



在做AI应用开发的时候,大模型都有一个通病,虽然强大,但它不知道你公司的私有文档,记不住之前的对话,更不会主动上网搜索最新信息。大模型就像一个博学但"与世隔绝"的学者——知识丰富,却无法连接现实世界。
LangChain 正是为了解决这个问题而生。它是由 Harrison Chase 开发的开源框架,专门用来构建基于大语言模型(LLM)的应用程序。简单来说,LangChain 就是连接"大脑"(LLM)和"现实世界"(数据库、搜索引擎、私有文档)的桥梁。
这篇文章将手把手带你从零开始掌握 LangChain,每个步骤都提供完整的可运行代码。你不需要有 Python 基础,只要跟着操作,就能构建出自己的 AI 应用。希望对你有所启发。
PART 01 - 技术背景与挑战
大模型的三大局限性
当我们直接调用 GPT 或其他大模型的 API 时,会遇到三个根本性问题:
知识过期 - 模型只知道训练时的数据,不知道昨天刚发生的新闻,也不知道你公司的内部文档。就像一个 2023 年就"冬眠"的人,醒来后对 2024 年的世界一无所知。
无记忆能力 - 每次 API 调用都是全新的开始。你问它"我叫什么",它回答了;下次再问,它完全忘记了。这不是模型笨,而是 API 的调用机制决定的——每次请求都是独立的,没有状态保持。
缺乏工具使用能力 - 问它"现在比特币多少钱",它只能胡乱猜测;让它"帮我算一下 23423 × 82342",大概率算错。大模型天生不擅长精确计算和实时数据获取。
LangChain 的解决方案:组件化与链式调用
LangChain 的核心哲学是组合优于继承。它把 AI 应用开发拆解成一个个独立的"积木":
-
Models
- 统一的模型接口,兼容 100+ 种 LLM 提供商
-
Prompts
- 可复用的提示词模板
-
Memory
- 开箱即用的记忆管理组件
-
Chains
- 将多个组件串联成工作流
-
Agents
- 能自主决策、使用工具的智能体
这种设计的精妙之处在于:数据流向清晰,组件职责单一。每个组件只做一件事,并且做好——这正是优秀架构的标志。
PART 02 - 核心架构解析
从企业架构的角度看,LangChain 的设计完美符合 TOGAF 框架的四层模型:
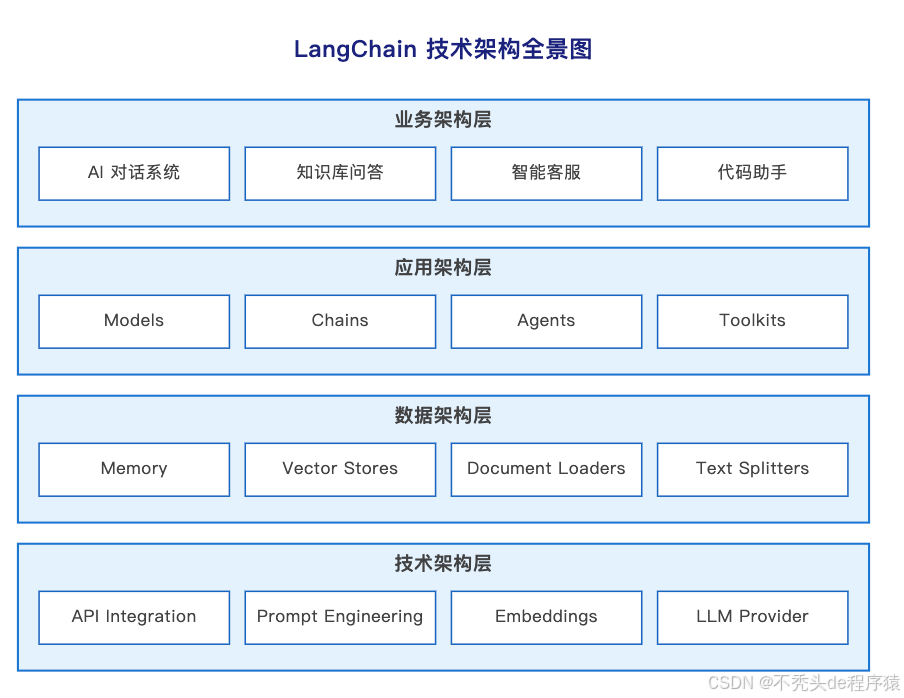
业务架构层 - LangChain 能构建哪些 AI 应用?答案是:AI 对话系统、知识库问答、智能客服、代码助手等。关键是它降低了门槛——以前需要 AI 团队才能做的事,现在几十行代码就能实现。
应用架构层 - 核心组件包括 Models(模型抽象)、Chains(链式调用)、Agents(智能体)、Toolkits(工具集)。这一层的设计哲学是可组合性:你可以像搭乐高一样组合这些组件,而不是从零开始写代码。
数据架构层 - 包含 Memory(记忆管理)、Vector Stores(向量数据库)、Document Loaders(文档加载器)、Text Splitters(文本切割器)。重点是数据的流转和转换:原始文档如何变成 AI 能理解的向量?对话历史如何高效存储和检索?
