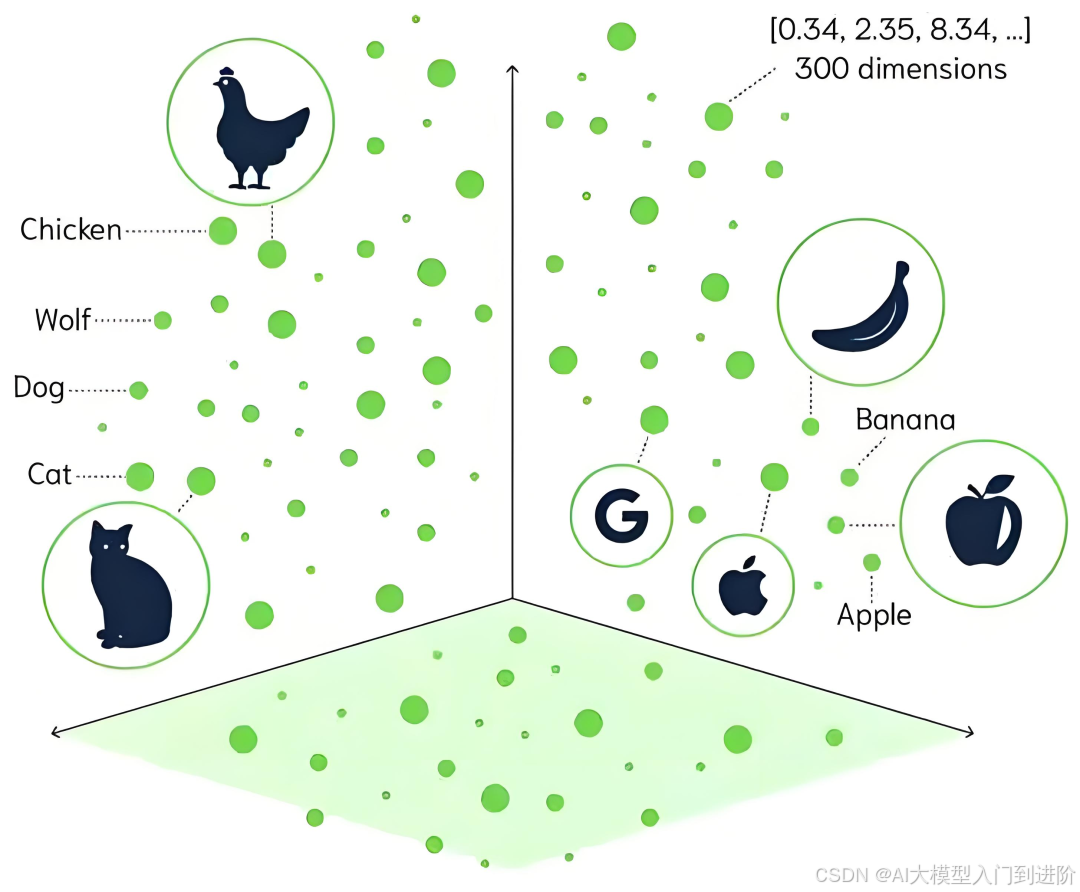
比如,下面的每个知识都转化为了一个 3 维向量(实际应用中可能把一个知识转化为几十甚至几千维的向量):
时间管理:[0.12,0.23,0.46]
工作地点:[0.92,0.82,0.65]
考勤制度:[0.83,0.93,0.78]
当用户查询“工作效率”,向量数据库就可以把“工作效率”转化为向量: [0.12,0.23,0.53]。
显然它和“时间管理”的向量 [0.12,0.23,0.46] 相似度很高——从业务上来说,是因为“时间管理”是提高“工作效率”的一种有效方法,这就导致两者的语义高度相关。
其实,这就是“语义检索”的过程。
在传统客服系统中,由于依赖“关键词匹配”,在面对复杂咨询时,就很难给出用户想要的答案。
而 AI 客服使用向量数据库,当用户咨询时,可以通过 “语义检索”快速找到最相关的答案,从而提升用户体验和满意度。
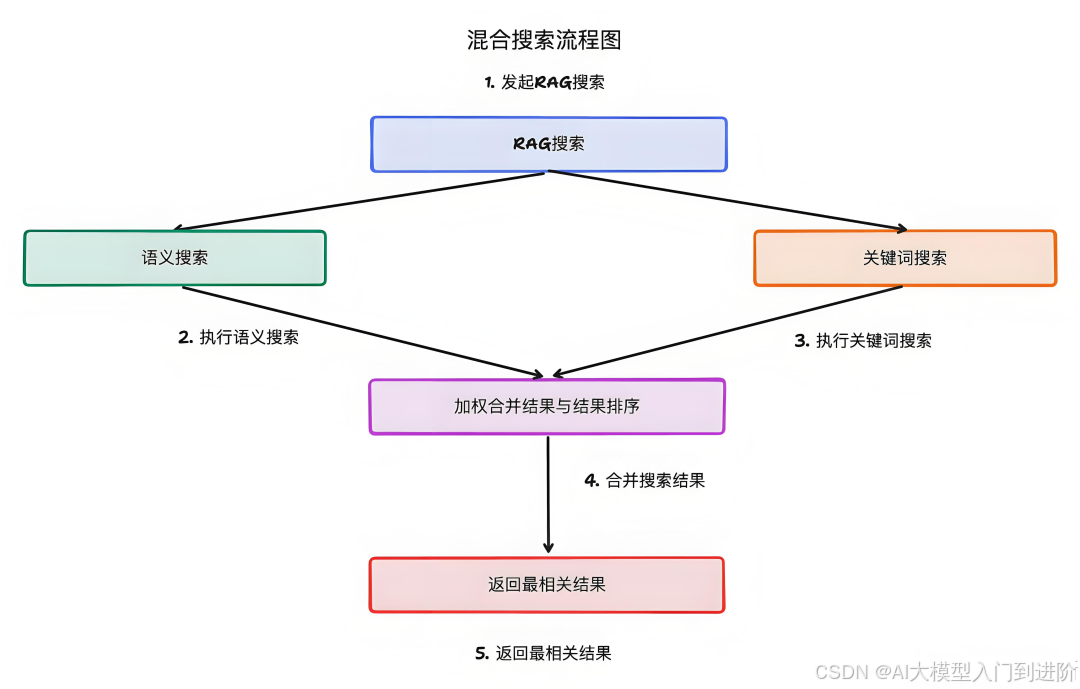
2、混合检索
图片来源:优快云@智兔唯新
基于向量知识库的语义检索虽然很好,但是也存在 2 个问题:
首先是面对超大数据量,语义检索的速度不如传统的关键词检索。
其次是对于一些需要精确匹配的场景,关键词匹配更有优势。比如在法律文件检索中,法律条文、案例等对措辞的精准要求就很高。
因此,在很多场景下,RAG 会同时使用关键词检索和语义检索,从而尽可能的提升检索体验。
