 20种RAG技术全景解析
20种RAG技术全景解析




1. Navie/Standard RAG
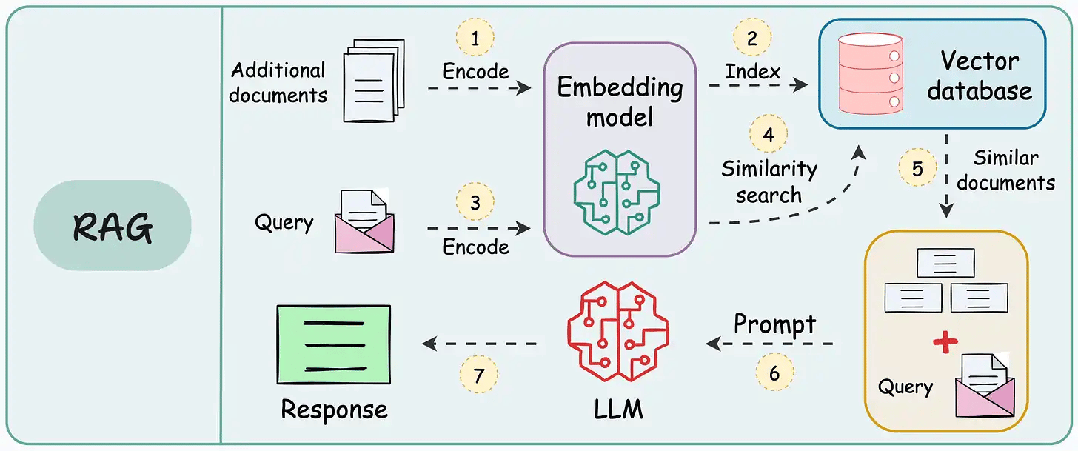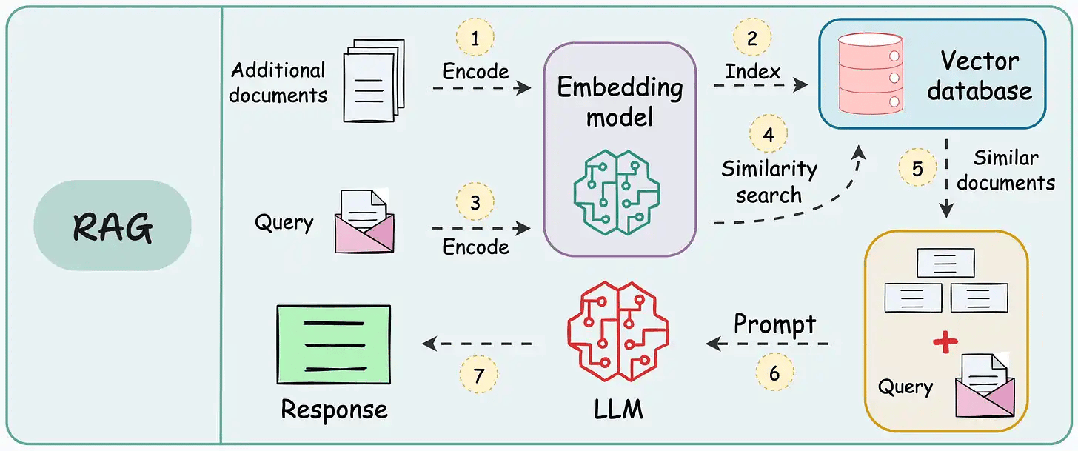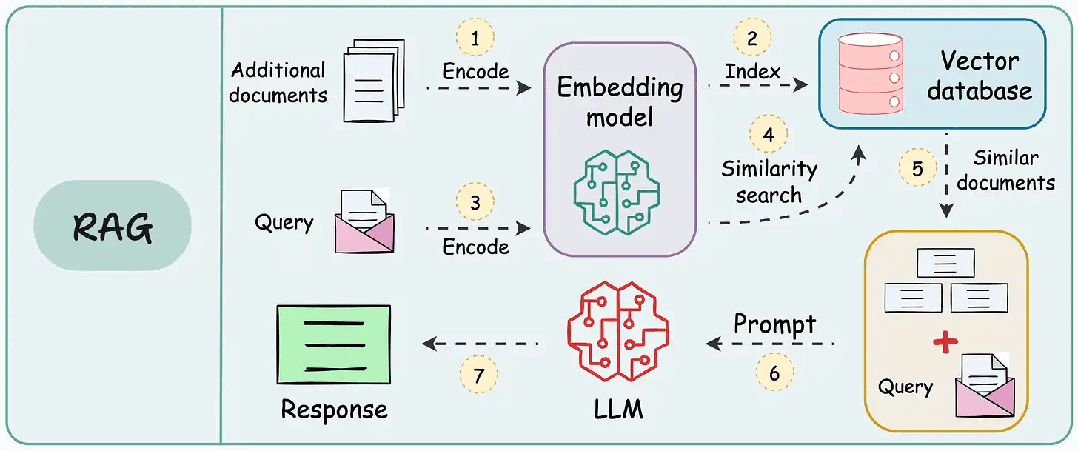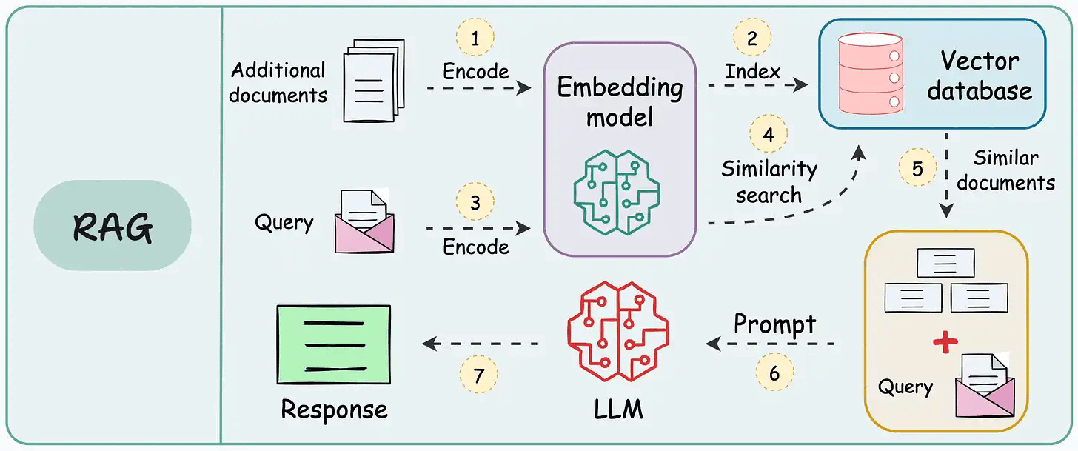
| 维度 | 说明 |
| 关键特征 | 1. 基础检索与生成集成 2. RAG-Sequence 和 RAG-Token 变体 |
| 优势 | 1. 提高准确性 2. 减少幻觉 |
| 应用场景 | 1. 通用问答系统 2. 初始RAG实现 |
| 工具/库示例 | 1. Hugging Face Transformers 2. Facebook 的 RAG 实现 3. LangChain |
2. Agentic RAG
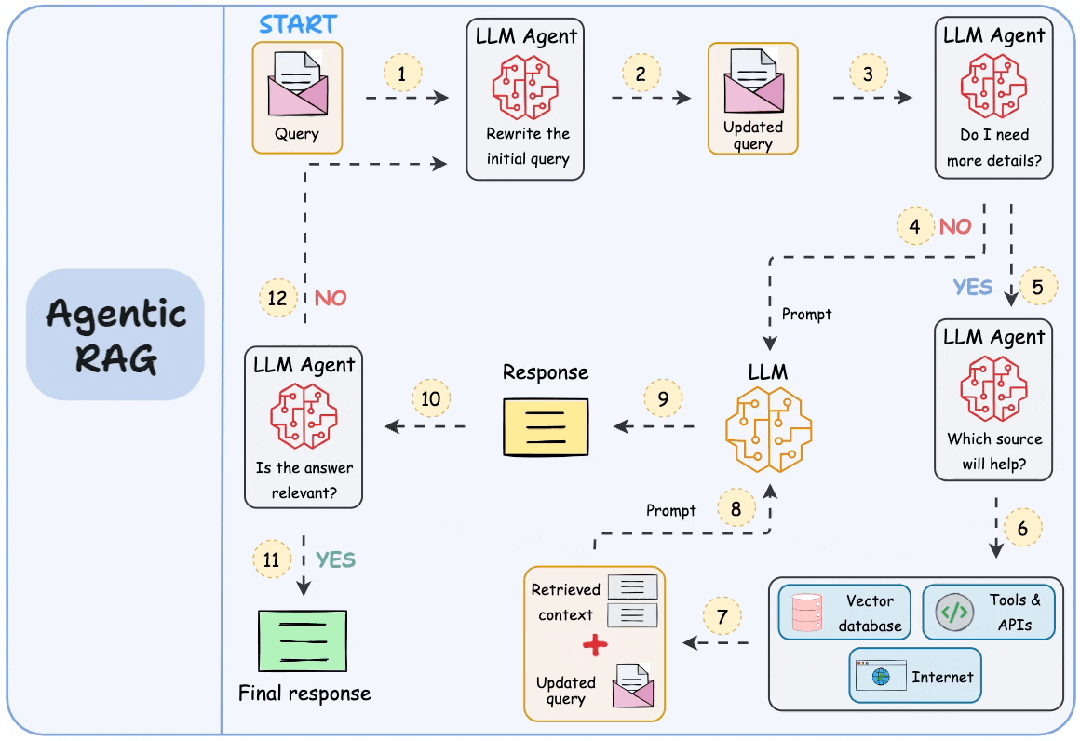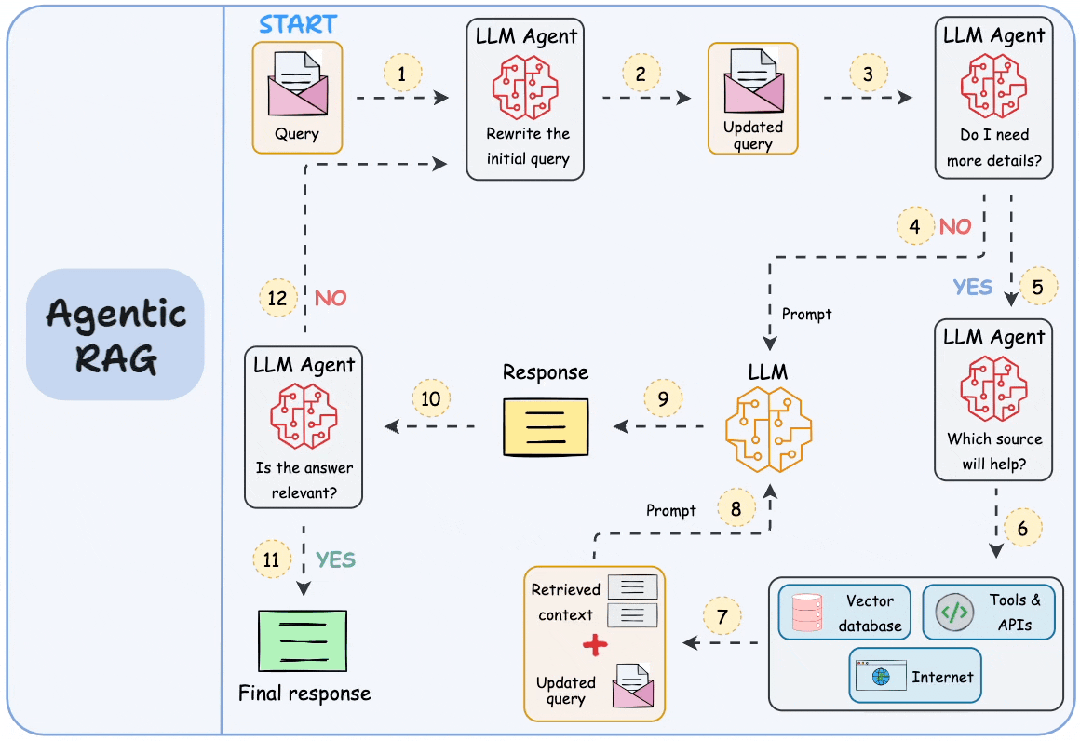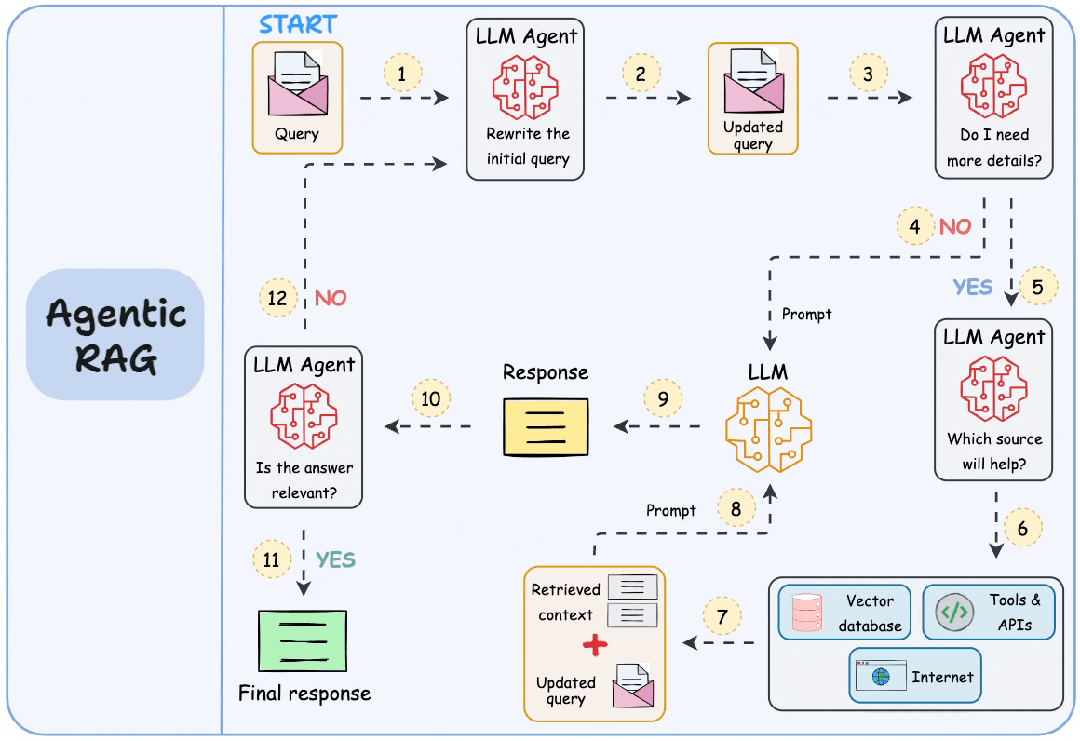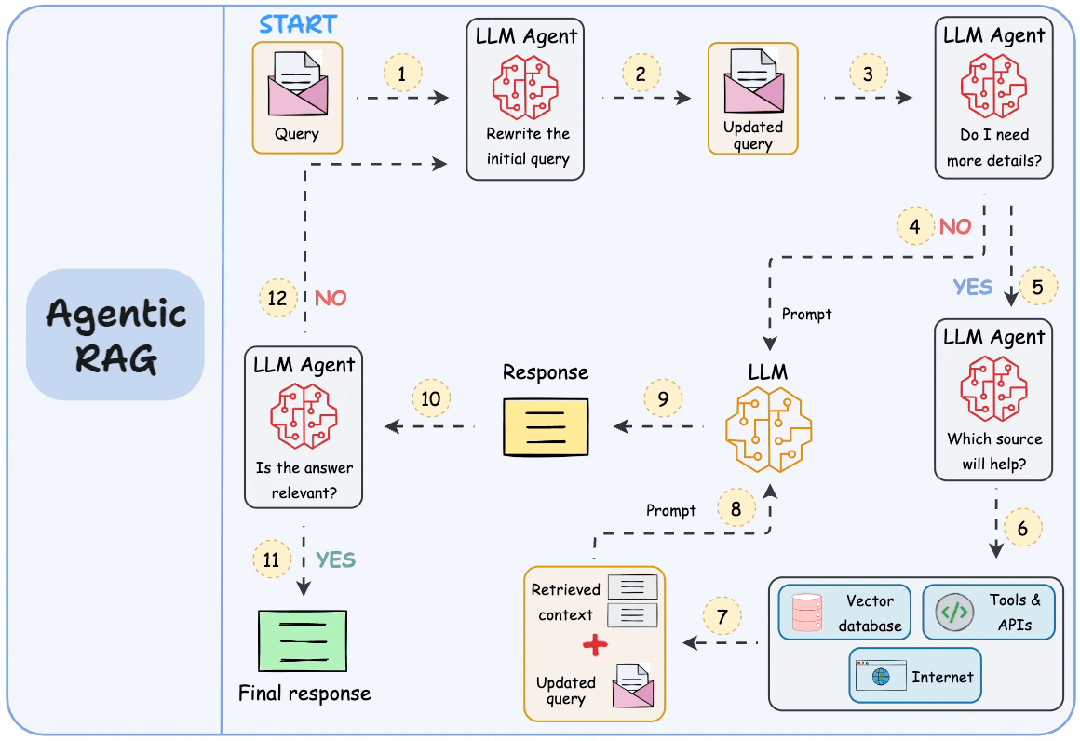
| 维度 | 说明 |
| 关键特征 | 1. 自主智能体 2. 工具使用 3. 动态检索 |
| 优势 | 1. 处理复杂任务 2. 主动式人工智能 |
| 应用场景 | 1. 个人助手 2. 需要动态交互的客服机器人 |