技术架构层 - 底层涉及 API Integration(多模型兼容)、Prompt Engineering(提示词工程)、Embeddings(向量化)、LLM Provider(模型提供商集成)。这一层解决的是如何让不同技术栈无缝协作。
核心设计:State、Node、Edge
从 LangGraph(LangChain 的进阶版)可以看出架构设计的精髓:
-
State
(状态) - 就像一个"货箱",在各个处理节点间传递数据。它不是简单的变量,而是结构化的数据容器,清晰定义了"这一步需要什么数据,输出什么数据"。
-
Node
(节点) - 每个节点是一个独立的处理单元,比如"分类器"、“数学专家”、“编辑审核”。节点的职责单一,边界清晰,这样才能组合出复杂的流程而不失控。
-
Edge
(边) - 定义数据流向。普通边是固定路径,条件边可以根据状态动态决定下一步去哪里(就像交通路口的红绿灯)。
这种设计的天才之处在于:把流程控制从代码逻辑中抽离出来,变成可视化的图结构。你画一个流程图,就能直接翻译成代码。
LangChain 基础工作流用户输入QueryPrompt 模板TemplateLLM 调用Model输出 解析Parser结果 返回Response

PART 03 - 环境准备与安装
在开始实战之前,我们需要搭建开发环境。以下步骤适用于 macOS、Linux 和 Windows 系统。
步骤 1:安装 Python
确保你的电脑已安装 Python 3.8 或更高版本。打开终端(Terminal 或 CMD),输入:
python3 --version
如果显示版本号(如 Python 3.12.11),说明已安装。否则请访问 https://www.python.org 下载安装。
步骤 2:安装 LangChain 核心库
在终端中执行以下命令:
pip install langchain langchain-openai
如果下载速度慢,可以使用国内镜像源:
pip install langchain langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤 3:获取 API Key
本教程使用**智谱 AI(ChatGLM)**作为示例,因为它:
- 完美兼容 OpenAI API 格式
- 中文能力强
- 价格实惠(约为 GPT-4 的 1/3)
访问 https://open.bigmodel.cn 注册账号并获取 API Key(通常是一串以 . 分隔的字符)。
重要提示:代码中所有 "你的_API_KEY" 都需要替换成你的真实 API Key。
PART 04 - 四阶段实战路线图
第一步:Hello World - 打通引擎
目标:让 AI 开口说话,验证环境配置正确。
核心洞察:LangChain 的模型接口抽象得非常巧妙。它兼容 OpenAI 格式的 API,这意味着你写的代码可以无缝切换到 DeepSeek、Moonshot 等其他模型——只需要改两行配置。
创建文件 lesson1.py,复制以下代码:
# 1. 导入必要的工具包# ChatOpenAI 是 LangChain 用来连接符合 OpenAI 标准接口的模型(智谱就是其中之一)from langchain_openai import ChatOpenAI# 2. 初始化模型 (配置"大脑")# 这里我们配置了三个关键参数:# - model: 我们用的是智谱的 GLM-4 模型# - openai_api_key: 你的通行证# - openai_api_base: 告诉 LangChain 不要去连 OpenAI 的服务器,而是连智谱的服务器llm = ChatOpenAI( model="glm-4", openai_api_key="你的_API_KEY", # 🔴 记得在这里填入你的 Key openai_api_base="https://open.bigmodel.cn/api/paas/v4/")# 3. 直接调用模型# invoke 就是"调用"的意思,我们发给它一句话print("正在思考中...")response = llm.invoke("你好!请用鲁迅的语气夸我一下学编程很快。")# 4. 打印结果# response.content 才是模型真正回复的内容print("--- 回复内容 ---")print(response.content)
运行方法:
python3 lesson1.py
预期输出:你会看到智谱 AI 用鲁迅的语气夸奖你,类似:
正在思考中...--- 回复内容 ---哦,你这位君子,编程之道,竟也能游刃有余...