比如,在电商平台上,用户搜索“无线蓝牙耳机”。纯语义检索可能会推荐一些带有“无线”或“蓝牙”字样的普通耳机,但混合检索除了语义匹配,还会根据关键词“无线蓝牙”进行精确匹配,确保优先推荐符合“无线蓝牙耳机”这一完整要求的产品。
3、分块、嵌入与索引
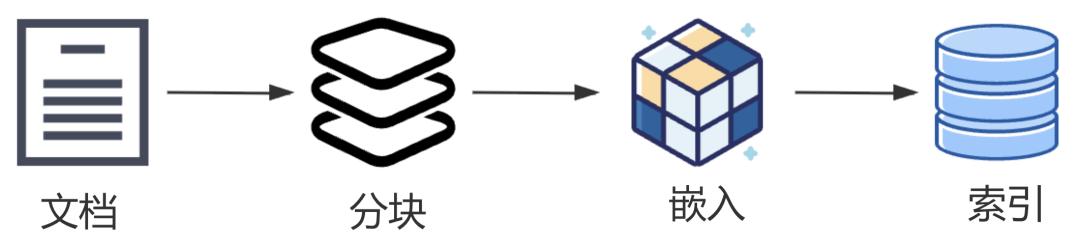
RAG在存储知识时,为了更高效地管理和检索,通常会将原始文档按照一定的规则(如固定长度、语义单元等)分块。
就如同一本很长的小说,如果把它切成一个个章节或者更小的段落块,那么在查找某个故事情节时就更方便快捷。
分块以后,还需要把每一个块转化为向量,从而存储到向量数据库,这就是嵌入。
嵌入以后,还可以把向量存储到一个高效的检索结构中,以便快速进行相似性计算和检索,这就是索引。
比如,某法律咨询平台为用户提供在线法律咨询服务。
由于法律领域的知识库通常非常庞大且复杂,包含大量的文本信息,如法律条文、司法解释、案例判决书等。
在构建知识库时,就可以将法律条文、案例等长文本分割成多个小块,同时,利用索引结构记录每个小块的向量位置,以便快速检索。
这样,当用户输入法律问题,如“合同违约的赔偿标准是什么”,RAG 就可以从数据库中快速找到最相关的多个小块,并通过上下文融合来生成更为准确和完整的答案。
4、重排序(re-rank)
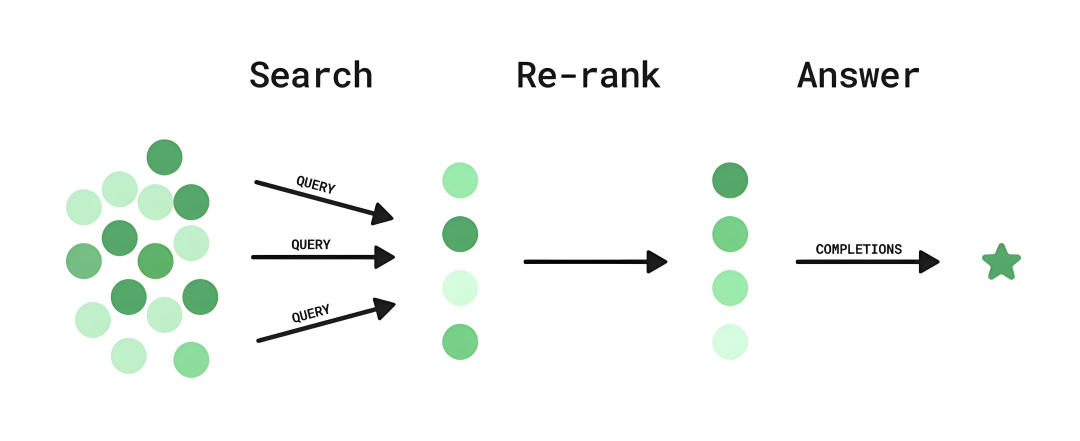