| 工具/库示例 | 1. LangChain Agents 2. OpenAI GPT-4 with Plugins 3. Microsoft Semantic Kernel |
3. Graph RAG
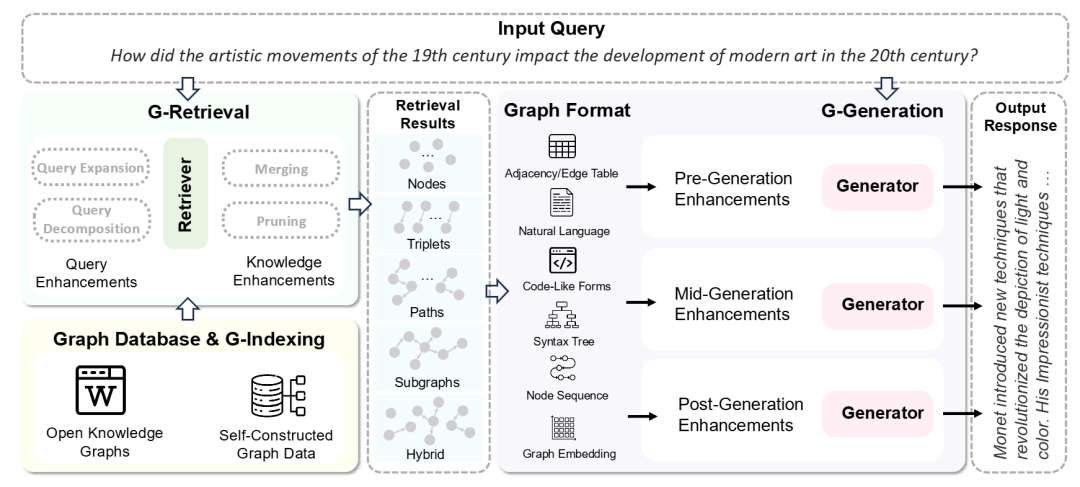
| 维度 | 说明 |
| 关键特征 | 1. 知识图谱 2. 关系推理 |
| 优势 | 1. 信息丰富 2. 上下文处理 |
| 应用场景 | 1. 医疗、法律、工程领域的专家系统 2. 语义搜索引擎 |
| 工具/库示例 | 1. Neo4j 图数据库 2. Apache Jena 3. Stardog |
4. Modular RAG
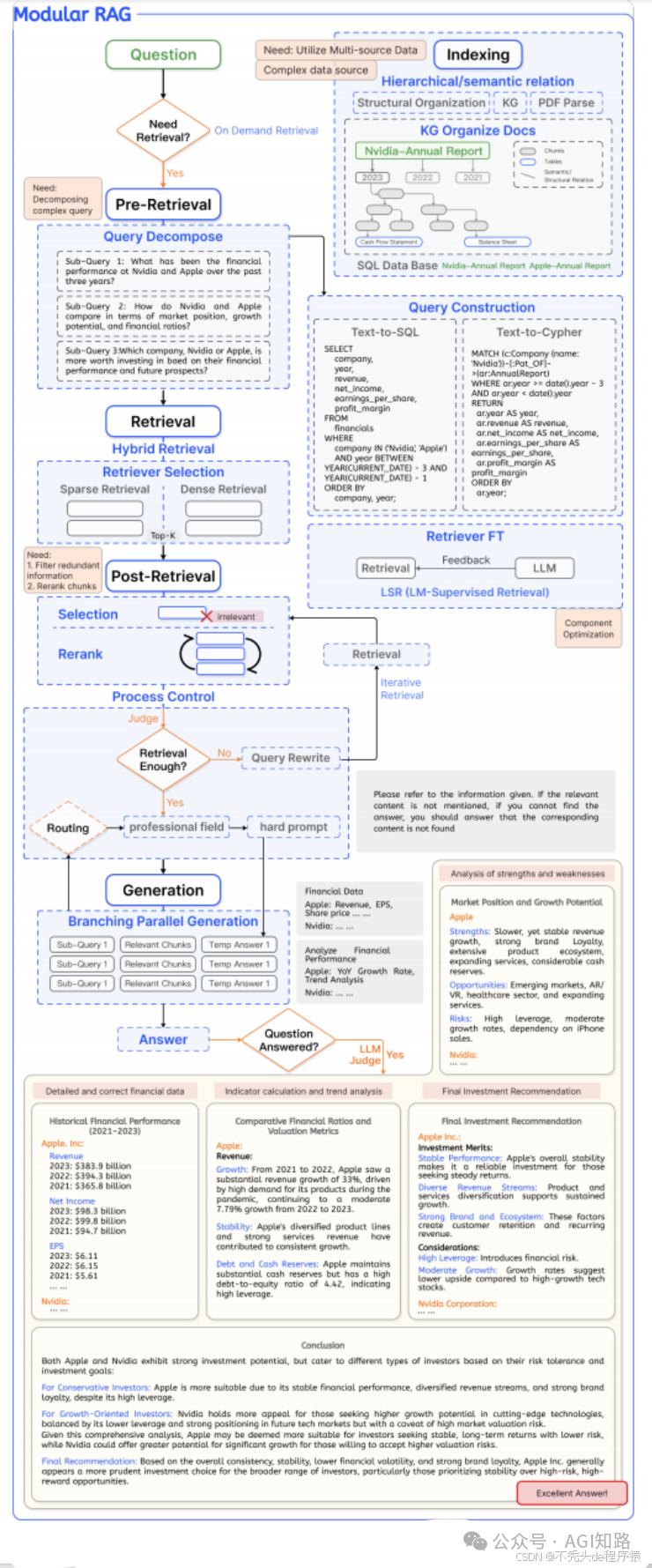
| 维度 | 说明 |
| 关键特征 | 1. 检索、推理、生成等独立模块 |
| 优势 | 1. 灵活性 2. 可扩展性 |
| 应用场景 | 1. 大型项目需要协作开发 2. 需要频繁更新的系统 |
| 工具/库示例 | 1. 微服务架构 2. Docker & Kubernetes 3. Apache Kafka |
5. Memory-Augmented RAG
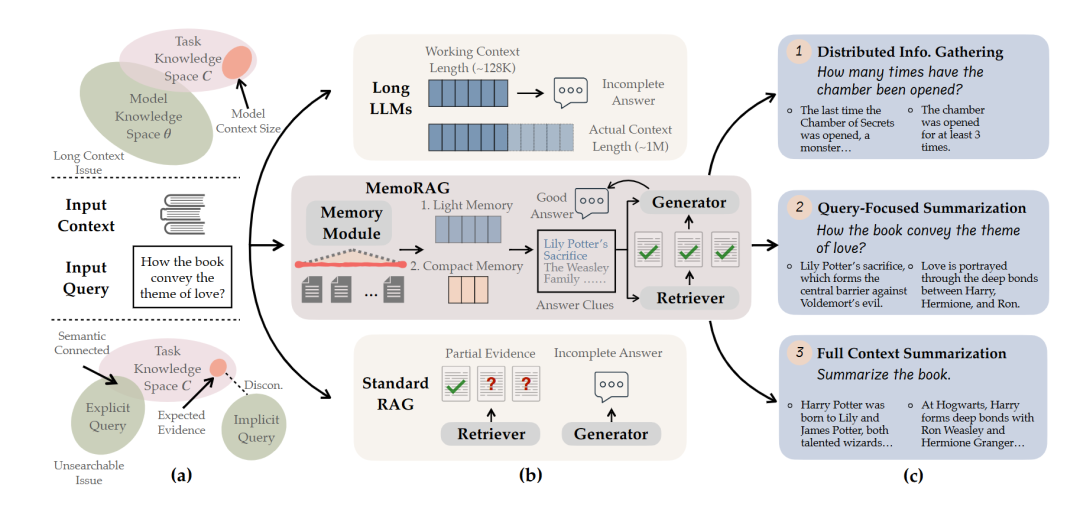
| 维度 | 说明 |
| 关键特征 | 1. 外部记忆存储 2. 外部记忆检索 |
| 优势 | 1. 连续性 2. 个性化 |
| 应用场景 | 1. 维持长期对话上下文的聊天机器人 2. 个性化推荐 |