架构洞察:这看似简单,实则蕴含深意——接口标准化是可移植性的前提。想象一下,如果没有统一的插座标准,每换一个电器就要重新布线,那将是灾难。LangChain 通过统一接口,让你的代码可以在不同模型间自由迁移。
第二步:给 AI 加上记忆 - Memory
目标:让 AI 记住上下文,实现多轮对话。
问题分析:现在的 AI 像一条金鱼,记忆只有 7 秒。如果你告诉它"我叫小明",然后再问"我叫什么",它会一脸茫然。因为每次运行都是一次全新的开始。
解决方案:LangChain 的思路很简单——把之前的聊天记录,打包一起发给它。
创建文件 lesson2.py:
from langchain_openai import ChatOpenAI# 1. 导入三种消息类型# SystemMessage: 系统指令 (比如:你是一个猫娘...)# HumanMessage: 用户说的话# AIMessage: AI 回复的话from langchain_core.messages import HumanMessage, AIMessage, SystemMessage# 2. 初始化模型 (配置和之前一样)llm = ChatOpenAI( model="glm-4", openai_api_key="你的_API_KEY", # 🔴 别忘了替换 Key openai_api_base="https://open.bigmodel.cn/api/paas/v4/")# 3. 初始化"记忆条"# 我们用一个列表来保存所有的对话历史# 先给它定个调子:你是一个资深的 Python 助教messages = [ SystemMessage(content="你是一个幽默的 Python 助教,说话喜欢带点 emoji。")]print("🤖 助教已上线!(输入 'exit' 退出)")# 4. 开启循环对话while True: # 获取用户输入 user_input = input("\n👤 你: ") # 如果输入 exit 就结束 if user_input.lower() == "exit": print("再见!") break # A. 把用户说的话,包装成 HumanMessage,存入记忆列表 messages.append(HumanMessage(content=user_input)) # B. 把整个记忆列表 (包含之前的对话) 发给 AI print("Thinking...") response = llm.invoke(messages) # C. 打印 AI 的回复 ai_reply = response.content print(f"🤖 助教: {ai_reply}") # D. 关键一步:把 AI 的回复也存入记忆列表 messages.append(AIMessage(content=ai_reply))
运行方法:
python3 lesson2.py
测试记忆力:
你: 你好,我叫张三助教: 你好张三!👋 很高兴认识你...你: 你知道我叫什么名字吗?助教: 当然知道!你叫张三 😊
架构洞察:记忆的本质是什么?不是什么黑科技,而是把之前的对话记录打包一起发给模型。就像开会时,你不能只告诉老板"我同意",你得先复述一遍前面讨论了什么,老板才知道你同意的是什么。
如果去掉代码中的 A 和 D 步骤,messages 列表里就永远只有那句系统指令,AI 每次都看不到之前的对话。记忆的本质,就是不断把新的聊天记录"追加"到清单里,再重新发给模型。
第三步:与你的数据对话 - RAG(检索增强生成)
目标:让 AI 基于你提供的文档回答问题(这是目前最火的应用场景)。
问题分析:现在的 AI 虽然博学,但它有两个大问题:
- 知识过期:它不知道昨天刚发生的新闻
- 私有数据盲区:它不知道你们公司的内部文档
解决方案:RAG (检索增强生成) 就是给 AI 搞一场"开卷考试"。我们先把资料给它,当你问问题时,它先去资料里翻书(检索),找到答案后再总结给你(生成)。
比喻:RAG 就像给 AI 配了一个外接移动硬盘。模型本身的参数是"内存",RAG 是"硬盘"——内存有限但速度快,硬盘容量大但需要检索。
步骤 1:安装额外依赖
pip install langchain-community faiss-cpu
步骤 2:准备知识文档
在你的代码文件夹里新建一个文本文件 knowledge.txt,写入一些只有你知道的秘密知识:
LangChain秘密档案:1. 这里的程序员其实都是猫变的,他们最爱吃的不是bug,是猫条。2. 学习LangChain的秘诀是每天对着电脑大喊三声"奥力给"。3. 2025年的最佳编程语言是"喵喵语"。
步骤 3:创建 RAG 程序
创建文件 lesson3.py:
import osfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import CharacterTextSplitterfrom langchain_community.vectorstores import FAISSfrom langchain_core.prompts import ChatPromptTemplate# --- 配置 ---API_KEY = "你的_API_KEY" # 🔴 记得填 KeyBASE_URL = "https://open.bigmodel.cn/api/paas/v4/"# 1. 配置"大脑" (负责回答)llm = ChatOpenAI( model="glm-4", openai_api_key=API_KEY, openai_api_base=BASE_URL)# 2. 配置"眼睛" (Embeddings - 负责把文字变成数字,方便搜索)# 智谱也提供了 embedding 模型,我们这里用 embedding-2embeddings = OpenAIEmbeddings( model="embedding-2", openai_api_key=API_KEY, openai_api_base=BASE_URL)print("📚 正在加载并处理文档...")# --- 第一步:加载文档 ---loader = TextLoader("knowledge.txt", encoding="utf-8")documents = loader.load()# --- 第二步:切割文档 ---# 如果文档太长,模型吃不消,所以要切成小块text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)docs = text_splitter.split_documents(documents)# --- 第三步:存入向量数据库 (建立书架) ---# 这一步会把文字变成向量存起来,这样才能进行语义搜索vectorstore = FAISS.from_documents(docs, embeddings)print("✅ 知识库建立完成!")