图片来源:公众号:AI大模型应用实践
当 RAG 从数据库中检索出多个内容时,需要选取相关性最大的内容喂给大模型,从而提高大模型的回答质量。
所谓重排序,是指 RAG 将初步检索出来的内容进行重新排序,其目的是将最相关的信息排在前面,从而选取出相对更为准确的内容。
打个比方,你想让 AI 搜索一批书籍,RAG 会先大致找出一批可能你想要的书籍,然后仔细评估每一本书和你需求的契合程度,把最符合你心意的书排在最前面,方便你优先查看。
重排序的应用非常广泛,比如电商平台根据用户需求初步筛选出一批商品后,就会通过“重排序”,根据用户的实时行为、偏好历史等,对推荐商品进行重新排序,把更符合用户当下需求的商品排在前面,提高推荐的准确性和实用性。
5、上下文融合
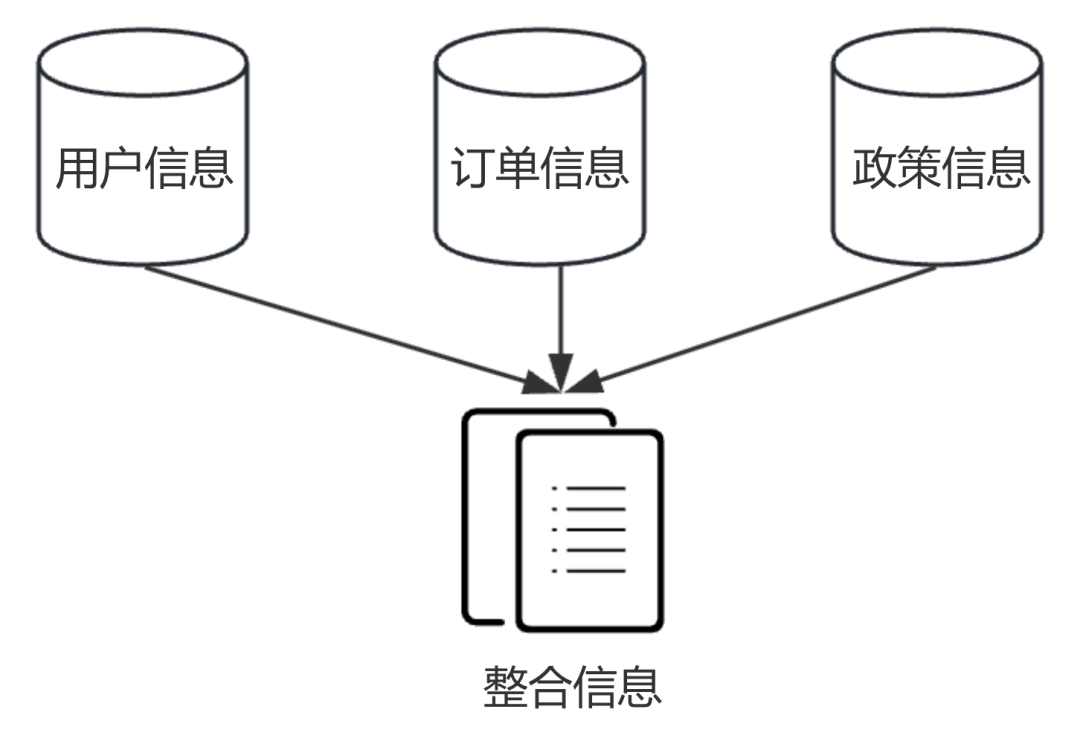
上下文融合是指 RAG 将从多个来源检索到的知识进行整合,以便为大模型提供更全面、连贯的输入内容,这样大模型的回答才能条理清晰、内容完整。
比如,在智能客服场景中,用户咨询:“我刚收到的商品有点瑕疵,我可以申请退货吗?”
要回答好这个问题,RAG 就需要从多个来源检索信息,比如用户的订单信息、退货政策等,再把这些内容整理成统一的内容,以便大模型能够基于内容生成高质量的回答。
6、准确率和召回率

准确率(Precision)是指在 RAG 检索到的内容中,与用户问题真正相关的内容的比例。