| 工具/库示例 | 1. Redis for Session Storage 2. Amazon Dynamo DB 3. Pinecone 向量数据库 |
6. Multi-Modal RAG
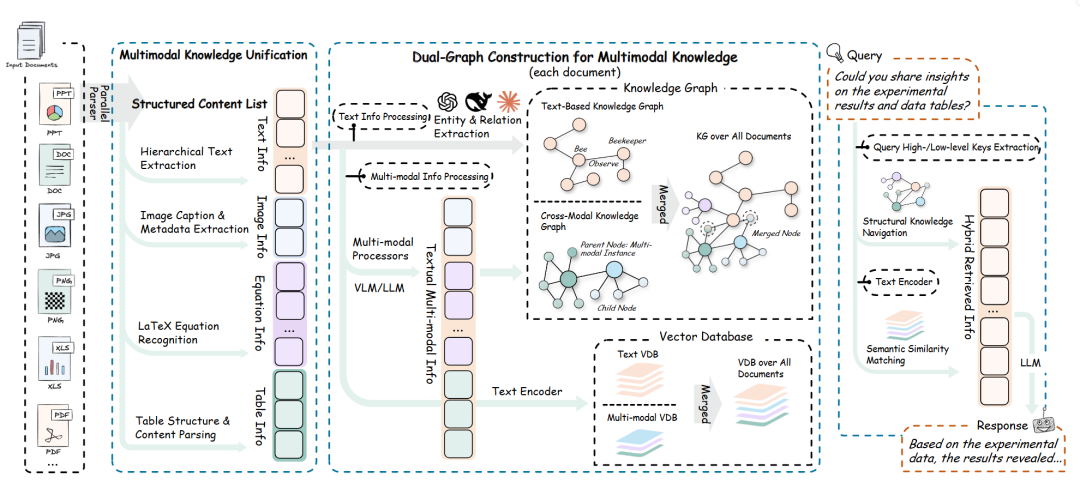
| 维度 | 说明 |
| 关键特征 | 1. 跨模态检索(文本、图像、音频) |
| 优势 | 1. 响应更加丰富 2. 可访问性 |
| 应用场景 | 1. 图像捕捉 2. 视频总结 3. 多模态助手 |
| 工具/库示例 | 1. OpenAI 的 CLIP 2. TensorFlow 多模态模型 3. PyTorch 多模态库 |
7. Federated RAG
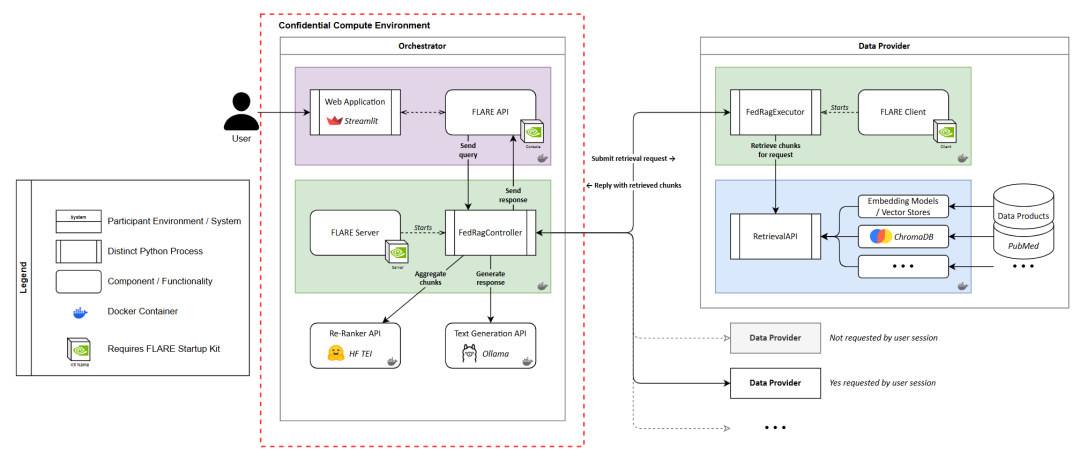
| 维度 | 说明 |
| 关键特征 | 1. 去中心化数据源 2. 隐私保护 |
| 优势 | 1. 数据安全 2. 合规性 |
| 应用场景 | 1. 处理敏感数据的医疗系统 2. 跨组织的协作平台 |
| 工具/库示例 | 1. TensorFlow Federated 2. PySyft by OpenMined 3. 联邦学习库 |
8. Streaming RAG
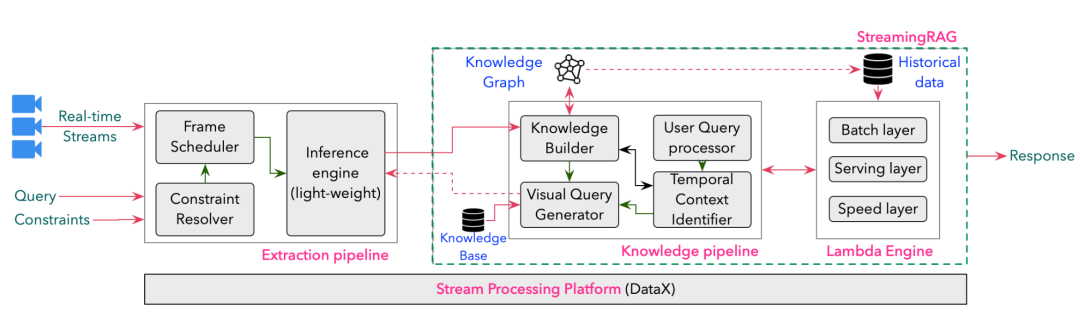
| 维度 | 说明 |
| 关键特征 | 1. 实时数据检索与生成 |
| 优势 | 1. 信息及时 2. 低延迟 |
| 应用场景 | 1. 实时报告 2. 金融行情提示 3. 社交媒体监控 |