# --- 第四步:检索与问答 ---# 这是一个特殊的 Chain,专门用来做 RAGfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain.chains import create_retrieval_chain# 这是一个提示词模板,告诉 AI:请根据下面的 context (上下文) 来回答问题prompt = ChatPromptTemplate.from_template("""请根据下面的内容回答用户的问题:<context>{context}</context>用户问题:{input}""")# 创建"文档处理链" (负责把找出来的文档塞给 LLM)document_chain = create_stuff_documents_chain(llm, prompt)# 创建"检索链" (负责先去书架找书,再交给上面的链)retriever = vectorstore.as_retriever()retrieval_chain = create_retrieval_chain(retriever, document_chain)# --- 开始提问 ---query = "学习 LangChain 的秘诀是什么?"print(f"\n❓ 提问: {query}")response = retrieval_chain.invoke({"input": query})print(f"💡 回答: {response['answer']}")
运行方法:
python3 lesson3.py
预期输出:AI 会基于 knowledge.txt 里的内容回答,比如:“学习 LangChain 的秘诀是每天对着电脑大喊三声’奥力给’。”
架构洞察:RAG 的数据流转
-
文档加载
- 把 PDF、Word 等文件读成文本
-
智能分块
- 每 500 字切一块,关键是相邻块重叠 50 字——为什么?因为如果从段落中间硬切,上下文就断了
-
向量化
- 把文本转成 384 维向量(这不是随机数字,而是"语义坐标")
-
语义检索
- 用户提问时,先在向量库里找最相关的文本块,再让 LLM 基于这些文本回答
核心创新:用空间距离表达语义相似度,把 NLP 问题转化为几何问题。意思相近的文本,向量距离会很近——这种"降维打击"的思想极其优雅。
第四步:给 AI 装上"双手" - Agents
目标:让 AI 学会使用工具(如搜索网络、查天气、算数学)。
问题分析:问 AI “现在比特币多少钱”,它只能胡乱猜测;让它算 23423 × 82342,大概率算错。大模型天生不擅长精确计算和实时数据获取。
解决方案:Agent (代理) 的核心概念——当 AI 遇到自己不会的问题时,它知道去使用"工具"。
步骤 1:安装搜索工具
pip install duckduckgo-searchpip install -U ddgs
步骤 2:创建 Agent 程序
创建文件 lesson4.py:
from langchain_openai import ChatOpenAI# 1. 导入搜索工具from langchain_community.tools import DuckDuckGoSearchRun# 2. 导入创建 Agent 的辅助函数from langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplate# --- 配置 ---API_KEY = "你的_API_KEY" # 🔴 记得填 KeyBASE_URL = "https://open.bigmodel.cn/api/paas/v4/"# 1. 初始化模型 (大脑)llm = ChatOpenAI( model="glm-4", openai_api_key=API_KEY, openai_api_base=BASE_URL)# 2. 准备工具 (双手)# 我们创建一个搜索工具实例search = DuckDuckGoSearchRun()# 把工具放在一个列表里 (以后你可以往里面加日历工具、计算器工具等)tools = [search]# 3. 创建 Prompt (任务书)# 我们需要告诉 AI:你是一个可以调用工具的助手prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个强大的助手。你可以使用工具来查找最新的信息。如果用户问的问题需要联网,请务必使用搜索工具。"), ("user", "{input}"), ("placeholder", "{agent_scratchpad}"), # 🔴 这是一个预留位置,用来存放 AI 的思考过程])# 4. 组装 Agent (大脑 + 手 + 任务书)agent = create_tool_calling_agent(llm, tools, prompt)# 5. 创建执行器 (监工)# verbose=True 会打印出 AI 思考和调用工具的详细过程,非常有趣!agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)# --- 开始运行 ---# 问一个它训练数据里肯定没有的问题 (比如最新的新闻)query = "2024年奥运会是在哪里举办的?结果如何?"print(f"🔍 用户提问: {query}\n")print("--- Agent 开始工作 ---")response = agent_executor.invoke({"input": query})print("\n--- 最终回答 ---")print(response["output"])
运行方法:
python3 lesson4.py
预期输出:你会看到 AI 的思考过程(绿色/黄色文字):
🔍 用户提问: 2024年奥运会是在哪里举办的?结果如何?--- Agent 开始工作 ---> Entering new AgentExecutor chain...需要使用搜索工具...调用工具: duckduckgo_searchTitle: Paris 2024 Olympics......最终回答 ---2024年奥运会在法国巴黎举办...