例如,在一个问答系统中,检索到 10 条知识,其中有 8 条与用户问题高度相关,那么准确率就是 80%。
准确率是衡量检索质量最重要的指标之一。
比如,智能客服在回答用户问题时,如果准确率不高,就会提供大量不相关或错误的答案,影响用户体验。
但是,只有高的准确率还不够,还必须有高的召回率。
所谓召回率(Recall),是指与用户问题相关的所有知识中,被成功检索到的比例。
例如,知识库中有 20 条与用户问题相关的知识,检索到 12 条,那么召回率就是 60%。
在实际应用场景中,召回率和准确率往往会成为跷跷板。比如如果过度追求高召回率,可能会导致检索结果中包含大量不相关的信息,影响准确率。反之亦然。
比如,在一个电商商品检索系统中,为了尽可能多地召回相关商品,降低了检索阈值,结果导致很多边缘相关甚至不相关的商品也出现在结果中。
在这种情况下,我们可以引入 F1 值进行综合评估,从而找到召回率和准确率之间的平衡点。
F1 值的计算公式是:F1= 2*(准确率*召回率)/(准确率+召回率)。
在这个公式中,当准确率或者召回率中的任何一个非常低时,F1 值也会相应的降低。
7、知识图谱
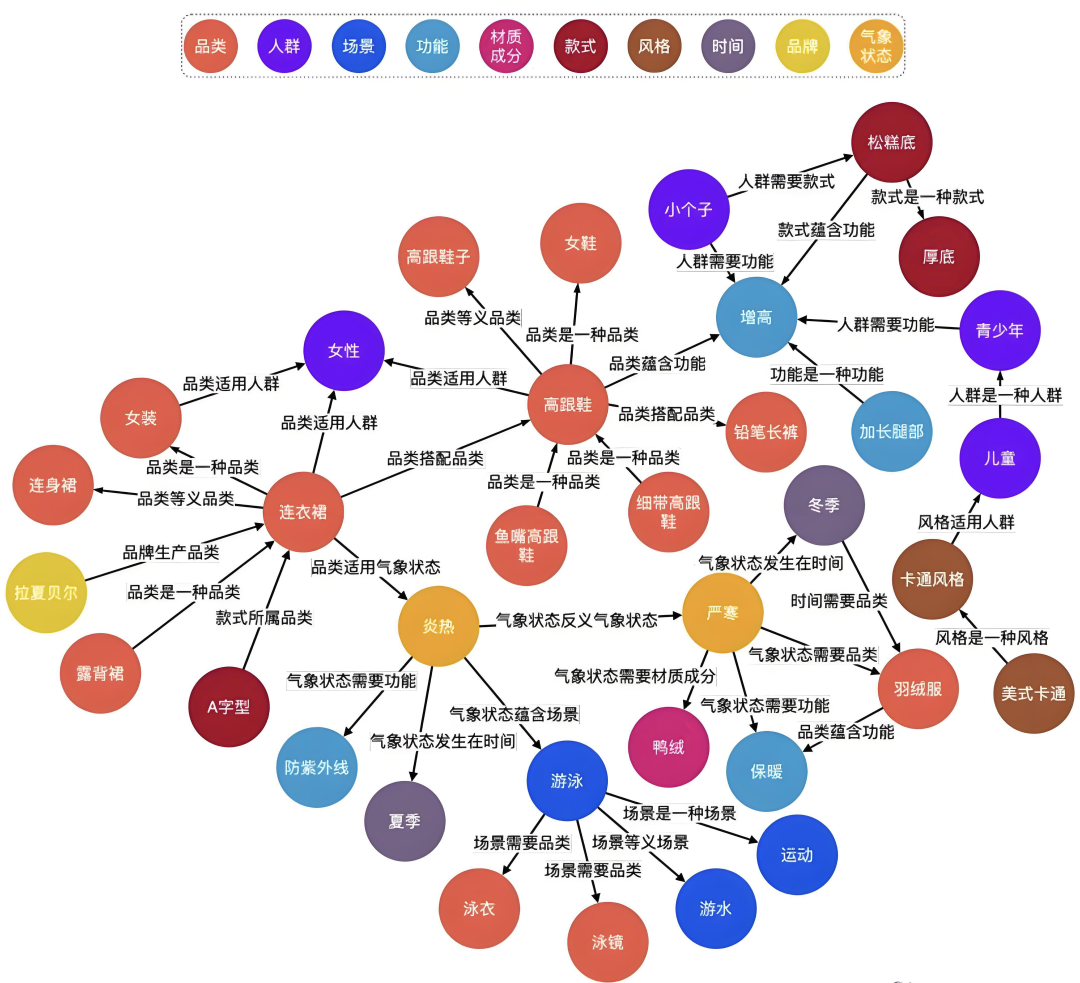
图片来源:优快云@思通数科x
知识图谱就像是一个巨大的知识网络,把各种知识当作一个个节点,并且把有关系的节点进行连接。