| 工具/库示例 | 1. Apache Kafka Streams 2. Amazon Kinesis 3. Star Streaming |
9. ODQA RAG
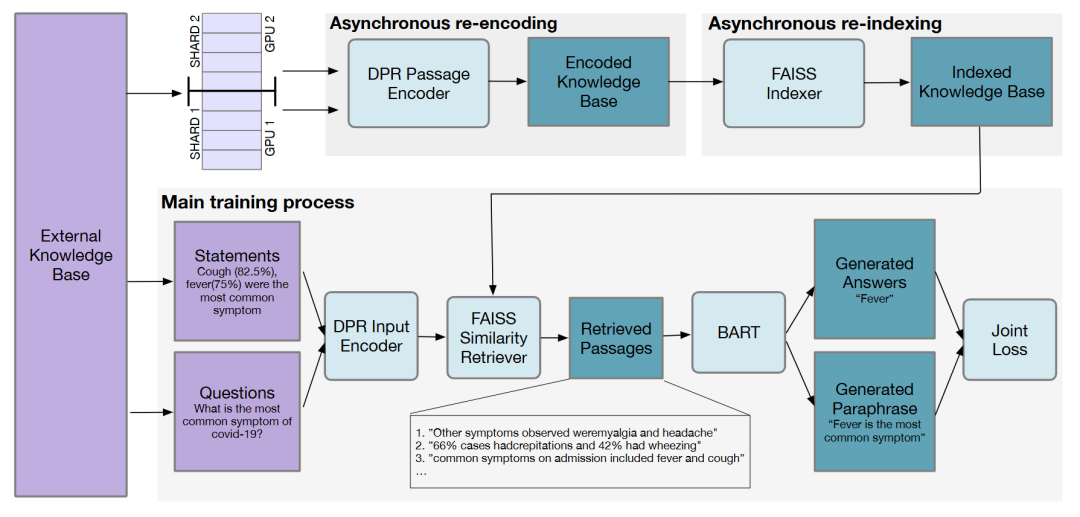
Open-Domain Question Answering (ODQA):开放域问答
| 维度 | 说明 |
| 关键特征 | 1. 广泛的知识库 2. 动态检索 |
| 优势 | 1. 适应性广 2. 响应动态 |
| 应用场景 | 1. 搜索引擎 2. 处理多样查询的虚拟助手 |
| 工具/库示例 | 1. Elasticsearch 2. Haystack by Deepset 3. Hugging Face Transformers |
10. Contextual Retrieval RAG
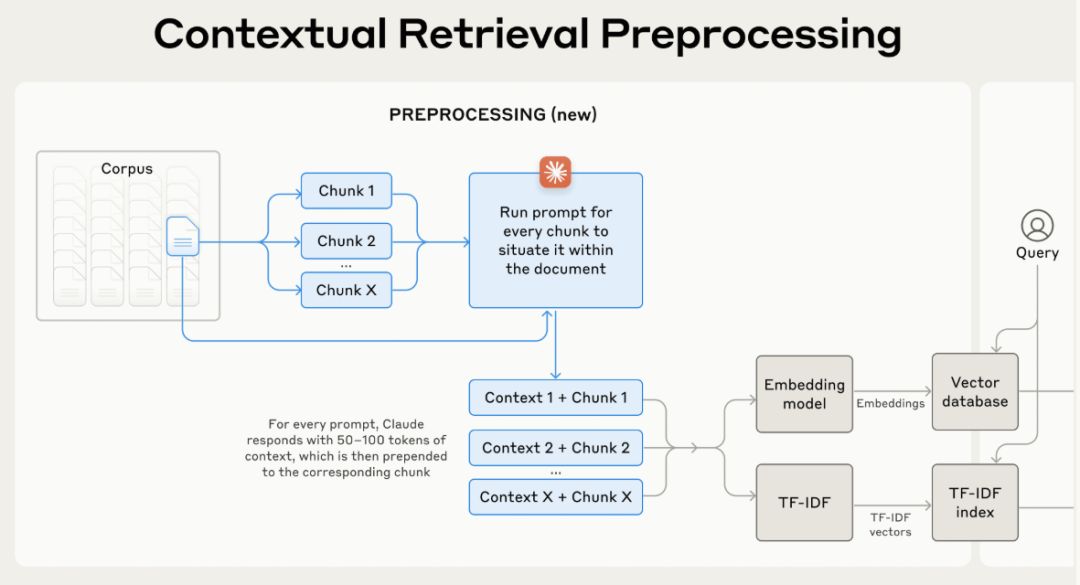
| 维度 | 说明 |
| 关键特征 | 1. 利用对话历史进行上下文感知检索 |
| 优势 | 1. 个性化 2. 连贯性 |
| 应用场景 | 1. 对话式 AI 2. 维持会话上下文的客户支持聊天机器人 |
| 工具/库示例 | 1. Dialogflow by Google 2. Rasa Open Source 3. Microsoft Bot Framework |
11. Knowledge-Graph-Enhanced RAG
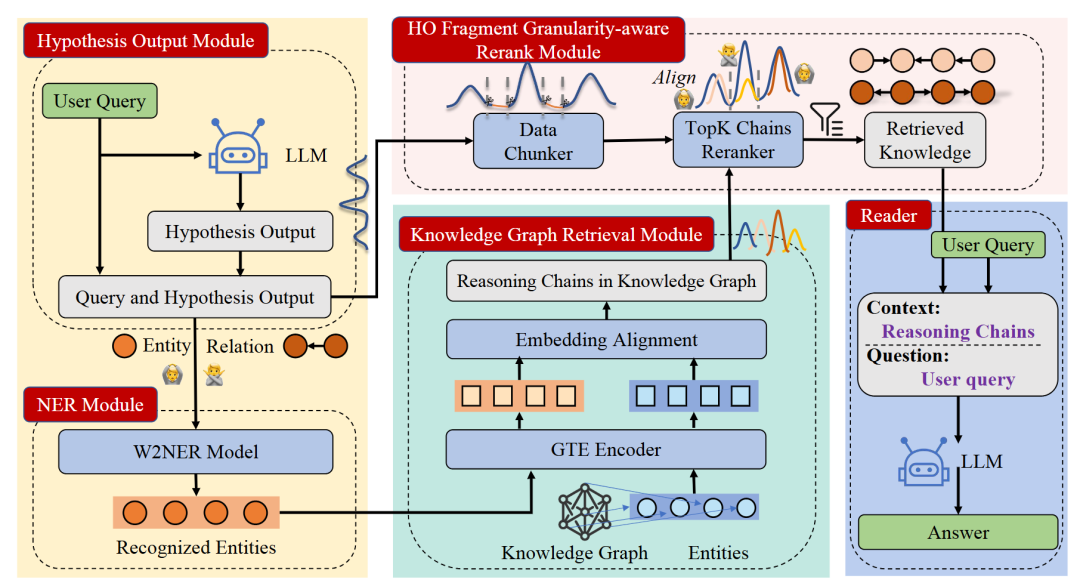
| 维度 | 说明 |
| 关键特征 | 1. 集成结构化知识库 2. 知识图谱 |