架构洞察:Agent 的设计哲学是将"决策"和"执行"分离。模型不直接输出答案,而是输出一个"调用工具"的指令,框架负责执行工具并把结果喂回给模型,模型再基于结果生成最终答案。这个循环可以重复多次,直到问题解决。 AI 从"只会说"进化到了"既会想又会做"。
第五步:给代码穿上"外衣" - Streamlit 网页界面
目标:把黑乎乎的终端程序变成漂亮的网页应用。
问题分析:目前的程序都在终端里运行,不够直观,也不方便分享给朋友使用。如果能有一个网页界面,就能像 ChatGPT 一样随时打开使用。
解决方案:Streamlit 是一个 Python 库,专门用来快速构建数据应用的 Web 界面。最神奇的是:你不需要懂 HTML、CSS、JavaScript,完全用 Python 就能写出漂亮的网页。 比喻:Streamlit 就像给你的 Python 程序套上一个精美的外壳,让它从"命令行工具"变成"Web 应用"。
步骤 1:安装 Streamlit
pip install streamlit
步骤 2:创建网页版聊天机器人
我们要把 Lesson 2 的带记忆聊天机器人搬到网页上。创建文件 lesson5_streamlit.py:
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# --- 1. 页面配置 ---
st.set_page_config(page_title="我的 AI 助手", page_icon="🤖")
st.title("🤖 我的专属 AI 聊天室")
# --- 2. 初始化模型 ---
# 为了防止每次页面刷新都重新连接模型,我们加个缓存装饰器 (可选,但推荐)
@st.cache_resource
def get_llm():
return ChatOpenAI(
model="glm-4",
openai_api_key="你的_API_KEY", # 🔴 记得填 Key
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
llm = get_llm()
# --- 3. 初始化"记忆" (Session State) ---
# 如果"暂存箱"里没有消息记录,我们就创建一个空的,并放入系统指令
if "messages" not in st.session_state:
st.session_state.messages = [
SystemMessage(content="你是一个乐于助人的 AI 助手,回答请简洁明了。")
]
# --- 4. 渲染聊天记录 ---
# 每次刷新页面,都把暂存箱里的历史消息画在屏幕上
for msg in st.session_state.messages:
if isinstance(msg, HumanMessage):
with st.chat_message("user"): # 渲染用户的气泡
st.write(msg.content)
elif isinstance(msg, AIMessage):
with st.chat_message("assistant"): # 渲染 AI 的气泡
st.write(msg.content)
# --- 5. 处理用户输入 ---
# st.chat_input 会在页面底部创建一个输入框
user_input = st.chat_input("说点什么吧...")
if user_input:
# A. 显示用户输入
with st.chat_message("user"):
st.write(user_input)
# B. 存入记忆
st.session_state.messages.append(HumanMessage(content=user_input))
# C. 调用模型 (带着之前的记忆)
with st.chat_message("assistant"):
with st.spinner("AI 正在思考..."): # 显示一个加载转圈圈
response = llm.invoke(st.session_state.messages)
st.write(response.content)
# D. 把 AI 的回复存入记忆
st.session_state.messages.append(AIMessage(content=response.content))
运行方法:
Streamlit 的运行方式和普通 Python 脚本不一样。请在终端输入:
streamlit run lesson5_streamlit.py
预期效果:
终端会自动打开你的默认浏览器(通常地址是 http://localhost:8501),你会看到:
- 一个漂亮的聊天界面(类似 ChatGPT)
- 对话历史会保留在页面上
- 底部有输入框,可以连续对话
- 每次刷新页面,历史记录都还在
架构洞察:Session State 的关键设计
Streamlit 有一个重要机制:每次你点击按钮或输入内容,整个 Python 脚本会从头到尾重新运行一遍。
这意味着什么?如果没有 st.session_state,每次输入都会创建一个新的空 messages 列表,AI 就会失忆。
st.session_state 的作用就是在页面刷新时保持数据不丢失。你可以把它理解为"网页的暂存箱":
- 第一次访问页面:创建空的
messages列表 - 用户输入 “你好”:追加到列表,刷新页面,从暂存箱读取完整列表
- AI 回复:追加到列表,刷新页面,从暂存箱读取完整列表
- 用户再次输入:继续追加…
实用技巧:你可以在侧边栏添加控制选项,比如调节 AI 的"创造力"(temperature 参数):
# 在文件开头添加侧边栏配置
with st.sidebar:
st.header("⚙️ 设置")
temperature = st.slider("创造力", 0.0, 1.0, 0.7, 0.1)
# 更新 llm 配置
llm = ChatOpenAI(
model="glm-4",
openai_api_key="你的_API_KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/",
temperature=temperature
)
PART 05 - LangGraph 进阶:流程编排的艺术
为什么需要 LangGraph?