比如,通过知识图谱可以对菜谱知识进行管理,把各个菜谱、原材料、烹饪方法连接起来,这样,当用户询问“用鸡蛋可以做哪些菜”时,RAG 就可以通过“菜谱-原材料”的连接关系,准确找到使用“鸡蛋”的菜谱。
通过知识图谱,RAG 能够捕捉到实体间的复杂关系,还能够基于已有的实体关系进行推理和扩展,发现更多潜在的相关信息,从而大大提升准确率和召回率。
比如,一年级有 5 个班,RAG 数据库中记录了 5 个班各自的期末成绩,但是并没有存储“一年级所有同学的平均成绩”。
这就导致,当用户询问“一年级期末平均成绩是多少”时,RAG 找不到相关内容,最后给出一个错误的答案。
但是,如果我们通过知识图谱建立了“一年级”和“5 个班级”之间的实体关系,RAG 就能根据根据这个关系找到“5 个班级的期末成绩”,再通过计算给到用户一个准确的回答。
最后,一个 RAG 系统的运行可能包含以下步骤:
1、向量数据库提供知识存储的基础设施
2、对内容进行分块、嵌入和索引,以方便检索
3、再通过知识图谱建立相关实体的关系,从而提高检索和生成的准确度
4、当用户查询时,通过混合检索、知识图谱等方式检索内容
5、然后把检索出来的内容进行重排序,选出最相关的内容
6、把选出的内容进行上下文融合,提供给大模型生成回答内容
7、最后,通过 F1 值对 RAG 系统的准确率和召回率进行综合评估
以上内容,你学废了吗?、
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