| 优势 | 1. 事实准确性 2. 领域专业性 |
| 应用场景 | 1. 教育工具 2. 专业领域应用(法律、医疗) |
| 工具/库示例 | 1. 知识图谱嵌入库 2. OWL API 3. Apache Jena |
12. Domain-Specific RAG
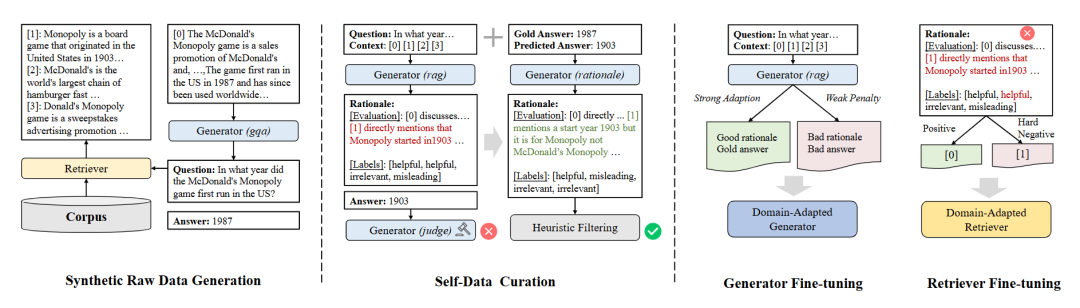
| 维度 | 说明 |
| 关键特征 | 1. 针对特定行业或领域定制 |
| 优势 | 1. 相关性 2. 合规性 3. 可信度 |
| 应用场景 | 1. 法律研究助手 2. 医疗诊断支持 3. 金融分析工具 |
| 工具/库示例 | 1. LexPredict 合同分析 2. Watson NLP 3. 金融健康工具 |
13. Hybrid RAG
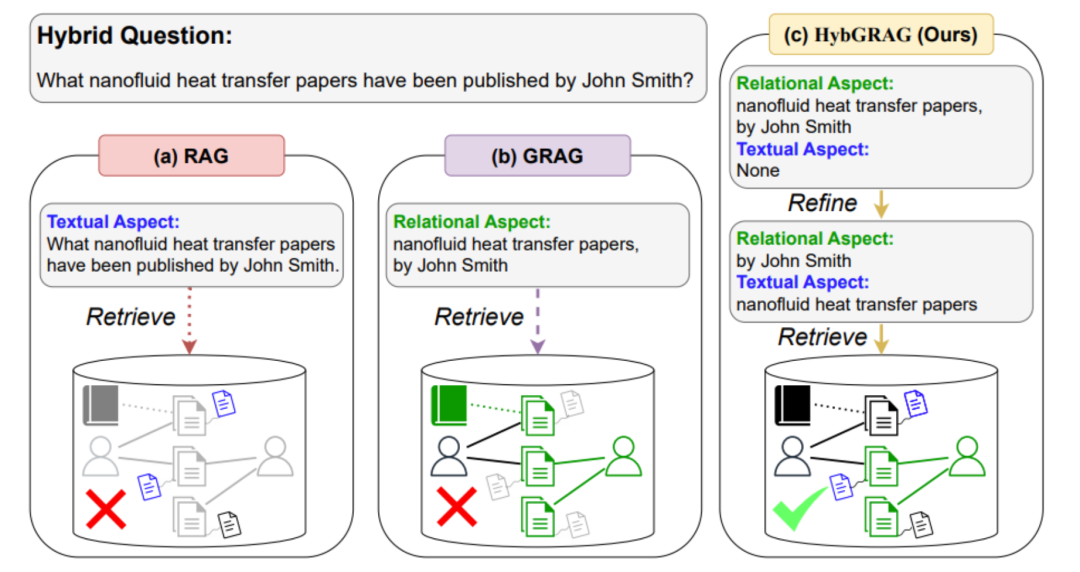
| 维度 | 说明 |
| 关键特征 | 1. 结合多种检索方法 |
| 优势 | 1. 提高召回率 2. 增强相关性 |
| 应用场景 | 1. 复杂问答系统 2. 需要词汇匹配和语义匹配的搜索引擎 |
| 工具/库示例 | 1. Elasticsearch with kNN 2. PLMS by Facebook AI 3. 混合检索库 |
14. Self-RAG
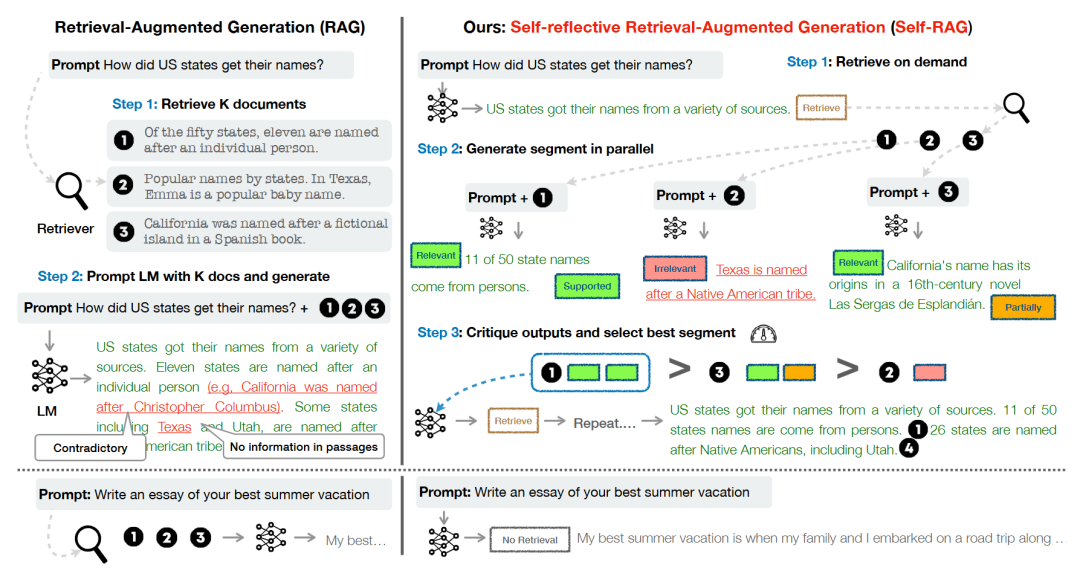
| 维度 | 说明 |
| 关键特征 | 1. 自反思机制 2. 迭代优化 |
| 优势 | 1. 准确性强 2. 连贯性高 |