LangChain 的 Chain(链)是单向流动的:A → B → C → 结束。但现实场景往往需要:
-
条件分支
- 如果是数学题走 A 路径,闲聊走 B 路径
-
循环迭代
- 写文章 → 审核 → 不满意就重写 → 再审核 → 直到满意
-
并行处理
- 同时调用多个工具,再汇总结果
LangGraph 引入了图结构(Graph),可以表达任意复杂的流程。
实战:条件路由 - 红绿灯式的智能分流
目标:做一个智能分流系统。用户输入 → AI 判断意图 → 如果是"数学题"走 A 路,如果是"闲聊"走 B 路。
步骤 1:安装 LangGraph
pip install langgraph
步骤 2:创建条件路由程序
创建文件 lesson6_router.py:
import osfrom typing import TypedDict, Literalfrom langgraph.graph import StateGraph, ENDfrom langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.messages import SystemMessage, HumanMessage# --- 配置 ---API_KEY = "你的_API_KEY" # 🔴 别忘了替换 KeyBASE_URL = "https://open.bigmodel.cn/api/paas/v4/"llm = ChatOpenAI( model="glm-4", openai_api_key=API_KEY, openai_api_base=BASE_URL)# --- 1. 定义 State (数据的货箱) ---# 我们规定这个箱子里只能装这三样东西class AgentState(TypedDict): question: str # 用户的原始问题 classification: str # 分类结果 (比如 "math" 或 "general") answer: str # 最终生成的回答print("✅ 状态定义完成!准备开始构建节点...")# --- 2. 定义节点 (干活的函数) ---# 节点 A: 分类员def classify_input(state: AgentState): # 拿到用户的问题 question = state["question"] # 让 AI 做选择题 response = llm.invoke( [SystemMessage(content="你是一个分类器。如果用户的问题是数学计算,请只回复 'math'。如果是其他问题,请只回复 'general'。不要有多余的废话。"), HumanMessage(content=question)] ) # 核心步骤:更新 State 中的 classification 字段 return {"classification": response.content.strip()}# 节点 B: 数学家def handle_math(state: AgentState): question = state["question"] print("🧮 正在调用数学专家...") response = llm.invoke( [SystemMessage(content="你是一个数学专家。请严谨地计算并给出答案。"), HumanMessage(content=question)] ) return {"answer": response.content}# 节点 C: 聊天员def handle_general(state: AgentState): question = state["question"] print("💬 正在调用闲聊助手...") response = llm.invoke( [SystemMessage(content="你是一个幽默的聊天助手。"), HumanMessage(content=question)] ) return {"answer": response.content}# --- 3. 定义变轨逻辑 (条件边) ---def route_logic(state: AgentState): # 看一眼分类员的结果 classification = state["classification"] # 决定下一步去哪里 if "math" in classification: return "math_expert" else: return "general_assistant"# --- 4. 组装图表 (The Graph) ---workflow = StateGraph(AgentState)# A. 添加节点 (给工人挂牌)workflow.add_node("classifier", classify_input)workflow.add_node("math_expert", handle_math)workflow.add_node("general_assistant", handle_general)# B. 设置起点workflow.set_entry_point("classifier")# C. 设置条件边 (关键步骤!)# 意思就是:从 classifier 出来后,执行 route_logic 函数# 如果函数返回 "math_expert",就去 math_expert 节点# 如果函数返回 "general_assistant",就去 general_assistant 节点workflow.add_conditional_edges( "classifier", route_logic, { "math_expert": "math_expert", "general_assistant": "general_assistant" })# D. 设置终点# 数学家和聊天员干完活,就直接结束workflow.add_edge("math_expert", END)workflow.add_edge("general_assistant", END)# E. 编译图表app = workflow.compile()print("✅ 路由系统已启动!")# --- 5. 测试运行 ---# 测试 1: 数学题print("\n🧪 测试 1: 输入 '123 * 456 等于几?'")inputs = {"question": "123 * 456 等于几?"}for output in app.stream(inputs): # 打印每一步的节点名称和输出,方便观察 for key, value in output.items(): print(f" -> 经过节点: {key}") print(f" 结果: {value}")# 测试 2: 闲聊print("\n🧪 测试 2: 输入 '给我讲个笑话'")inputs = {"question": "给我讲个笑话"}for output in app.stream(inputs): for key, value in output.items(): print(f" -> 经过节点: {key}") print(f" 结果: {value}")
运行方法:
python3 lesson6_router.py
预期输出:你会看到不同的问题走不同的路径:
测试 1: 数学题 -> 经过节点: classifier -> 经过节点: math_expert 结果: 123 * 456 = 56088测试 2: 闲聊 -> 经过节点: classifier -> 经过节点: general_assistant 结果: 为什么程序员喜欢用暗色主题?因为光太亮会吸引bug!