| 应用场景 | 1. 内容创作 2. 教育平台 |
| 工具/库示例 | 1. OpenAI GPT Models with Fine-Tuning 2. Human-in-the-Loop Platforms |
15. HyDE RAG
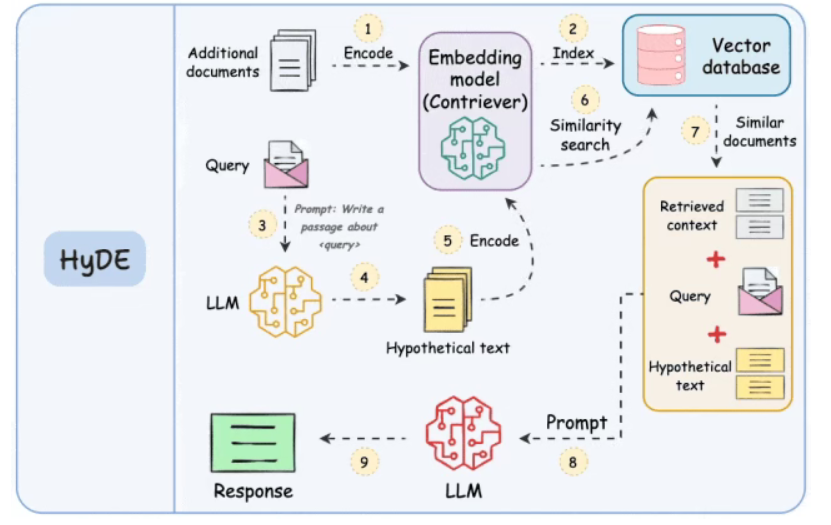
Hypothetical Document Embeddings(HyDE):假设文档嵌入
| 维度 | 说明 |
| 关键特征 | 1. 假设文档嵌入用于引导检索 |
| 优势 | 1. 召回率更高 2. 答案质量提升 |
| 应用场景 | 1. 具有隐性含义的复杂查询 2. NICHE 领域的研究辅助 |
| 工具/库示例 | 1. 基于 Transformer 的自定义实现 2. Haystack Pipelines |
16. Recursive/Multi-Step RAG
| 维度 | 说明 |
| 关键特征 | 1. 多轮检索与生成 |
| 优势 | 1. 推理增强 2. 理解更深入 |
| 应用场景 | 1. 分析和解决问题的任务 2. 多轮交互的对话系统 |
| 工具/库示例 | 1. LangChain 的 Chains 和 Agents 2. DeepMind 的 AlphaCode 框架 |
17. Corrective RAG
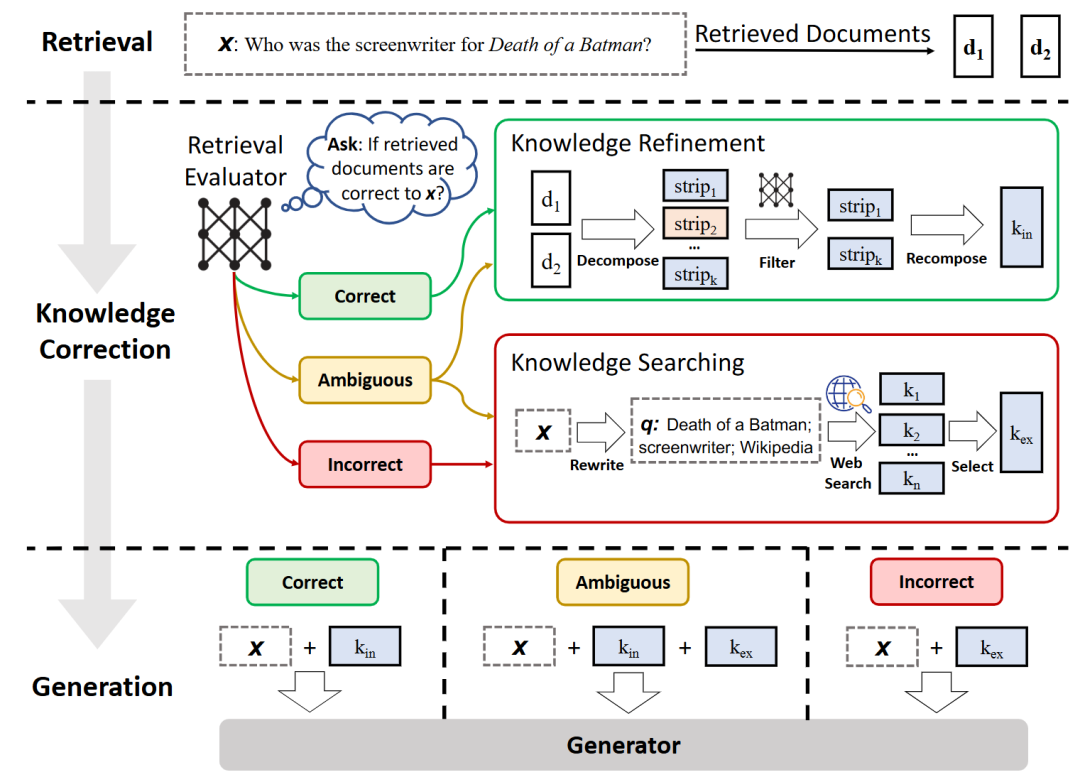
| 维度 | 说明 |
| 关键特征 | 1. 基于可信数据源进行交叉验证和修正 |
| 优势 | 1. 精准度更高 2. 答案质量提升 |
| 应用场景 | 1. 医疗、法律、新闻摘要等对事实准确性零容忍领域 |
| 工具/库示例 | 1. 基于LangChain框架 2. 基于LangGraph框架 3. 开源CRAg项目 |
18. MultiHop-RAG
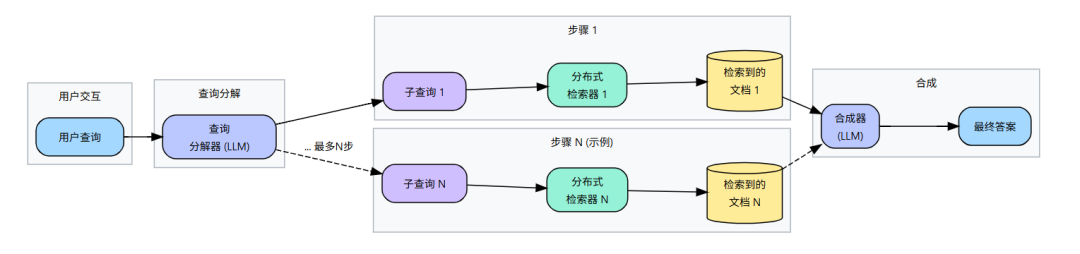
| 维度 | 说明 |
| 关键特征 | 1. 进行多次检索,构建上下文进行多角度审视 |
| 优势 | 1. 增强推理与关联能力 2. 提高答案准确性与完整性 3. 结合知识图谱辅助推理 |
| 应用场景 | 1. 学术研究与教育 2. 医疗保健 3. 法律与合规 |
| 工具/库示例 | 1. 基于LangChain框架 2. 基于LangGraph框架 3. 基于LlamaIndex框架 |
19. RAG Fusion
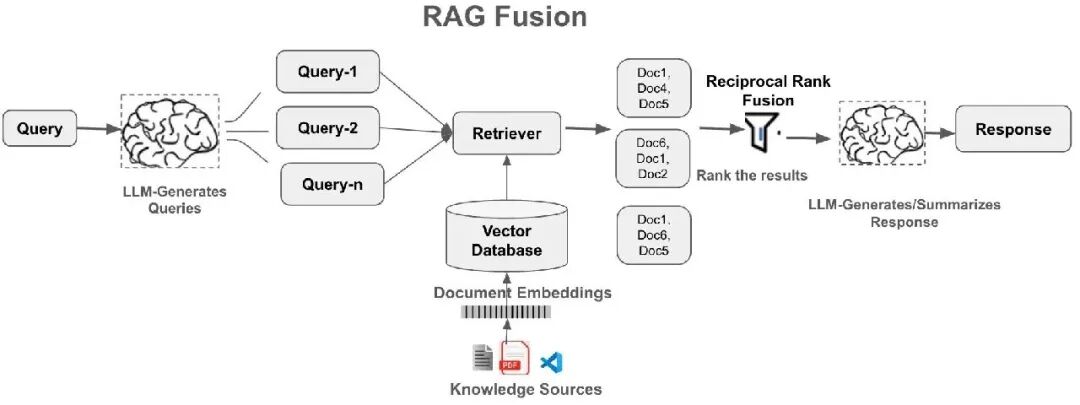
| 维度 | 说明 |
| 关键特征 | 1. 将多个搜索结果合并起来以生成单一统一排名 |
| 优势 | 1. 更全面的回答 2. 减少偏见 3. 提升准确性 |
| 应用场景 | 1. 开放域问答 2. 跨模态搜索 3. 争议性话题分析 |
| 工具/库示例 | 1. 基于LangChain框架 2. 基于LlamaIndex框架 3. 开源RAG-Fusion项目 |
20. Adaptive RAG
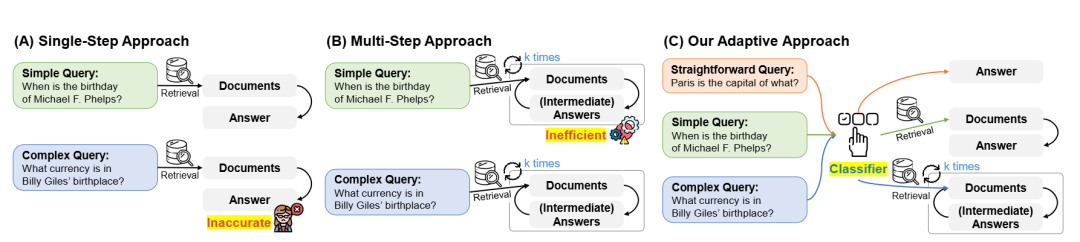
| 维度 | 说明 |
| 关键特征 | 1. 用小模型或规则进行问题分类,动态选择检索深度与生成策略 |