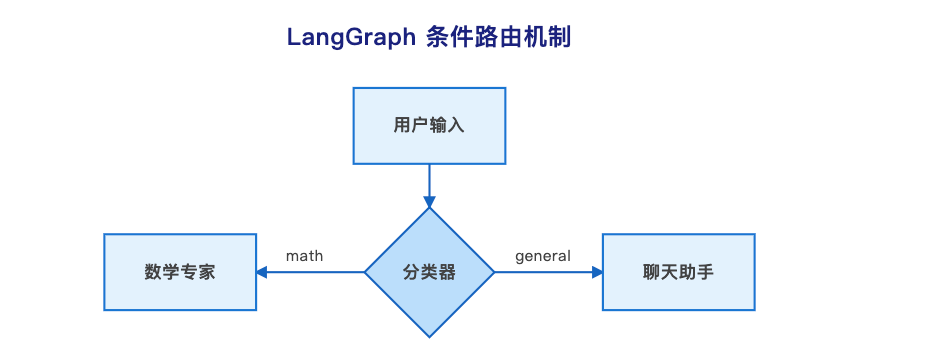
架构洞察:这种设计的好处是流程控制逻辑从业务代码中剥离。修改路由规则不需要动核心代码,符合"开闭原则"。你可以轻松添加更多分支,比如"翻译"、“代码生成"等,而不会让代码变成"意大利面条”。
实战:循环流程 - 自我修正的 AI 作家
目标:构建一个"追求完美"的作家 Agent。写初稿 → 检查质量 → 如果不达标,返回重写 → 再检查 → 直到满意。
创建文件 lesson7_loop.py:
import osfrom typing import TypedDictfrom langgraph.graph import StateGraph, ENDfrom langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.messages import SystemMessage, HumanMessage# --- 配置 ---API_KEY = "你的_API_KEY" # 🔴 记得填 KeyBASE_URL = "https://open.bigmodel.cn/api/paas/v4/"llm = ChatOpenAI( model="glm-4", openai_api_key=API_KEY, openai_api_base=BASE_URL)# --- 1. 定义 State (新的数据结构) ---class RevisionState(TypedDict): topic: str # 写作的主题 (例如: "关于AI的科普文章") draft: str # 当前的草稿内容 critique: str # 编辑的反馈意见 iterations: int # 已经修改的次数print("✅ 循环状态定义完成!")# --- 2. 定义节点 (干活的函数) ---# 节点 A: 初稿撰写员/修改员def draft_writer(state: RevisionState): topic = state["topic"] draft = state.get("draft") critique = state.get("critique") # 第一次写作和后续修改使用不同的 Prompt if draft is None: print("✍️ 首次撰写初稿...") prompt_text = f"你是一位优秀的作家。请就以下主题撰写一篇 500 字的简短文章:{topic}" else: print(f"🔄 收到编辑意见,进行第 {state['iterations'] + 1} 次修改...") prompt_text = f"你正在修改一篇关于 '{topic}' 的文章。这是编辑的意见:'{critique}'。请根据意见修改文章,并重新输出完整的文章。" response = llm.invoke( [SystemMessage(content="你是一位专业作家,请专注于内容和逻辑的改进。"), HumanMessage(content=prompt_text)] ) # 核心步骤:更新 State 中的 draft 字段 return {"draft": response.content}# 节点 B: 专业编辑def editor_critique(state: RevisionState): draft = state["draft"] print("🧐 编辑正在审阅草稿...") # 🔴 加入了严格的负面约束 response = llm.invoke( [SystemMessage(content=""" 你是一位苛刻的编辑。请阅读草稿并提出改进意见。 如果文章已经非常好(字数合理,逻辑清晰),请**只回复 'PASS'**。 如果需要修改,请给出不超过三点的具体修改意见。 **【严禁格式要求】**:在你的回复中,**严禁包含**任何 Markdown 格式、代码块、特殊字符或工具调用。你的回复必须是纯文本的建议或 'PASS'。 """), HumanMessage(content=draft)] ) critique = response.content.strip() print(f" -> 编辑反馈: {critique}") # 核心步骤:更新 State 中的 critique 字段 return {"critique": critique}# 节点 C: 计数员def increment_iteration(state: RevisionState): current_iter = state["iterations"] new_iter = current_iter + 1 return {"iterations": new_iter}# --- 3. 定义循环的"红绿灯" ---def should_continue(state: RevisionState): critique = state["critique"] # 判断条件:如果 critique 包含了 "PASS" 字符串 if "PASS" in critique: return "end" # 批准通过,结束循环 else: return "continue" # 需要修改,继续循环# --- 4. 组装循环图表 (The Graph) ---workflow = StateGraph(RevisionState)# A. 添加所有节点 (工人)workflow.add_node("draft_writer", draft_writer)workflow.add_node("editor_critique", editor_critique)workflow.add_node("increment_iteration", increment_iteration)# B. 设置起点workflow.set_entry_point("draft_writer")# C. 设置普通边 (写作 -> 审阅)workflow.add_edge("draft_writer", "editor_critique")# D. 设置条件边 (循环的关键!)# 从审阅出来后,执行 should_continue 函数# 如果返回 "end",流程结束# 如果返回 "continue",流程转到计数员workflow.add_conditional_edges( "editor_critique", should_continue, { "end": END, "continue": "increment_iteration", })# E. 设置循环边 (计数员 -> 再次撰写)# 计数员完成后,跳回到撰写节点,开始下一轮修改!workflow.add_edge("increment_iteration", "draft_writer")# F. 编译图表app = workflow.compile()print("✅ 完美循环系统已启动!")# --- 5. 测试运行 ---# 设定一个主题,并初始化状态 (iterations 从 0 开始)topic_to_write = "关于智能手机对青少年影响的利弊分析"print(f"\n🧪 开始撰写主题: {topic_to_write}")inputs = { "topic": topic_to_write, "iterations": 0}# 运行循环 (使用 invoke,它会一次性跑完所有循环,直到 END)final_state = app.invoke(inputs)print("\n--- 任务完成 ---")print(f"最终修改次数: {final_state['iterations']} 次")print(f"最终编辑反馈: {final_state['critique']}")print(f"\n最终文章:\n{final_state['draft']}")
运行方法:
python3 lesson7_loop.py
预期输出:你会看到 AI 反复修改文章,直到编辑满意:
✍️ 首次撰写初稿...🧐 编辑正在审阅草稿... -> 编辑反馈: 1. 需要增加具体数据支持... 2. 段落逻辑需要优化...🔄 收到编辑意见,进行第 1 次修改...🧐 编辑正在审阅草稿... -> 编辑反馈: 文章已经很好,结构清晰。PASS--- 任务完成 ---最终修改次数: 1 次
架构洞察:循环不是盲目重复,而是带着反馈的迭代。每次循环都把上一次的"编辑意见"传给撰写节点,这样 AI 知道哪里需要改进。
Prompt 工程的关键:我们在编辑节点强调"严禁包含 Markdown、代码块",为什么?因为 LLM 很"礼貌",如果不管教,它可能回复:“是的,这是一个好文章。” 而不是单独的 “PASS”,导致程序无法识别终止条件,陷入无限循环。
PART 07 -下一步学习
通过以上7步,我们现在已经掌握了所有核心积木:链条、记忆、RAG、Agent,以及让它们变得智能的 LangGraph。
接下来,我们将从核心架构转向应用深度。将会陆续开展以下几个方面的实操教程:
多智能体协作 (Multi-Agent Systems):
探索 LangGraph 的终极形态:让多个 Agent 像一个团队一样工作。例如,我们创建一个团队,包括一个“研究员”、一个“总结员”和一个“审批员”,它们在 LangGraph 中相互协作、传递信息,共同完成一个复杂的任务。
RAG 生产级优化 (Advanced Retrieval)
深入 RAG(知识检索)的难点。如何处理复杂的 PDF、表格、以及索引优化策略(如 RAG-Fusion, Small-to-Large Chunking),让你的知识库应用在真实场景中更聪明、更精确。
结构化数据与工具整合 (Structured Output & Tools)
专注于数据的稳定性和可靠性。如何强制 LLM 严格输出 JSON 或 Pydantic 格式的数据(这是自动化流程的关键),以及如何将更多的外部工具(如计算器、数据库查询)安全可靠地集成到 Agent 中。
记住,框架是手段,解决问题才是目的。当你的业务需求超出框架能力时,不要犹豫——基于你学到的架构思想,自己实现定制版本。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