| 优势 | 1. 简单题快速回答,复杂题自动拆解 2. 提升准确性 |
| 应用场景 | 1. 百科全书式开放域问答 2. 金融、政务等领域知识问答 |
| 工具/库示例 | 1. 基于LangChain框架 2. 基于LlamaIndex框架 |
结论
RAG 已完成从「独立热点」到「智能体基础设施」的转型。未来竞争焦点不再是单点召回率,而是多智能体协同效率、跨模态证据融合与低成本边缘部署,需要抓住「Agentic + 图谱 + 轻量化」三条主线。
- Agentic 化
静态「检索-生成」流水线被多智能体协作替代;Agent 负责任务拆解、工具选择、交叉验证与答案裁决,成为复杂推理场景的缺省配置 。
- 多模态统一
统一模型同时处理文本、图表、公式、视频帧,「版面解析→结构序列化→跨模态嵌入」将替代纯文本切块,金融研报、医疗影像率先落地 。
- 图-向量混合索引
知识图谱提供可解释多跳,向量检索保证语义泛化;动态图增量更新、因果子图抽取、多模态节点是下一步重点 。
- 轻量化与低代码
100MB以内嵌入模型 + ONNX 边缘推理,配合Agent编排平台让中小企业 1 周内上线 RAG 应用,成本低。
- 实时 & 联邦化
CDC+流式向量库实现秒级知识更新;联邦学习确保「数据不出域」场景也能共享全局检索能力。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 7039
7039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









